







 本文探讨如何使用Python处理各种文本信息,包括从网络下载、分割文档、分词、提取特征词,以及HTML和本地文件的处理。通过实例演示了正则表达式、NLTK库和BeautifulSoup在文本处理中的应用。
本文探讨如何使用Python处理各种文本信息,包括从网络下载、分割文档、分词、提取特征词,以及HTML和本地文件的处理。通过实例演示了正则表达式、NLTK库和BeautifulSoup在文本处理中的应用。
摘要:
- 学习目的:
文本来源各种各样,除了已知的nltk中自带的语料库,我们本地及网络上也有很多的文本信息。为了能处理各种文本信息,我们这章学习:
(1)编写程序处理各种文本信息及输出至一个文件中。
(2)分割文档内信息,包括词和标点的划分,更深一点是进行分词及特性词的提取。
-
涉及内容:
Python、字符串、正则表达式、不同格式文本处理(TXT/HTML)等… -
前提导入:
>>> import nltk, re, pprint
>>> from nltk import word_tokenize
3.1 从本地及网络访问文本
1.网上书籍
>>>import nltk,re,pprint
>>>from nltk import word_tokenize
>>>from urllib import request
>>>url="http://www.gutenberg.org/cache/epub/8254/pg8254.html"
>>>response=request.urlopen(url)
>>>contents=response.read().decode('utf8')
#此时电子书中的内容就到了contents里面,让我们来看一下文本属性
此过程可能需要等待一会,不要着急
>>>type(contents)
<class 'str'> #类型为字符串
>>>len(contents)
89770
>>>contents[3110:3200]
'Lord gave Jehoiakim king of Judah into his hand,\r\n with part of the vessels of the '
- 分词:
我们看到很多的*\r和*\n*,我们目的是将字符串分解为词和标点。
>>>tokens=word_tokenize(contents)
>>>type(tokens)
<class 'list'>
>>>len(tokens)
17878
>>>tokens[8000:8020]
['they', 'cast', 'them', 'into', 'the', 'den', 'of', 'lions', ',', 'them', ',', 'their', 'children', ',', 'and', 'their', 'wives', ';', 'and', 'the']
- 提取文本内容:
首先将url里文本内容放进一个NLTK创建的文本
>>>text=nltk.Text(tokens)
>>>type(text)
<class 'nltk.text.Text'>
>>>text[1024:1062]
['of', 'the', 'prince', 'of', 'the', 'eunuchs', '.', '001:010', 'The', 'prince', 'of', 'the', 'eunuchs', 'said', 'to', 'Daniel', ',', 'I', 'fear', 'my', 'lord', 'the', 'king', ',', 'who', 'has', 'appointed', 'your', 'food', 'and', 'your', 'drink', ':', 'for', 'why', 'should', 'he', 'see']
>>>text.collocations()
Project Gutenberg; meta name=; wise men; burning fiery; make known;
fiery furnace; Small Print; shall come; burnt offering; golden image;
PROJECT GUTENBERG; PROJECT GUTENBERG-tm; Literary Archive; Anointed
One; public domain; came near; seven times; Archive Foundation; shall
stand; two horns
#我们通过gutenberg中文本可以发现,文本开头都有PROJECT GUTENBERG
gutenberg文本开头都有PROJECT GUTENBERG

gutenberg文本结尾都有END OF THE PROJUECT
利用这点我们找出开头和结尾所在的位置:
>>>contents.find('Project Gutenberg')
1202
>>>contents.rfind('END OF THE PROJECT GUTENBERG')
74593
#rfind是反向查找,用find也行
>>>text[1202:74593]
Squeezed text(1620 lines)
#即去除开头和结尾,得到内容部分
2.处理HTML
网络上文本多为HTML形式,可采用本地下载或用Python来解决。
>>> from urllib import request
>>> url="https://www.runoob.com/python3/python3-tutorial.html"
>>> html=request.urlopen(url).read().decode('utf8')
>>> html[100:200]
'\n <meta property="qc:admins" content="465267610762567726375" />\n\t<meta name="viewport" content="wid'
>>>
采用print得到的是HTML全部内容
>>> print(html)
Squeezed text(1383 lines)
BeautifulSoup
用它我们可以很方便地提取出 HTML 或 XML 标签中的内容
>>> from nltk import word_tokenize
>>> from urllib import request
>>> from bs4 import BeautifulSoup
>>> url="https://www.runoob.com/python3/python3-tutorial.html"
>>> html=request.urlopen(url).read().decode('utf8')
>>> raw=BeautifulSoup(html).get_text()
>>> tokens=word_tokenize(raw)
>>> tokens
当然,这些还是无法滤除不需要的内容,故可以自定义感兴趣字符进行操作:
>>> tokens=tokens[110:390]
>>> import nltk
>>> text=nltk.Text(tokens)
>>> text
<Text: PyMySQL ) Python3 网络编程 Python3 SMTP发送邮件 Python3 多线程...>
>>> text.concordance('Python3')
Displaying 10 of 10 matches:
PyMySQL ) Python3 网络编程 Python3 SMTP发送邮件 Python3 多线程 P
PyMySQL ) Python3 网络编程 Python3 SMTP发送邮件 Python3 多线程 Python3 XML 解析
SQL ) Python3 网络编程 Python3 SMTP发送邮件 Python3 多线程 Python3 XML 解析 Python3 JSON Pyt
3 网络编程 Python3 SMTP发送邮件 Python3 多线程 Python3 XML 解析 Python3 JSON Python3 日期和时间 P
SMTP发送邮件 Python3 多线程 Python3 XML 解析 Python3 JSON Python3 日期和时间 Python3 内置函数 Pyt
on3 多线程 Python3 XML 解析 Python3 JSON Python3 日期和时间 Python3 内置函数 Python MongoDB P
3 XML 解析 Python3 JSON Python3 日期和时间 Python3 内置函数 Python MongoDB Python uWSGI 安装
函数 Python MongoDB Python uWSGI 安装配置 Python3 解释器 Python 3 教程 Python 的 3.0 版本,常被称
hello.py 文件中并使用 python 命令执行该脚本文件。 $ python3 hello.py 以上命令输出结果为: Hello , World !
Python 3.6.3 中文手册 Python 2.X 版本的教程 Python3 解释器 4 篇笔记 写笔记 # 4 helloworld 229 *
>>>
feedparser
安装采用pip install feedparser
feedparser是一个Python的Feed解析库,能处理RSS ,CDF,Atom,。让我们可从任何 RSS 或 Atom 订阅源得到标题、链接和文章的条目。
>>> log=feedparser.parse("http://feed.cnblogs.com/blog/sitehome/rss")
>>> log['feed']['title']
'博客园_首页'
>>> type(log.entries)
<class 'list'>
>>> len(log.entries)
20
>>> [e.title for e in log.entries][:5]
['程序员需要有学会讲故事 - 袁吴范pointers', 'linux DRM GEM 笔记 - -Yaong-', 'Mac mini M1使用简单体验(编程、游戏、深度学习) - 老潘博客', '在.NET Core 中使用 FluentValidation 进行规则验证 - SpringLeee', 'sklearn中的pipeline - 快到皖里来']
>>> log.entries[0].summary
'今天儿子吵着要我给他讲故事,想了想脑子中的故事少得可怜,狼来了的故事,已经讲了N遍了。只能找了本寓言故事书,敷衍了事 儿子闹过之后,慢慢地我静下心来,陷入了沉思。突然感受到了一丝恐惧。这个世界的本质,就是靠各种故事构建一个看似真实的世界。 我们从小都是听着各式各样的故事长大的,故事是我们了解世界的最'
3. 读取本地文件
>>> f=open('123.txt')
>>> a=f.read()
若出现错误,无法打开,用如下函数查找Python试图打开的地址,再将其文本放到此目录.
>>> import os
>>> os.listdir('.')
Python strip()方法
用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
str.strip([chars]);
#chars – 移除字符串头尾指定的字符序列
例子:
>>> f=open('commercial.txt','r')
>>> for line in f:
print(line.strip())
Slide: 1
标题: Clauses and Phrases
副标题: the building blocks of sentences
Slide: 2
标题: Clauses
其他占位符: Clauses are subjects and predicates working together. A sentence can have as few as one clause, or it may have many clauses. Clauses are to sentences what rooms are to houses. A sentence may have only one clause like a studio may have only one room, or a sentence may have many clauses like a house may have many rooms. Clauses are the building blocks of longer sentences
......
而原文章为:
lide:\t1\n标题:\tClauses and Phrases\n副标题:\tthe building blocks of sentences\n\n\nSlide:\t2\n标题:\tClauses\n
等于去除了\n和\r
注:不好的一点是open打开后,需要手动输入f.close()关闭,不然一直占用内存。
4. NLP 的流程

思路步骤为:打开URL—读取里面HTML格式内容—去除标记并切片—分词转化nltk.text可选择对象
type()类型辨析
‘str’
>>> a=open('123.txt').read()
>>> type(a)
<class 'str'>
‘list’
>>> tokens=word_tokenize(a)
>>> type(tokens)
<class 'list'>
>>> words=[w.lower() for w in tokens]
>>> type(words)
<class 'list'>
>>> vocab=sorted(set(words))
>>> type(vocab)
<class 'list'>
以下为反面教材,字符串只能与字符串,列表只能与列表等,不等字符串连列表
均为str与list混淆出现错误
>>> vocab.append('blog')
>>> a.append('blog')
Traceback (most recent call last):
File "<pyshell#98>", line 1, in <module>
a.append('blog')
AttributeError: 'str' object has no attribute 'append'
>>> a='i think so'
>>> b=['a','b','c']
>>> a+b
Traceback (most recent call last):
File "<pyshell#101>", line 1, in <module>
a+b
TypeError: can only concatenate str (not "list") to str
3.2 字符串:最底层的文本处理
- 学习目的:之前我们只是把文本转化为列表形式进行处理,本节注重字符串与词汇,文件和文本之间的具体联系
1.字符串的基本操作
- 字符串有单引号为’ '包含单引号(test2)前用\
或直接用双引号(test3)
>>> test='nice day'
>>> test
'nice day'
>>> test2='That's sound good'
SyntaxError: invalid syntax
>>> test2='That\'s sound good'
>>> test2
"That's sound good"
>>> test3="That's sound good"
>>> test3
"That's sound good"
- 长文本:
>>> a="nice day"\
"i think so"
>>> a
'nice dayi think so'
>>> print(a)
nice dayi think so
>>> a=("nice day,""i think so")
>>> a
'nice day,i think so'
- “”" 长文本自动换行""
三双引号及三单引号辨析如下:
都有自动换行功能
>>> a="""nice day
i think so"""
>>> a
'nice day\ni think so'
>>> print(a)
nice day
i think so
>>> b='''nice day
i think so'''
>>> b
'nice day\ni think so'
>>> print(b)
nice day
i think so
>>>
- 字符串可加乘
>>> a="nice"
>>> a+a
'nicenice'
>>> a*3
'nicenicenice'
>>>
不可减及除
2.输出字符串
>>> b="i think so"
>>> print(a+b)
nicei think so
>>> print(a,b)
nice i think so
>>> print(a,"and",b)
nice and i think so
>>>
3.访问单个字符
同列表相同,字符串也有索引
>>> a='Mike'
>>> a[0]
'M'
>>> a[4]
Traceback (most recent call last):
File "<pyshell#155>", line 1, in <module>
a[4]
IndexError: string index out of range
>>> a[-1]
'e'
>>> a[-1]
'e'
>>> a[0:-2] #[]右边为<号
'Mi'
>>> a[-2]
'k'
>>> a[-2:1]
''
>>> a[-2:4]
'ke'
-
end=’ '用法
end’'的用法是不让Python在尾输出换行符
>>> test="Do you want to go there"
>>> print(test)
Do you want to go there
>>> for w in test:
print(w)
D
o
y
o
u
w
a
n
t
t
o
g
o
t
h
e
r
e
>>> for w in test:
print(w,end='')
Do you want to go there
关于寻找字符串中特定文本方法举例:
>>> test="Do you want to go there"
>>> if 'so' in test:
print('get,"there"')
else:
print("nothing")
nothing
>>> if 'there' in test:
print('get,"there"')
else:
print("nothing")
get,"there"
>>>
函数find(’ ')
查找文本所在位置
>>> test.find('to')
12
4.字符串与列表区别
直接通过举例分析:
>>> str='what about you'
>>> list=['Lucy','Jim','Mike']
>>> str[0]
'w'
>>> list[0]
'Lucy'
>>> str[:2]
'wh'
>>> list[:2]
['Lucy', 'Jim']
>>> str+'cool'
'what about youcool'
>>> list+'cool'
Traceback (most recent call last):
File "<pyshell#211>", line 1, in <module>
list+'cool'
TypeError: can only concatenate list (not "str") to list
>>> list+['cool']
['Lucy', 'Jim', 'Mike', 'cool']
函数del用法
>>> list=['Lucy','Jim','Mike']
>>> list[0]="happy"
>>> del list[-1]
>>> list
['happy', 'Jim']
辨析str
>>> str
'what about you'
>>> str[0]='r'
Traceback (most recent call last):
File "<pyshell#228>", line 1, in <module>
str[0]='r'
TypeError: 'str' object does not support item assignment
因为字符串不可改变,自创建以后;
列表是可变的,内容随时修改
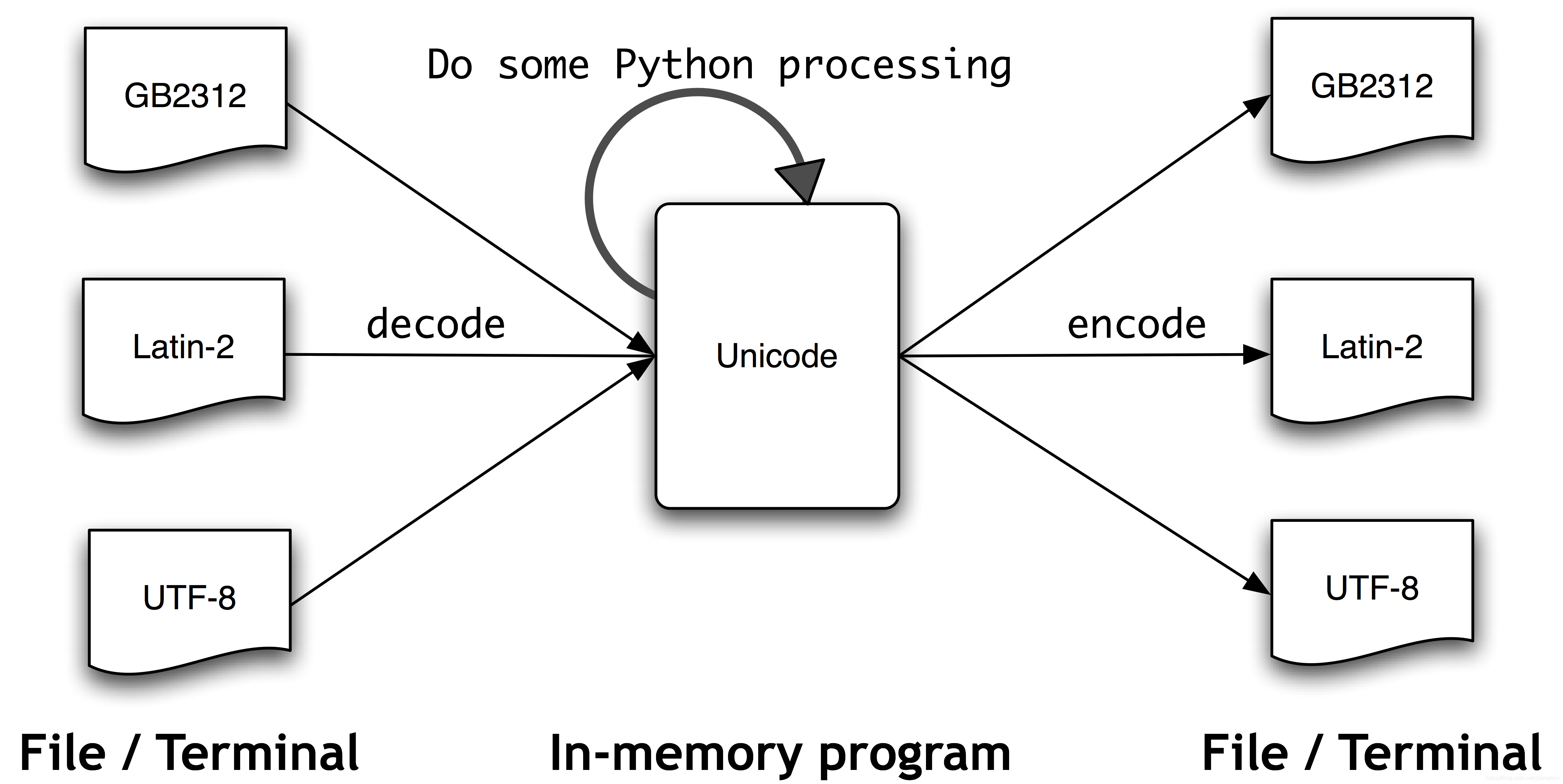
3.3 使用 Unicode 进行文字处理
- 学习目的:由于语言种类多,有很多非ASCLL字符集的文本,为解决这个问题学习使用Unicode进行处理
1.Unicode概念
Unicode 支持超过一百万种字符。每个字符分配一个编号,称为编码点
一些编码(如 ASCII 和 Latin-2)中每个编码点使用单字节,所以它们可以只支持 Unicode 的一个小的子集,足够单个语言使用了。其它的编码(如 UTF-8)使用多个字节,可以表示全部的 Unicode 字符。
\u转义字符
假设原内容:Pruska Biblioteka Państwowa
未处理的内容:Pruska Biblioteka Pa\u0144stwowa
观察得ń对应得\u0144
>>> ord('ń')
324
>>> hex(324) #324的16进制为0144
'0x144'
>>> '\u0144'
'ń'
3.4 使用正则表达式检测词组搭配
- 学习目的:之前的学习中只能满足endswith(‘ing’)等固定的搜索机制,而正则表达式让我们更加灵活搜索词组搭配。
1 导入正则表达式库
re.search(p, s)
检查字符串s中是否有模式p, 然后p后加上$
>>> import re
>>> test=[w for w in nltk.corpus.words.words('en') if w.islower()]
>>> [w for w in test if re.search('ed$',w)]
['abaissed', 'abandoned', 'abased', 'abashed',...]
*$*是正则表达式中匹配单词末尾使用
.配符代替单个字符。
字符^*匹配字符串的开始,
?*符合表示前面的字符是可选的
假设我们有一个 8 个字母组成的词的字谜室,a是其第一个字母,c是其第四个字母,y是最后一个字母。空白单元格中的每个地方,我们用一个句点:
>>> [w for w in test if re.search('^a..c...y',w)]
['alacrify', 'alacrity', 'amicably', 'anacrogynae', 'anacrogynous', 'anacromyodian', 'anococcygeal', 'apectomy', 'apically', 'apocarpy']
#若单词末尾加上$结果如下:
>>> [w for w in test if re.search('^a..c...y$',w)]
['alacrify', 'alacrity', 'amicably', 'apectomy', 'apically', 'apocarpy']
*?*符合表示前面的字符是可选的
9键键盘中‘good’是由4663打出,让我们看下4663还能
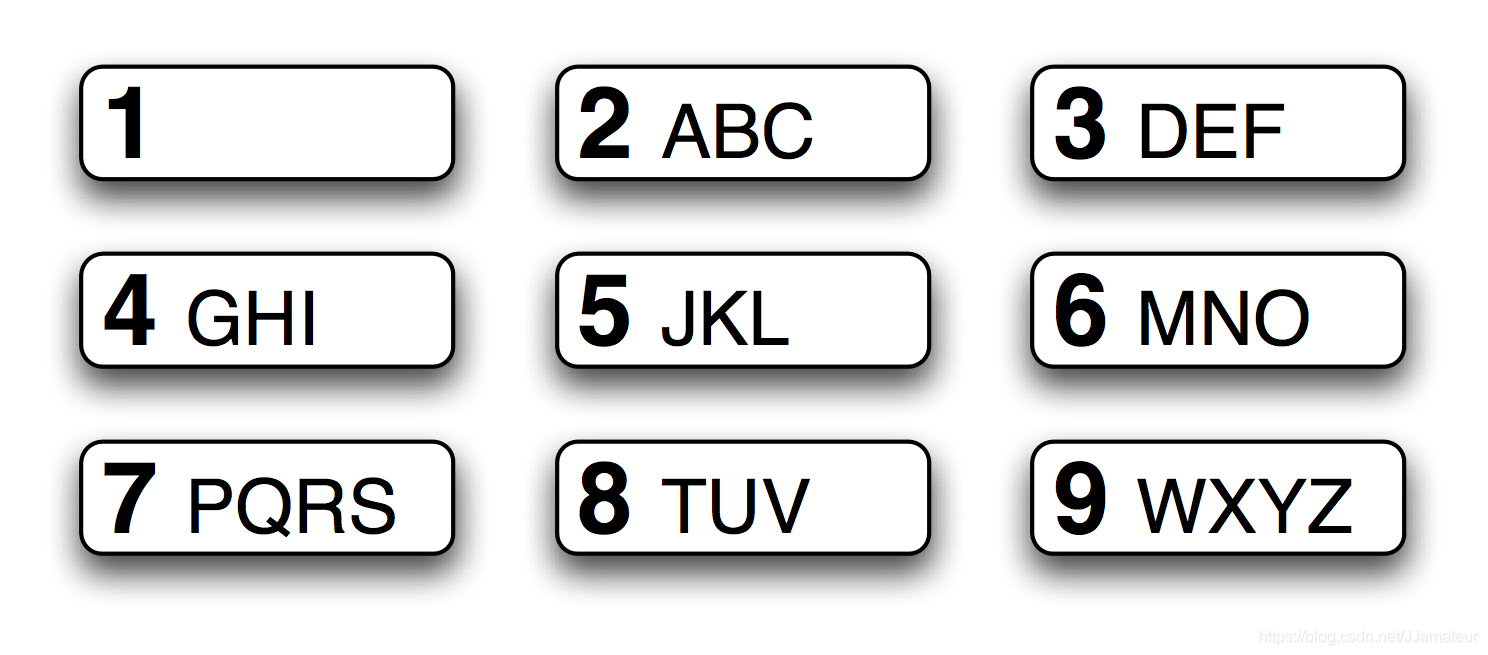
*[ghi]表示以g,h,i开头,[def]*表以d,e,f结尾
第二和第三部分同样被限制为m,n,o
>>> import re
>>> import nltk
>>> test=[w for w in nltk.corpus.words.words('en') if w.islower()]
>>> [w for w in test if re.search('^[ghi][mno][mno][def]$',w)]
['gone', 'good', 'goof', 'home', 'hone', 'hood', 'hoof']
切记不要忘记加re.search中的^和$符号,不然得不到特定的词汇,这两个符号限定了单词开头和结尾.
+和*的举例:
>>> [w for w in test if re.search('^m+i+n+$',w)]
['min']
>>> [w for w in test if re.search('^[ly]+$',w)]
['l', 'ly', 'y']
>>> [w for w in test if re.search('^a*b+$',w)]
['abb', 'b']
2 查找词干
学习目的:我们在搜索books可能会找到含book关键词的信息,我们采用提取词干搜索来避免这种情况发生。
- re.findall()只可提供后缀
>>> re.findall(r'^.*(ing|ly|ed|ious|ive|es|s|ment)$','apartment')
['ment']
“词干+词缀”形式
?:
(.*)
>>> re.findall(r'^.*(?:ing|ly|ed|ious|ive|es|s|ment)$','apartment')
['apartment']
>>> re.findall(r'^(.*)(ing|ly|ed|ious|ive|es|s|ment)$','apartment')
[('apart', 'ment')]
然而在面对searches这种-es为后缀单词时出现如下错误:
>>> re.findall(r'^(.*)(ing|ly|ed|ious|ive|es|s|ment)$','searches')
[('searche', 's')]
#解决方案
>>> re.findall(r'^(.*?)(ing|ly|ed|ious|ive|es|s|ment)$','searches')
[('search', 'es')]
不过优化后的代码仍有问题:
例如basis处理为basi ;derive处理为deriv…
>>> re.findall(r'^(.*?)(ing|ly|ed|ious|ive|es|s|ment)$','basis')
[('basi', 's')]
>>> re.findall(r'^(.*?)(ing|ly|ed|ious|ive|es|s|ment)$','derives')
[('deriv', 'es')]
不过整体可以接受,人们可以看出
3 搜索已分词文本
尖括号<>标记词符边界,括号间为空白(只对nltk文本处理方法有用)
找"a xxx man" 中间的形容词
>>> import nltk
>>> from nltk.corpus import gutenberg,nps_chat
>>> book=nltk.Text(gutenberg.words("melville-moby_dick.txt"))
>>> book.findall(r"<a>(<.*>)<man>")
monied; nervous; dangerous; white; white; white; pious; queer; good;
mature; white; Cape; great; wise; wise; butterless; white; fiendish;
pale; furious; better; certain; complete; dismasted; younger; brave;
brave; brave; brave
chat=nltk.Text(nps_chat.words())
找“xxx xxx bro ”找一个小短语
>>> chat.findall(r"<.*><.*><bro>")
you rule bro; telling you bro; u twizted bro
换个语法:找wxx and other xxs短语
>>> from nltk.corpus import brown
>>> sorts=nltk.Text(brown.words(categories=['hobbies','learned']))
>>> sorts.findall(r"<\w*><and><other><\w*s>")
speed and other activities; water and other liquids; tomb and other
landmarks; Statues and other monuments; pearls and other jewels;
charts and other items; roads and other features; figures and other
objects; military and other areas; demands and other factors;
abstracts and other compilations; iron and other metals
3.5 规范化文本
学习目的:本节是展示nltk中自带词干提取代码的功能比较
1 词干提取器
Porter和Lancaster词干提取器比较
>>> raw = """DENNIS: Listen, strange women lying in ponds distributing swords
is no basis for a system of government. Supreme executive power derives from
a mandate from the masses, not from some farcical aquatic ceremony."""
>>> tokens=word_tokenize(raw)
>>> porter=nltk.PorterStemmer()
>>> lancaster=nltk.LancasterStemmer()
>>> [porter.stem(t) for t in tokens]
['denni', ':', 'listen', ',', 'strang', 'women', 'lie', 'in', 'pond', 'distribut', 'sword', 'is', 'no', 'basi', 'for', 'a', 'system', 'of', 'govern', '.', 'suprem', 'execut', 'power', 'deriv', 'from', 'a', 'mandat', 'from', 'the', 'mass', ',', 'not', 'from', 'some', 'farcic', 'aquat', 'ceremoni', '.']
>>> [lancaster.stem(t) for t in tokens]
['den', ':', 'list', ',', 'strange', 'wom', 'lying', 'in', 'pond', 'distribut', 'sword', 'is', 'no', 'bas', 'for', 'a', 'system', 'of', 'govern', '.', 'suprem', 'execut', 'pow', 'der', 'from', 'a', 'mand', 'from', 'the', 'mass', ',', 'not', 'from', 'som', 'farc', 'aqu', 'ceremony', '.']
我们观察发现Porter中将lying处理为lie而Lancaster提取器没有做到,同理power在Lancaster中被处理为pow;当然Porter也有做的不好地方,basis-basi,Supreme-suprem…而Lancaster有做好的地方,如:strange没有变成strang,ceremony也是;
总结:选择最适合你这个文本提取的提取器就好
WordNet词形归并器
缺点:处理慢
优点:提取准确
>>> from nltk import WordNetLemmatizer
>>> wnl=nltk.WordNetLemmatizer()
>>> [wnl.lemmatize(t) for t in tokens]
['DENNIS', ':', 'Listen', ',', 'strange', 'woman', 'lying', 'in', 'pond', 'distributing', 'sword', 'is', 'no', 'basis', 'for', 'a', 'system', 'of', 'government', '.', 'Supreme', 'executive', 'power', 'derives', 'from', 'a', 'mandate', 'from', 'the', 'mass', ',', 'not', 'from', 'some', 'farcical', 'aquatic', 'ceremony', '.']
3.6 用正则表达式为文本分词
- 学习目的:使用正则表达式进行文本分词
首先设置文本:
>>> raw = """'When I'M a Duchess,' she said to herself, (not in a very hopeful tone though), 'I won't have any pepper in my kitchen AT ALL. Soup does very well without--Maybe it's always pepper that makes people hot-tempered..."""
-
使用raw.split()处理原始文本
>>> re.split(r' ',raw)
["'When", "I'M", 'a', "Duchess,'", 'she', 'said', 'to', 'herself,', '(not', 'in', 'a', 'very', 'hopeful', 'tonethough),', "'I", "won't", 'have', 'any', 'pepper', 'in', 'my', 'kitchen', 'AT', 'ALL.', 'Soup', 'does', 'very', 'well', 'without--Maybe', "it's", 'always', 'pepper', 'that', 'makes', 'people', 'hot-tempered,']
>>> re.split(r'[\t\n]+',raw)
["'When I'M a Duchess,' she said to herself, (not in a very hopeful tonethough), 'I won't have any pepper in my kitchen AT ALL. Soup does very well without--Maybe it's always pepper that makes people hot-tempered,"]
re.findall(r'\w+|\S\w*',raw)
["'When", 'I', "'M", 'a', 'Duchess', ',', "'", 'she', 'said', 'to', 'herself', ',', '(not', 'in', 'a', 'very', 'hopeful', 'tonethough', ')', ',', "'I", 'won', "'t", 'have', 'any', 'pepper', 'in', 'my', 'kitchen', 'AT', 'ALL', '.', 'Soup', 'does', 'very', 'well', 'without', '-', '-Maybe', 'it', "'s", 'always', 'pepper', 'that', 'makes', 'people', 'hot', '-tempered', ',']
-
\w+|\S\w*首先尝试匹配词中字符的所有序列。如果没有找到匹配的,它会尝试匹配后面跟着词中字符的任何 非 空白字符
>>> re.findall(r'\w+|\S\w*',raw)
["'When", 'I', "'M", 'a', 'Duchess', ',', "'", 'she', 'said', 'to', 'herself', ',', '(not', 'in', 'a', 'very', 'hopeful', 'tonethough', ')', ',', "'I", 'won', "'t", 'have', 'any', 'pepper', 'in', 'my', 'kitchen', 'AT', 'ALL', '.', 'Soup', 'does', 'very', 'well', 'without', '-', '-Maybe', 'it', "'s", 'always', 'pepper', 'that', 'makes', 'people', 'hot', '-tempered', ',']
-
\w+([-’]\w+)*这个表达式表示\w+后面跟零个或更多[-’]\w+的实例;它会匹配 hot-tempered 和 it’s。(我们需要在这个表达式中包含?:
>>> print(re.findall(r"\w+(?:[-']\w+)*|'|[-.(]+|\S\w*", raw))
["'", 'When', "I'M", 'a', 'Duchess', ',', "'", 'she', 'said', 'to', 'herself', ',', '(', 'not', 'in', 'a', 'very', 'hopeful', 'tonethough', ')', ',', "'", 'I', "won't", 'have', 'any', 'pepper', 'in', 'my', 'kitchen', 'AT', 'ALL', '.', 'Soup', 'does', 'very', 'well', 'without', '--', 'Maybe', "it's", 'always', 'pepper', 'that', 'makes', 'people', 'hot-tempered', ',']
这好在比如:“it’s” 可以提取出来,其他的均为’it’,’‘s’,
其中:*[-.(]+*会使双连字符、省略号和左括号被单独分词
总结:re.split(’ ‘,raw)和re.findall(r"\w+(?:[-’]\w+)|’|[-.(]+|\S\w", raw))效果更好,更实用一点;
3.7 分割
学习目的:采用不同技术分割文本
- 断句
>>> import pprint
>>> text=nltk.corpus.gutenberg.raw('chesterton-thursday.txt')
>>> sents=nltk.sent_tokenize(text)
>>> sents[79:89]
['"Nonsense!"', 'said Gregory, who was very rational when anyone else\nattempted paradox.', '"Why do all the clerks and navvies in the\nrailway trains look so sad and tired, so very sad and tired?', 'I will\ntell you.', 'It is because they know that the train is going right.', 'It\nis because they know that whatever place they have taken a ticket\nfor that place they will reach.', 'It is because after they have\npassed Sloane Square they know that the next station must be\nVictoria, and nothing but Victoria.', 'Oh, their wild rapture!', 'oh,\ntheir eyes like stars and their souls again in Eden, if the next\nstation were unaccountably Baker Street!"', '"It is you who are unpoetical," replied the poet Syme.']
>>> pprint.pprint(sents[79:89])
['"Nonsense!"',
'said Gregory, who was very rational when anyone else\nattempted paradox.',
'"Why do all the clerks and navvies in the\n'
'railway trains look so sad and tired, so very sad and tired?',
'I will\ntell you.',
'It is because they know that the train is going right.',
'It\n'
'is because they know that whatever place they have taken a ticket\n'
'for that place they will reach.',
'It is because after they have\n'
'passed Sloane Square they know that the next station must be\n'
'Victoria, and nothing but Victoria.',
'Oh, their wild rapture!',
'oh,\n'
'their eyes like stars and their souls again in Eden, if the next\n'
'station were unaccountably Baker Street!"',
'"It is you who are unpoetical," replied the poet Syme.']
3.8 格式化:从列表到字符串
- 学习目的:将不同类型文本采用各种方式输出
1 从列表到字符串
’ '.join()胶水函数
用与连接列表里内容,并将其转化为字符串。
>>> contents=['who not want to have a good friend']
>>> ' '.join(contents)
'who not want to have a good friend'
2 字符串与格式
直接通过举例来理解:
- 字符串
>>> a='fish'
>>> b="""nice
day"""
>>> print(a)
fish
>>> print(b)
nice
day
>>> a
'fish'
>>> b
'nice\nday'
>>>
- 格式化
format()函数:
>>> import nltk
>>> fdist=nltk.FreqDist(['a','b','a','a','b','b','a','a','b'])
>>> for c in sorted(fdist):
print(c,':',fdist[c],end=';')
a : 5;b : 4;
>>> '{}:{};'.format('a',5)
'a:5;'
>>> '{}:'.format('a')
'a:'
>>> '{}:'.format('5')
'5:'
>>> 'i go to school by {}'.format('bus')
'i go to school by bus'
>>> '{} goes to {} by {}'.format('He','school','bus')
'He goes to school by bus'
#必须用数目相同来对应
>>> '{} goes to {} by {}'.format('He','school')
Traceback (most recent call last):
File "<pyshell#181>", line 1, in <module>
'{} goes to {} by {}'.format('He','school')
IndexError: Replacement index 2 out of range for positional args tuple
#format()后多余的内容自动被忽略
>>> '{} goes to {} by {}'.format('He','school','bus','monkey')
'He goes to school by bus'
>>> 'from {1} to {0}'.format('a','b')
'from b to a'
>>> sentence='He has a {} right now'
>>> list=['book','pen','ruler']
>>> for a in list:
print(sentence.format(a))
He has a book right now
He has a pen right now
He has a ruler right now
3 对齐
- 学习目的:自定义文本对齐宽度
format( ) 函数
数字默认右对齐
>>> '{:6}'.format(12345)
' 12345'
>>> '{:<6}'.format(12345)
'12345 '
字符串默认左对齐
>>> '{:<6}'.format('cat')
'cat '
>>> '{:>6}'.format('cat')
' cat'
{:.4f}表浮点数小数点后显示4位
>>> import math
>>> '{:.4f}'.format(math.pi)
'3.1416'
'%'标百分数,不需要乘100
>>> words,total=3000,6000
>>> "OUT sum:{} words: {:.4%}".format(total,words/total)
'OUT sum:6000 words: 50.0000%'
- 制作表格
学习字符串格式和对齐,让我们制表更加的方便。
import nltk
def tabulate(cfdist, words, categories):
print('{:16}'.format('Category'), end=' ') # column headings
for word in words:
print('{:>6}'.format(word), end=' ')
print()
for category in categories:
print('{:16}'.format(category), end=' ') # row heading
for word in words: # for each word
print('{:6}'.format(cfdist[category][word]), end=' ') # print table cell
print() # end the row
from nltk.corpus import brown
cfd = nltk.ConditionalFreqDist(
(genre, word)
for genre in brown.categories()
for word in brown.words(categories=genre))
genres = ['news', 'religion', 'hobbies', 'science_fiction', 'romance', 'humor']
modals = ['can', 'could', 'may', 'might', 'must', 'will']
tabulate(cfd, modals, genres)
$结果
Category can could may might must will
news 93 86 66 38 50 389
religion 82 59 78 12 54 71
hobbies 268 58 131 22 83 264
science_fiction 16 49 4 12 8 16
romance 74 193 11 51 45 43
humor 16 30 8 8 9 13
4 将结果写入文件
- 学习目的:将非文本数据写入文件时,先将它转换为字符串
textwrap模块
‘%s_(%d),’
>>> contents=['After', 'all', 'is', 'said', 'and', 'done', ',','more', 'is', 'said', 'than', 'done', '.']
>>> for word in contents:
print(word,'('+str(len(word))+')',end=' ')
After (5) all (3) is (2) said (4) and (3) done (4) , (1) more (4) is (2) said (4) than (4) done (4) . (1)
>>> from textwrap import fill
>>> format='%s (%d),'
>>> part=[format % (word,len(word)) for word in contents]
>>> output=' '.join(part)
>>> wrapped=fill(output)
>>> print(wrapped)
After (5), all (3), is (2), said (4), and (3), done (4), , (1), more
(4), is (2), said (4), than (4), done (4), . (1),
>>>


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









