







1 引言
1957年Rosenblatt提出感知机模型,它是神经网络和支持向量机的基础。其主要适用于分类任务,训练好的感知机模型可将数据集正确地分为两类:超平面以上为正类,超平面以下为负类(后面会讲到感知机是一个超平面)。它通过利用梯度下降法最小化损失函数的思想让感知机学习到最优的状态,使得数据集的误分类点个数为0。其优点主要体现在其算法实现相对简单。
2 理论
2.1 定义
设输入特征向量为,感知机权重为
,偏置为
,输出值为
,则感知机模型定义为:
这是一个将的输入空间转换为
的输出空间的感知机模型,其中的
函数定义为:
2.2 几何解释
设超平面,数据集
,若这个超平面可将这个数据集的
个样本点划分到超平面的两边,则这个超平面可以定义为一个感知机模型。

图1 感知机几何解释
如图1所示绿线代表超平面,数据集
有17个样本:红色三角形代表
类别的样本,其样本数量为8;蓝色圆点代表
类别的样本,其样本数量为9。图1的超平面
将数据集
的样本划分成了两个类别:超平面以下的样本属于-1类,超平面以上的属于+1类。
2.3 数据集的线性可分性
给定数据集,若存在一个超平面
:
能够将数据集正确地划分出来则称这个数据集为线性可分数据集。如图1所示超平面将数据集正确划分成了+1类和-1类,则这个数据集称为线性可分数据集。
2.4 感知机的学习策略
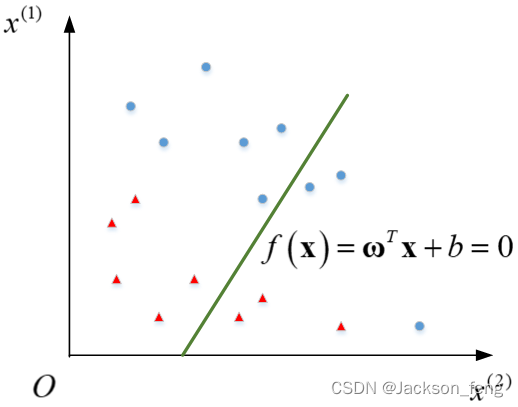
图2 误分类的感知机模型
感知机可以通过学习的方式更新参数(和
)拟合出一个能将线性可分数据集
正确分类的超平面。假设初始随机设置超平面
的参数为
,
,此时误分类样本点的集合为
(如图2所示)。感知机学习的目标是让误分类样本点集合
的长度
极小化,则只需使得超平面
往着集合
中的样本点方向更新。若集合
中的点到
的距离和为:
其中,则以上问题可以表示为:
由于误分类点的标签与超平面的输出
符号相反,所以
。若设
,则公式(5)可以表示为:
公式(6)是感知机学习的损失函数。
2.5 感知机的学习算法
感知机的学习算法采用梯度下降法来优化2.4节所提到的损失函数。首先对公式(6)的损失函数求梯度:
由梯度下降法得到参数更新公式:
其中为学习率且
,
。通过调节学习率的大小可以改变整个算法的收敛速度。由以上步骤导出感知机学习算法(算法1)。

2.6 感知机的对偶学习算法
对于公式(6)的优化参数有和
两个变量,更新这两个变量的算法复杂度较高。为了降低算法复杂度,这里提出了一种感知机的对偶学习算法,它将原算法的优化参数
和
改为
和
,下面将列出详细推导这个算法的步骤。
定义和
为第
轮更新时的参数,则公式(8)的
更新步骤可以表示为:
经过多轮迭代,上式可以描述为:
表示第
轮的误分类点,
对应其标签。若设初始值
,
表示数据集
第
个样本被误分类的次数,则公式(10)可以表示为:
设,则:
将公式(12)带入公式(1)可得感知机的对偶形式:
定义,则公式(6)的损失函数的对偶形式可以表示为:
参数更新可以表示为:
综上所述,感知机的对偶学习算法可以用算法2描述:

3例子
3.1 感知机学习算法
建立数据集它的正实例点为
,
,负实例点为
,试用感知机学习算法求感知机模型
。(学习率
)
解:选取初始化参数,
第1轮:,
更新参数:
第2轮:,
更新参数:
第3轮:,
更新参数:
表1 感知机算法的迭代过程

则,
3.2 感知机对偶形式学习算法
建立数据集,它的正实例点为
,
,负实例点为
,试用感知机对偶学习算法求感知机模型
。(学习率
)
解:选取初始化参数,
第1轮:,
更新参数:
第2轮:,
更新参数:
第3轮:,
更新参数:
表2 感知机对偶算法的迭代过程

则,
4课后习题
4.1 (习题2.1)Minsky与Papert指出:感知机因为是线性模型,所以不能表示复杂的函数,如异或(XOR)。验证感知机为什么不能表示异或。
解:异或函数是一种非线性函数,它是一种线性不可分函数。而感知机是线性模型,所以感知机不能表示异或(如图3所示)。

图3 误分类的感知机模型
4.2 (习题2.2)模仿例题2.1,构建从训练数据集求解感知机模型的例子。
解:设正样本点为:,
;负样本点为:
,则:
表3 习题2.2求解过程

则,
4.3 (习题2.3)证明以下定理:样本集线性可分的充分必要条件是正实例点集所构成的凸壳与负实例点集所构成的凸壳不相交。
证: 设正样本点集合为:,负样本点集合为
,则它们的凸壳分别为:
① 充分性;正、负样本点集凸壳不相交样本集线性可分:
因为,则:
且使得
与
线性可分,则:
若:
且使得
与
线性可分,则:
所以,与原问题矛盾。
② 必要性:样本集线性可分正、负样本点集凸壳不相交
当:
且使得
与
线性可分,所以:
则
5参考文献
[1] 李航. 统计学习方法[M]. 清华大学出版社, 2012.
[2] Rosenblatt, F. The perceptron: a probabilistic model for information storage and organization in the brain.[J]. Psychological Review, 1958, 65:386-408.
代码实现
A 算法2.1
import numpy as np
# 感知机学习算法
class Perceptron:
def __init__(self, X, y):
self.X=np.array(X)
self.y=np.array(y)
self.w=np.zeros(self.X.shape[1])
self.b=0
def train(self,ita):
k,epoch=0,0
while k<self.y.shape[0]:
k=0
for _X,_y in zip(self.X,self.y):
if _y*(np.dot(self.w,_X.T)+self.b)<=0:
self.w=self.w+ita*_y*_X
self.b=self.b+ita*_y
break
else:
k+=1
print(f"epoch={epoch}:\tw={self.w}\tb={self.b}")
epoch+=1
if __name__=="__main__":
X=[[3,3],[4,3],[1,1]]
y=[1,1,-1]
print("\n感知机学习算法:\n")
perc=Perceptron(X,y)
perc.train(ita=1)B 算法2.2
# 感知机对偶形式学习算法
class DualPerceptron:
def __init__(self, X, y):
self.X=np.array(X)
self.y=np.array(y)
self.alpha=np.zeros(self.X.shape[0])
self.b=0
def train(self,ita):
k,epoch=0,0
while k<self.y.shape[0]:
k=0
for i,data in enumerate(zip(self.X,self.y),0):
_X,_y=data
temp=np.zeros(self.X.shape[1])
for alphaj,xj,yj in zip(self.alpha,self.X,self.y):
temp=temp+alphaj*xj*yj
if _y*(np.dot(temp,_X.T)+self.b)<=0:
self.alpha[i]=self.alpha[i]+1
self.b=self.b+ita*_y
break
else:
k+=1
print(f"epoch={epoch}:\talpha={self.alpha}\tb={self.b}")
epoch+=1
self.w=np.zeros(self.X.shape[1])
for alphaj, xj, yj in zip(self.alpha, self.X, self.y):
self.w = self.w + alphaj * xj * yj
if __name__=="__main__":
X=[[3,3],[4,3],[1,1]]
y=[1,1,-1]
print("\n感知机对偶形式学习算法:\n")
dual_perc=DualPerceptron(X, y)
dual_perc.train(ita=1)*本文仅代表作者自己的观点,欢迎大家批评指正















 308
308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









