







目录
一.Terraform功能简介
Terraform是IT 基础架构自动化编排工具,它的口号是 "Write,Plan, and create Infrastructure as Code", 基础架构即代码。
怎么理解这句话,我们先假设在没有Terraform的年代我们是怎么操作云服务。
- 方式一:直接登入到云平台的管控页面,人工点击按钮、键盘敲入输入参数的方式来操作,这种方式对于单个或几个云服务器还可以维护的过来,但是当云服务规模达到几十几百甚至上千以后,明显这种方式对于人力来说变得不再现实,而且容易误操作。
- 方式二:云平台提供了各种SDK,将对云服务的操作拆解成一个个的API供使用厂商通过代码来调用。这种方式明显好于方式一,使大批量操作变得可能,而且代码测试通过后可以避免人为误操作。但是随之带来的问题是厂商们需要专业的开发人员(Java、Python、Php、Ruby等),而且对复杂云平台的操作需要写大量的代码。
- 方式三:云平台提供了命令行操作云服务的工具,例如AWS CLI,这样租户厂商不再需要软件开发人员就可以实现对平台的命令操作。命令就像Sql一样,使用增删改查等操作元素来管理云。
- 方式四:Terraform主角登场,如果说方式三中CLI是命令式操作,需要明确的告知云服务本次操作是查询、新增、修改、还是删除,那么Terraform就是目的式操作,在本地维护了一份云服务状态的模板,模板编排成什么样子的,云服务就是什么样子的。对比方式三的优势是我们只需要专注于编排结果即可,不需要关心用什么命令去操作。
Terraform的意义在于,通过同一套规则和命令来操作不同的云平台(包括私有云)。
二.Terraform知识准备:
- 核心文件有2个,一个是编排文件,一个是状态文件
- main.tf文件:是业务编排的主文件,定制了一系列的编排规则,后面会有详细介绍。
- terraform.tfstate:本地状态文件,相当于本地的云服务状态的备份,会影响terraform的执行计划。
如果本地状态与云服务状态不一样时会怎样?
这个大家不需要担心,前面介绍过Terraform是目的式的编排,会按照预设结果完成编排并最终同步更新本地文件。
- Provider:Terraform定制的一套接口,跟OpenStack里Dirver、Java里Interface的概念是一样的,阿里云、AWS、私有云等如果想接入进来被Terraform编排和管理就要实现一套Provider,而这些实现对于Terraform的顶层使用者来说是无感知的。
三.Terraform安装:
- 方式一(推荐):
brew install terraform
不用配置环境变量,brew自动帮我们配置好了。在cd /usr/local/bin 可以看到软连接。
本质是下载二进制的文件安装到linux中,然后通过terraform命令来操作。
安装后需要在path中配置terraform:
export PATH=$PATH:/path/to/dir
export PATH=$PATH:/home/terraform
source ~/.bashrcsource只是让配置立刻生效,如果要永久生效需要直接修改文件
- 方案1:在/etc/profile文件中添加变量【对所有用户生效(永久的)】
- 方案2:在用户目录下的.bash_profile文件中增加变量【对单一用户生效(永久的)】
四.Terraform的基本命令:
- 1,mkdir一个干净的工作目录,为后续操作做准备,该目录就像git的仓库,或者像软件开发中的workspace。
- 2,需要创建一个.tf文件,指定provider等信息,工作目录下需要有至少一个tf文件,否则后续命令无法进行。
- 3,执行terraform init命令,就像git init一样,对当前目录做初始化,下载tf中的provider,并喂后续的操作准备必要的环境条件。
- 4,terraform plan,预览执行计划,不是必须的,但是强烈建议,好明白这次要把云服务弄成什么样子。Ps:该命令在后期版本与apply合并成一个,所以请根据自己的版本来使用plan命令。
- 5,terraform apply,真正执行编排计划
- 6,terraform show,展示现在状态。
- 6,terraform destroy,销毁云服务,将tf中的云服务清理干净
4.1 Terraform的编排
先看个简单的官网例子:
provider "aws" {
access_key = "ACCESS_KEY_HERE"
secret_key = "SECRET_KEY_HERE"
region = "us-east-1"
}
resource "aws_instance" "example" {
ami = "ami-2757f631"
instance_type = "t2.micro"
}Provider说明是个AWS的provider,剩下的鉴权和区域比较好理解;请注意provider的名字必须严格按照terraform的规则,不是你随便乱填的。例如阿里云对应的provider名称是“alicloud”,你如果写个“aliyun”是会出错的。
Resource是在定义资源,第一个属性aws_instance说明是个aws的实例,通过命名规则中的前缀来指明provider;第二个属性example是本resource的name;ami指明用哪个镜像来启动实例;instance_type指定的是实例的“规格”,在云服务里定义了不同的类型来代表着服务器不同的配置(CPU、内存、磁盘等硬件资源)。
Terrafomr执行时的output如下图:
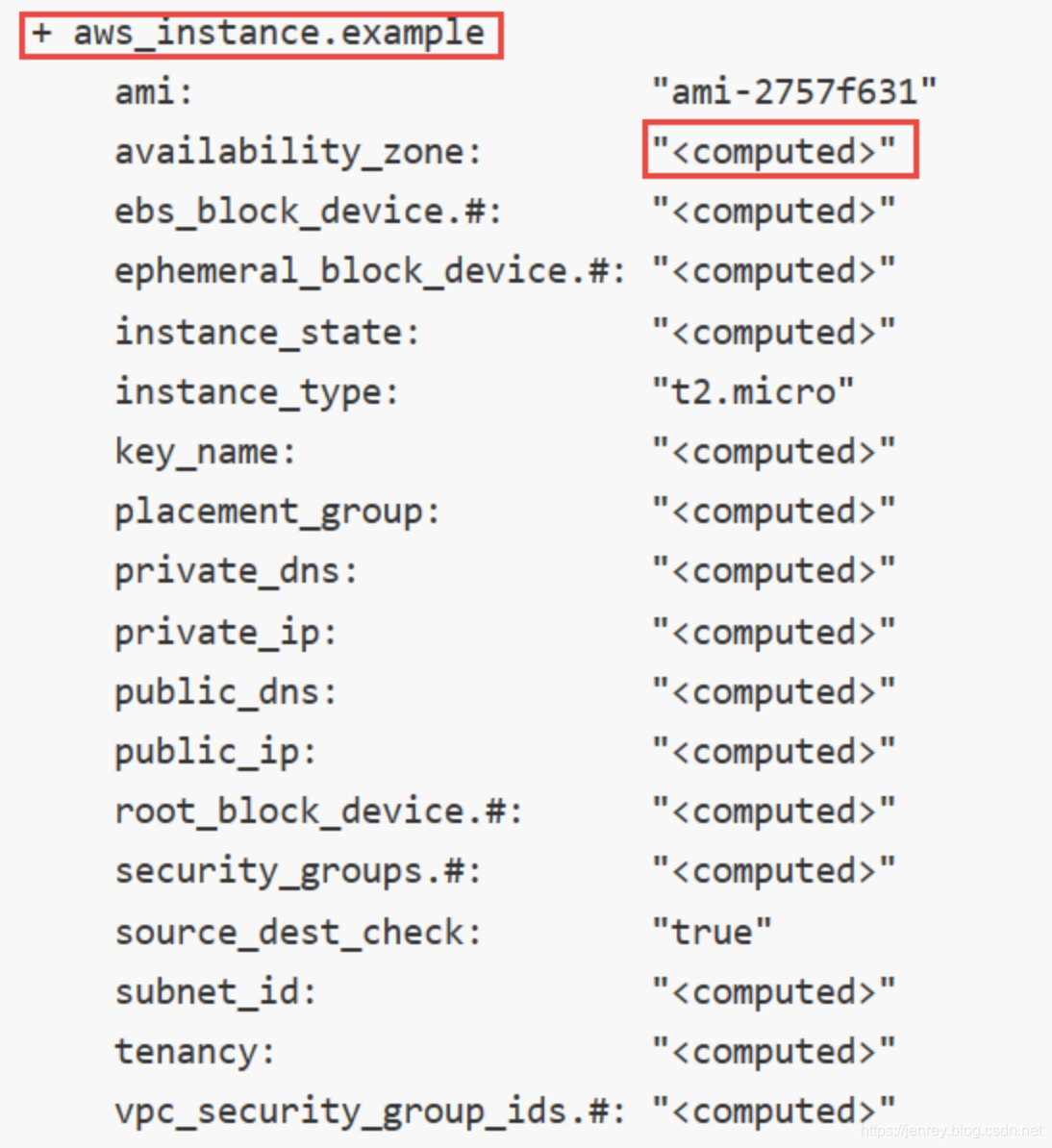
号代表的是新增操作,与使用git一样,同理如果看到-号那就是要在云上做删除操作,修改操作+-会同时出现,本质上在云上会先删除再添加。像ami、instance_type我们显示给定的,或者说本地仓库文件已知的属性,会直接在右边显示出来;其他未知的显示的是computed,代表的是要在云上操作结束后才能知道。
4.2 Terrafrom的执行计划:
有过Spark基础的开发人员都知道一个概念DAG(有向无环图),是为了最大程度地并行同时也要保证各任务间的依赖性。Terraform也是个并行执行的框架,而任务间的依赖性是通过显示依赖和隐式依赖来实现的。
如基于上面的tf基础上又配置了一个资源:
resource "aws_eip" "ip" {
instance = "${aws_instance.example.id}"
}那么在创建aws_eip.id这个资源时由于里面的instance需要指定aws_instance.example的id,而aws_instance.example的id只有实例创建后才能获得,所以这就形成了一个隐式的依赖,执行计划就要先执行aws_instance.example这个resource再执行aws_eip.ip这个resource。
再看下面这个例子:
resource "aws_instance" "example" {
ami = "ami-2757f631"
instance_type = "t2.micro"
depends_on = ["aws_s3_bucket.example"]
}
resource "aws_s3_bucket" "example" {
bucket = "terraform-getting-started-guide"
acl = "private"
}在aws_instance.example这个resource创建时通过depends_on属性显示的指定了依赖,所以先执行aws_s3_bucket.example这个执行计划再回头来创建这个实例。
如果resource间没有依赖,terraform会并行的发送任务到云端完成任务。
如果你想在resource成功创建后执行某些操作,就需要用到Provisioner配置,示例:
resource "aws_instance" "example" {
ami = "ami-b374d5a5"
instance_type = "t2.micro"
provisioner "local-exec" {
command = "echo ${aws_instance.example.public_ip} > ip_address.txt"
}
}当resource创建完毕后可以在ip_address.txt文件中看到该aws的ip地址。
Provisioner的使用会带来一个问题,如果实例创建成功但是provisioner失败会如何?Terraform并不具有关系型数据库那样的事务,一定要保证一起成功或失败,如果发生这种情况,resource的实例会被成功创建但是状态会被置为“tainted”污染的,是为了告知云使用者该服务并不是安全的。当再次执行resouce计划时Terraform并不会在原来基础上retry失败的provisioner,而是整个resource铲掉重新执行一边编排。
4.3 Terraform的出入参变量:
有些参数我们不想通过硬编码的方式写入到tf中,我们就会采用变量方式来搞定这种场景。
一般我们会把所有的变量都单独拿到一个tf文件里去声明,例如variables.tf,虽然不是必须要命名成variables.tf,但是我们约定俗成这么做。
Variables.tf内容如下:
variable "access_key" {}
variable "secret_key" {}
variable "region" {
default = "us-east-1"
}很好理解,region我们给了默认值
在其他tf中引用方式如下:
provider "aws" {
access_key = "${var.access_key}"
secret_key = "${var.secret_key}"
region = "${var.region}"
}也很理解,那么剩下的问题是如何在使用时设定这些变量?
- 方式一:命令参数设置
$ terraform apply -var 'access_key=foo' -var 'secret_key=bar'- 方式二:默认参数文件
Terraform默认会加载terraform.tfvars or *.auto.tfvars的文件为初始化参数的文件,文件内容是键值对的方式:
access_key = "foo"
secret_key = "bar"- 方式三:命令制定参数文件
如果不按照方式二的命名规则,而是自己自定义文件名,可以采用方式一和方式二结合的方式指定参数文件:
$ terraform apply -var-file="secret.tfvars" -var-file="production.tfvars"- 方式四:操作用户的环境变量中去获取
terraform会环境变量path中找TF_VAR_开头的变量并把后面的内容映射成自己的变量参数,本方法不推荐。
- 方式五:什么都不预配置,执行Terraform时遇到没有赋值的变量会在控制台给出提示让操作员直接输入。该方式不推荐,但是当输入密码等场景时从安全角度来说可以考虑使用。
除开String类型变量,Terraform还支持List和Map类型:
- List的定义:
variable "cidrs" { type = "list" }
List的赋值:
cidrs = [ "10.0.0.0/16", "10.1.0.0/16" ]- Map的定义和赋值:
variable "amis" {
type = "map"
default = {
"us-east-1" = "ami-b374d5a5"
"us-west-2" = "ami-4b32be2b"
}
}对Map的使用时会调用Terraform的内部函数:
resource "aws_instance" "example" {
ami = "${lookup(var.amis, var.region)}"
instance_type = "t2.micro"
}Lookup就是从amis这个map变量中根据region这个变量去get。
学完Terraform的入参,Terraform的出参就变得很简单了。
4.4 Terraform的出参
把一次编排看成Oracle的一个存储过程,Terraform的出参就像是存过的产出,开发人员可以在编排时定义output出参来指定自己关心的内容,该内容会在任务执行的日志中高亮显示,而且在任务执行完毕后我们可以通过terrafomr output var_name的方式查看参数结果。
出参声明:
output "ip" {
value = "${aws_eip.ip.public_ip}"
}
生产级应用我们往往将Terraform的state文件维护在云端或远程服务器,这样既可以保证高可用性,也可以方便多名编排人员共同维护。
需要添加以下配置:
terraform {
backend "consul" {
address = "demo.consul.io"
path = "getting-started-RANDOMSTRING"
lock = false
}
}这样在执行terraform init时就会在本地和remote端各维护一份状态文件。
Terraform在Iaas基础维护方面的侧重点,只是对云平台实例级别的管理,如果要对实例内部进行更复杂的编排需要配合ansible组件。














 4932
4932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









