







现有的很多量化方法都是通过量化后重训练来弥补量化损失的,但这些方法并不完美:它们需要完整的数据集(这涉及到隐私及其他问题),而且还需要大量的计算资源。于是,一种被称为post-training的方法被提出了:它不需要完整的数据集,也不需要重新训练或微调模型(也就是说,可以达到端对端),且它的准确率与流行的浮点模型的精度接近。
但这类方法一旦把量化精度放到8bit以下时,精度就大幅下降。为了解决这个问题,本文提出了一种利用网络分布的统计信息来最小化在量化过程中引入的本地误差。
ACIQ: Analytical Clipping for Integer Quantization
作者提出了三种方法,第一种是应用于激活层,其形式为:
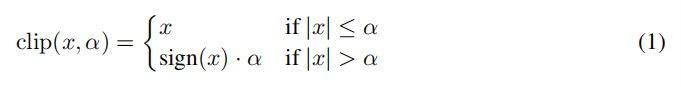
由于[-α,α]被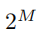
均分,因此设间隔Δ:
作者又假设量化前的值位于每个小区间的中心处(由大数定理知,这个假设是可行的),于是量化的方差为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2816
2816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









