







虽然我走得很慢,但我从不后退!

目录
一.What?Why?How?
其实每接触到一样新鲜技术,都需要What? Why? How?让自己知其然,知其所以然。更多的学会思考,才能学的更加完善。
1.什么是大数据?(What)
“大数据”这个词相信很多小伙伴听过,那么什么是大数据呢?
①下面是标准的定义:
大数据(big data),IT行业术语,是指
无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
②自己的理解
从标准定义,可以看出大数据是一种
新的技术发展模式。那么为什么会产生这么模式呢?归根到底是社会的快速发展,催生出海量数据。随着人们对数据重要性的认知,开始分析和挖掘海量丰富数据资源价值,于是大数据的价值才能更好的脱颖而出
2.为什么要学习大数据? (Why)
1.国家对大数据发展的支持。
国务院以及各级地方政府从2012年开始,颁布了大量政策来扶持大数据产业
大数据发展已被列入国家发展战略了,大数据发展前景毋庸置疑。
2.应用领域广泛
大数据已经不仅仅是政府用来分析居民生活状态的工具了,现在它被广泛的应用于各个领域。
医疗,教育,体育,金融,娱乐产业,房地产,电影电视剧的制作等等,都用上了大数据。
3.人才需求巨大
利用大数据优势,获取
更高的利益,大数据发展势头十分迅猛。近年来,中国互联网三巨头BAT(百度、阿里、腾讯)均耗费巨资投入大数据发展,纷纷建立大数据研究院、大数据实验室等,提供大数据专业服务,一批大数据专业分析公司也应运而生。
3.如何才能更好的学习大数据? (How)
1.首先明确个人学习大数据方向,才能更加针对的学习。
大致分为这四种:我目前选择的是大数据开发,后面可能也会全面发展。
- 大数据开发工程师
- 大数据分析工程师
- 大数据运维工程师
- 大数据挖掘工程师
2.自己要搞清楚自己为什么要学大数据,可能是工资高,也可能是热爱。自己要搞清楚这个问题,很关键。因为,这将是学习大数据持续源源不断的动力。
3.要对大数据技术有一个整体认知,学什么,哪些是重点技术,都要了解。
4.学习没有捷径,同时学习的过程需要大量自己的思考,加上自己的练习,这样基本功才扎实。俗话说:“底层建筑,决定上层高度”。
学习要思考,学习要思考,学习思考…,重要的事情只说2.5遍
二.单机处理VS分布式处理 海量数据?
需求1:我有一万个元素(比如数字或单词)需要存储?
答案:数组:Array,List , 集合:Map
需求2:如果查找某一个元素,最简单的遍历方式复杂的是多少?

答案:O(n), 因为可能要遍历一整遍。
需求3:如果我期望复杂度是O(4)呢?
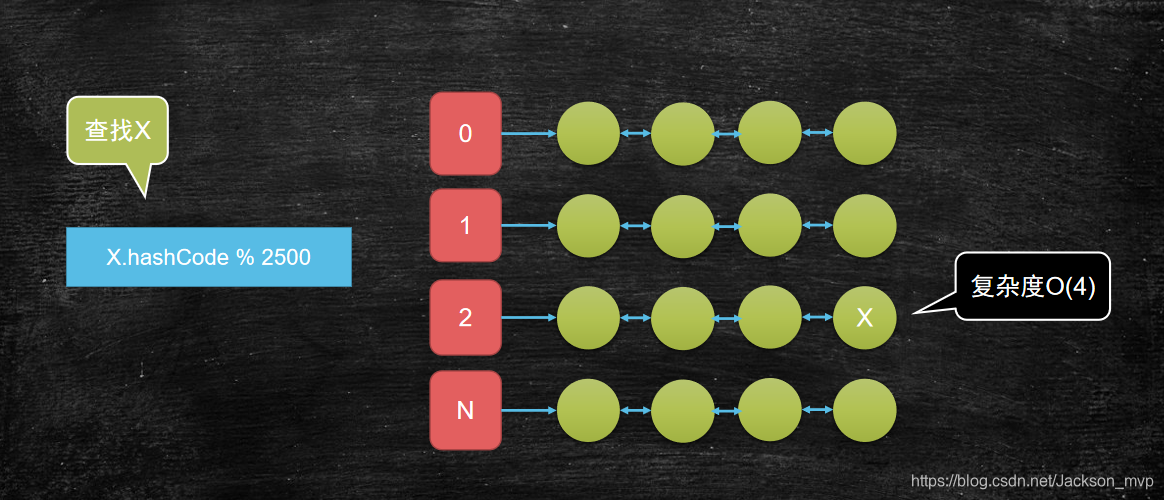
答案:1万个元素,可以分成2500个链,每个链上有4个元素。
2500个链可以当成2500个对象,然后用数组去存。即便如此,此时要查的结果还是O(n)。
此时可以逆推下,如果确定链是不是就可以确定查找复杂度是O(4)了?
如何确定链:此时可以用上图的方法,采用x.hashCode与模的方式。因为如果设置2500个链,那么肯定对应2500个数组。模与值的方式,找到数组下标,就可以确定再哪个链上。然后确定好链,就可以再确定复杂度O(4)了。
单机版:hashCode的作用:分而治之,减少复杂度。类似这种需求就靠hashCode取模。hashCode底层还是靠hashTable来实现。就是一巨大的张散列表。
总结:分而治之,大而化小

需求4:很多行,查找出相同内容的俩行
有一个非常大的文本文件,里面有很多很多的行,只有两行一样,它们出现在未知的位置,需要查找到它们。
注意:单机,而且可用的内存很少,也就几十兆。
答案:1TB可以大致拆分为2000个500MB。IO速度是500MB/S,也就是需要2000s可以读完,差不多30分钟。
1.第一种:最简单的方式(效率是最低)
读取上一次的与第一个元素对比,依次类似循环到最后复杂度为O(n)。这才是第一遍。然后开始上一次元素与第二个元素对比,再一次循环到最后复杂度为O(n),一共的复杂度为nO(n)。
2.第二种方法: 分而治之,采用readLine方法(单机版)
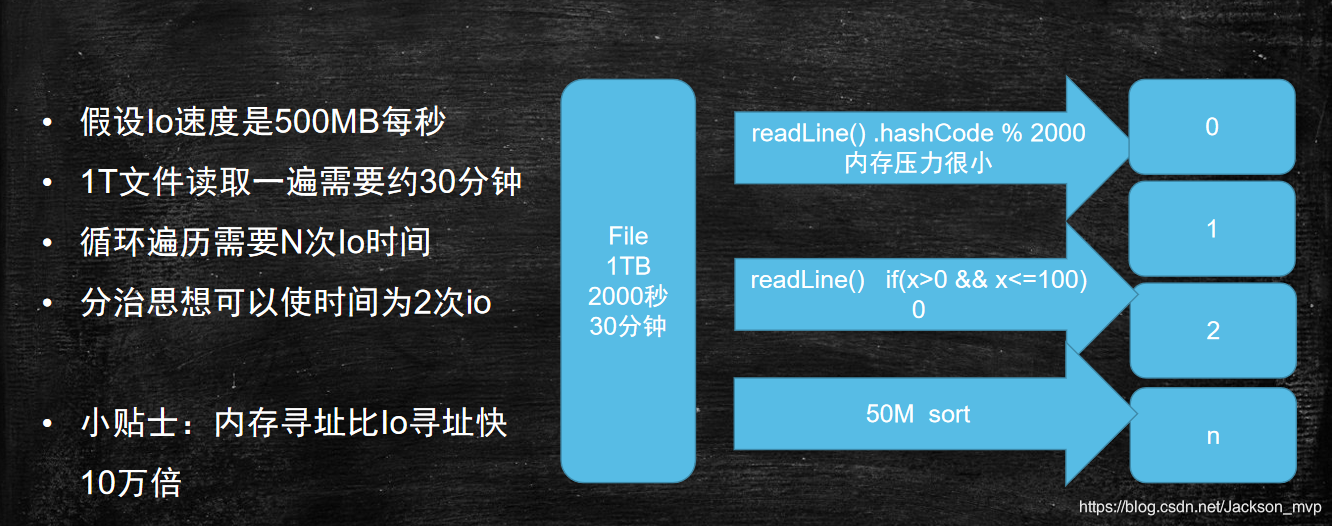
一个小的知识点:IO的速度是500MB/S,传统机械硬盘是100MB/S.
首先来看下1T文件很难放到内存。因此,要把1T文件切分成2000个小文件。
readLine() .hashCode % 2000,对应着一行一个小文件。30分钟读完,然后划分的越小越好,然后放到内存。然后2000个小文件开始进行排序,也需要30分钟。因为内存寻址比Io寻址快10万倍。所以寻址时间就按1S,因此一共1小时1S完成。排序是为了方便找出相同俩行,内部有序,外部无序。
网络IO往往是ms为单位,而内存却是ns为单位,所以相差10万倍。往往IO是互联网技术发展的瓶颈。
第三种方法:分布式方法,分成块处理(分布式版)****
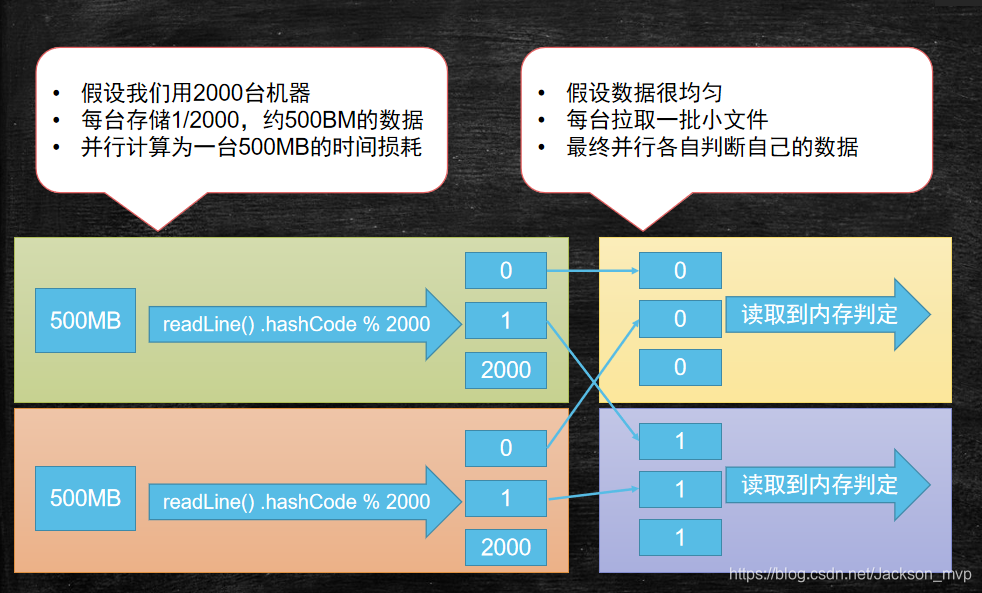
2000台,每台有500MB大小。此时采用的是分块读取,而不是用条件判断,逐个读取。因为是分布式的,所以可以同时进行,此时每台只要1S就可以读完500M。采用readLine() .hashCode % 2000方法,生成2000个小文件。
由于,判定的是很多行,查找出相同内容的俩行,所以将每一台对应相同的号小文件,进行合并。此时,网卡速度按100MB/S,因为每台对应读取的依然是500M,因为是分布式可以并行计算拉取数据,所以大致需要5S就可以全部读取完。
然后到内存进行判定。由于内存的寻址时间是磁盘的10万倍,所以2000个小文件立刻判定完。就按一秒算完成。因此一共需要1S+5S+1S=7S就可以完成结果。
可以看出分布式的效率是十分的高(注:暂且不考虑1T数据分发到2000台时间)后面再讨论这个问题。
需求5:如果是1T数值文件,那么如何全排序呢?
1.第一种方法:条件判断,放到对应的小文件当中
if(x>0&&x<100) => 0 号小文件
if(x>10-&&x<1000) => 1 号小文件
…
if(x>x&&x<n) => n 号小文件
假如说:产生了1000个小文件。注意:这些小文件是内部无序,外部有序。
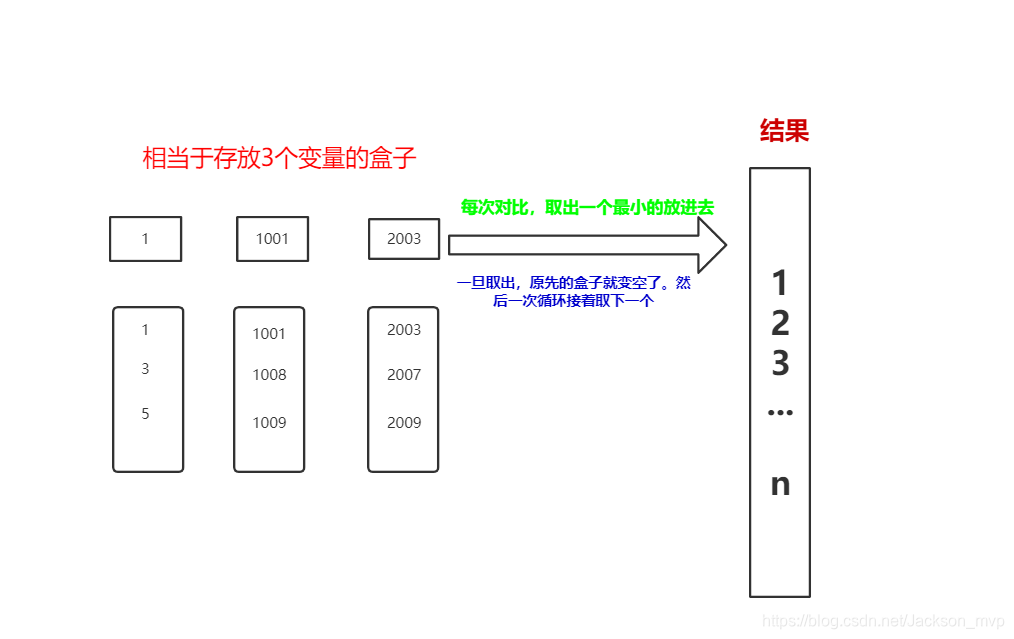
如果是这样的方式,结果还是要2个30分钟,也就是一小时才可以完成。
2.第二种方法:采用分布式方法,切块处理。
先读500M进行排序 ——> ①号文件
再读500M进行排序 ——> ②号文件
依次进行循环…
最后读500M进行排序 ——> 2000号文件
此时需要30分钟来完成。因为现在是外部无序,内部有序。因为只要文件足够小,然后放到内存进行排序,追加到另一个文件,很快就可读取完,就按一分钟来完成。时间一共是30分钟+1分钟=31分钟。效率基本上是上一种方法的一倍。
需求6:对比,思考总结
- 2000台真的比一台速度快吗? 如果考虑分发上传文件的时间呢?
如果不考虑分发数据时间,确实比一台快超级多。
如果考虑分发数据时间,当数据为1T时,确实没有一台快。因为网卡分发速度为200MB/S,,分发到2000台要30分钟*5=2小时30分钟,然后再加上计算完成的时间31分钟左右,差不多分布式版要3个小时。而单机版却只要1个小时左右。
- 如果考虑每天都有1T数据的产生呢? 如果增量了一年,最后一天计算数据呢?
每天都有1T数据,那肯定是
分布式效率最高。
当是单机版,1T是需要1个小时,365天就是365个小时。
当时分布式版,全量导入进去,只需要2个小时30分钟,因为是并行。计算全量数据的时候就按9个小时,那么一共才需要12个小时左右。
所以单机版365个小时,分布式版12个小时,肯定是分布式版效率更加之高。
- 分布式文件系统那么多,为什么hadoop项目中还要开发一个hdfs文件系统?
因为,
HDFS可以将数据进行分块处理,很大一部分程度提高数据计算效率。此外,HDFS还有一些独有的特点,比如副本放置策略,也能高效的提高效率,再加上是并行运行,效率更加得以凸显。因此,HDFS是特别合适得存储文件系统,应用到Hadoop生态之中。
三.对比得出什么结论?

这些结论是
十分核心的,具有重大意义。思考,是学习效率的重要方式。
学习知识的时候要去搞明白它存在的意义,这样学习成本才会低!
后面我会持续更新,喜欢的小伙伴可以关注或者点赞评论哟…















 4649
4649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











