






一、 机器学习的一些概念 有监督、无监督、泛化能力、过拟合欠拟合(方差和偏差以及各自解决办法)、交叉验证
-
监督学习:
数据 ===> 结果(已提前知道),输入和输出之间有着一个特定的关系。
1.1 监督学习分类:

案例:
回归:结果是连续值(应用场景:房价预测)
预测一个给定面积的房屋的价格就是回归问题。这里我们可以把价格看成是面积的函数,它是一个连续的输出值。
从“面积—价格”的坐标系中找到一条线可以近似满足面积—价格的关系。

房价预测步骤

分类:结果是离散值(应用场景:判断肿瘤的良性or恶性) Tips:分类有二分类和多分类给定医学数据,通过肿瘤的大小来预测该肿瘤是恶性or良性,这就是一个分类问题,输出0或者1两个离散的值。(0代表良性,1代表恶性)。
下图有两个轴,Y轴表示是否是恶性瘤,X轴表示瘤的大小;

上面的图我们只是简单的用了一个特征:肿瘤的大小判断,但有时候我们需要用到两个甚至多个特征才能进行判断,如下图,我们用 x : 肿瘤大小,y:年龄两个特征进行判断,在坐标系中用了不同的标记,用O表示良性瘤,X表示恶性瘤。如图

-
无监督学习:
数据 ===> 结果(提前不知道),但我们可以通过聚类的方式从数据中提取一个特殊的结构。
Tips:在无监督学习中给定的数据是和监督学习中给定的数据是不一样的。在无监督学习中给定的数据没有任何标签或者说只有同一种标签。如下图所示:

如下图所示,在无监督学习中,我们只是给定了一组数据,我们的目标是发现这组数据中的特殊结构。例如我们使用无监督学习算法会将这组数据分成两个不同的簇,,这样的算法就叫聚类算法。

无监督案例:新闻分类:Google News
Google News搜集网上的新闻,并且根据新闻的主题将新闻分成许多簇, 然后将在同一个簇的新闻放在一起。如图中红圈部分都是关于BP Oil Well各种新闻的链接,当打开各个新闻链接的时候,展现的都是关于BP Oil Well的新闻。

- 泛化能力
泛化能力就是模型对未知数据的预测能力。在实际当中,我们通常通过测试误差来评价学习方法的泛化能力。
泛化误差的定义:

## 大家很快就能发现,这不是损失函数的期望吗?没错,泛化误差就是所学习到的模型的风险函数或期望损失。
机器学习的目标:减小学习后的估计值和真实值的误差。比如在回归中,我们的 loss function 就表示一个误差。而我们需要做的,就是最小化这个误差,也就是对 object function 的处理。
判断学习模型好坏的标准:交叉验证求取泛化误差,泛化误差越小越好
- 交叉验证
将原始数据分成二八分组,20%做测试数据,剩下的80%均分成k份,每次拿出1份做验证数据,剩下的k-1份做训练数据,这样会得到K个模型,用这K个模型最终的验证集的分类准确率的平均数作为此K-CV下分类器的性能指标。(泛化误差)
tips:K一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取2。

Q:交叉验证在做什么?
A:多组模型,我们就需要测试每一个模型训练后的泛化误差,从而选择最佳的模型。每一个模型自然对应着一组最佳的参数,可以由最小化 loss function 来得到。
交叉验证的意义在于,不是选最佳的参数,而是对每一个可能的模型,用训练集最小化 loss function 的误差从而得到最佳参数后,运用验证集来算出泛化误差。通过对泛化误差的评估来选出最优的模型。
Tips:什么是模型?
我一直理解为模型就是不同参数下的同一种假设函数。实际上是完全错误的。模型指的是假设函数长什么样子,比如在回归问题中,我的假设函数可能是一个二次函数,也可能是三次甚至更高的多项式。
所以我的理解就是: 训练集的作用是最小化 loss function 这样一个误差,从而能够得到最佳的参数,他不管你输入的是什么模型;验证集的作用是求取一个模型的泛化误差,它默认在测试后已经得到了该模型的最佳参数。所以交叉验证的核心在于验证集!
- 过拟合欠拟合
训练结果反馈:一般有三种叫法,欠拟合,拟合,过拟合。
下面三个图分别展示的是欠拟合,合适拟合,过拟合

针对线性回归的欠拟合,拟合,过拟合。

针对逻辑回归的欠拟合,拟合,过拟合。

通俗版:
欠拟合:光看书不做题觉得自己会了,上了考场啥都不会。
过拟合: 课后题全能做对但是理解的不好,好多题答案都是强背下来的,上考场变一点儿人就懵逼
Q:如何防止过拟合?
A:应该用cross validation,交叉比对。
解释起来就是,你在你表妹那儿学到的东西,在你表姐那儿测试一下对不对。在你表姐那儿学到的,在你二姐那测试一下。来来回回用不同的测试对象和训练对象做交叉比对。这样学到规律就不会过拟合啦~
差不多的拟合: 做了题,背了老师给画了重点,考试60分过了。
优秀的拟合: 课后题全能作对,考试100分。
特征选择就是划重点
一个人如果连身边时时见、日日见的现有环境都适应不了,这叫欠拟合,说白了是缺少训练
如果在已有环境如鱼得水,新环境下分分钟死翘翘,这叫过拟合,说白了是在小数据范围内过渡训练
专业版:
在训练数据不够多时,或者over-training时,经常会导致over-fitting(过拟合)。其直观的表现如下图所所示。

随着训练过程的进行,模型复杂度,在training data上的error渐渐减小。可是在验证集上的error却反而渐渐增大——由于训练出来的网络过拟合了训练集,对训练集以外的数据却不work。
机器学习中,经常将原始数据集分为三部分:训练集(training data)、验证集(validation data)、测试集(testing data)。
1.validation data是什么?
事实上validation data就是用来避免过拟合的。在训练过程中,我们通经常使用它来确定一些超參数(比方,依据validation data上的accuracy来确定early stopping的epoch大小、依据validation data确定learning rate等等)。那为啥不直接在testing data上做这些呢?由于假设在testing data做这些,那么随着训练的进行,我们的网络实际上就是在一点一点地overfitting我们的testing data,导致最后得到的testing accuracy没有什么參考意义。因此,training data的作用是计算梯度更新权重,testing data则给出一个accuracy以推断好坏。
2.防止过拟合方法主要有:
1.正则化(Regularization)(L1、L2(L2 regularization也叫权重衰减,weight decay))
2.数据增强(Data augmentation),也就是增加训练数据样本
3.Dropout
4.early stopping
L2正则:
L2 正则化公式非常简单,直接在原来的损失函数基础上加上权重参数的平方和:

其中,Ein 是未包含正则化项的训练样本误差,λ 是正则化参数,可调。但是正则化项是如何推导的?接下来,我将详细介绍其中的物理意义。
我们知道,正则化的目的是限制参数过多或者过大,避免模型更加复杂。例如,使用多项式模型,如果使用 10 阶多项式,模型可能过于复杂,容易发生过拟合。所以,为了防止过拟合,我们可以将其高阶部分的权重 w 限制为 0,这样,就相当于从高阶的形式转换为低阶。
为了达到这一目的,最直观的方法就是限制 w 的个数,但是这类条件属于 NP-hard 问题,求解非常困难。所以,一般的做法是寻找更宽松的限定条件:

上式是对 w 的平方和做数值上界限定,即所有w 的平方和不超过参数 C。这时候,我们的目标就转换为:最小化训练样本误差 Ein,但是要遵循 w 平方和小于 C 的条件。
下面,我用一张图来说明如何在限定条件下,对 Ein 进行最小化的优化。


如上图所示,蓝色椭圆区域是最小化 Ein 区域,红色圆圈是 w 的限定条件区域。在没有限定条件的情况下,一般使用梯度下降算法,在蓝色椭圆区域内会一直沿着 w 梯度的反方向前进,直到找到全局最优值 wlin。例如空间中有一点 w(图中紫色点),此时 w 会沿着 -∇Ein 的方向移动,如图中蓝色箭头所示。但是,由于存在限定条件,w 不能离开红色圆形区域,最多只能位于圆上边缘位置,沿着切线方向。w 的方向如图中红色箭头所示。
那么问题来了,存在限定条件,w 最终会在什么位置取得最优解呢?也就是说在满足限定条件的基础上,尽量让 Ein 最小。
我们来看,w 是沿着圆的切线方向运动,如上图绿色箭头所示。运动方向与 w 的方向(红色箭头方向)垂直。运动过程中,根据向量知识,只要 -∇Ein 与运行方向有夹角,不垂直,则表明 -∇Ein 仍会在 w 切线方向上产生分量,那么 w 就会继续运动,寻找下一步最优解。只有当 -∇Ein 与 w 的切线方向垂直时,-∇Ein在 w 的切线方向才没有分量,这时候 w 才会停止更新,到达最接近 wlin 的位置,且同时满足限定条件。


-∇Ein 与 w 的切线方向垂直,即 -∇Ein 与 w 的方向平行。如上图所示,蓝色箭头和红色箭头互相平行。这样,根据平行关系得到:

这样,我们就把优化目标和限定条件整合在一个式子中了。也就是说只要在优化 Ein 的过程中满足上式,就能实现正则化目标。
接下来,重点来了!根据最优化算法的思想:梯度为 0 的时候,函数取得最优值。已知 ∇Ein 是 Ein 的梯度,观察上式,λw 是否也能看成是某个表达式的梯度呢?
当然可以!λw 可以看成是 1/2λw*w 的梯度:

这样,我们根据平行关系求得的公式,构造一个新的损失函数:

之所以这样定义,是因为对 Eaug 求导,正好得到上面所求的平行关系式。上式中等式右边第二项就是 L2 正则化项。
这样, 我们从图像化的角度,分析了 L2 正则化的物理意义,解释了带 L2 正则化项的损失函数是如何推导而来的。
L1正则:
在原始的代价函数后面加上一个L1正则化项,即全部权重w的绝对值的和

Ein 优化算法不变,L1 正则化限定了 w 的有效区域是一个正方形,且满足 |w| < C。空间中的点 w 沿着 -∇Ein 的方向移动。但是,w 不能离开红色正方形区域,最多只能位于正方形边缘位置。其推导过程与 L2 类似,此处不再赘述。

Ein 优化算法不变,L1 正则化限定了 w 的有效区域是一个正方形,且满足 |w| < C。空间中的点 w 沿着 -∇Ein 的方向移动。但是,w 不能离开红色正方形区域,最多只能位于正方形边缘位置。其推导过程与 L2 类似,此处不再赘述。
L1 与 L2 解的稀疏性
介绍完 L1 和 L2 正则化的物理解释和数学推导之后,我们再来看看它们解的分布性。

以二维情况讨论,上图左边是 L2 正则化,右边是 L1 正则化。从另一个方面来看,满足正则化条件,实际上是求解蓝色区域与黄色区域的交点,即同时满足限定条件和 Ein 最小化。对于 L2 来说,限定区域是圆,这样,得到的解 w1 或 w2 为 0 的概率很小,很大概率是非零的。
对于 L1 来说,限定区域是正方形,方形与蓝色区域相交的交点是顶点的概率很大,这从视觉和常识上来看是很容易理解的。也就是说,方形的凸点会更接近 Ein 最优解对应的 wlin 位置,而凸点处必有 w1 或 w2 为 0。这样,得到的解 w1 或 w2 为零的概率就很大了。所以,L1 正则化的解具有稀疏性。
扩展到高维,同样的道理,L2 的限定区域是平滑的,与中心点等距;而 L1 的限定区域是包含凸点的,尖锐的。这些凸点更接近 Ein 的最优解位置,而在这些凸点上,很多 wj 为 0。
关于 L1 更容易得到稀疏解的原因,有一个很棒的解释,请见下面的链接:
https://www.zhihu.com/question/37096933/answer/70507353
正则化参数 λ
正则化是结构风险最小化的一种策略实现,能够有效降低过拟合。
损失函数:训练样本误差 + 正则化项。 其中,参数 λ 起到了权衡的作用。

以 L2 为例,若 λ 很小,对应上文中的 C 值就很大。这时候,圆形区域很大,能够让 w 更接近 Ein 最优解的位置。若 λ 近似为 0,相当于圆形区域覆盖了最优解位置,这时候,正则化失效,容易造成过拟合。相反,若 λ 很大,对应上文中的 C 值就很小。这时候,圆形区域很小,w 离 Ein 最优解的位置较远。w 被限制在一个很小的区域内变化,w 普遍较小且接近 0,起到了正则化的效果。但是,λ 过大容易造成欠拟合。欠拟合和过拟合是两种对立的状态。
在什么情况下使用L1,什么情况下使用L2?
L1和L2的差别,为什么一个让绝对值最小,一个让平方最小,会有那么大的差别呢?我看到的有两种几何上直观的解析:
(1)下降速度:
我们知道,L1和L2都是规则化的方式,我们将权值参数以L1或者L2的方式放到代价函数里面去。然后模型就会尝试去最小化这些权值参数。而这个最小化就像一个下坡的过程,L1和L2的差别就在于这个“坡”不同,如下图:L1就是按绝对值函数的“坡”下降的,而L2是按二次函数的“坡”下降。所以实际上在0附近,L1的下降速度比L2的下降速度要快,所以会非常快得降到0。不过我觉得这里解释的不太中肯,当然了也不知道是不是自己理解的问题。
总结:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
-
线性回归的原理
根据线性代数,我们可以定义线性方程组Xw=y,在线性回归问题中,X是我们的样本数据矩阵,y是我们的期望值向量,也就是说,对于线性回归问题,我们的X和y是已知的,我们要解决的问题是,求取最合适的一个向量w,使得线性方程组能够尽可能的满足样本点的线性分布。之后我们就可以利用求得的w,对新的数据点进行预测。
模型公式:
![]()
从一维到n维:

这里我们使用平方误差来评估实际y值和预测值之间的误差:
 或者
或者
修改为矩阵形式:

我们要使平方误差为最小,根据微积分的内容,我们可以对上面的式子相对w求导:

令上式等于0,然后求得:

等式右边都是我们的已知数据,所以可以求得w的最佳估计。
可以看到,线性回归的原理比较简单,但是,如果注意上面的式子会发现,我们需要求逆矩阵,但是如果矩阵不可逆怎么办?这里有两个思路,一个是采用岭回归的思路,引入参数lambda:

这样,按照线性代数的理论,对于lambda不为0,逆矩阵是一定存在的。
![]() 是半正定,对于任意lambda > 0,
是半正定,对于任意lambda > 0,![]() 一定是正定的,所以一定可逆
一定是正定的,所以一定可逆
详细推导:线性回归之数学原理解析
- 线性回归损失函数、代价函数、目标函数
损失函数:计算的是一个样本的误差
代价函数:是整个训练集上所有样本误差的平均
目标函数:代价函数 + 正则化项
tips:实际应用中,损失函数和代价函数是同一个东西,目标函数是一个与他们相关但更广的概念。
举例说明:

上面三个图的曲线函数依次为f1(x),f2(x),f3(x),我们想用这三个函数分别来拟合真实值Y。
我们给定x,这三个函数都会输出一个f(X),这个输出的f(X)与真实值Y可能是相同的,也可能是不同的,为了表示我们拟合的好坏,我们就用一个函数来度量拟合的程度。这个函数就称为损失函数(loss function),或者叫代价函数(cost function)。

损失函数越小,就代表模型拟合的越好。那是不是我们的目标就只是让loss function越小越好呢?还不是。这个时候还有一个概念叫风险函数(risk function)。风险函数是损失函数的期望,这是由于我们输入输出的(X,Y)遵循一个联合分布,但是这个联合分布是未知的,所以无法计算。但是我们是有历史数据的,就是我们的训练集,f(X)关于训练集的平均损失称作经验风险(empirical risk),所以我们的目标就是最小化经验风险。(风险函数应该就是之前讲的x折交叉验证的损失函数,个人理解...)

我们看上面的图,发现最右面的f3(x)的经验风险函数最小,因为它对历史的数据拟合的最好。但是我们从图上来看它肯定不是最好的,因为它过度学习历史数据,导致它在真正预测时效果会很不好,这种情况称为过拟合(over-fitting)。为什么会造成这种结果?大白话说就是它的函数太复杂了,都有四次方了,这就引出了下面的概念,我们不仅要让经验风险最小化,还要让结构风险最小化。
这个时候就定义了一个函数J(f),这个函数专门用来度量模型的复杂度,在机器学习中也叫正则化(regularization)。常用的有L1, L2范数。到这一步我们就可以说我们最终的优化函数是:
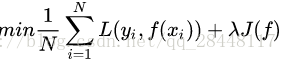
即最优化经验风险+结构风险 = 目标函数 (具体见L1、L2正则部分)
- 优化方法(梯度下降法、牛顿法、拟牛顿法等)
梯度下降可以直接参考:浅谈对梯度下降法的理解
梯度:

1)随机初始值;
2)迭代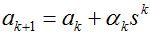
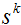
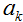
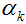
在这里,简单谈一下自己对梯度下降法的理解。
首先,要明确梯度是一个向量,是一个n元函数f关于n个变量的偏导数,比如三元函数f的梯度为(fx,fy,fz),二元函数f的梯度为(fx,fy),一元函数f的梯度为fx。然后要明白梯度的方向是函数f增长最快的方向,梯度的反方向是f降低最快的方向。
我们以一元函数为例,介绍一下梯度下降法。
设f(x) = (x-1)2+1/2,
上图给出了函数f的图像和初始值x0,我们希望求得函数f的最小值,因为沿负梯度方向移动一小步后,f值降低,故只需x0沿着负梯度方向移动一小步即可。
而f在点x0的导数大于0,从而f在点x0的梯度方向为正,即梯度方向为f’(x0),故由梯度下降法可知,下一个迭代值,也就是说x0向左移动一小步到了x1,同理在x1点的导数同样大于零,下一次迭代x1向左移动一小步到达x2,一直进行下去,只要每次移动的步数不是很大,我们就可以得到收敛1的解x。
同样,如果处置选在了最小值的左边,即如图所示:

由于f’(x0)<0,所以梯度方向为负,负梯度方向为正,故需将x0沿负梯度方向移动一小步,即向右移动一小步,这样使得f值更小一些。或用梯度下降法迭代公式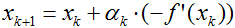
额 不想搬运了,直接去原作者博客吧:浅谈对梯度下降法的理解
- 线性回归的评估指标

- sklearn参数详解
numpy sklearn matpolotlib pandas
写不下去了,就这样吧
参考:
1.监督学习与无监督学习:机器学习笔记 (一) 监督学习、无监督学习
2.泛化:机器学习--泛化能力 谈谈对泛化误差的理解
3.欠拟合和过拟合:机器学习入门-过拟合欠拟合 怎么解决过拟合与欠拟合
4.正则化:【通俗易懂】机器学习中 L1 和 L2 正则化的直观解释
5.线性回归:线性回归算法原理及实现
6.损失函数、代价函数:深入理解机器学习中的:目标函数,损失函数和代价函数
7.评估指标:邹博
8.周志华老师的西瓜书(经典,但是有点难...)














 8377
8377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









