







一致性协议
背景
当网站流量很小时,只需要一个应用,并且把这个应用部署到一个机器上,就是传统的单机应用。随着流量的增大,单机应用已经不满足需求,将该应用部署到多个机器上,使用负载均衡算法将流量打在不同的机器上,就是垂直应用结构,当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,形成服务中心,就是分布式服务架构。
CAP理论
- Consistency一致性 是指强一致性,即当有一个数据库集群mysql A和B,有一个x值为1,用户a修改x=2,然后用户b从B读取x的值。当用户a修改了A机器的值,此时会把数据同步到B。
- 强一致性要求用户b读取的时候x的值必须为2 要求数据库中同步很快速
- 弱一致性 就是用户b读取的时候可以读到1
- 最终一致性 是指 用户b读取值时可以先读到1 ,过一段时间后读到2 就是最终一致性
- Availability 可用性 指服务一直可以用,是正常响应时间,也就是对用户而言有好的用户体验,不出现用户操作失败或者超时。
- Partition tolerance 分区容错性 是指分布式系统中某节点或者某分区故障后,整体仍然能对对提供服务
当错误发生的时候,CAP是不能同时满足的。分布式对于单机,最大的区别在于网络,当某节点网络错误,对机器A的写操作未能同步到B,而另外的用户对于B读取数据,由于数据没有同步,应用程序没法立即给用户返回最新的数据,此时有两种选择
- 牺牲 C 返回旧数据
- 牺牲 A 直至网络恢复再返回新数据
对于一个分布式系统要么AP,要么CP
因为不能没有P,如果舍弃P就舍弃分布式系统了
对于何种选择,其实是按场景来选择的。对于钱财类的那肯定选择CP
Base理论
Base理论是对CAP的延申,是指应用无法达到CAP的强一致性,但是可以实现最终一致性
单机应用下不存在一致性问题,再分布式下,如果用户a对数据库A中X=1,网络原因B为同步到,而用户b对数据库B中X=2,则数据库集群下,对于X的值的一致性问题就出现了,到底是都是1还是都是2,怎么实现一致性,也就是共识
一致性算法
-
主从同步 强一致性
主从架构下,master接收写请求,master复制日志到slave节点,等待所有slave响应成功,返回客户端结果
一个节点失败,导致整个集群不可用,保证了一致性,可用性降低
-
多数派
保证每次写入大于n/2个节点,每次读保证从大于N/2个节点中读
但是并发情况下,多数派无法保证系统正确性,顺序非常重要
例如,对x的两个操作对集群中的两个机器作用,
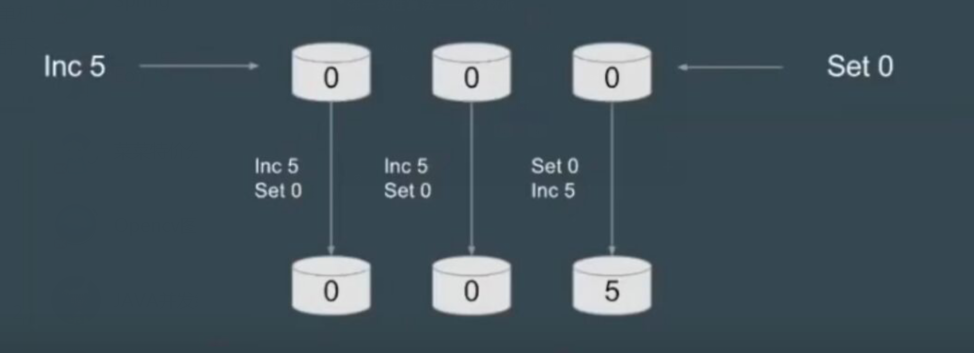
所以多数派还是有问题
Paxos
该算法参考了城邦的一会制度。分为三个角色proposer,acceptor,leaner.
proposer提出议案,Acceptor对议案进行投票,只有在大多数时,提议才会接收,leaner负责记录议案
阶段:
-
prepare阶段 proposer对提案编号为N,N大于之前所有的提案编号
-
Promise阶段 如果N大于Acceptor之前接收的提案编号,则接收,否则拒绝
-
accept阶段 如果达成了多数派,proposer会发出accept请求,该请求包含提案编号N和提案内容
-
Accepted阶段 如果acceptor在此期间没有收到大于N的提案,则接收提案内容,否则忽略

客户端发起一个请求到proposer,第一回合proposer和acceptor商量提案编号N,编号多数派通过,则proposer把提案告诉acceptor,acceptor不管提案内容,只在乎这这个N,也就是说如果没有收到大于N的提案,就接收了,最后告诉Leaner,最后返回客户端结果。
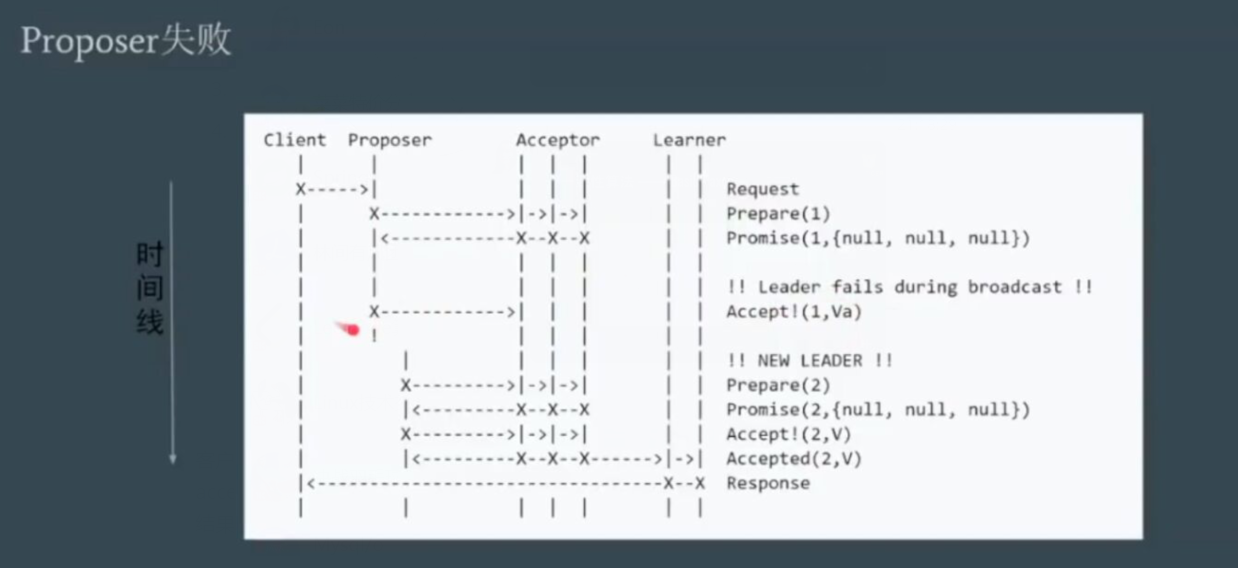
此时,proposer先商量提案编号1,都通过了,但是返回的时候proposer宕机了,当另外的proposer发起商量提案2,则提案2通过,此时如果提案1的重连回来,因为2>1,则acceptor不会通过。
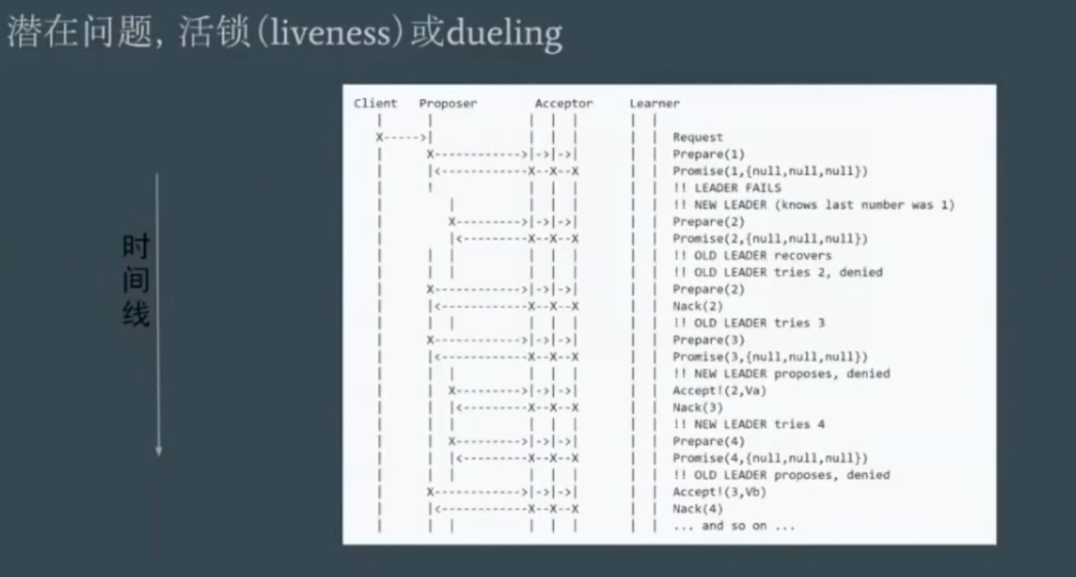
此时,如果网络原因导致这种问题,两个Proposer一直在争抢提案编号问题。
可以设置随机等待时间,让proposer等待避让其它的proposer先完成
Multi Paxos
basic paxos的问题:
难实现,效率低(两轮RPC),活锁
因此Multi paxos引入了leader,唯一的proposer,所有请求经过此leader
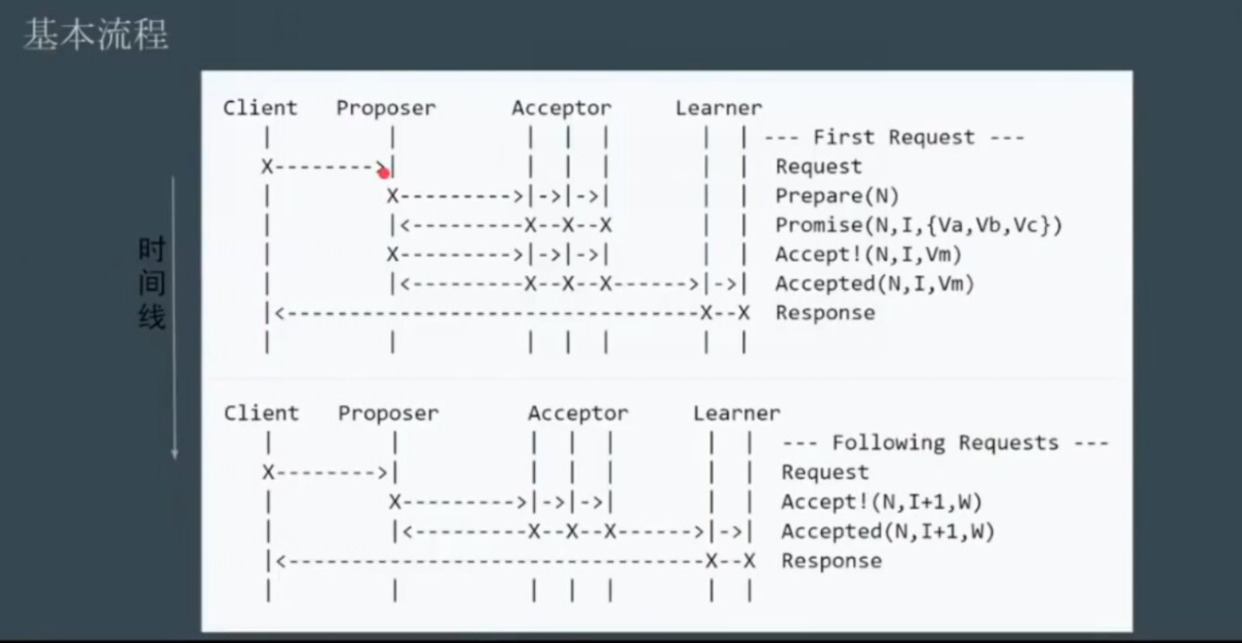
Proposer会去竞选第n任leader,竞选成功后,所有的提案都是由该Proposer提出,所以就不用在意编号的问题,因为一个Proposer提案就不会冲突。
由原来的两轮rpc,到除了竞选总统外都是一轮rpc。
Raft
简单版本的mutli paxos
分成三个子问题 : 1. leader选举 2. 日志同步 3.共识一致
三个角色 : 1. leader 2. follower 3. candidate
开始,所有的节点都是follower,每个节点有个随机超时时间,最先超时的节点会成为candidata,会发起leader竞选,任期加1,会给自己投一票,并告诉其它节点都来投他自己,此时其它节点收到消息会响应,当多数派节点响应成功,该candidate会成为leader,并发心跳包给其它follower.
所有的write请求都会打到leader,而leader首先在自己这里保存事务日志,在广播到其它所有follower,其它follower先不commit只是存到本地,并响应leader,当多数派follower响应成功,此时leader会commit,而且再后面的心跳包中告诉follower commit
所有的日志和leader保持一致
脑裂问题
当出现了分区,一个集群和另外一个集群出现了网络等故障,因为集群一般都设置为奇数节点
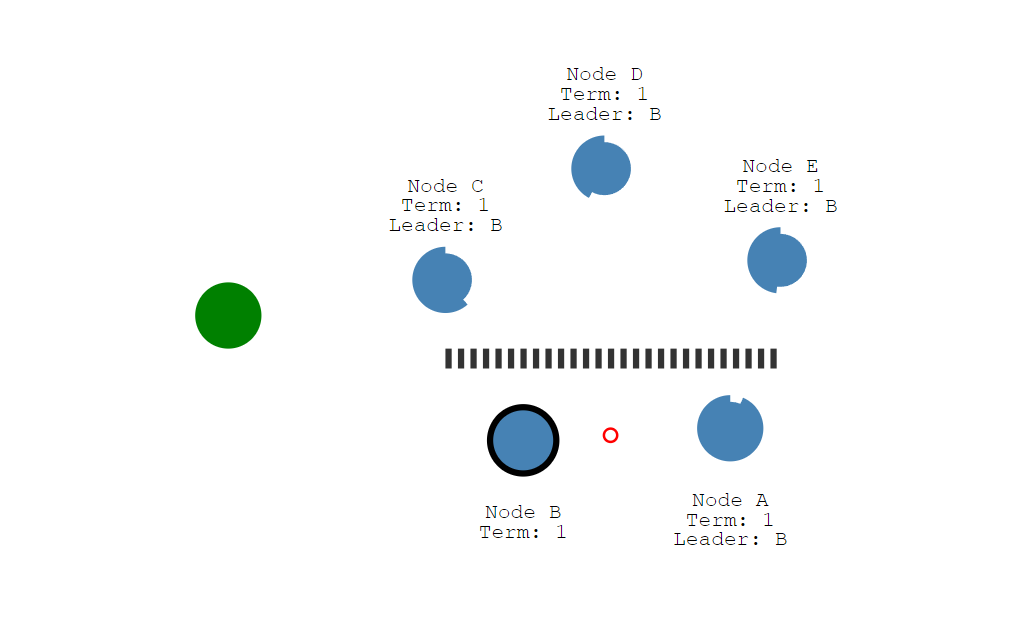
此时出现分区故障,由于上面集群节点收不到leader心跳,会触发超时,重新竞选leader,而上面集群的leader竞选也会成功,
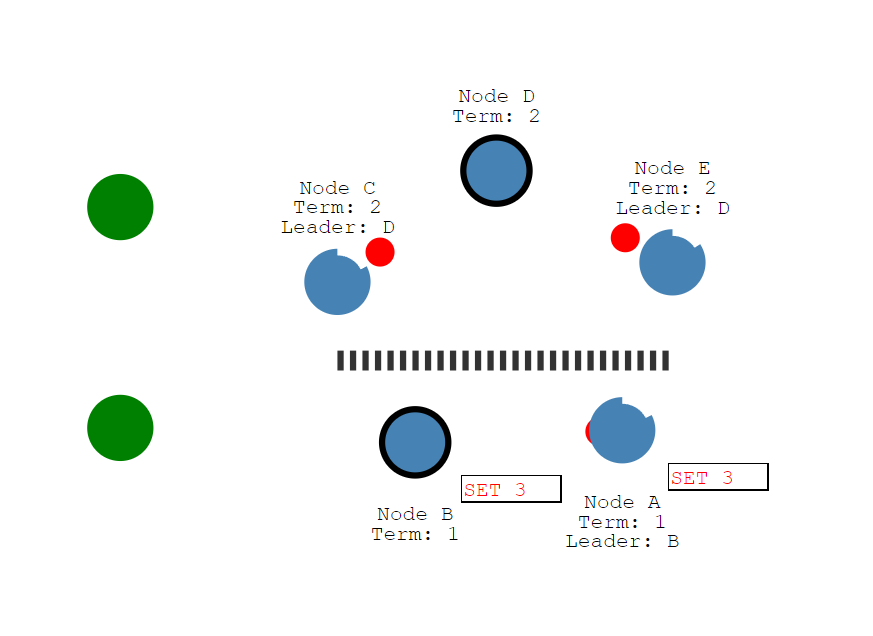
此时,如果两个客户端一个同上面集群发起写请求,一个在下面集群发起写请求。
Node D因为能接收到多数派follower的日志同步信息,而使得日志能提交
而Node B因为收不到多数派的日志同步信息,导致日志不能提交
当分区恢复,Node B会同步Node D的所有数据,因为超时后竞选leader 任期会加一,低任期的leader会同步高任期的leader,而未提交的日志会覆盖,且此时只有Node D这一个leader。
ZAB协议
ZAB和Raft很相似
因为mutli-paxos无法保证顺序性。只实现了达成共识,值一致,而不在乎值是什么
ZAB和Raft保证了顺序性,而且做法很相似,都是基于日志。
一切都与主节点保持一致
日志项多的节点,最完备的节点才能当选领导者.
ader。
ZAB协议
ZAB和Raft很相似
因为mutli-paxos无法保证顺序性。只实现了达成共识,值一致,而不在乎值是什么
ZAB和Raft保证了顺序性,而且做法很相似,都是基于日志。
一切都与主节点保持一致
日志项多的节点,最完备的节点才能当选领导者.
















 2377
2377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











