






第一步:找到时间设置,更改时间至June 30,2020这个时间之前
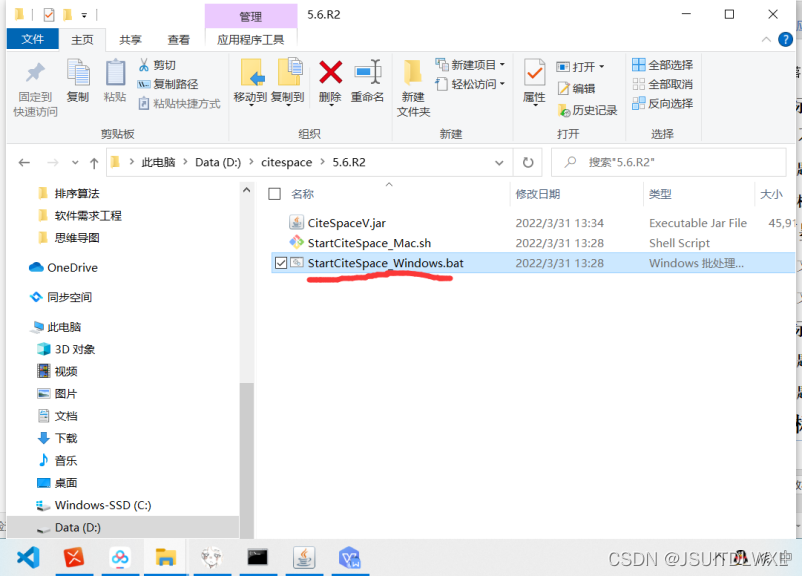
第二步:找到文件,点击
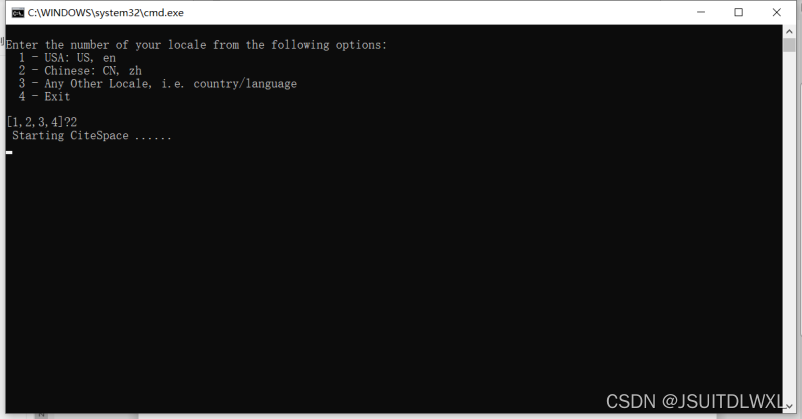
第三步:按2启动
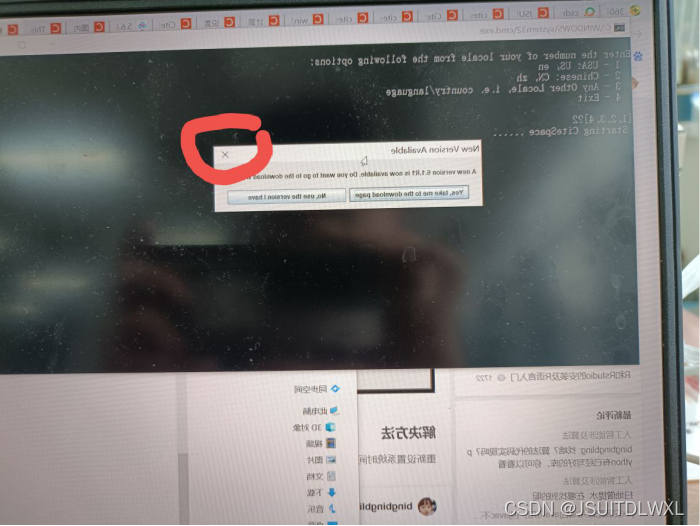
第四步:出现这个点击差掉,然后等上20秒左右
第五步:出现这个界面,点击agree
出现下面这个界面表示成功

第一步:找到时间设置,更改时间至June 30,2020这个时间之前
第二步:找到文件,点击
第三步:按2启动
第四步:出现这个点击差掉,然后等上20秒左右
第五步:出现这个界面,点击agree
出现下面这个界面表示成功

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























