







 本文介绍了如何在京东集团EA的P40机器上利用ChatGLM2-6B大模型进行LORA(低秩适应大型语言模型)微调,包括模型性能提升、微调环境配置、LORA原理和实际操作步骤。作者郑少强强调领域内prompt构建的重要性。
本文介绍了如何在京东集团EA的P40机器上利用ChatGLM2-6B大模型进行LORA(低秩适应大型语言模型)微调,包括模型性能提升、微调环境配置、LORA原理和实际操作步骤。作者郑少强强调领域内prompt构建的重要性。
背景:
目前,大模型的技术应用已经遍地开花。最快的应用方式无非是利用自有垂直领域的数据进行模型微调。chatglm2-6b在国内开源的大模型上,效果比较突出。本文章分享的内容是用chatglm2-6b模型在集团EA的P40机器上进行垂直领域的LORA微调。
一、chatglm2-6b介绍
github: https://github.com/THUDM/ChatGLM2-6B
chatglm2-6b相比于chatglm有几方面的提升:
1. 性能提升: 相比初代模型,升级了 ChatGLM2-6B 的基座模型,同时在各项数据集评测上取得了不错的成绩;
2. 更长的上下文: 我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练;
3. 更高效的推理: 基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%;
4. 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
二、微调环境介绍
2.1 性能要求
推理这块,chatglm2-6b在精度是fp16上只需要14G的显存,所以P40是可以cover的。
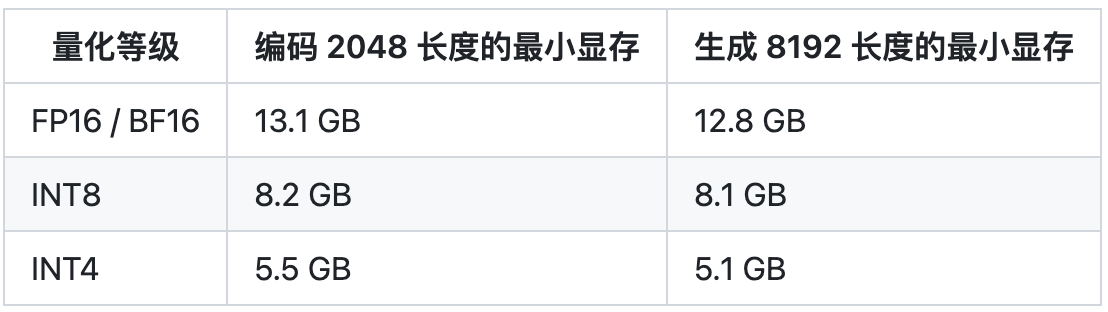
EA上P40显卡的配置如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1710
1710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









