






目录
第二步、试着凑出,当src找不到,就会执行onerror里面的字符串
dhcp工作流程图
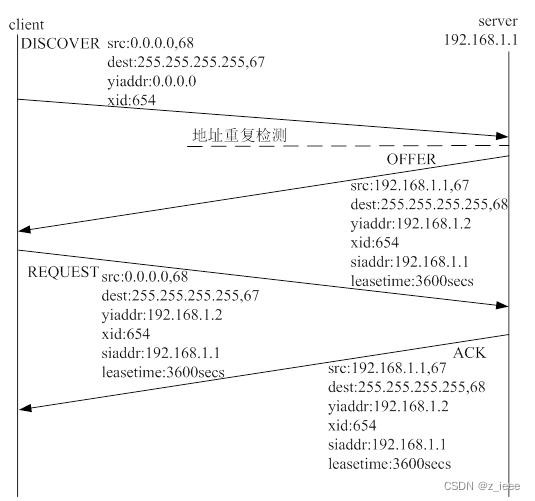
- 1 发现阶段:DHCP客户端寻找DHCP 服务器的阶段。客户端以广播方式发送 DISCOVER 报文。
- 2 提供阶段:DHCP服务器提供 IP 地址的阶段。DHCP 服务器接收到客户端的DISCOVER 报文后,根据 IP 地址分配的优先次序选出一个IP地址,与其他参数一起通过OFFER报文发送给客户端。
- 3 选择阶段:DHCP客户端选择IP地址的阶段。如果有多台DHCP 服务器向该客户端发来OFFER报文 ,客户端只接受第一个收到的OFFER 报文,然后以广播方式发送 REQUEST 报文,该报文中包含DHCP 服务器在OFFER 报文中分配的 IP 地址。同时该报文中包含Option 54(服务器标识选项),即它选择的DHCP服务器的IP地址信息。
- 4 确认阶段:DHCP服务器确认IP 地址的阶段。DHCP 服务器收到DHCP 客户端发来的 REQUEST 报文后,只有DHCP 客户端选择的服务器会进行如下操作:如果确认地址分配给该客户端,则返回 ACK 报文;否则将返回NAK 报文,表明地址不能分配给该客户端。客户端收到服务器返回的ACK 确认报文后,会以广播的方式发送ARP 报文(目的地址是被分配到的地址)进行地址探测,如果在规定的时间内没有收到回应,客户端才使用此地址。
request response状态码
200 成功
403 forbidden (权限不够)
401 unanthorized
500 服务器错误
30x 重定向 重新指定方向 (登录 )
UTF-8
这里直接说,他其实就是可变长的unicode,进而达到不浪费。
UTF-8编码规则:
1、对于单字节的其实就是unicode编码
2、对于N字节的(N>1),第一个字节的前N位都是1,(在第一个字节中)第N+1位和后面都为0
后面字节前两位一律设为10。
注意:
字 word
字节 byte
位 bit,来自英文bit,音译为“比特”,表示二进制位。
字长是指字的长度
1字=2字节(1 word = 2 byte)
1字节=8位(1 byte = 8bit)
一个字的字长为16
一个字节的字长是8

字节长度
 所以单字节(0~127)
所以单字节(0~127)
双字节 (128~2047)
三字节 (2048~65535)
下面看一下例子,以'中'为例
注意:python3才支持中文转换ascii码

转为2进制

咱们先拿出来'0b100 111000 101101',开始填充,因为‘中’是三个字节那么格式为:
1110xxxx 10xxxxxx 10xxxxxx,从最后一位开始,依次从后向前填充未知的x,如果不够进行补零。然后中的UTF-8编码是 11100100 10111000 10101101


显而易见,就是这样
下面来一道URL code的绕过
前端(php)页面代码
<?php
header('X-XSS-Protection:0');
$xss = isset($_GET['xss'])? $_GET['xss'] : '';
$xss = str_replace(array("(",")","&","\\","<",">","'"),'',$xss);
echo "<img src=\"{$xss}\">";
?>
第一步、开始逃逸双引号的限制
第二步、试着凑出<img src=http://www.baidu.com οnerrοr="alert(1)">,当src找不到,就会执行onerror里面的字符串

由于括号被过滤,我们可以使用反引号进行平替

sucess!
如果反引号被过滤,那么我们只能进行urlcode编码绕过

咱们先试一下

好像不行,因为你摁下回车浏览器将%28%29解析成了()导致在前端页面过滤掉啦

我们再用%2528 %2529在尝试一下 (%25是由urlcode进行编码的%)

结果不尽人意

JS规范:不可以编码符号() , : 等
但是我们可以借助咱们的location和javascript

原因:location函数可以将等号右边的都变为一个变量,在JS中变量可以随意编码
注意看一下
1,2,3都不能被弹窗,因为协议不能被urlcode编码,但是可以被html实体编码,所以4可以弹窗
总结
说一下我的理解,总的来说就是因为过滤了html实体编码(&),又因为url code 编码不能编码协议,unicode不能编码符号,又因为页面的解析流程为 html --> url -->js,所以我们使用url将括号进行编码,由于浏览器地址会进行解析urlcode,所以我们需要在进行一下url code编码,但此时,由于不是变量,不会进行第二遍url code解码,然后我们通过location函数可以将后面视为变量,但此时alert(1)还是为只读的,我们需要再使用javascript伪协议将他变为字符串。
HTML例子(不会弹窗)

当存在编码标签时,他不会在重新进入标签开始的状态。只会认为他是一个文本,两个不能弹窗
<script>标签是JS标签,只能放函数和文本吧 (不能弹)















 4312
4312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









