







1.JVM
1.1类加载运行过程
当运行某个类的main函数启动程序的时候,首先会通过类加载器把主类加载到JVM
比如当我们需要加载People类时,首先会创建java虚拟机,并创建一个引导类加载器实例,创建JVM启动器实例sun.misc.Launcher该类由引导类加载器负责加载,并创建其它类加载器。通过Launcher类获取运行类自己的系统类加载器即应用类加载器AppClassLoader,通过调用其loadClass方法加载要运行的类People,加载完成后JVM会执行主类的main方法。
其中loadClass的类加载过程有
加载 >> 验证 >> 准备 >> 解析 >> 初始化 >> 使用 >> 卸载
加载过程就是从本地经过io把class文件读进内存,并生成一个java.lang.class对象,作为方法区这个类各种数据的入口。
验证阶段验证字节码文件的正确性,准备阶段就为类的静态变量分配内存,赋默认值。
解析阶段将符号引用替换为直接引用。 初始化 对类的静态变量初始化为指定的值,并执行静态代码块。
类加载到方法区后主要包含 运行时常量池,类型信息,字段信息,方法信息,类加载器的引用,对象class实例的引用(Class对象在heap,作为访问方法区的入口)
实际上,jvm是使用时才加载对应的类。
1.2类加载器
启动类加载器 负责加载javahome 下lib下的class c++实现
扩展类加载器 加载javax下的class
应用程序类加载器 加载classpath下的class
自定义加载器 加载自定义目录下的class
类加载器初始化过程:
//Launcher类 由c++创建的BootStrap类加载器加载产生实例 由该类产生其它的加载器
public Launcher() {
Launcher.ExtClassLoader var1;
try {
var1 = Launcher.ExtClassLoader.getExtClassLoader();
//将launcher内部类ExtClassLoader实例化 产生过程中,会把ext.parrent = null
//因为启动类加载器由c++实现 必然在java里无类对象
//ext 和 appclassloader都是继承自URLClassLoader内部有parrent属性
} catch (IOException var10) {
throw new InternalError("Could not create extension class loader", var10);
}
try {
this.loader = Launcher.AppClassLoader.getAppClassLoader(var1);
//实例产生应用类加载器 ,并实例过程中将该加载器的parrent指向ext类加载器
} catch (IOException var9) {
throw new InternalError("Could not create application class loader", var9);
}
Thread.currentThread().setContextClassLoader(this.loader);
String var2 = System.getProperty("java.security.manager");
if (var2 != null) {
SecurityManager var3 = null;
if (!"".equals(var2) && !"default".equals(var2)) {
try {
var3 = (SecurityManager)this.loader.loadClass(var2).newInstance();
} catch (IllegalAccessException var5) {
} catch (InstantiationException var6) {
} catch (ClassNotFoundException var7) {
} catch (ClassCastException var8) {
}
} else {
var3 = new SecurityManager();
}
if (var3 == null) {
throw new InternalError("Could not create SecurityManager: " + var2);
}
System.setSecurityManager(var3);
}
双亲委派机制:
代码实现即ClassLoader的loadclass方法
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
//先去看该类是否已经被加载过了
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
c = parent.loadClass(name, false);
//如果父类加载器不为null 则派给父类加载器加载
} else {
c = findBootstrapClassOrNull(name);
//如果父类为null 则说明到了ext加载器 其父类就为null就找bootstrap去加载
//底层调c++代码
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
//如果该类还没被加载则自己加载
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
设计双亲委派机制的原因:
1.避免类的重复加载
2.避免核心类库被修改
自定义类加载器的实现:
只需要写一个类继承ClassLoader类,该类两个核心方法 loadClass和findClass,
在loadClass方法里实现了双亲委派机制,在findclass里主要对class的扫描和define class;
如果实现自定义类加载器,需要打破双亲委派机制,可以重写loadClass里的逻辑。
如果不需要打破,就只需要重写findClass方法
public class MyClassLoader extends ClassLoader{
private String classPath;
public MyClassLoader(String classPath) {
this.classPath = classPath;
}
private byte[] loadByte(String name) throws Exception {
name = name.replaceAll("\\.", "/");
FileInputStream fis = new FileInputStream(classPath + "/" + name
+ ".class");
int len = fis.available();
byte[] data = new byte[len];
fis.read(data);
fis.close();
return data;
}
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
try {
//io读取文件
byte[] bytes = loadByte(name);
//本地方法 验证 准备 解析 初始化
return defineClass(name,bytes,0,bytes.length);
} catch (Exception e) {
e.printStackTrace();
throw new ClassNotFoundException();
}
}
打破双亲委派机制的用处:
1.tomcat
一个tomcat可以部署多个war应用程序,如果应用程序之间依赖的比如spring版本不同,如果按照传统方式,则就只能加载一个spring版本,因为类加载只在乎全限定类名,所以,对于tomcat就必须打破双亲委派机制。让每个应用程序自己加载自己所依赖的类库。
同一个JVM类,两个相同包名和类名的类对象可以共存,因为其类加载器不一样,所以看两个类是否是同一个,除了看包类名外,还要看其类加载器。
1.3 内存模型
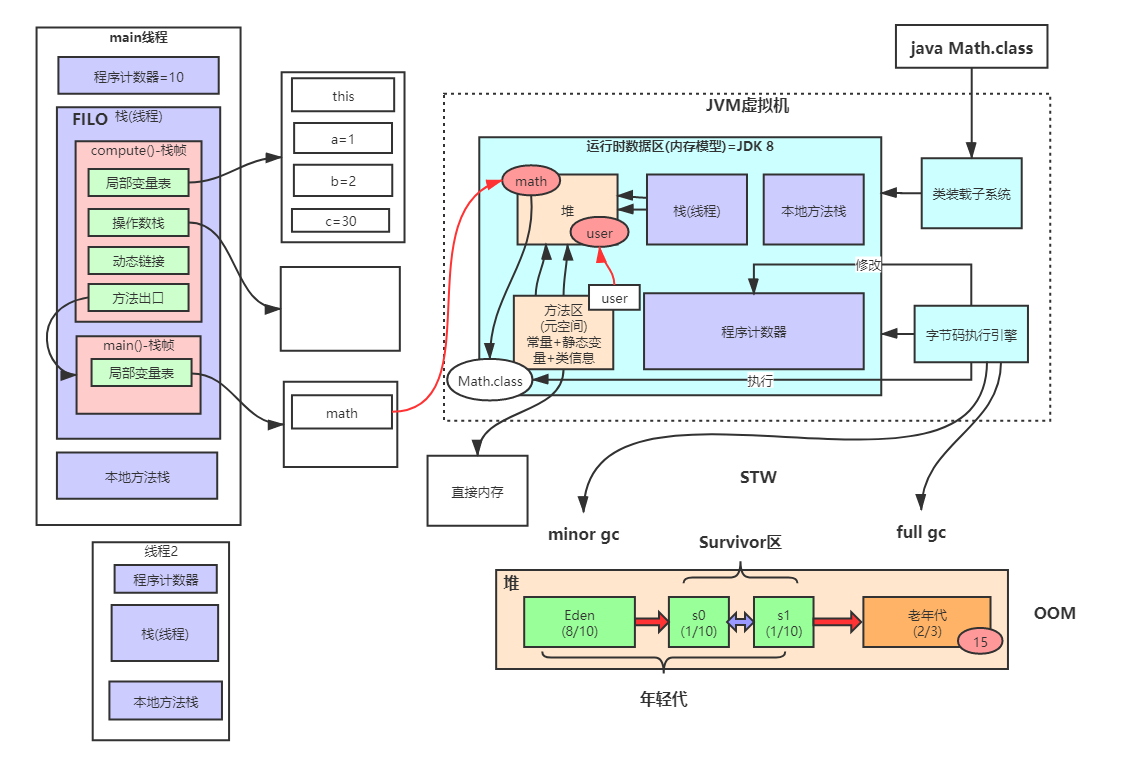
通过本地defineclass方法将class加载进JVM内存中,存在这个一个内存模型去存放类对应的数据
-
本地方法栈 本地方法的栈
-
程序计数器 字节码执行引擎根据程序计数器决定执行哪行指令
-
栈 每个方法的调用都会在栈里产生一个栈帧,这个栈帧里存放的有
- 局部变量表 该方法所有的局部变量的引用
- 操作数栈 该方法所有的操作数 例如 赋值操作 a = 3 ,3会入操作数栈
- 动态链接 将类文件编译成字节码文件时,会形成该class的常量池 常量池里会存放该类的符号引用(变量和方法) 编译器可以确定的叫静态链接,只能在运行期确定的叫动态链接。当程序运行时,就能通过这个符号引用找到相应的变量和方法(直接引用)
- 方法出口
- 局部变量表 该方法所有的局部变量的引用
-
堆 对象会被分派到这里 静态变量
-
方法区 静态变量(1.7后移到堆中),常量,类源信息。(元空间)
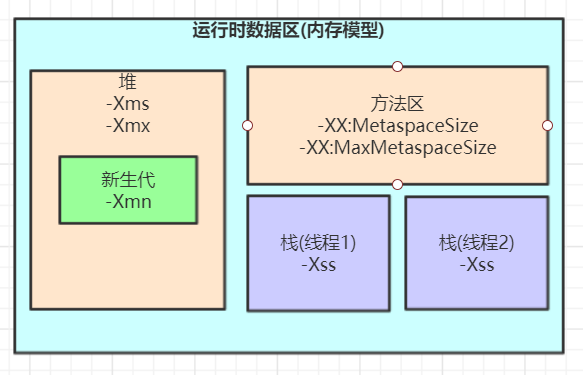
方法区 即元空间 可以设置最大值,不设置就是受限于本地内存的大小。
metspacesize指定元空间触发fullgc的初始阈值,默认21M,并且会动态调整该值。因为fullgc操作昂贵,所以避免程序启动频繁在元空间频繁fullgc可以调大该值
堆中eden区或者年轻代一定比old区小吗??
不一定,如果对于一个高并发下的订单处理系统,某时刻肯定有大量的订单对象生成,但是这些对象都是朝生夕死的对象,很快就成为垃圾对象,如果年轻代比较小,则高并发大量订单下,很多订单对象会进入老年代,但是这些订单很快就成为了垃圾对象,所以会频繁fullgc,所以可以调高年轻代的空间。
s0,s1区存在的目的也就是成为eden gen到old gen的缓冲区,让那些活的不久的对象尽量在进入old区前被gc。
1.4 类加载过程详解
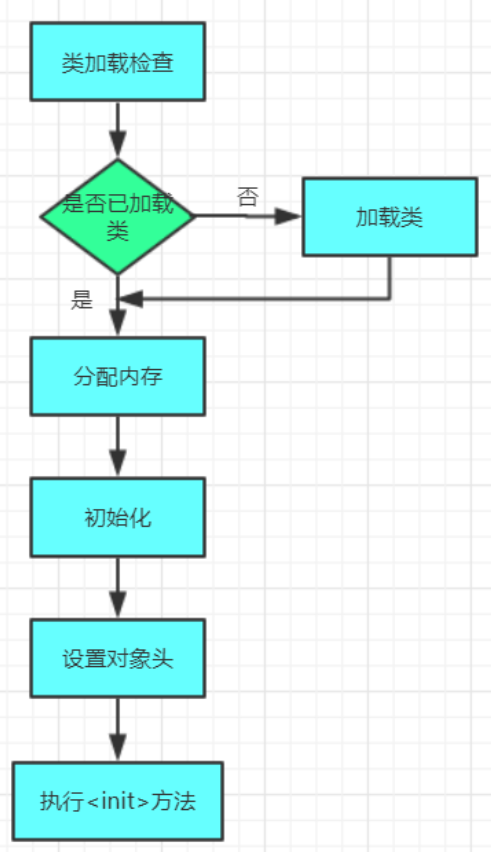
-
类加载检查 当jvm遇到new指令时,会检查该指令的参数是否能在常量池里定位到一个符号引用,看其是否被加载,解析,初始化。
-
分配内存
如何划分内存
- 指针碰撞
- 空闲列表
解决并发问题
-
CAS 保证多线程下内存的分配问题
- 本地线程分配缓冲 为每个线程在堆中分配空间。
-
初始化 为分配到的内存空间赋零值。
-
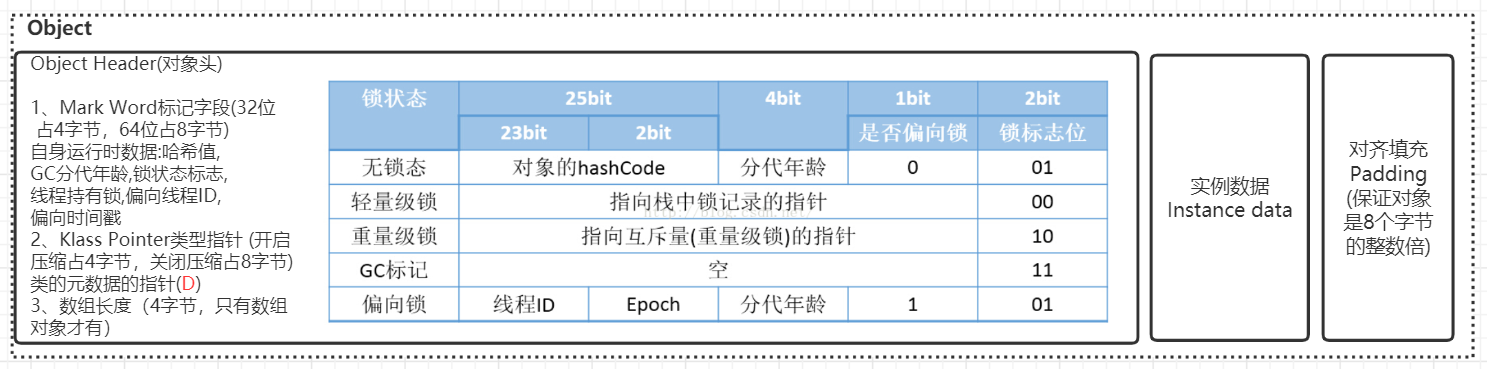
设置对象头
对象头有三部分 1. markword 2.KlassPointer 3. 数组长度
-
初始化
1.5对象内存分配
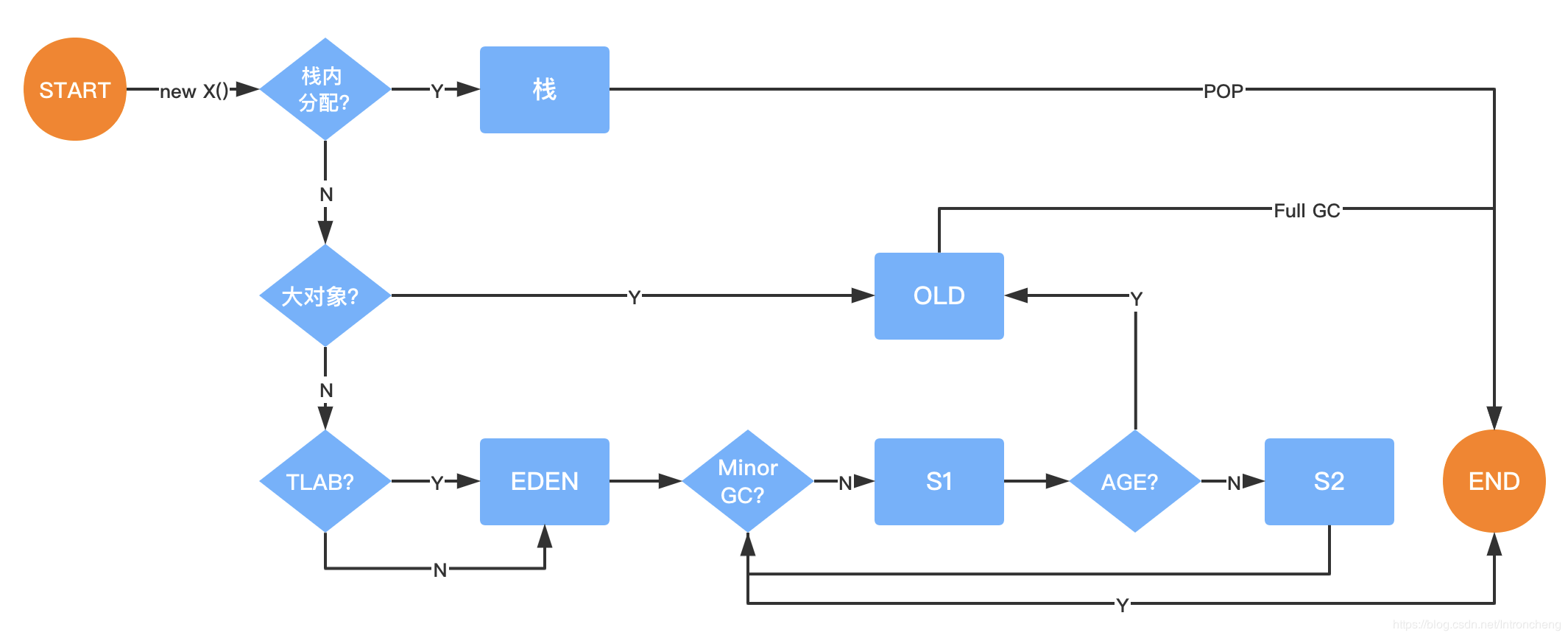
首先并不是所有对象都会直接分配到heap,JVM会通过逃逸分析确定该对象会不会被外部访问,如果不会逃逸会在栈上分配,这样方法的对象会随栈帧出栈而销毁,减轻了heap上gc的压力。不会逃逸,则才有可能发生标量替换,将聚合量替换成表量(不创建类对象,只创建其成员变量)
多数情况下,对象会优先在eden gen分配,当eden不够时,会young gc , gc时会把eden区和s0或s1区活对象放入s1或s0区,如果不够放则放入old gen .
大对象(字符串,数组)直接进入老年代,JVM参数可以设置这个阈值,这个参数只有在serial和parnew下有效,目的是避免大对象复制降低效率。
长期存活的对象进入old gen,对象头有对象的age,在young gc下 对象在s0,s1区来回移动会增加年龄,默认15(因为对象头里有4 bit存放age) CMS默认6,年龄阈值也可以参数配置。
对象动态年龄判断
在s区,当age0 + age1 + age2 + … + age n的多个年龄对象的总和超过s0区的一半,则把n(含)以上年龄的对象放入老年代,目的是在于那些可能长时间存活的对象尽早进入Old gen,在 young gc下触发。
老年代空间分配担保机制
young gc之前jvm会计算old gen剩余可用空间,看可用空间是否小于年轻代所有对象大小之和,如果小于,则会看之前young gc移动到old gen平均大小,如果young gc到old gen平均大小大于old gen可用空间则会full gc。对old gen和young gen进行gc,如果放不下会oom。
2.对象内存回收
1.引用计数法 存在垃圾对象和垃圾对象之间循环引用 所以不用
2.可达性分析法
从gc roots开始遍历所有的对象,标记所有活对象,清理其它未标记对象。
GC RootS起点 : 栈帧中 局部变量表的引用 方法区中 静态变量的引用 本地方法栈中的引用
如果不可达的对象并不会宣布死亡,如果对象没有覆盖了finalize()方法,直接回收,如果覆盖了则该方法里是对象逃脱死亡的唯一办法,则在方法里重新加一个引用链与存活的对象之间产生关联,则就不会回收。
一个对象的finalize()方法只会执行一次
方法区回收:
方法区回收无用的类,则同时满足
- 该类所有实例被回收
- 该类类加载器被回收
- 该类的Class对象没有被任何地方被引用
2.1 垃圾收集算法
分代收集理论 : 因为有的对象生存周期长,有的对象生存周期短,将堆分区,按照对应区的生命周期特点采用不同的收集算法
比如在new gen对象一般存活几率比较低,所以用标记复制算法,因为少量对象进行复制,所以效率较高
old gen对象存活几率较高,所以采用标记整理,或者标记清除算法
2.2 垃圾收集器
1.Serial
串行收集器是单线程收集器,整个收集过程会STW,new gen采用复制算法,old gen标记整理算法,较其它收集器简单高效,是CMS的备用方案 Serial Old 是old gen版本
2.Parallel
多线程收集器 默认的收集线程是cpu的核数 该垃圾收集器主要关注是吞吐量,CMS等更关注的是STW时间。
Parallel old是old gen版本
3.ParNew
和Parallel类似,与CMS组合使用
4. CMS
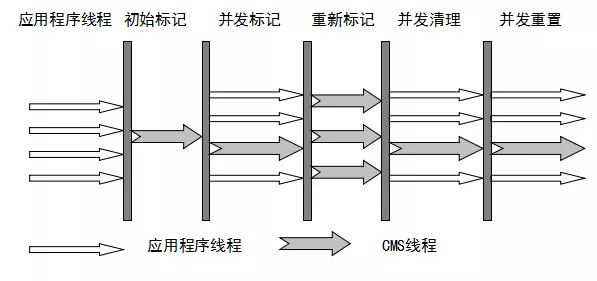
concurrent mark sweep并发标记清除算法,它能和用户线程同时工作,缩小了STW的时间。
工作流程
-
初始标记 此阶段是STW的 从GCRoots标记直接对象
-
并发标记 这个阶段采用三色标记的方法进行标记,从第一步的对象深入标记,此阶段和用户线程同时进行,则会有出现多标和漏标的可能,即一个对象是垃圾,随用户线程运行,结果不是垃圾,或者一个对象不是垃圾,随着用户线程运行,结果成了垃圾。漏标还好,这些对象在下一次gc收集就行,但多标就会导致业务代码的错误。针对这种问题,有增量更新和 原始快照两种解决办法。
-
三色标记 : 黑色表示对象已经被访问过,且这个对象的所有属性对象也被访问过,灰色表示该对象被访问过,但其对象所有属性对象没被访问完,白色表示该对象尚未被访问
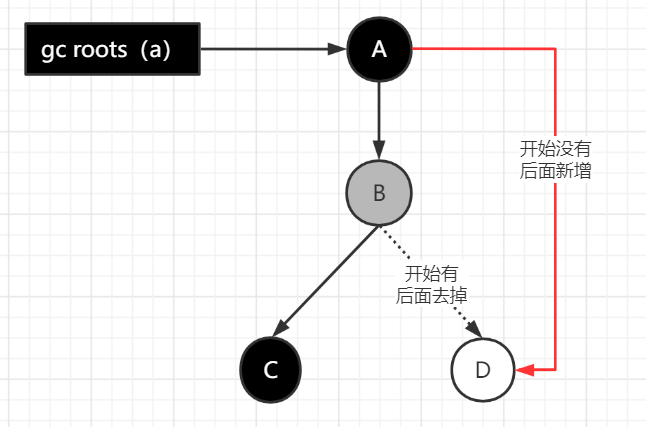
- 增量更新 : 即在并发标记阶段,如果有代码将白色对象和黑色对象进行关联,则将这种赋值的关系记录出来,等下一个阶段重新标记的时候再重新标记
- 原始快照 : 即将灰色对象要删除与白色对象的引用时,将删除的引用记录下来,重新标记阶段,将这些白色对象标记成黑色对象,目的是让这些对象存活下来,下一次gc时再做处理,也可能成为垃圾对象。
无论是引用关系的新增和删除,都是通过虚拟机的写屏障实现的,类似aop的思想,在底层进行写操作的前置后置处理
-
-
重新标记 根据上一部记录的引用关系,继续标记。
-
并发删除 删除那些白色对象,如果有新对象产生,则标记为黑色。
-
并发重置 重置颜色 为下一轮gc做准备
并发收集,STW时间短
缺点:会和服务抢资源,无法处理浮动垃圾,标记清除算法会产生空间碎片,但是可以通过设置参数可以让其标记清除后整理
并发过程不确定性,在并发阶段可能出现执行的过程中再次触发gc,则就是并发失败,则此时会进入STW,由serial old收集器收集
CMS的一些参数
-
-XX:+UseConcMarkSweepGC:启用cms
-
-XX:ConcGCThreads:并发的GC线程数
-
-XX:+UseCMSCompactAtFullCollection:FullGC之后做压缩整理(减少碎片)
-
-XX:CMSFullGCsBeforeCompaction:多少次FullGC之后压缩一次,默认是0,代表每次FullGC后都会压缩一
次
-
-XX:CMSInitiatingOccupancyFraction: 当老年代使用达到该比例时会触发FullGC(默认是92,这是百分比)
-
-XX:+UseCMSInitiatingOccupancyOnly:只使用设定的回收阈值(-XX:CMSInitiatingOccupancyFraction设
定的值),如果不指定,JVM仅在第一次使用设定值,后续则会自动调整
-
-XX:+CMSScavengeBeforeRemark:在CMS GC前启动一次minor gc,目的在于减少老年代对年轻代的引
用,降低CMS GC的标记阶段时的开销,一般CMS的GC耗时 80%都在标记阶段
-
-XX:+CMSParallellnitialMarkEnabled:表示在初始标记的时候多线程执行,缩短STW
-
-XX:+CMSParallelRemarkEnabled:在重新标记的时候多线程执行,缩短STW;
5. G1
G1适合多颗处理器,大内存的机器做垃圾回收
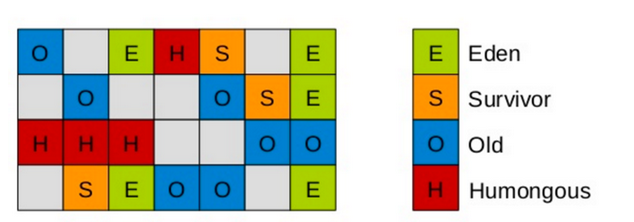
G1仍然使用分代思想,但是将堆分成了一个个的region,做到了物理上分代的不连续。
JVM最多有2048个region,new gen占5%(可调),eden : s0 : s1 = 8 : 1 : 1
一个region的分区是动态的,可能上次gc是old 下次就是eden。
不同的是,G1有了Humongous,让大对象进入该区,而不是Old gen,大对象的规则就是超过一个region大小的50%
用于存放短期巨型对象,full gc时该区也会被回收。
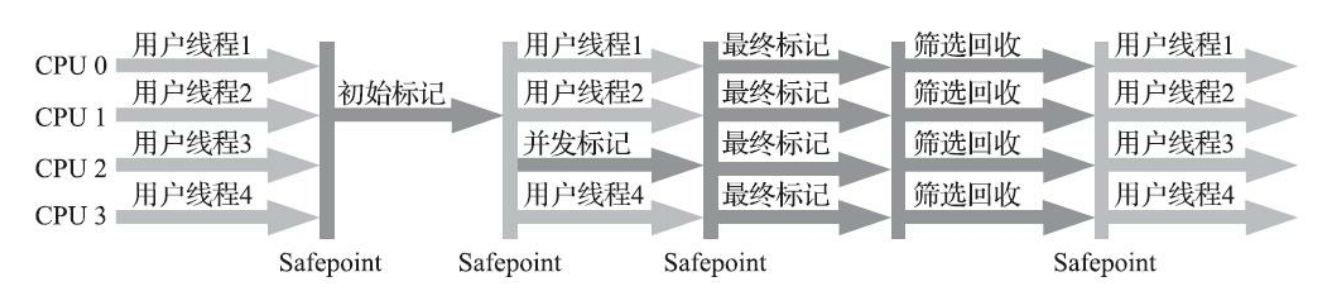
- 初始标记
- 并发标记
- 最终标记
- 筛选回收
可以看到只有第四步与CMS不同,是STW的,筛选回收,意味着该阶段会对所有的region的回收价值和成本排序,选择性的回收,根据用户指定的STW时间,可能这个阶段不会回收完所有的垃圾。回收算法是复制算法,将该region存活的对象复制到相邻的region区中,G1不会产生太多的内存碎片。
G1垃圾收集分类
-
young gc
young gc不是所有的eden放满了就会触发,而是算eden区回收大概的时间,如果远小于用户设置的时间,则不会触发,而会选择eden区扩容,增加eden gen region
-
mixed gc
不是full gc ,当老年代的空间占有率达到参数设定的值,会回收所有new gen 部分old gen(根据期望的STW时间选择)以及H区,当mixed gc 回收时,采用复制算法,如果没有空region承载对象,则会full gc
-
full gc
停止系统程序,STW采用单线程进行标记清理压缩。
参数:
-XX:+UseG1GC:使用G1收集器
-XX:ParallelGCThreads:指定GC工作的线程数量
-XX:G1HeapRegionSize:指定分区大小(1MB~32MB,且必须是2的N次幂),默认将整堆划分为2048个分区
-XX:MaxGCPauseMillis:目标暂停时间(默认200ms)
-XX:G1NewSizePercent:新生代内存初始空间(默认整堆5%)
-XX:G1MaxNewSizePercent:新生代内存最大空间
-XX:TargetSurvivorRatio:Survivor区的填充容量(默认50%),Survivor区域里的一批对象(年龄1+年龄2+年龄n的多个
年龄对象)总和超过了Survivor区域的50%,此时就会把年龄n(含)以上的对象都放入老年代
-XX:MaxTenuringThreshold:最大年龄阈值(默认15)
-XX:InitiatingHeapOccupancyPercent:老年代占用空间达到整堆内存阈值(默认45%),则执行新生代和老年代的混合
收集(MixedGC),比如我们之前说的堆默认有2048个region,如果有接近1000个region都是老年代的region,则可能
就要触发MixedGC了
-XX:G1MixedGCLiveThresholdPercent(默认85%) region中的存活对象低于这个值时才会回收该region,如果超过这
个值,存活对象过多,回收的的意义不大。
-XX:G1MixedGCCountTarget:在一次回收过程中指定做几次筛选回收(默认8次),在最后一个筛选回收阶段可以回收一
会,然后暂停回收,恢复系统运行,一会再开始回收,这样可以让系统不至于单次停顿时间过长。
-XX:G1HeapWastePercent(默认5%): gc过程中空出来的region是否充足阈值,在混合回收的时候,对Region回收都
是基于复制算法进行的,都是把要回收的Region里的存活对象放入其他Region,然后这个Region中的垃圾对象全部清
理掉,这样的话在回收过程就会不断空出来新的Region,一旦空闲出来的Region数量达到了堆内存的5%,此时就会立
即停止混合回收,意味着本次混合回收就结束了
什么场景适合使用G1
-
50%以上的堆被存活对象占用
-
对象分配和晋升的速度变化非常大
-
垃圾回收时间特别长,超过1秒
-
8GB以上的堆内存(建议值)
-
停顿时间是500ms以内
3. JVM调优
JVM主要调优的目的是减少full gc次数和STW时间
例如像导致full gc的原因
- 大对象到old gen会导致full gc
- 动态年龄判断
- Old gen担保机制 (提高old gen的大小或者提高CMS在old gen触发full gc的占用比例)
- metaspace初始动态扩容 这个启动项目时调参数
在业务系统里,尽量让朝生夕死的对象提前在new gen里被回收,不要进入到old gen,例如在young gc时,每秒产生大部分很快死亡的对象,那在gc前一秒会有很多活的对象还未死亡,如果进入S0,很容易使得S0的占用达到一半,导致很多很快就死亡的对象提前进入到Oldgen,优化方法就是提高new gen的内存大小。
除了基础的一些自带的jdk监控命令之外,还有像Arthas的图形化工具等
4.常量池
Class常量池 放Class类元信息,存在字面量和符号引用
字面量就比如字母,数字构成的字符串或者数值常量
例如 int a = 1 ,1就是字面量
符号引用就比如方法引用,字段引用,类引用
在编译成字节码时会生成Constant pool,例如方法全限定名,字段全限定名都会放在池子里,也是静态常量池,当字节码编译成机器指令加载到内存,则这运行时常量池在内存里有一块儿区域,像方法的符号引用compute()在运行时由动态链接到运行时常量池,则执行compute()放法时就知道这个方法的方法体。
字符串常量池
字符串分配耗费时间和空间,大量创建影响性能,所以用常量池优化
为字符串开辟一个字符串常量池,类似缓存。
三种字符串操作
String s = "hi"
出现字面量,则优先去常量池查找,如果没有则常量池里创建
String s = new String("hi");
出现字面量,先去常量池里查找或创建,最后都会在堆里创建"hi"
String s1 = new String("zhuge");
String s2 = s1.intern();
System.out.println(s1 == s2); //false
//intern()方法 如果池中有 返回池中的引用 如果池中没有heap有返回heap的引用 如果都有返回池中的引用
字符串常量池在堆中.静态变量也在堆中
还有八大基本类型的包装类都实现了常量池技术,在堆上例如Integer 默认缓存-128 — 127
有一块儿区域,像方法的符号引用compute()在运行时由动态链接到运行时常量池,则执行compute()放法时就知道这个方法的方法体。
字符串常量池
字符串分配耗费时间和空间,大量创建影响性能,所以用常量池优化
为字符串开辟一个字符串常量池,类似缓存。
三种字符串操作
String s = "hi"
出现字面量,则优先去常量池查找,如果没有则常量池里创建
String s = new String("hi");
出现字面量,先去常量池里查找或创建,最后都会在堆里创建"hi"
String s1 = new String("zhuge");
String s2 = s1.intern();
System.out.println(s1 == s2); //false
//intern()方法 如果池中有 返回池中的引用 如果池中没有heap有返回heap的引用 如果都有返回池中的引用
字符串常量池在堆中.静态变量也在堆中
还有八大基本类型的包装类都实现了常量池技术,在堆上例如Integer 默认缓存-128 — 127
















 240
240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











