









引言
- 相信大家一定知道信号量。在上学的时候,老师讲到操作系统,一般都会说信号量;并会列举出信号量解决了哪些问题,例如生产者消费者的同步问题、科学家就餐等问题,解决这些问题就会使用到pv信号量来解决多线程间的同步问题;由多线程间的同步,我们又会想到线程间的通信常用的六种方式为:信号量、匿名管道、命名管道、socket、共享内存空间、消息队列;通过这六种方式,我们就可以实现线程间的通信。我们会发现,只要是线程间的问题,大部分都可以使用信号量解决,而我们本文所说的管程就是和信号量等价的,信号量能够解决的问题,使用管程也能够解决。那有些人就会问:既然管程能解决的,使用信号量就能够解决,并且我们都学习过信号量,为什么还要再学管程?在这里,我的理解是:信号量的使用门槛是比较高的,稍有不慎就会出现问题,没有一个固定的思考范式,而管程就不一样了,我们可以把管程抽象成一个小区,这个小区只有一个出入口,在人多的时候,我们需要排队刷门禁卡进入小区;在这里,我们的临界区就是小区,加锁的位置就是小区刷门禁卡进来的位置,解锁的位置就是刷门禁卡出去的位置。结果上述的抽象,我们就可以形成一种意识:涉及到并发代码的部分就是小区,我们需要在这部分代码前后设置好加解锁的位置。
正题
- 在java1.5之前,java里面只有synchronized、wait、notify、notifyAll等方式,这些方式实际上用的就是管程。我的理解是:synchronized包起来的代码块部分就是小区,wait就是相当于你的朋友让你去小区外面等他,notify是你通知某一个人可以进入小区,notifyAll是你用大喇叭告诉所有的人此时可以进小区。进入小区之后,还会进入某一幢楼,这个时候要满足一定的条件才可以进入,如果不满足,就会让你等着,等到满足条件之后,才可以允许你进入。
- 管程通常有三种模型:Hasen模型、Hoare模型、MESA模型。这三种模型只是在通知方式上有所不同,例如t1线程因为不满足某些条件开始阻塞,t2线程执行了一些步骤之后导致t1线程所需要的条件满足了,这个时候就需要通知t1线程。
Hasen模型
- 要求t2线程在结束的时候通知t1线程,相当于notify()、notifyAll()写在最后面;适用于生产者-消费者场景
Hoare模型
- 要求t2在t1满足条件后,立即通知t1,t2开始阻塞直到t1运行结束,相当于调用join(),相比较于Hasen模型,多了一步等待t2线程被唤醒继续执行;适用于主线程依赖子线程执行结果的场景。
MESA模型
- t2通知完t1线程之后,并不会立即进入阻塞状态,而是会继续执行,t1进入到入口处的等待队列中,等待再次进入、再次判断条件是否满足。相比较于Hoare模型,此处没有t2再次被唤醒的过程,只是t1执行的时候,条件不一定满足了,所以一般需要循环判断条件变量是否满足;类似于notify()、notifyAll()在t1需要的条件变量满足之后可以直接调用,不需要严格限定位置,比Hasen更具灵活性,t1响应的实时性比Hoare模型低。
- java只要使用的就是MESA模型。管程模型图大致如下
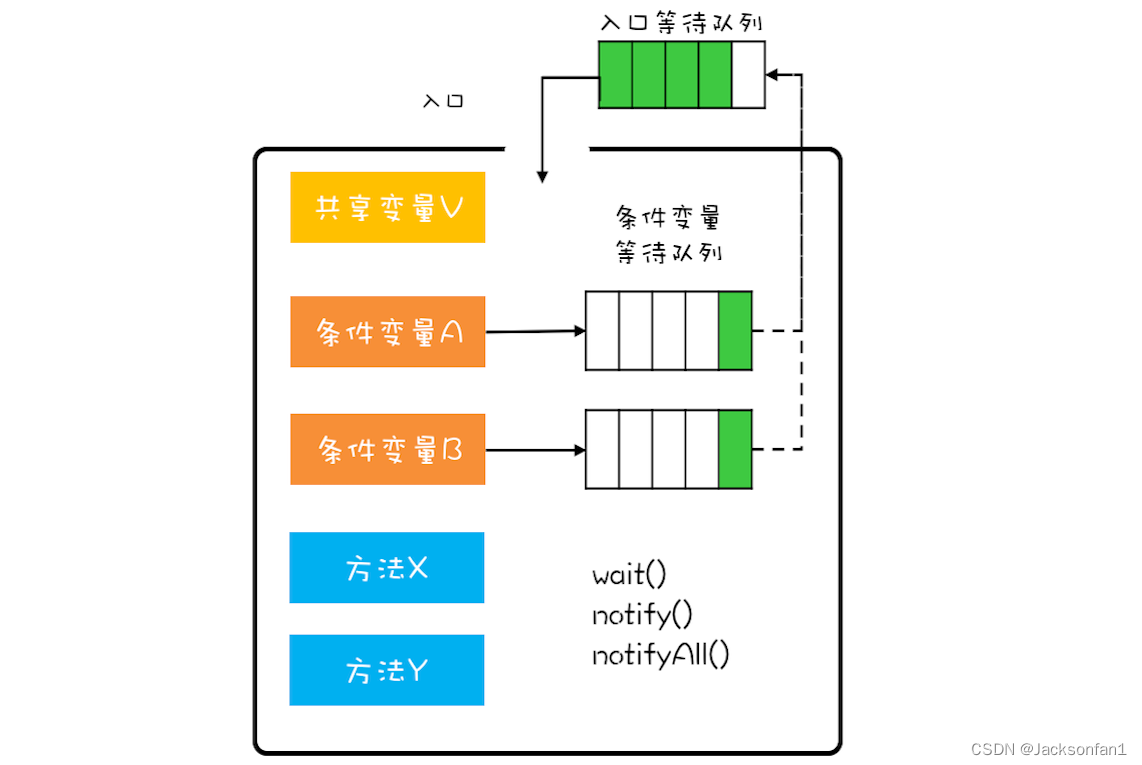
总结
通常我们会把条件变量的判断写成一个循环,因为阻塞线程再次被唤醒时,条件变量可能又不满足了,一般是这样的:
while(条件变量不满足) {
wait();
}
如果我们写成
if (条件变量不满足) {
wait();
}
当我们的线程被唤醒时,就不会再次进行条件变量的判断,这个时候是有风险的,例如涉及到电商商品库存的时候,就会造成超卖。
一般的完整流程代码如下:
类 A {
锁 lock;
方法 A () {
// 加锁
lock.lock();
while (条件变量不满足) {
wait();
}
// 通知代码,具体可根据自己的代码逻辑设置通知
notify();
// 逻辑代码
lock.unlock();
}
}
参考:
https://time.geekbang.org/column/article/86089
https://www.cnblogs.com/myworld7/p/12238796.html#_label4
https://blog.csdn.net/qq_33479841/article/details/126091931














 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









