







 本文介绍了ApacheFlink的SQL方言FlinkSQL,其支持标准SQL处理流式和批处理数据,包括窗口操作和各种连接器的使用。同时,DataGen功能在测试中的重要性被详细说明,如性能测试、边界条件测试和数据完整性测试。
本文介绍了ApacheFlink的SQL方言FlinkSQL,其支持标准SQL处理流式和批处理数据,包括窗口操作和各种连接器的使用。同时,DataGen功能在测试中的重要性被详细说明,如性能测试、边界条件测试和数据完整性测试。
什么是 Flinksql
Flink SQL 是基于 Apache Calcite 的 SQL 解析器和优化器构建的,支持ANSI SQL 标准,允许使用标准的 SQL 语句来处理流式和批处理数据。通过 Flink SQL,可以以声明式的方式描述数据处理逻辑,而无需编写显式的代码。使用 Flink SQL,可以执行各种数据操作,如过滤、聚合、连接和转换等。它还提供了窗口操作、时间处理和复杂事件处理等功能,以满足流式数据处理的需求。
Flink SQL 提供了许多扩展功能和语法,以适应 Flink 的流式和批处理引擎的特性。他是Flink最高级别的抽象,可以与 DataStream API 和 DataSet API 无缝集成,利用 Flink 的分布式计算能力和容错机制。
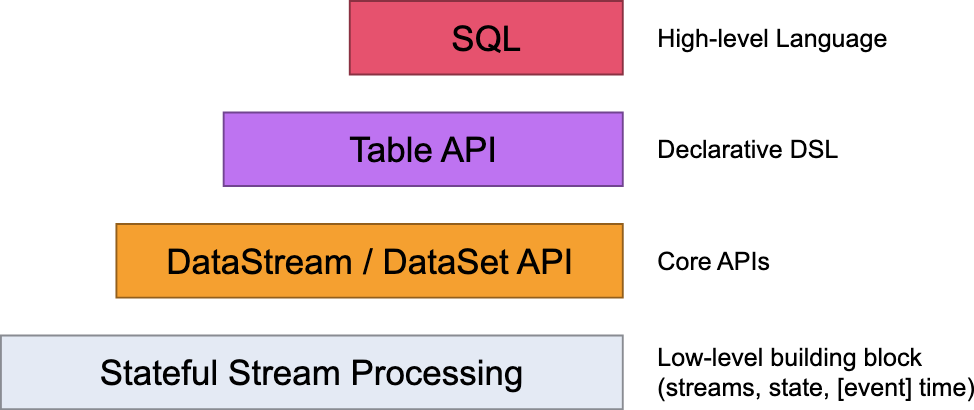
使用 Flink SQL处理数据的基本步骤:
-
定义输入表:使用 CREATE TABLE 语句定义输入表,指定表的模式(字段和类型)和数据源(如 Kafka、文件等)。
-
执行 SQL 查询:使用 SELECT、INSERT INTO 等 SQL 语句来执行数据查询和操作。您可以在 SQL 查询中使用各种内置函数、聚合操作、窗口操作和时间属性等。
-
定义输出表:使用 CREATE TABLE 语句定义输出表,指定表的模式和目标数据存储(如 Kafka、文件等)。
-
提交作业:将 Flink SQL 查询作为 Flink 作业提交到 Flink 集群中执行。Flink会根据查询的逻辑和配置自动构建执行计划,并将数据处理任务分发到集群中的任务管理器进行执行。
总而言之,我们可以通过Flink SQL 查询和操作来处理流式和批处理数据。它提供了一种简化和加速数据处理开发的方式,尤其适用于熟悉 SQL 的开发人员和数据工程师。
什么是 connector
Flink Connector 是指用于连接外部系统和数据源的组件。它允许 Flink 通过特定的连接器与不同的数据源进行交互,例如数据库、消息队列、文件系统等。它负责处理与外部系统的通信、数据格式转换、数据读取和写入等任务。无论是作为输入数据表还是输出数据表,通过使用适当的连接器,可以在 Flink SQL 中访问和操作外部系统中的数据。目前实时平台提供了很多常用的连接器:
例如:
-
JDBC :用于与关系型数据库(如 MySQL、PostgreSQL)建立连接,并支持在 Flink SQL 中读取和写入数据库表的数据。
-
JDQ :用于与 JDQ 集成,可以读取和写入 JDQ 主题中的数据。
-
Elasticsearch :用于与 Elasticsearch 集成,可以将数据写入 Elasticsearch 索引或从索引中读取数据。
-
File Connector:用于读取和写入各种文件格式(如 CSV、JSON、Parquet)的数据。
-
…
还有如HBase、JMQ4、Doris、Clickhouse,Jimdb,Hive等,用于与不同的数据源进行集成。通过使用 Flink SQL Connector,我们可以轻松
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









