







Spark Streaming运行kafka数据源
实验内容
了解kafka的基本知识,对kafka进行安装和基础环境配置
2. 安装和准备flume
3. 编译相关测试代码,测试环境,对word count进行spark streaming
Kafka基本介绍
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
Kafka是非常流行的日志采集系统,可以作为DStream的高级数据源,也可以作为Flume的Sink端接收来自Flume的数据。本实验同时用到这两种功能。
Kafka的使用依赖于zookeeper,安装Kafka前必须先安装zookeeper.
实验要求
- 文档格式工整规范,一目了然。
- 文字描述与截图说明相结合,清清楚楚。
实验步骤
一、Ubuntu 系统安装Kafka
访问Kafka官方下载页面,下载稳定版本0.10.1.0的kafka.此安装包内已经附带zookeeper,不需要额外安装zookeeper.按顺序执行如下步骤:
1. cd ~/下载
2. sudo tar -zxf kafka_2.11-0.10.1.0.tgz -C /usr/local
3. cd /usr/local
4. sudo mv kafka_2.11-0.10.1.0/ ./kafka
5. sudo chown -R hadoop ./kafka
此处我选择的是kafa 2.11-2.0.1.tgz,下载后需要解压:

核心概念
下面介绍Kafka相关概念,以便运行下面实例的同时,更好地理解Kafka.
1.Broker Kafka集群包含一个或多个服务器,这种服务器被称为broker
2. Topic 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
3. Partition Partition是物理上的概念,每个Topic包含一个或多个Partition.
4. Producer 负责发布消息到Kafka broker
5. Consumer 消息消费者,向Kafka broker读取消息的客户端。
6. Consumer Group 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
测试简单实例
接下来在Ubuntu系统环境下测试简单的实例。按顺序执行如下命令:
1. # 进入kafka所在的目录
2. cd /usr/local/kafka
3. bin/zookeeper-server-start.sh config/zookeeper.properties

Shell 命令
命令执行后不会返回Shell命令输入状态,zookeeper就会按照默认的配置文件启动服务,请千万不要关闭当前终端.启动新的终端,输入如下命令:
1. cd /usr/local/kafka
2. bin/kafka-server-start.sh config/server.properties
3.
](https://img-blog.csdnimg.cn/20190510144058730.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0pJQVlJTllB,size_16,color_FFFFFF,t_70)
Shell 命令
kafka服务端就启动了,请千万不要关闭当前终端。启动另外一个终端,输入如下命令:
1. cd /usr/local/kafka
2. bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic dblab

Shell 命令
topic是发布消息发布的category,以单节点的配置创建了一个叫dblab的topic.可以用list列出所有创建的topics,来查看刚才创建的主题是否存在。
1. bin/kafka-topics.sh --list --zookeeper localhost:2181

Shell 命令
可以在结果中查看到dblab这个topic存在。接下来用producer生产点数据:
1. bin/kafka-console-producer.sh --broker-list localhost:9092 --topic dblab
Shell 命令
并尝试输入如下信息:
hello hadoop
hello xmu
hadoop world
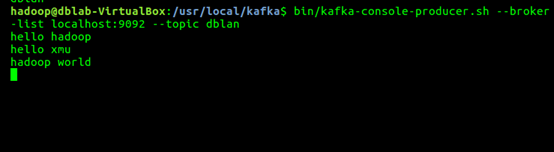
然后再次开启新的终端或者直接按CTRL+C退出。然后使用consumer来接收数据,输入如下命令:
1. cd /usr/local/kafka
2. bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic dblab --from-beginning
Shell 命令

便可以看到刚才产生的三条信息。说明kafka安装成功。
二、Flume的安装和准备
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume主要由3个重要的组件构成:
Source:完成对日志数据的收集,分成transtion 和 event 打入到channel之中。
Channel:主要提供一个队列的功能,对source提供中的数据进行简单的缓存。
Sink:取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。
Flume逻辑上分三层架构:agent,collector,storage
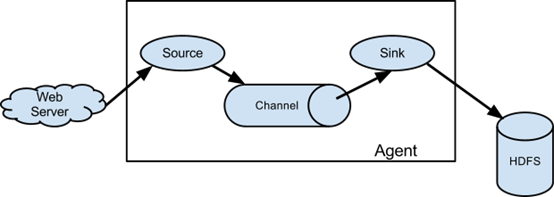
agent用于采集数据,agent是flume中产生数据流的地方,同时,agent会将产生的数据流传输到collector。
collector的作用是将多个agent的数据汇总后,加载到storage中。
storage是存储系统,可以是一个普通file,也可以是HDFS,HIVE,HBase等。
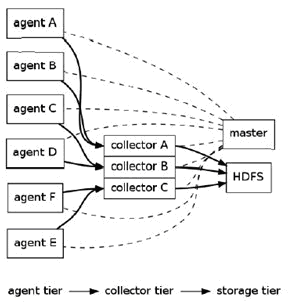
Flume的架构主要有一下几个核心概念:
Event:一个数据单元,带有一个可选的消息头
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 712
712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









