









Token
在继续前行之前,需要先停下来澄清下Token这个词,以及如何将原始的语料转化为Token,在细究背后的原理之后会更加优雅的理解大模型。任何的资讯都可以生成语料,而这些语料需要被机器理解以及供后续的模型训练,那么最常见的做法是将一段文字先切片,然后一一对应的转化为数字或者向量输入模型。通常而言有三种类型的分词法:基于单词、字符以及子词的分词法。单词和字符这里就不解释,字词法运用得最为广泛,也是最为主流。字词分词法包含了BPE、WordPiece、Unigram等。GPT等主流大模型也是采用BPE的分词法。
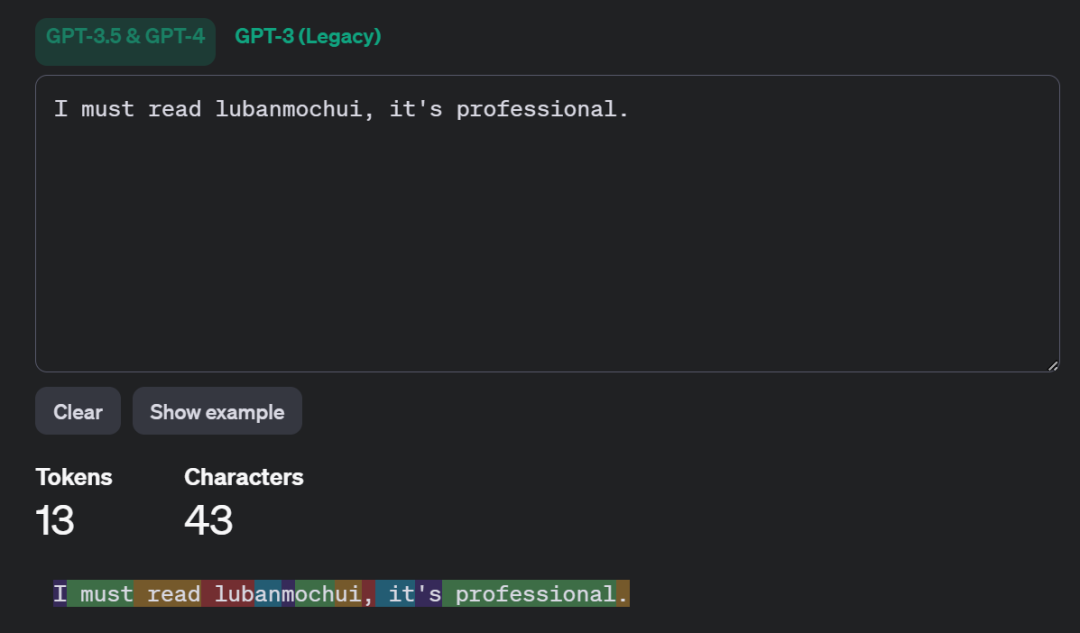
先从个列子开始以GPT-3.5为例,输入“I must read lubanmochui, it's professional.”,下图则表明整句话一共43个字符,按照不同的颜色块被切分成13份(Token)。而且每个Token都有与之对应的i
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









