









面试官:嗯,如果我给你一段文字,以及给你一些需要过滤的敏感词,你会怎么来实现这个敏感词过滤的算法呢?例如我给你一段字符串“abcdefghi",以及三个敏感词"de", “bca”, “bcf”。
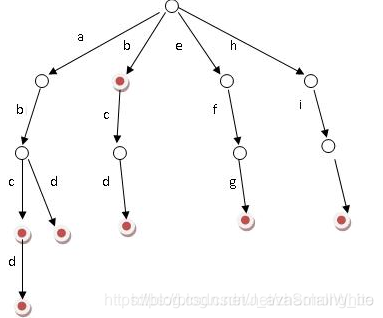
先把你给我的三个敏感词:“de”, “bca”, “bcf” 建立一颗 trie 树,如下:
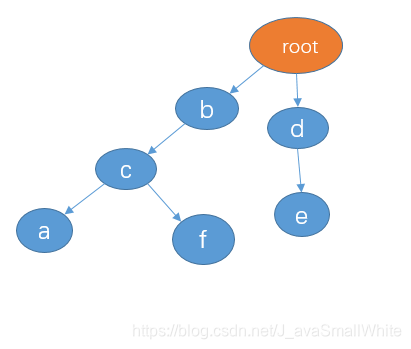
接着我们可以采用三个指针来遍历,我直接用上面你给你例子来演示吧。
1、首先指针 p1 指向 root,指针 p2 和 p3 指向字符串第一个字符
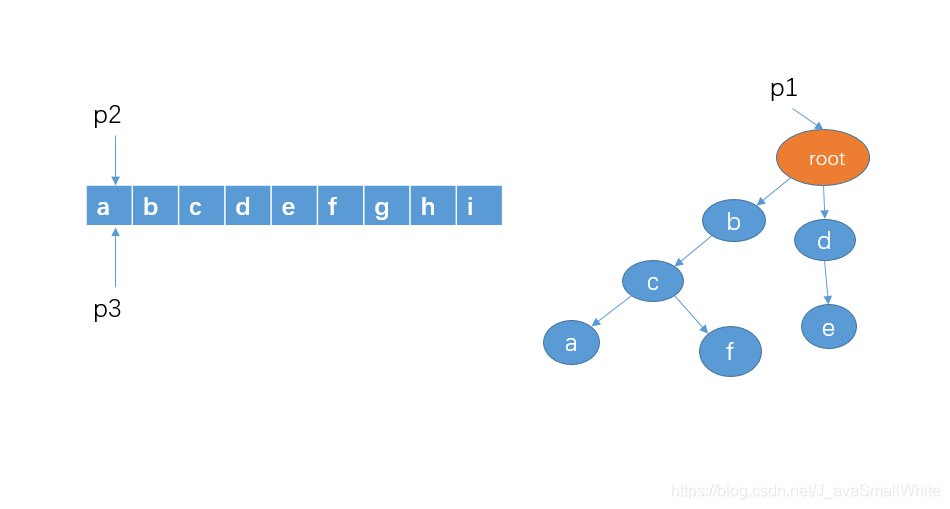
2、然后从字符串的 a 开始,检测有没有以 a 作为前缀的敏感词,直接判断 p1 的孩子节点中是否有 a 这个节点就可以了,显然这里没有。接着把指针 p2 和 p3 向右移动一格。
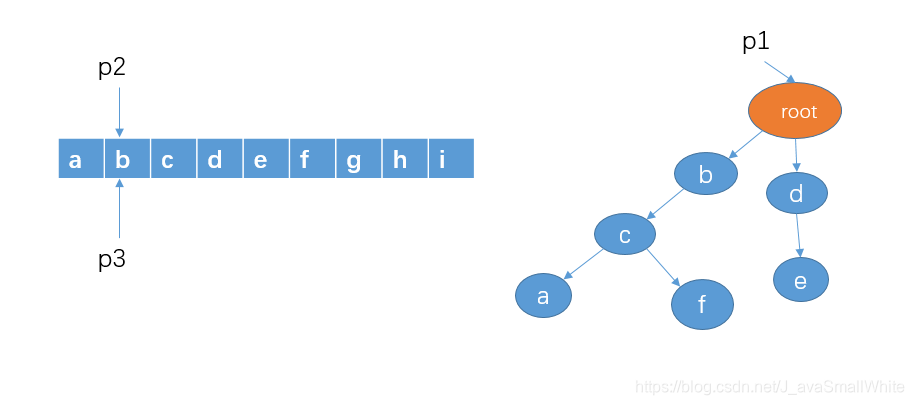
3、然后从字符串 b 开始查找,看看是否有以 b 作为前缀的字符串,p1 的孩子节点中有 b,这时,我们把 p1 指向节点 b,p2 向右移动一格,不过,p3不动。
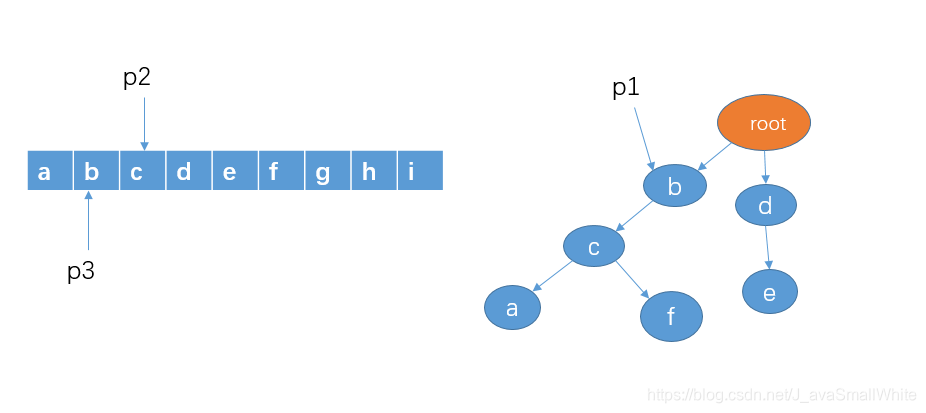
4、判断 p1 的孩子节点中是否存在 p2 指向的字符c,显然有。我们把 p1 指向节点 c,p2 向右移动一格,p3不动。
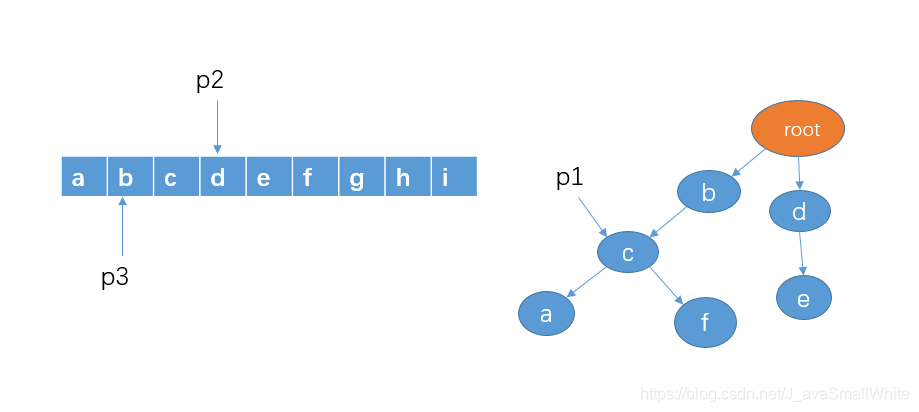
5、判断 p1 的孩子节点中是否存在 p2 指向的字符d,这里没有。这意味着,不存在以字符b作为前缀的敏感词。这时我们把p2和p3都移向字符c,p1 还是还原到最开始指向 root。
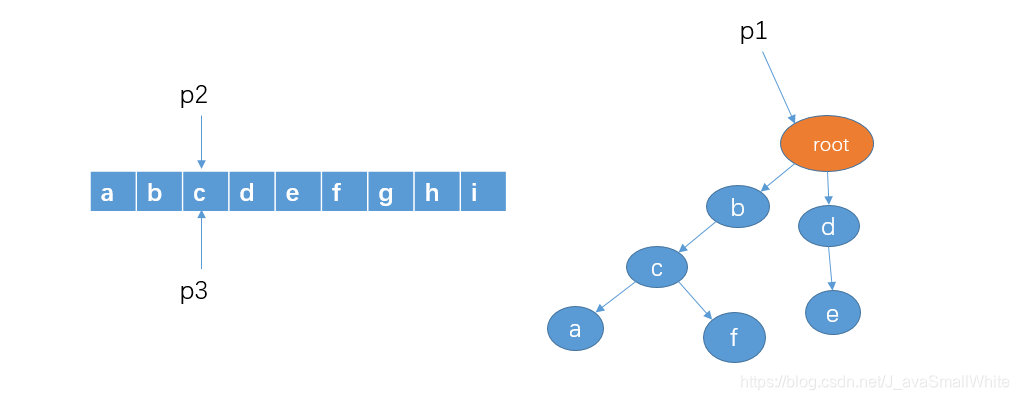
6、和前面的步骤一样,判断有没以 c 作为前缀的字符串,显然这里没有,所以把 p2 和 p3 移到字符 d。
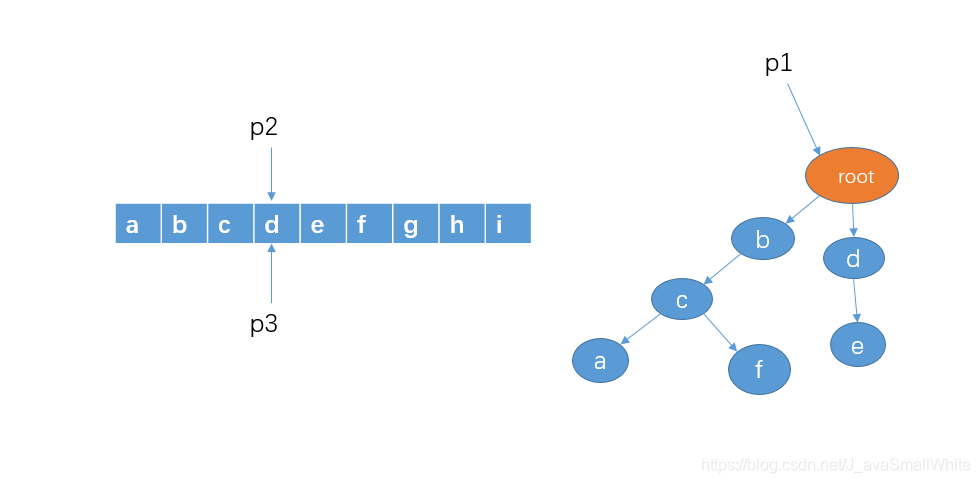
7、然后从字符串 d 开始查找,看看是否有以 d 作为前缀的字符串,p1 的孩子节点中有 d,这时,我们把 p1 指向节点 d,p2 向右移动一格,不过,p3和刚才一样不动。(看到这里,我猜你已经懂了)
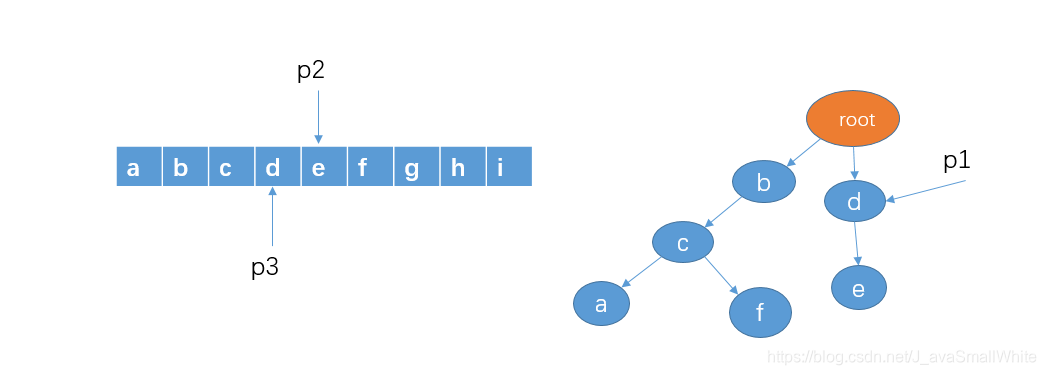
8、判断 p1 的孩子节点中是否存在 p2 指向的字符e,显然有。我们把 p1 指向节点 e,并且,这里e是最后一个节点了,查找结束,所以存在敏感词de,即 p3 和 p2 这个区间指向的就是敏感词了,把 p2 和 p3 指向的区间那些字符替换成 *。并且把 p2 和 p3 移向字符 f。如下:
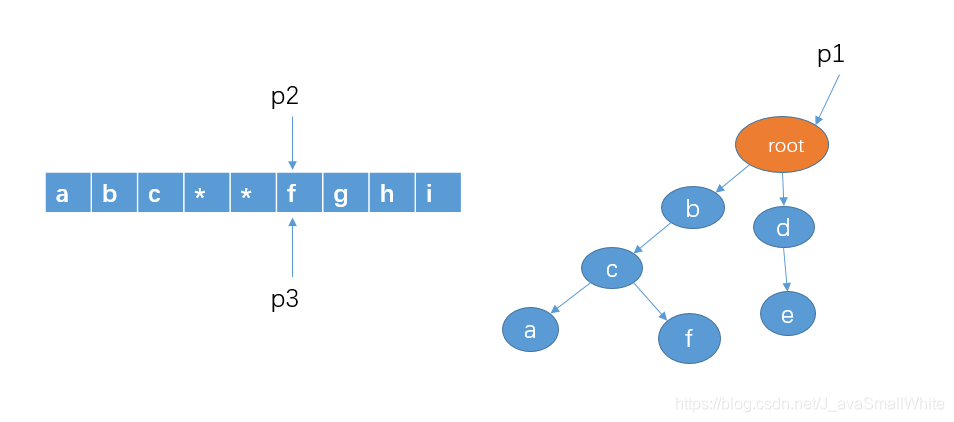
9、接着还是重复同样的步骤,知道 p3 指向最后一个字符。
复杂度分析
如果敏感词的长度为 m,则每个敏感词的查找时间复杂度是 O(m),字符串的长度为 n,我们需要遍历 n 遍,所以敏感词查找这个过程的时间复杂度是 O(n * m)。如果有 t 个敏感词的话,构建 trie 树的时间复杂度是 O(t * m)。
2.1Trie Tree(字典树)
字典树,又称为单词查找树,Tire数,是一种树形结构,它是一种哈希树的变种。
2.2基本性质
- 根节点不包含字符,除根节点外的每一个子节点都包含一个字符
- 从根节点到某一节点。路径上经过的字符连接起来,就是该节点对应的字符串
- 每个节点的所有子节点包含的字符都不相同
2.3应用情景
典型应用是用于统计,排序和保存大量的字符串(不仅限于字符串),经常被搜索引擎系统用于文本词频统计。
2.4优点
利用字符串的公共前缀来减少查询时间,最大限度的减少无谓的字符串比较,查询效率比哈希树高。
https://blog.csdn.net/zhaohong_bo/article/details/90293862
https://www.cnblogs.com/kubidemanong/p/10834993.html

















 950
950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









