







Kubernetes入门及集群部署文档
一、前言
哈喽啊,就是突然想写一遍技术文档与君共勉,也算证明自己在这个行业待过,好与不好大家凑合看看,接受指正
官方文档:https://kubernetes.io/zh-cn
二、Kubernetes (K8S) 是什么
它是一个为 容器化 应用提供集群部署和管理的开源工具,由 Google 开发。Kubernetes 这个名字源于希腊语,意为“舵手”或“飞行员”。k8s 这个缩写是因为 k 和 s 之间有八个字符的关系。 Google 在 2014 年开源了 Kubernetes 项目
三、主要特性
1.高可用,不宕机,自动灾难恢复
2.灰度更新,不影响业务正常运转
3.一键回滚到历史版本
4.方便的伸缩扩展(应用伸缩,机器加减)、提供负载均衡
5.有一个完善的生态
四、应用部署类型
为啥有这个章节呢,我觉得如果咱确实从没了解过容器,k8s啥的,那还是不容易理解这个有啥用,k8s的魅力何在,所有引出这一小节,只是我的拙见,见仁见智,以下以我们最常用的Java应用部署方式举例说明
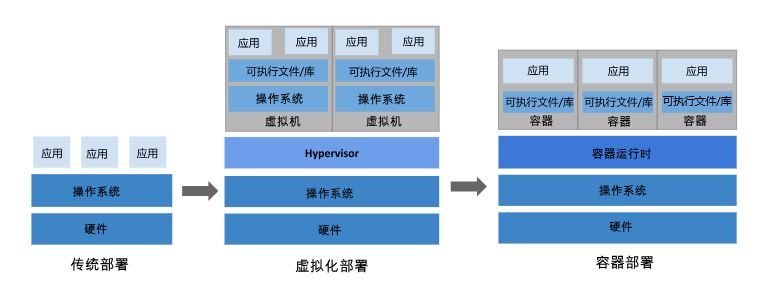
1、传统部署方式
- 应用直接在物理服务器(裸金属)上安装操作系统和应用程序,所有资源(CPU、内存、磁盘、网络)由物理机独占。
- 应用之间共享同一操作系统,没有隔离机制 物理机的资源(如内存、CPU)无法按需分配,容易出现资源浪费或争抢。例如:一个应用占用大量内存时,其他应用可能因资源不足崩溃
- 应用之间共享操作系统和库文件,一个应用的故障(如内存泄漏、崩溃)可能影响其他应用。
- 不同应用可能依赖不同的系统环境(如特定版本的库),导致兼容性问题。
2、虚拟化部署(Virtual Machine, VM)
- 通过 Hypervisor(如 VMware、KVM)在物理机上虚拟化多个独立虚拟机。每个虚拟机拥有完整的操作系统(Guest OS)和虚拟化硬件资源(vCPU、虚拟内存、虚拟磁盘)。
- 虚拟机之间完全隔离,故障或资源争抢仅影响当前虚拟机。
- 不同虚拟机可运行不同操作系统(如 Windows 和 Linux 共存)。
- 虚拟机的 CPU、内存等资源可动态调整(需 Hypervisor 支持)。
- 每个虚拟机需运行完整的操作系统,占用额外资源(如内存、存储)。
- Hypervisor 的虚拟化层会引入 10%~20% 的性能损耗。
- 启动虚拟机需要加载完整操作系统,耗时较长(分钟级)。
- 虚拟机可能因资源预留(如固定内存分配)导致浪费。
3、容器部署(Container)
- 基于容器引擎(如 Docker、Containerd)实现轻量级虚拟化。
- 容器无独立操作系统,直接共享主机内核,启动速度极快(秒级)。资源占用少(仅包含应用和依赖库),性能损耗低(接近原生)。
- 资源隔离与动态分配,通过 Cgroups 限制 CPU、内存等资源使用上限,避免资源争抢,可按需动态调整资源配额
- 容器镜像(Image)打包应用及其依赖,实现“一次构建,随处运行”。
- 适用场景:微服务架构(每个服务独立容器化)、DevOps 流程中的持续集成/持续部署(CI/CD)、高密度部署(如云原生应用、弹性扩缩容场景)
4、应用部署方式对比总结
| 特性 | 传统部署 | 虚拟化部署 | 容器部署 |
|---|---|---|---|
| 隔离性 | 无隔离 | 完全隔离(独立操作系统) | 进程级隔离(共享内核) |
| 性能损耗 | 无 | 高(10%~20%) | 极低(1%~5%) |
| 启动速度 | 秒级(仅应用启动) | 分钟级(需启动完整系统) | 秒级(直接运行容器) |
| 资源利用率 | 低(资源独占) | 中等(虚拟机资源预留) | 高(动态按需分配) |
| 环境一致性 | 依赖物理机环境 | 依赖虚拟机镜像 | 容器镜像保证一致性 |
| 适用场景 | 高性能计算、遗留系统 | 多租户、多操作系统需求 | 云原生、微服务、CI/CD |
5、补充说明
- 性能损耗:容器因共享内核且无虚拟化层,性能接近原生;虚拟机需通过 Hypervisor 虚拟化硬件,损耗较高。
- 隔离性:虚拟机提供硬件级隔离(安全性更高),容器依赖内核机制隔离(轻量但共享内核)。
- 资源分配:容器支持动态调整资源配额(如 CPU 核数、内存上限),传统部署和虚拟机需手动配置。
五、应用部署的演进与 Kubernetes 的价值
1、单机部署场景
方案: 使用 Docker + Docker Compose 单机编排,即可快速完成环境配置、依赖管理和服务启动。
优势: 简单轻量,适合开发测试或小型项目,告别“环境不一致”的噩梦。
2、中小规模集群(3~10 台)
方案: 手动在多台机器部署应用,搭配 Nginx/HAProxy 等负载均衡器。
痛点:
- 机器扩容时需重复配置环境
- 版本更新需逐台操作,易出错且效率低下
3、大规模集群(百台/千台以上)
3.1 灾难性挑战
- 运维成本剧增
机器扩容、版本回滚、配置同步等操作需投入大量人力,沦为“重复性劳动奴隶”。 - 稳定性风险
人工操作易失误,可能导致服务中断,影响用户体验甚至企业收益。
3.2 破局者:Kubernetes (K8s)
核心能力:
- 自动化运维: 通过声明式 API 一键完成滚动更新、故障自愈、弹性扩缩容
- 跨机器调度: 智能分配容器到最优节点,提升资源利用率
- 零停机发布: 支持蓝绿部署、金丝雀发布,保障业务连续性
- 统一管控: 集中管理数千节点,监控、日志、网络策略全链路覆盖
价值体现:
将工程师从琐碎运维中解放,聚焦架构优化与核心业务创新,技术团队效能与系统稳定性双赢。
4、为什么选择 Kubernetes?
4.1 传统部署痛点与K8S解决方案
-
人工运维困境
- 传统部署需手动上传程序包、配置环境、启动服务,扩容需人工介入加服务器配负载均衡
- K8S解决方案: 全自动化容器编排,实现服务自动部署/更新/扩缩容,消除人工干预
-
集群管理缺陷
- 裸跑Docker存在单机局限、管理成本高、无自愈机制、缺乏编排模板等问题
- K8S核心能力:
✅ 跨节点集群管理
✅ 容器智能调度
✅ 故障自愈与滚动更新
✅ 统一配置中心
✅ 全生命周期管理工具链
4.2 Kubernetes核心特性
| 特性维度 | 实现能力 |
|---|---|
| 弹性伸缩 | 支持CPU/内存指标自动扩缩容,手动/自动混合模式控制资源成本 |
| 故障自愈 | 自动重启异常容器,节点宕机时迁移Pod,确保业务持续可用 |
| 服务治理 | 内置DNS服务发现,四层负载均衡,支持金丝雀发布/蓝绿部署等高级流量策略 |
| 配置管理 | ConfigMap统一管理环境变量,Secret加密存储敏感数据,版本化配置回滚 |
| 存储编排 | 整合本地存储/NFS/云盘,动态供给PV/PVC,支持StatefulSet有序持久化部署 |
| 批量任务 | CronJob定时任务,Job并行计算,支撑大数据/AI训练场景 |
| 多云兼容 | 无缝运行于物理机/虚拟机/混合云,提供Cluster API统一多云管理接口 |
4.3 技术收益 vs 商业收益
| 技术维度 | 商业维度 |
|---|---|
| 🚀 标准化交付体系 | 💰 运维成本下降 |
| - 一次构建,跨云/混合环境运行 | - 自动化替代人工,成本降低60%+ |
| 🛠 微服务治理能力 | 📈 资源效率跃升 |
| - 集成Istio服务网格 | - 智能调度提升利用率40%+ |
| 👁 全链路可观测性 | ⏱ 业务连续性保障 |
| - Prometheus监控 + ELK日志 | - 故障自愈,恢复时间从小时级降至分钟级 |
| 🔄 生态兼容性 | 🌍 规模化扩展能力 |
| - 兼容多云/混合架构 | - 生产验证支持千万级并发集群 |
六、Kubernetes 集群架构图
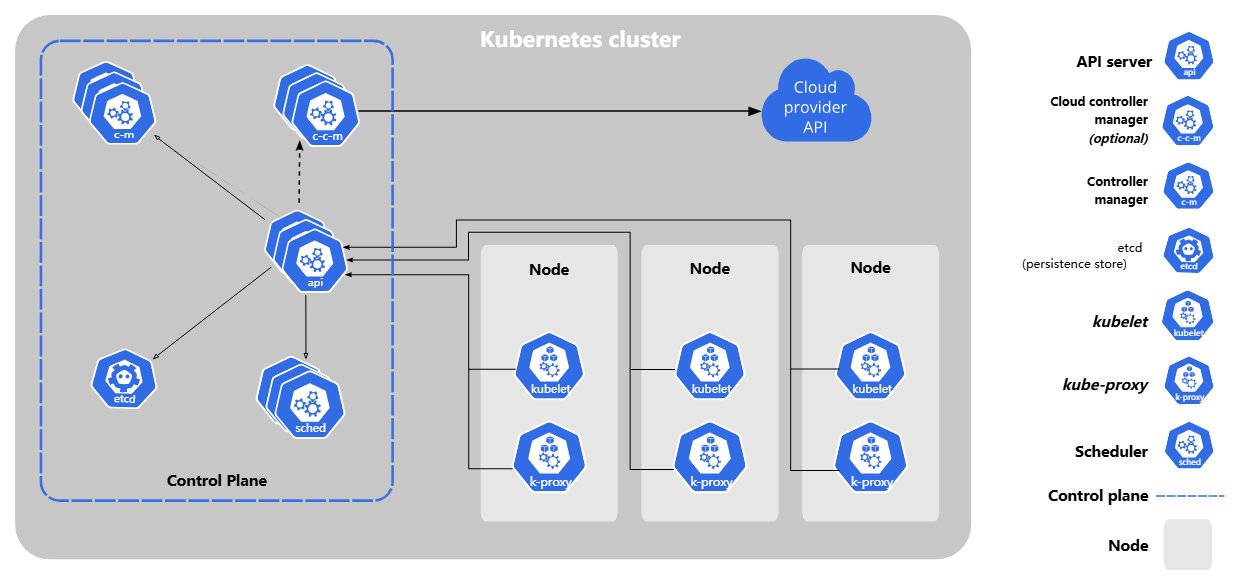
1、集群架构组成
1.1 Master(主节点)
- 角色定位
集群控制平面,不运行实际业务负载 - 核心特性
- 单节点可用于开发测试环境
- 生产环境需部署3个以上节点实现高可用
- 硬件建议配置
- CPU:4核+(etcd节点建议8核+)
- 内存:8GB+(大规模集群需16GB+)
- 存储:etcd专用SSD(至少200GB)
1.2 Worker(工作节点)
- 核心职责
运行业务Pod的核心节点 - 部署规范
- 支持物理机/虚拟机混合部署
- 通过
Cluster Autoscaler实现自动扩缩容 - 建议单独挂载
/var/lib/docker目录
- 硬件基准配置
- CPU:16核+
- 内存:64GB+
- 存储:NVMe SSD(500GB+)
2、核心资源对象
2.1 基础工作单元
| 资源类型 | 特性描述 |
|---|---|
| Pod | 最小调度单元,包含1个或多个共享存储/网络的容器 |
| Service | 定义Pod访问策略,提供负载均衡和稳定IP端点 |
| Deployment | 管理无状态应用的副本数和滚动更新 |
2.2 高级工作负载
| 资源类型 | 应用场景 |
|---|---|
| StatefulSet | 管理有状态应用(如MySQL集群),保证Pod有序部署和唯一标识 |
| DaemonSet | 每个Worker节点运行指定Pod(适用于日志收集/监控代理) |
| CronJob | 定时任务调度(如每日备份) |
2.3 配置管理
| 资源类型 | 数据管理特性 |
|---|---|
| ConfigMap | 存储非敏感配置数据(如环境变量) |
| Secret | 存储敏感数据(如密码/TLS证书),Base64编码 |
3、核心组件解析
3.1 Master组件
| 组件名称 | 核心功能 |
|---|---|
| API Server | 提供REST API接口,处理kubectl命令 |
| etcd | 分布式键值存储,持久化集群状态 |
| kube-scheduler | 决策Pod调度到最优节点 |
| kube-controller-manager | 维护副本数/节点状态等集群状态 |
3.2 Node组件
| 组件名称 | 功能描述 |
|---|---|
| kubelet | 管理Pod生命周期,上报节点状态 |
| kube-proxy | 维护Service的iptables/IPVS规则 |
| Container Runtime | 容器运行时引擎(Docker/containerd) |
4、网络与存储
4.1 网络架构
| 概念 | 功能实现 |
|---|---|
| CNI插件 | 管理Pod网络通信(Flannel/Calico) |
| Service | 类型:ClusterIP(内部)/NodePort(节点端口)/LoadBalancer(云厂商LB) |
| Ingress | 七层流量管理(域名/路径路由) |
4.2 存储管理
| 资源类型 | 功能特性 |
|---|---|
| Volume | Pod级存储(emptyDir临时存储/hostPath主机路径) |
| PersistentVolume | 集群级持久化存储(NFS/云存储) |
| PVC | 用户存储资源申请(指定容量/访问模式) |
5、安全与权限
5.1 核心机制
| 机制 | 功能描述 |
|---|---|
| Namespace | 资源逻辑隔离(如prod/test环境隔离) |
| ServiceAccount | 为Pod提供身份凭证 |
| RBAC | 基于角色的访问控制(Role/ClusterRole定义权限) |
5.2 安全配置命令
# 创建ServiceAccount
kubectl create serviceaccount api-user
# 角色绑定
kubectl create rolebinding dev-edit --role=edit --serviceaccount=default:api-user
6、扩展工具
| 工具名称 | 核心用途 |
|---|---|
| kubectl | 集群管理命令行工具(支持插件扩展) |
| Helm | 应用包管理(Chart模板/版本控制) |
| HPA | 自动扩缩容(基于CPU/内存指标) |
七、Kubernetes部署
我之前部署过1.20版本的,但现在1.33版本都快发布了,时间过的真快啊,本次以1.24版本演示一下部署过程吧,后续如果有时间了再搞下最新版本的部署
从1.24版本开始,Kubernetes移除了对Docker的支持,所以必须使用containerd或CRI-O作为容器运行时。因此,部署文档中安装和配置containerd,而不是Docker
好了,说了这么多,想必各位准大佬对k8s已经有一个了解了,那我们开始部署吧
1、环境准备
| 主机名 | IP地址 | 角色 | 最低配置要求 |
|---|---|---|---|
| master | 172.16.0.42 | 控制平面(Control Plane) | 2核CPU,4GB内存,20GB磁盘 |
| node1 | 172.16.0.43 | 工作节点(Worker Node) | 2核CPU,4GB内存,50GB磁盘 |
| node2 | 172.16.0.44 | 工作节点(Worker Node) | 2核CPU,4GB内存,50GB磁盘 |
在阿里云上购买了3台服务器,配置如下,如果你虚拟机配置足够,那也是可以的

为了方便演示,这3台服务器都默认公网了,如果是内网环境安装的话,有的地方需要自行斟酌了
2、系统初始化(所有节点执行)
# 关闭防火墙(所有节点)
systemctl stop firewalld && systemctl disable firewalld
# 关闭 SELinux(所有节点)
setenforce 0
sed -i 's/^SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
# 关闭 Swap(所有节点)
swapoff -a
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
#修改主机名
#在42执行
hostnamectl set-hostname master --static
#在43执行
hostnamectl set-hostname node1 --static
#在44执行
hostnamectl set-hostname node2 --static
# 配置主机名解析(所有节点)
cat >> /etc/hosts << EOF
172.16.0.42 master
172.16.0.43 node1
172.16.0.44 node2
EOF
# 配置内核参数(所有节点)
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --system
# 配置时区并同步时间,内网环境的话时间同步需要找其它本地机器同步时间(所有节点)
timedatectl set-timezone Asia/Shanghai
yum install -y ntpdate
ntpdate ntp.aliyun.com
# 加载内核模块(所有节点)
modprobe br_netfilter
modprobe overlay
echo "br_netfilter" >> /etc/modules-load.d/k8s.conf
echo "overlay" >> /etc/modules-load.d/k8s.conf
3、安装容器运行时(containerd)(所有节点)
3.1 安装依赖工具
yum install -y yum-utils device-mapper-persistent-data lvm2
3.2 配置 Docker CE 仓库
#使用阿里云镜像仓库
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
3.3 安装 containerd
yum install -y containerd.io
3.4 配置 containerd
mkdir -p /etc/containerd
containerd config default > /etc/containerd/config.toml
# 修改配置文件启用 Systemd Cgroup
sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
sed -i 's#registry.k8s.io#registry.aliyuncs.com/google_containers#g' /etc/containerd/config.toml
# 检查 containerd 是否运行
systemctl status containerd
# 如果未运行,启动服务
systemctl start containerd
# 如果运行,则重新启动服务
systemctl restart containerd
# containerd 加入开机自启
systemctl enable containerd --now
出现 Running 就说明containerd安装成功了,其它两台一样
查看镜像
crictl images

这个错误是因为 Kubernetes 1.24 及以上版本移除了对 Docker 的支持,我们这里装的是containerd,containerd是用 crictl 查看镜像的,然后crictl默认尝试连接 dockershim.sock,导致连接失败。
所有还需要配置 crictl 使用正确的容器(containerd)
# 创建或修改 crictl 配置文件
cat > /etc/crictl.yaml << EOF
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
EOF
##修改后一般无须重启直接查看镜像,如果有问题再看下的
# 检查 containerd 是否运行
systemctl status containerd
# 如果未运行,启动服务
systemctl start containerd && systemctl enable containerd

4、安装 Kubernetes 组件(所有节点)
4.1 配置 Kubernetes 仓库
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
4.2 安装 kubeadm、kubelet、kubectl
yum install -y kubelet-1.24.0 kubeadm-1.24.0 kubectl-1.24.0 --disableexcludes=kubernetes
# 启动 kubelet
systemctl enable kubelet --now
#查看kubelet状态 现在每隔几秒就会重启,因为它陷入了一个等待 kubeadm 指令的死循环,这是正常的
systemctl status kubelet
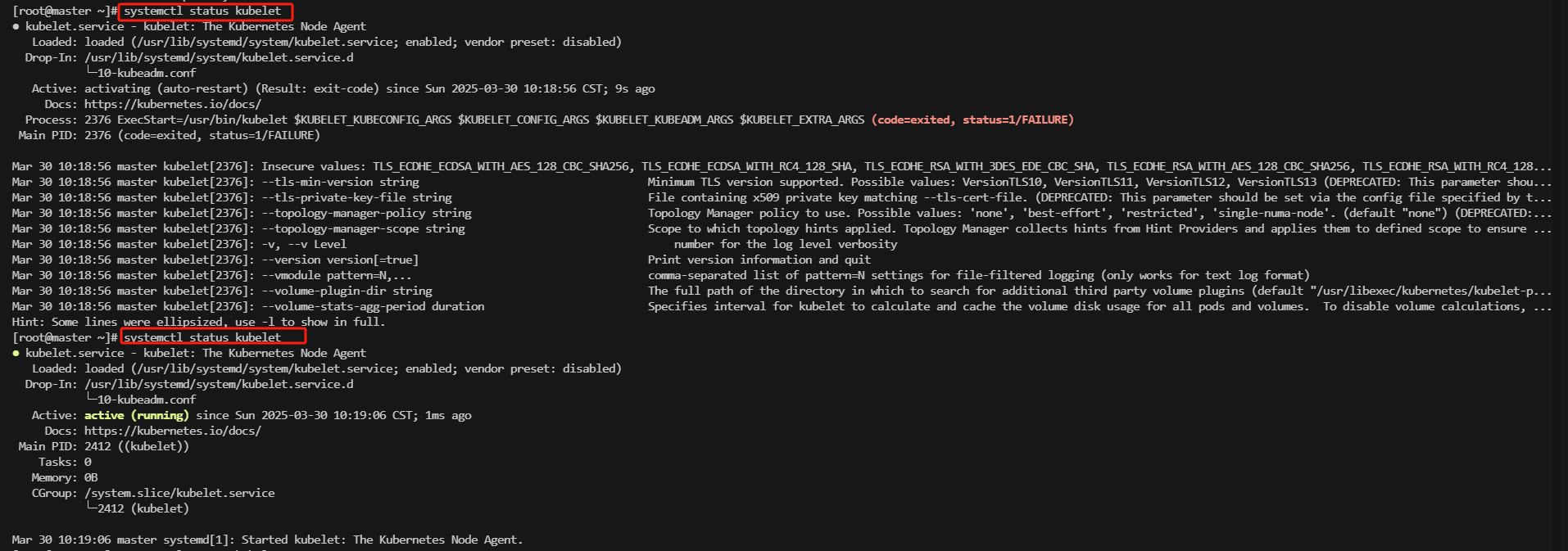
5、 初始化控制平面(master 执行)
5.1 初始化控制平面
kubeadm init \
--apiserver-advertise-address=172.16.0.42 \
--image-repository registry.aliyuncs.com/google_containers \
--control-plane-endpoint=master \
--kubernetes-version v1.24.0 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16
执行过程如下:
[root@master ~]# kubeadm init \
> --apiserver-advertise-address=172.16.0.42 \
> --image-repository registry.aliyuncs.com/google_containers \
> --control-plane-endpoint=master \
> --kubernetes-version v1.24.0 \
> --service-cidr=10.1.0.0/16 \
> --pod-network-cidr=10.244.0.0/16
[init] Using Kubernetes version: v1.24.0
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master] and IPs [10.1.0.1 172.16.0.42]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master] and IPs [172.16.0.42 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master] and IPs [172.16.0.42 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 6.004854 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node master as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: vqu0vz.xgucn5ssaw114vxi
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join master:6443 --token vqu0vz.xgucn5ssaw114vxi \
--discovery-token-ca-cert-hash sha256:44f362df4094a243f0292ca26584e8432d2bb04227a4c986652bfb2b1da88d7d \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join master:6443 --token vqu0vz.xgucn5ssaw114vxi \
--discovery-token-ca-cert-hash sha256:44f362df4094a243f0292ca26584e8432d2bb04227a4c986652bfb2b1da88d7d
[root@master ~]#
#看到下面这段话,就说明master安装成功了 。然后得到如下这段提示,复制出来找地方存下,后面用
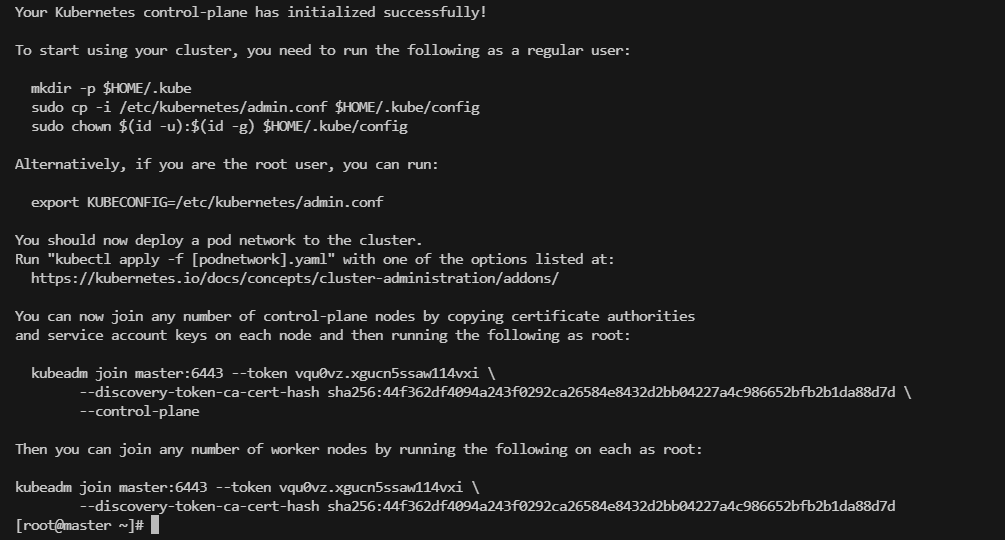
执行下面3个命令
o start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
至此,k8s的master部署完成,可以通过如下命令查看集群节点
kubectl get nodes
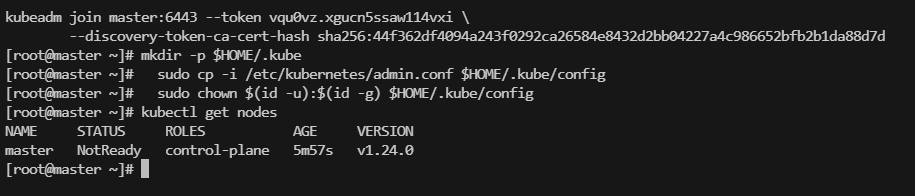
目前集群没有加入node节点,如果只有master。status为:NotReday,这是因为没有做网络插件,做好了之后状态就为Reday了
6、安装网络插件(Calico)
6.1 部署 Calico
在 Kubernetes 中,网络插件(如 Calico)的版本与 Kubernetes 版本之间没有直接的版本号对齐关系,它们的版本号是独立维护的。Calico 的 v3.25.x 是长期支持(LTS)版本,提供更长的维护周期,适合生产环境
Calico手动下载地址:https://github.com/projectcalico/calico/releases
#有条件的可以直接执行下面的命令,但先往下看,不要突突就执行了哦
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.25.0/manifests/calico.yaml
#calico.yaml里会默认下载下面这几个镜像,由于这个网络组件calico是从dockerhup安装的,docker官网被国内禁止后,需要找镜像包手动上传用ctr import的方式导入镜像
[root@master ~]# grep "image:" calico.yaml
image: docker.io/calico/cni:v3.25.0
image: docker.io/calico/cni:v3.25.0
image: docker.io/calico/node:v3.25.0
image: docker.io/calico/node:v3.25.0
image: docker.io/calico/kube-controllers:v3.25.0
calico.yaml下载不了的用我这个
镜像下载不了的也用这个release-v3.25.0,然后导入进去
所有节点都需要导入release-v3.25.0,将下载好的release-v3.25.0放到服务器上,在同目录创建 calico.sh
#!/bin/bash
#解压
tar xf release-v3.25.0.tgz
# 进入镜像目录
cd release-v3.25.0/images
# 导入所有镜像
sudo tee load-images.sh <<EOF
#!/bin/bash
tars=(
calico-cni.tar
calico-node.tar
calico-kube-controllers.tar
calico-pod2daemon.tar
calico-typha.tar
)
for tar in "\${tars[@]}"; do
sudo ctr -n=k8s.io image import \$tar
done
EOF
# 执行脚本
chmod +x load-images.sh && ./load-images.sh
执行脚本:sh calico.sh
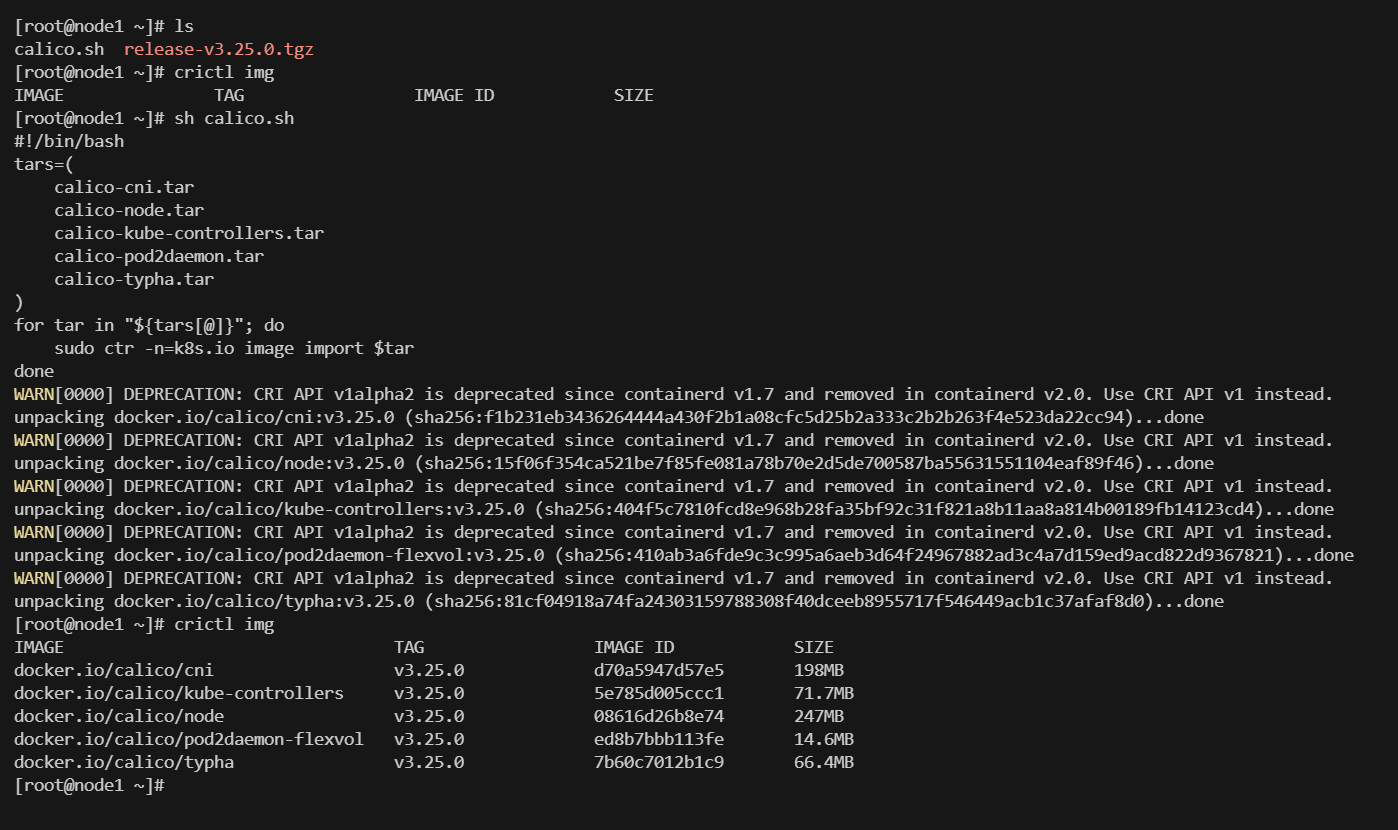
CRI API版本警告,CRI API v1alpha2 is deprecated提示当前containerd版本较高(≥1.7),需适配新版API,但该警告不影响镜像导入操作。若需消除CRI弃用警告,可升级Calico至v3.26+或配置containerd使用CRI v1,兼容高版本containerd
修改calico.yaml里image 地址
sed -i 's/image: docker.io\//image: /g' calico.yaml
说明 ✒:
原本 calico.yaml 中所规定的 image 资源都是长这样的docker.io/calico/cni:v3.20.6, 由于这个 docker.io/ 前缀会导致 k8s 去 DockerHub 上找 image ,而不是使用刚才我们导入进本地的 images。所以我们用 sed -i 来全局查找替换,去掉它们。
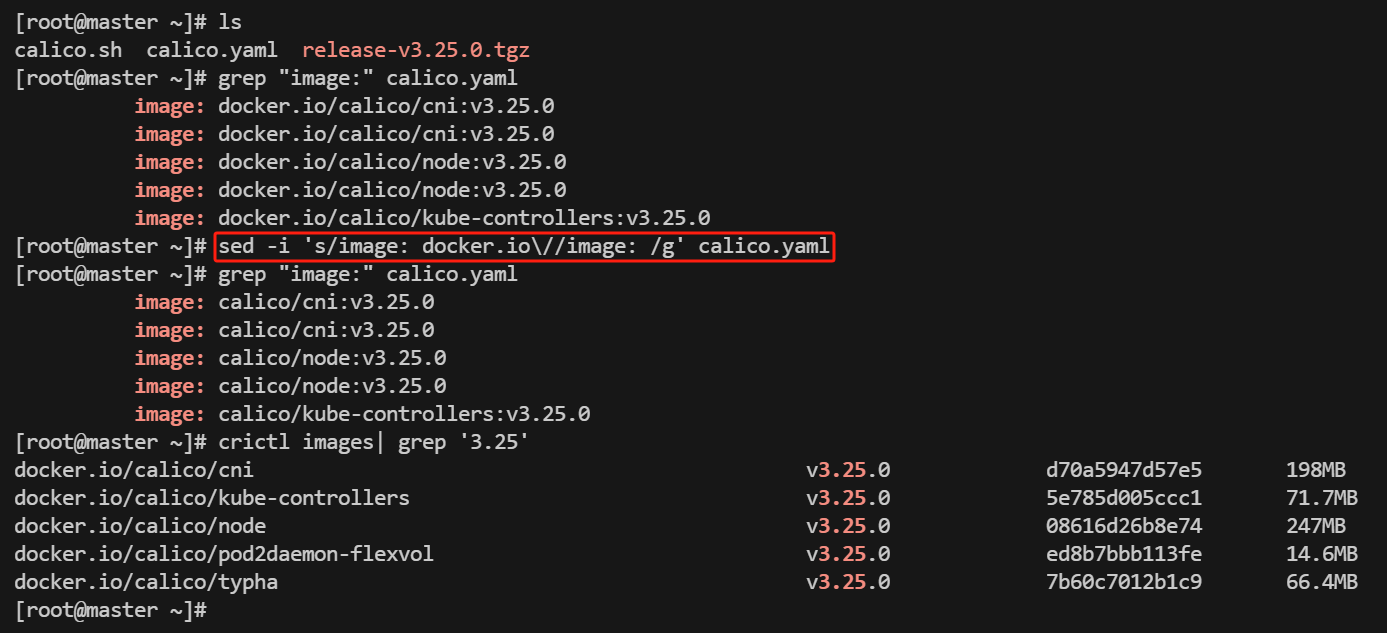
创建calico:kubectl apply -f calico.yaml
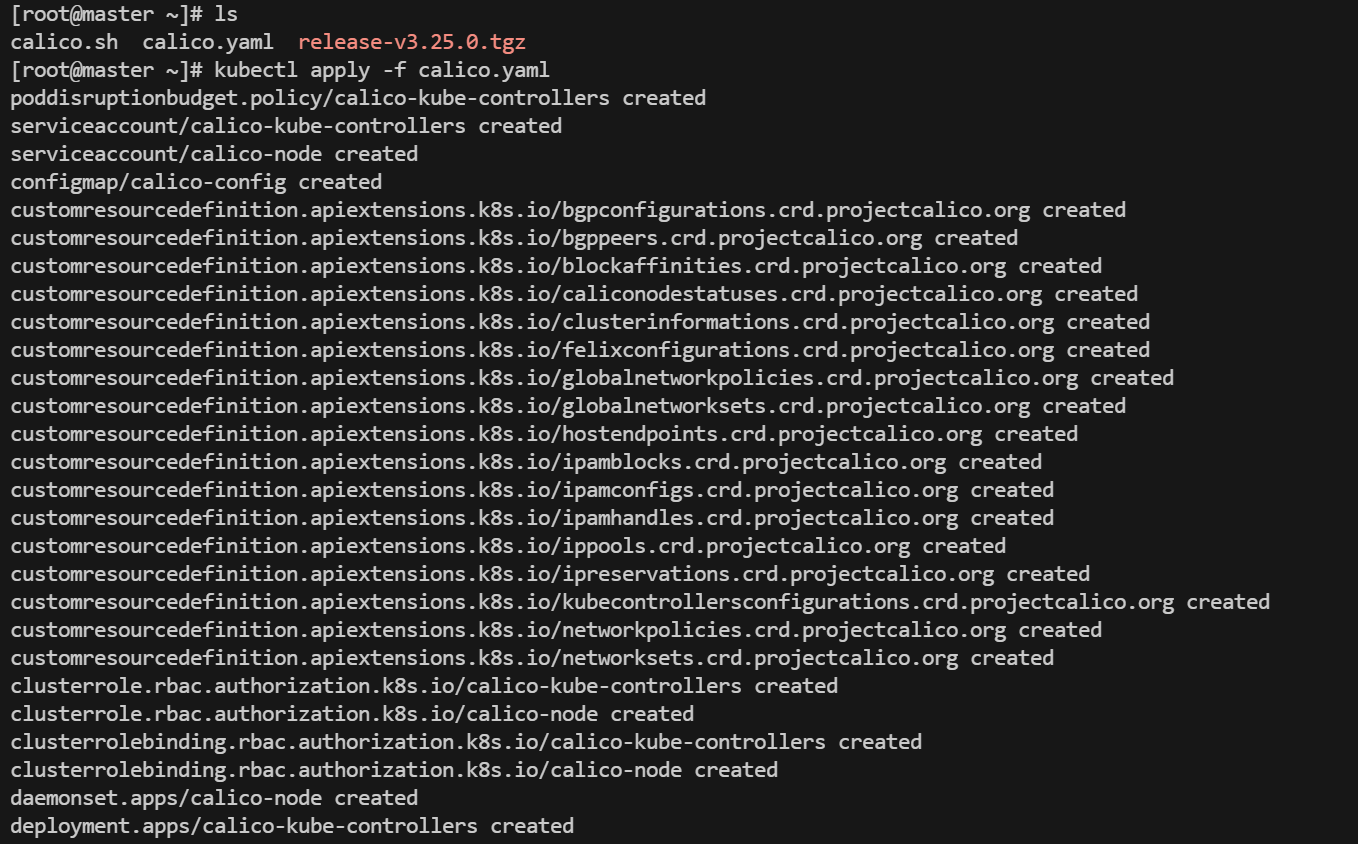
查看calico:kubectl get pods -n kube-system |grep calico

7、加入工作节点(node1/node2 执行)
在前面kubeadm init 成功后获得的一段信息
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join master:6443 --token vqu0vz.xgucn5ssaw114vxi \
--discovery-token-ca-cert-hash sha256:44f362df4094a243f0292ca26584e8432d2bb04227a4c986652bfb2b1da88d7d
我们要作为node节点加入这个集群,就在node节点执行下面的命令就行
# 使用 kubeadm join 命令(在 master1 初始化后输出)
kubeadm join master:6443 --token vqu0vz.xgucn5ssaw114vxi \
--discovery-token-ca-cert-hash sha256:44f362df4094a243f0292ca26584e8432d2bb04227a4c986652bfb2b1da88d7d
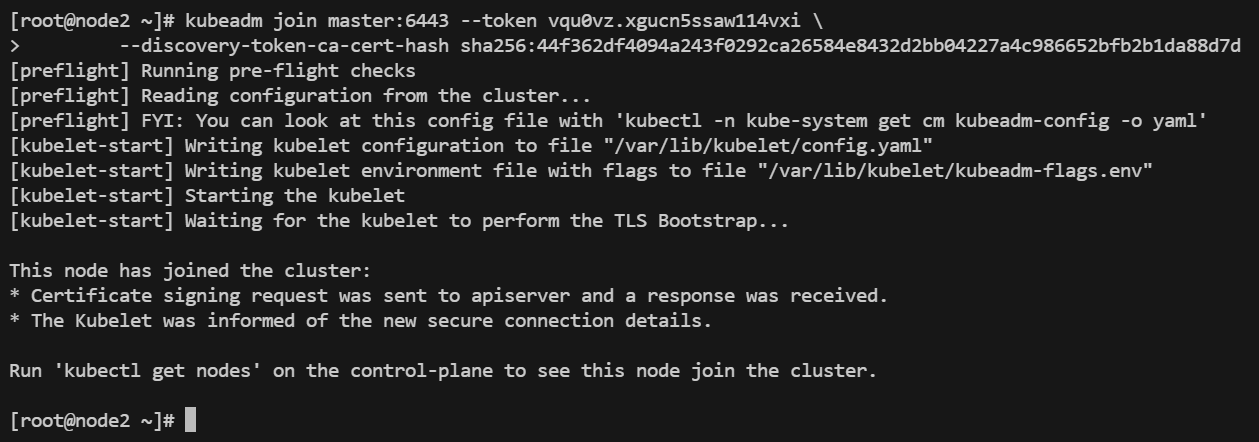
当node节点出现这个就说明加入成功了,
8、验证集群状态
# 查看节点状态
kubectl get nodes -o wide

# 查看所有 Pod 状态
kubectl get pods --all-namespaces
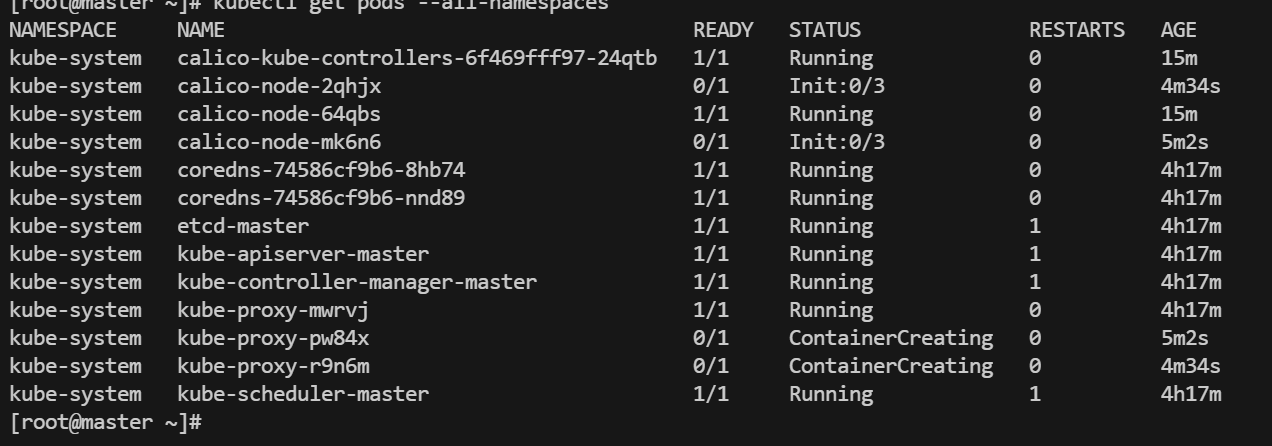
等了一会后再看,所有pod都是Running状态,所有节点都是Ready状态了
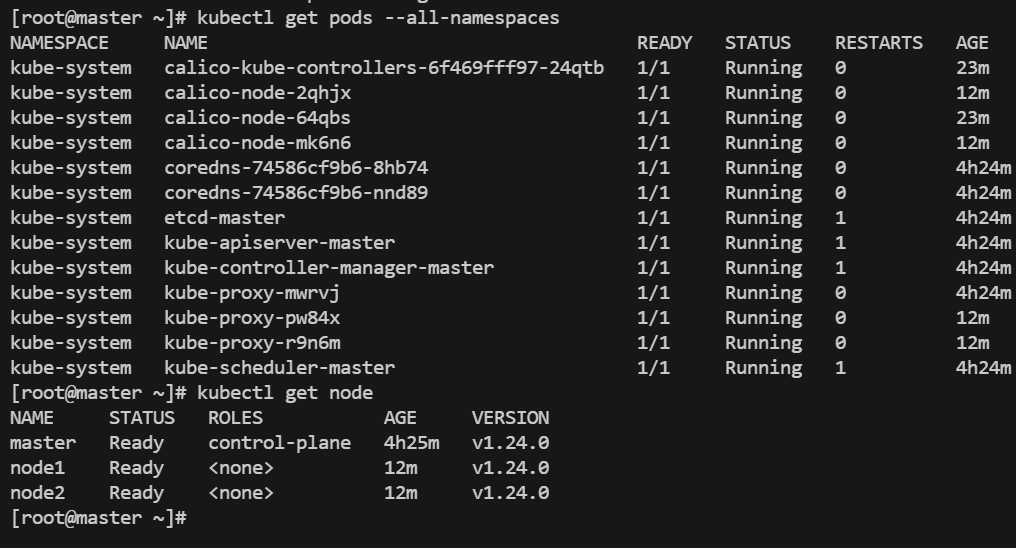
从node节点查看Pod报错?
[root@node1 ~]# kubectl get pod
The connection to the server localhost:8080 was refused - did you specify the right host or port?
[root@node1 ~]#
出现这个问题的原因是kubectl命令需要使用kubernetes-admin来运行,解决方法如下,将主节点中的【/etc/kubernetes/admin.conf】文件拷贝到从节点相同目录下,然后配置环境变量
#从主节点传输admin.conf到node节点
scp /etc/kubernetes/admin.conf root@172.16.0.43:/etc/kubernetes/
scp /etc/kubernetes/admin.conf root@172.16.0.44:/etc/kubernetes/
#node节点执行
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
[root@node2 ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
[root@node2 ~]# source ~/.bash_profile
[root@node2 ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-6f469fff97-24qtb 1/1 Running 0 34m
kube-system calico-node-2qhjx 1/1 Running 0 23m
kube-system calico-node-64qbs 1/1 Running 0 34m
kube-system calico-node-mk6n6 1/1 Running 0 23m
kube-system coredns-74586cf9b6-8hb74 1/1 Running 0 4h35m
kube-system coredns-74586cf9b6-nnd89 1/1 Running 0 4h35m
kube-system etcd-master 1/1 Running 1 4h36m
kube-system kube-apiserver-master 1/1 Running 1 4h36m
kube-system kube-controller-manager-master 1/1 Running 1 4h36m
kube-system kube-proxy-mwrvj 1/1 Running 0 4h35m
kube-system kube-proxy-pw84x 1/1 Running 0 23m
kube-system kube-proxy-r9n6m 1/1 Running 0 23m
kube-system kube-scheduler-master 1/1 Running 1 4h36m
[root@node2 ~]#
至此你已经把集群搭建完毕,各节点连接正常,给自己点个赞吧!!!
k8s集群具有自愈功能,即服务器重启后,集群会自动启动并保持连接
9、部署dashboard
版本信息:https://github.com/kubernetes/dashboard/releases
9.1 修改配置文件
# 使用阿里云镜像源
curl -s https://raw.githubusercontent.com/kubernetes/dashboard/v2.6.1/aio/deploy/recommended.yaml -O
# 替换 Dashboard 主镜像
sed -i 's#\(image: \).*kubernetesui/dashboard:v2.6.1#\1crpi-qg408gvx95qwvd9b.cn-beijing.personal.cr.aliyuncs.com/dsg_images/dashboard:v2.6.1#g' recommended.yaml
# 替换 Metrics Scraper 镜像
sed -i 's#\(image: \).*kubernetesui/metrics-scraper:v1.0.8#\1crpi-qg408gvx95qwvd9b.cn-beijing.personal.cr.aliyuncs.com/dsg_images/metrics-scraper:v1.0.8#g' recommended.yaml
# 检查镜像地址是否替换成功
[root@master ~]# grep 'image:' recommended.yaml
image: crpi-qg408gvx95qwvd9b.cn-beijing.personal.cr.aliyuncs.com/dsg_images/dashboard:v2.6.1
image: crpi-qg408gvx95qwvd9b.cn-beijing.personal.cr.aliyuncs.com/dsg_images/metrics-scraper:v1.0.8
[root@master ~]#
[root@master ~]# kubectl apply -f recommended.yaml
namespace/kubernetes-dashboard created
serviceaccount/kubernetes-dashboard created
service/kubernetes-dashboard created
secret/kubernetes-dashboard-certs created
secret/kubernetes-dashboard-csrf created
secret/kubernetes-dashboard-key-holder created
configmap/kubernetes-dashboard-settings created
role.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
deployment.apps/kubernetes-dashboard created
service/dashboard-metrics-scraper created
deployment.apps/dashboard-metrics-scraper created
9.2 安装成功查看pod
[root@master ~]# kubectl get pod -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-88f44df8f-kbfc8 1/1 Running 0 34s
kubernetes-dashboard-7d68c4969-qmn86 1/1 Running 0 35s
[root@master ~]#
9.3 设置访问端口
kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard
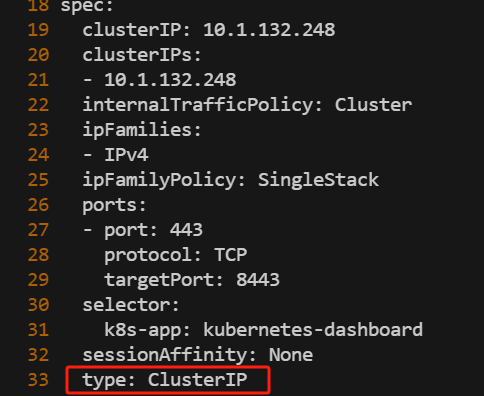
将type: ClusterIP 改为 type: NodePort

[root@master ~]# kubectl get svc -A |grep kubernetes-dashboard
kubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.1.221.183 <none> 8000/TCP 5m19s
kubernetes-dashboard kubernetes-dashboard NodePort 10.1.132.248 <none> 443:30657/TCP 5m19s
9.4 开放安全组
我这里是端口是30657,在安全组放行,本地服务器关闭防火墙,或者网络策略即可
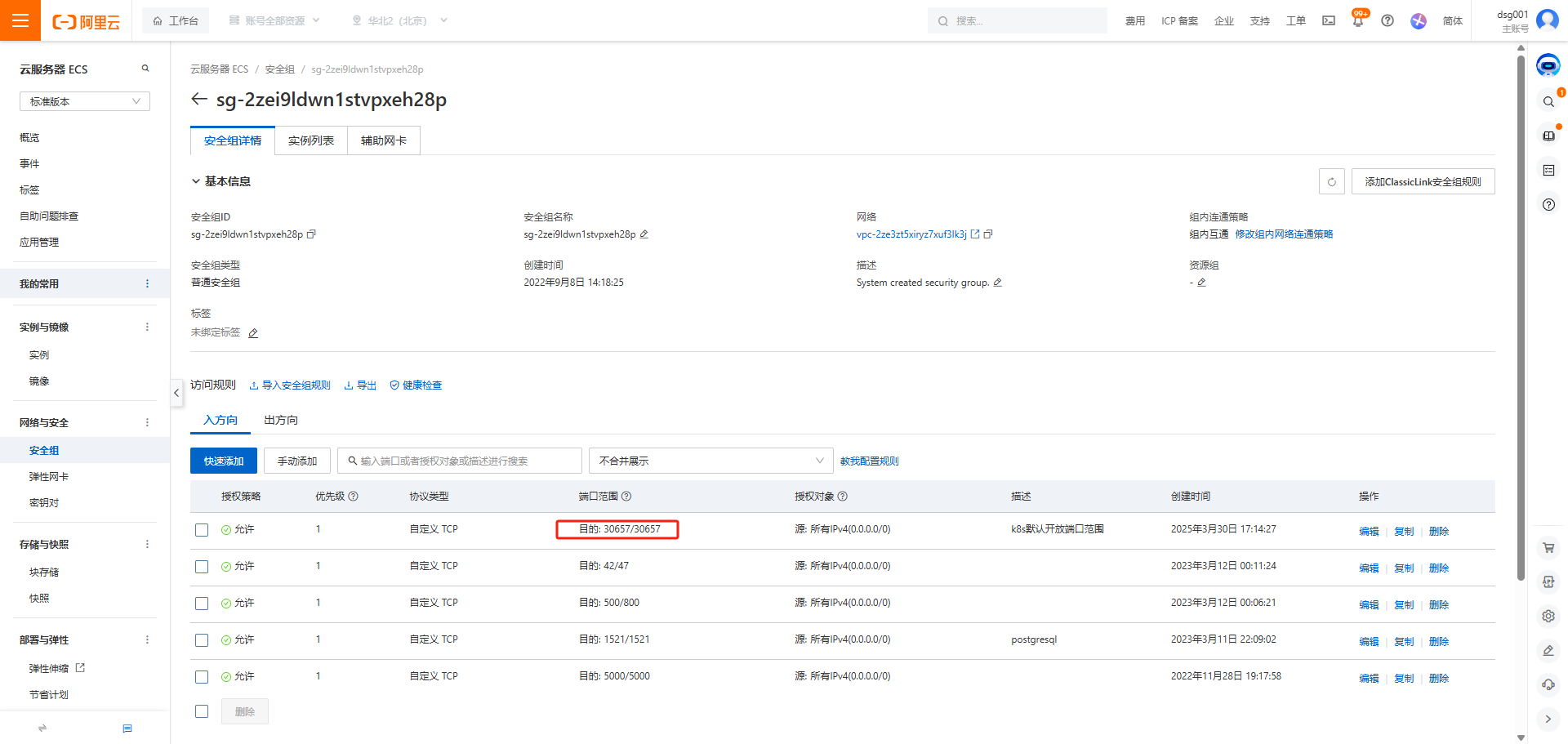
9.5 页面访问
浏览器访问集群的任意ip的30657端口即可访问kubernetes-dashboard,我这里用的是阿里云服务器,所以直接用节点对应的互联网ip:30657访问了
访问地址:https://ip:30657,下面用俩节点ip演示登录是没问题的
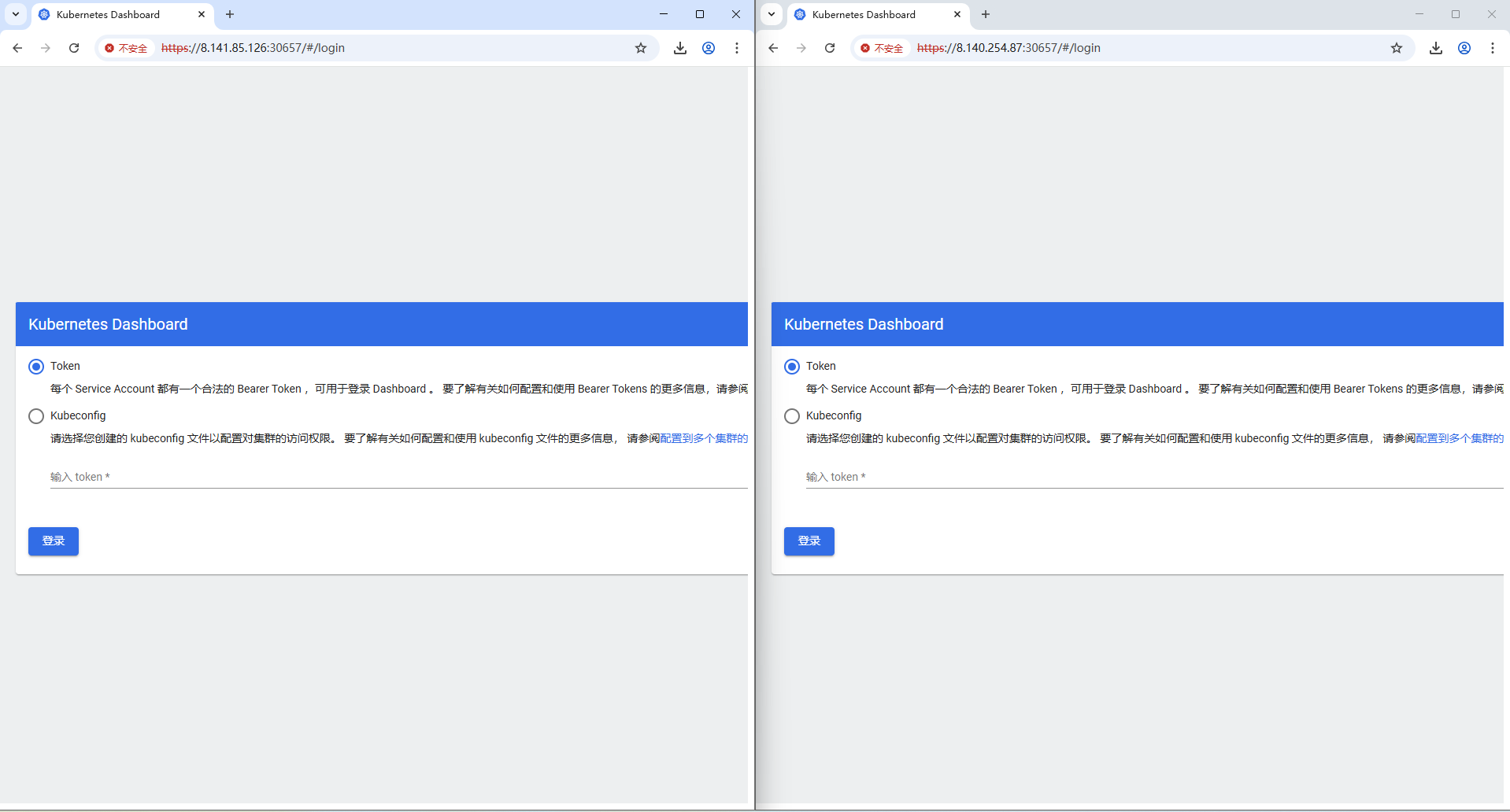
9.6 创建访问账号
准备一个yaml文件; vi dash.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: dashboard-admin
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: dashboard-admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: dashboard-admin
namespace: kubernetes-dashboard
应用一下:
[root@master ~]# kubectl apply -f dash.yaml
serviceaccount/admin-user created
clusterrolebinding.rbac.authorization.k8s.io/admin-user created
9.7 通过令牌登录
#获取访问令牌,token24H有效
[root@master ~]# kubectl -n kubernetes-dashboard create token dashboard-admin
eyJhbGciOiJSUzI1NiIsImtpZCI6IlhoejJod01UX0NRNmlLa3JIQm9MTTV1ZlpTbG9OLTFTdEtXbk81TnBENmMifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNzQzMzMwNjE1LCJpYXQiOjE3NDMzMjcwMTUsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJkYXNoYm9hcmQtYWRtaW4iLCJ1aWQiOiIwMmFlOWRmYy1jYzk4LTQ2NTYtOGY3Yi01MGUyMTdiMTE3NTMifX0sIm5iZiI6MTc0MzMyNzAxNSwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmVybmV0ZXMtZGFzaGJvYXJkOmRhc2hib2FyZC1hZG1pbiJ9.vbUYKEKP3R9Xkg33RLhMo_wd8PYyO0LfyEibWn1IU3nvWxDhSdu5hik44meqa0LH8lOev8geGNp88K8FQzLSk99ez_43cbaUxuG-9wUx9cfivIsvkuI4X0KYGaTQ6tYEJDQ5y-0tjWECkSm7Er7VmtNE7zwqOZZlTmF8iZHbjeHQLi292f583YN3pIidtWIEW2EuL275S6uzDFcc6wGWWxAWQqn0HF1OU4V7HY6LQ_49nCEin9ScQt1DbUeSUkgIU7bdnXTqS-OdwS1vzs3lDDf-CDCKgJ-ZIlH2kM1f0qHfsOE0mLZxUxfh7VtbQUq8MQc8uMgkykeZJYf0oN0IEw
[root@master ~]#
至此你已经把k8s面板部署完成呐,后续每次登录k8s面板都需要通过此命令进行获取令牌:kubectl -n kubernetes-dashboard create token dashboard-admin
或者寻找其它可视化工具如Kuboard、kubesphere、Rancher等等,感兴趣的可以了解一下,不在这里赘述了
10、存储抽象
这块部分写的比较潦草,算是个半成品吧。主要是我习惯用WPS智能文档记录技术笔记,基本也就自己看,那个方式也更适合我,第一次在csdn写这种技术文档,还是写的Markdown,挺痛苦的,我用不惯,大周末的在电脑边搞了一天,搞急了哈哈哈,这部分随便看看吧。如果你能独立部署没问题了,我觉得也算是入门了,从我学习k8s以来到现在反反复复部署过不下50次了,每次想用的时候就部署一遍,也算是熟悉熟悉,当然网上有很多部署文档,一键部署的直接搞定,但为什么我每次还要这么麻烦的敲命令呢,无他,就是热爱吧
10.1 所有机器安装
#所有机器安装
yum install -y nfs-utils
10.2 主节点执行
#nfs主节点
echo "/data/nfs/ *(insecure,rw,sync,no_root_squash)" > /etc/exports
mkdir -p /data/nfs
systemctl enable rpcbind --now
systemctl enable nfs-server --now
#配置生效
exportfs -r
10.3 从节点执行
#从节点执行
showmount -e 172.16.0.42 #主节点ip
#执行以下命令挂载 nfs 服务器上的共享目录到本机路径 /nfs/data
mkdir -p /data/nfs
mount -t nfs 172.16.0.42:/data/nfs /data/nfs
# 写入一个测试文件
echo "hello nfs server" > /data/nfs/test.txt
#node1节点运行日志
[root@node1 ~]# showmount -e 172.16.0.42
Export list for 172.16.0.42:
/data/nfs *
[root@node1 ~]# mkdir -p /data/nfs
[root@node1 ~]# mount -t nfs 172.16.0.42:/data/nfs /data/nfs
[root@node1 ~]# echo "hello nfs server" > /data/nfs/test.txt
[root@node1 ~]# cat /data/nfs/test.txt
hello nfs server
[root@node1 ~]#
[root@node1 ~]#
#node2节点运行日志
[root@node2 ~]# cat /data/nfs/test.txt
hello nfs server
[root@node2 ~]#
#master节点运行日志
[root@master ~]# cat /data/nfs/test.txt
hello nfs server
[root@master ~]#
11、Ingress
Service的统一网关入口
一张图看懂Ingress
其实我觉得这个Ingress应该单开一页来讲的,但如果是自己学习的话,通过service访问pod就足够了,其次参考存储抽象引用的信息,,,对不起,是我偷懒了,哈哈哈
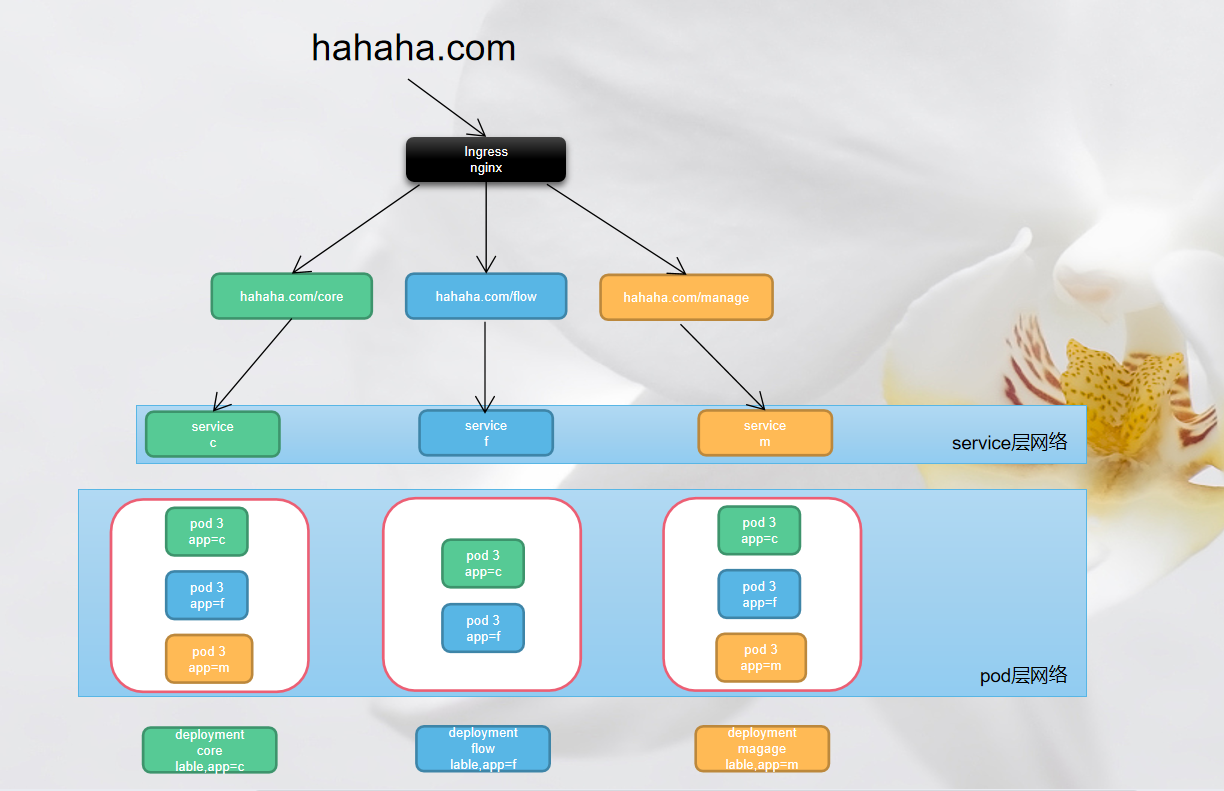
11.1 定义和作用
-
定义
Ingress是Kubernetes中的一种资源对象,用于管理对集群中服务(Service)的外部访问。它允许从集群外部访问集群内的服务,提供了一种统一的、基于HTTP/HTTPS的路由机制。 -
作用
路由规则:能够依据不同的域名、路径等,将外部请求路由至不同的后端服务。例如,依据hahaha.com/core、hahaha.com/flow、hahaha.com/manage等不同路径,把请求转发到对应的服务。
负载均衡:在多个相同服务的副本(如多个Pod)之间进行流量分配,达成负载均衡。
11.2 Ingress资源与其他组件的关系
-
与Service的关系
Ingress通过规则将请求路由到对应的Service,Service再把请求转发到具体的Pod。就像在相关图中,Ingress依据不同的路径(hahaha.com/core等),将请求路由到对应的service(如service c、service f、service m),这些service接着将请求转发到下层的Pod。 -
与Pod的关系
最终请求会抵达运行具体应用的Pod,Pod是实际处理业务逻辑之处。
11.3 Ingress的工作原理
-
基于规则的路由
域名和路径规则:可基于不同的域名(如hahaha.com)和路径(如/core、/flow、/manage)来设定路由规则。当外部请求到达Ingress时,Ingress会依照这些规则,将请求转发到相应的Service。
示例:在图中,当有请求访问hahaha.com/core时,Ingress会把请求转发到service c,然后service c再将请求转发到对应的pod 3 app=c等Pod。 -
负载均衡机制
流量分配:当存在多个相同服务的Pod副本时(如多个pod 3 app=c),Ingress会把请求均匀分配到这些Pod上,实现负载均衡,提升系统的可用性和性能。
11.4 使用场景和优势
-
使用场景
微服务架构:在微服务架构里,大量服务需要对外暴露,Ingress能够提供统一的入口和路由规则,便于管理外部对这些微服务的访问。
多环境部署:例如开发、测试、生产等不同环境,借助Ingress可便捷地配置不同的路由规则和访问策略。 -
优势
简化管理:提供一种集中式的、声明式的方式来管理外部对集群内服务的访问,相较于直接暴露每个服务,管理更为便捷。
灵活的路由规则:能够依据复杂的业务需求,定义灵活的域名、路径等路由规则,满足不同的应用场景。
八、常用命令
1、集群信息
| 命令 | 说明 |
|---|---|
kubectl cluster-info | 查看集群基本信息(API Server、CoreDNS等组件地址) |
kubectl config view | 查看当前kubectl配置 |
2、节点管理
| 命令 | 说明 |
|---|---|
kubectl get componentstatuses | 查看核心组件(如etcd、scheduler)状态 |
kubectl get nodes -o wide | 查看节点列表(含IP、资源使用、角色等详细信息) |
kubectl describe node <node-name> | 查看指定节点的详细描述(资源分配、污点、事件等) |
kubectl drain <node-name> --ignore-daemonsets | 排空节点(驱逐Pod,准备维护) |
kubectl cordon/uncordon <node-name> | 标记节点不可调度/恢复调度 |
3、命名空间
| 命令 | 说明 |
|---|---|
kubectl get ns | 查看所有命名空间 |
kubectl create ns <namespace> | 创建新命名空间 |
kubectl delete ns <namespace> | 删除命名空间(连带删除资源) |
4、Pod操作
| 命令 | 说明 |
|---|---|
kubectl get pods -A | 查看所有命名空间的Pod |
kubectl describe pod <pod-name> | 查看Pod详细信息(事件、状态、容器等) |
kubectl logs <pod-name> -f | 实时查看Pod日志(加-c指定多容器Pod的容器) |
kubectl exec -it <pod-name> -- sh | 进入Pod容器执行命令 |
kubectl delete pod <pod-name> --force --grace-period=0 | 强制删除Terminating状态的Pod |
5、扩展命令
5.1 部署管理
| 命令 | 说明 |
|---|---|
kubectl get deployments | 查看所有Deployment |
kubectl scale deployment <name> --replicas=3 | 扩缩容Deployment |
kubectl rollout status deployment/<name> | 查看滚动更新状态 |
kubectl rollout undo deployment/<name> | 回滚到上一个版本 |
5.2 服务管理
| 命令 | 说明 |
|---|---|
kubectl get svc | 查看所有Service |
kubectl expose deployment <name> --port=80 | 创建Service暴露部署 |
5.3 存储管理
| 命令 | 说明 |
|---|---|
kubectl get pv | 查看持久卷 |
kubectl get pvc | 查看持久卷声明 |
5.4 故障排查
| 命令 | 说明 |
|---|---|
kubectl get events --sort-by=.metadata.creationTimestamp | 按时间排序查看事件日志 |
kubectl top nodes | 查看节点资源使用率 |
kubectl top pods | 查看Pod资源使用率 |
6、使用提示:
- 缩写支持:如 po(Pod)、deploy(Deployment)、svc(Service)等
- 字段过滤:
kubectl get pods --field-selector status.phase=Running # 过滤运行中的 Pod
kubectl get pods -l app=nginx # 按标签筛选
- 输出格式化:
kubectl get pods -o json # JSON 格式输出
kubectl get pods -o wide # 显示更列(如节点、IP)
kubectl get pods -o custom-columns=NAME:.metadata.name,STATUS:.status.phase # 自定义列
接受各位大佬批阅时刻
我的天呐,终于在csdn写完了一遍技术文档,用了整整一天的时间。写到吐,什么时候csdn能像WPS只能文档一样写个文章就好了。这几年翻阅了无数大神的笔记,可我也想留下点什么,证明一下我真的来过。文章杂七杂八的也凑完了,算不上原创,毕竟确实有学习别人的风格,但这也是我前几年的积累,一时间还真找不到出处,要是有雷同,肯定是我抄袭了,请告诉我地址,我加一下转载。
这个文档真就只写到了皮毛,如果你想学习,想入门k8s,那应该够用,想深入的话我这个不行,等有时间再深究一下吧,文档不足的地方我再填充一下。先这样哈
大千网络世界,你我皆为电子浮游

















 2912
2912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









