







如何获取微信公众号的“biz”?
本文主要介绍如何获取指定微信公众号的”biz”,至于biz编号能做什么我想大家在搜集这个词的时候就应该了,这里就不墨迹了。具体如下:
1、找到你需要获取的公众号页面,找到历史文章页面
2、然后直接复制该页的链接,里面就包含了”biz“
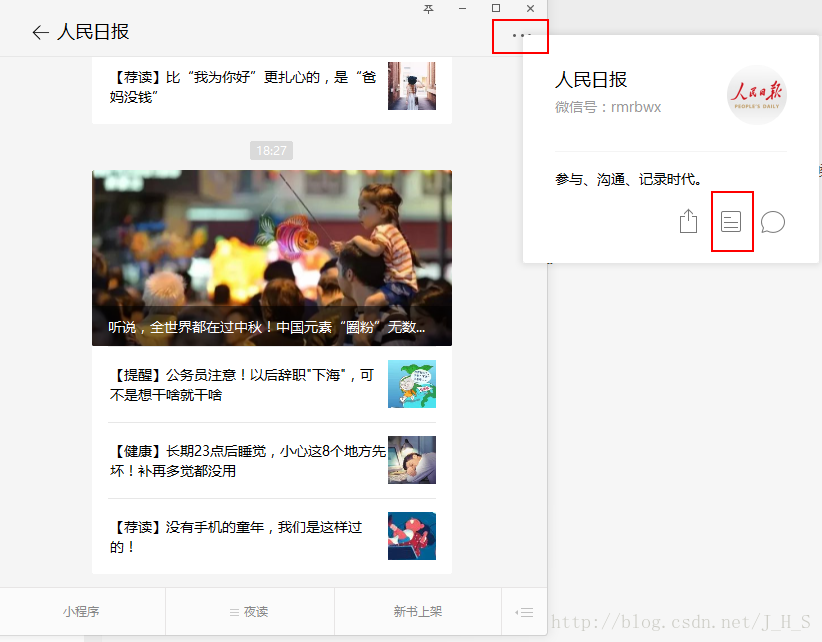
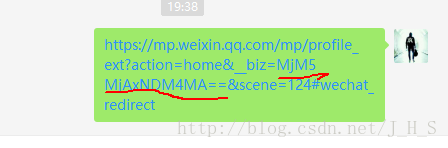
最终得到“人民日报”的“biz”为“MjM5MjAxNDM4MA==”(注意:不要遗漏了后面的‘==’哟)
本文主要介绍如何获取指定微信公众号的”biz”,至于biz编号能做什么我想大家在搜集这个词的时候就应该了,这里就不墨迹了。具体如下:
1、找到你需要获取的公众号页面,找到历史文章页面
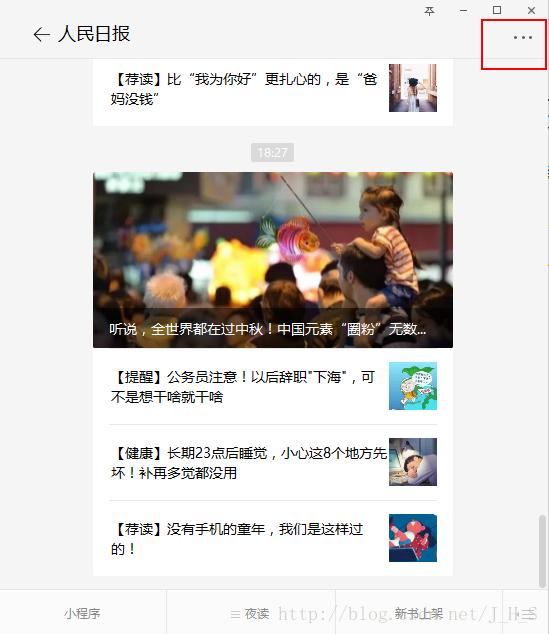
2、然后直接复制该页的链接,里面就包含了”biz“

最终得到“人民日报”的“biz”为“MjM5MjAxNDM4MA==”(注意:不要遗漏了后面的‘==’哟)
 712
1201
965
766
712
1201
965
766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























