







点击「京东数科技术说」可快速关注

「摘要」数据治理 (Data Governance) [1]作为一种数据管理的重要一环,主要目的在于保证数据在整个生命周期内的高质量性。数据治理的核心包括:数据的可用性 (Availability),易用性 (Usability),一致性 (Consistency),完整性 (Integrity) 和安全性 (Security)。数据的安全性作为关键的一项,旨在保护数据中敏感和隐私数据,因此对于数据中敏感和隐私信息的识别至关重要。利用机器学习算法对敏感字段识别不仅能够提高识别的准确率,同时也能极大的提高识别的效率,从而帮助数据仓库运营人员高效地完成敏感数据的存储策略制定和数据落库。
本文实现了一种基于 Wide & Deep 网络和 TextCNN 的敏感字段识别算法,文章分为如下 3 个部分:
数据探索性分析
Wide & Deep 网络和 TextCNN
敏感字段识别模型
01
数据探索性分析
首先,我们对接入整个数据仓库贴源层中的所有表所有字段的敏感类型 (也就是模型的目标变量Y)进行了统计,其中敏感类型的字段占全部字段 2% 左右,主要的敏感信息类型包括:姓名,身份证号,手机号,固定电话号,银行卡号,邮箱等。可以看出这一个样本极度不均衡的问题。
其次,我们对于所能获取到的用于判断一个字段敏感类型的信息 (也就是模型的自变量X)统计如下:
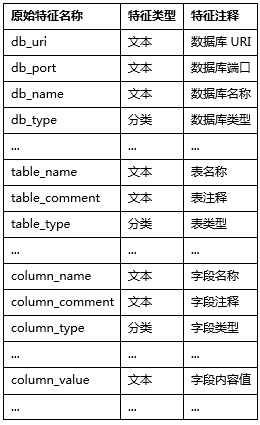
对于上表中的原始特征,通过统计分析确定相应的数据预处理方法和参数,从而衍生出更多的特征。例如,对于数据库名称 (db_name),我们衍生出数据库名称长度 (db_name_len)特征,并对其在是否为敏感字段上的分布统计如下:
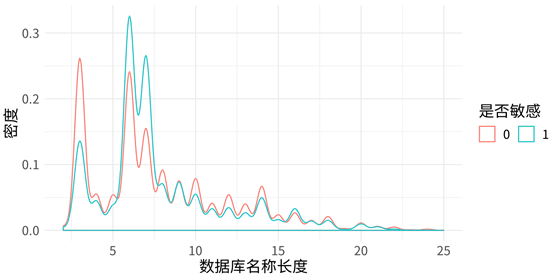
从上图中不难看出,数据库名称长度对于字段是否为敏感具有一定的区分性。从字段类型 (column_type) 角度分析,不同字段类型的敏感和非敏感字段占比如下:
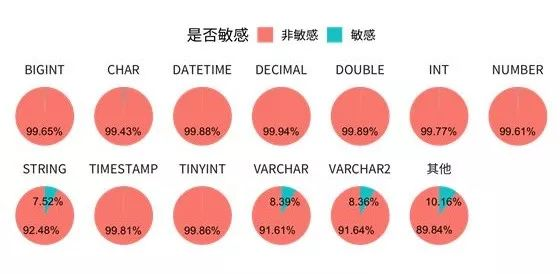
最终,通过数据预处理,特征衍生等多种手段得到模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1744
1744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









