






趁着最近比较闲,静下心来准备把关于集合框架的东西好好整理一下,边学边整理。近阶段先是整理整体的知识点,一些接口,一些继承类以及它们的特性,用法,后续还会有一些常用的,比较重要的类的jdk源码剖析。
Java集合框架详解之继承set接口:http://blog.csdn.net/JasonZhangOO/article/details/55807103
Java集合框架详解之继承list接口:http://blog.csdn.net/JasonZhangOO/article/details/55807177
Java集合框架详解之继承queue接口:http://blog.csdn.net/JasonZhangOO/article/details/55807197
Java集合框架详解之继承map接口:http://blog.csdn.net/JasonZhangOO/article/details/55807685
Java集合框架详解之一点小总结:http://blog.csdn.net/JasonZhangOO/article/details/55808011
map接口:
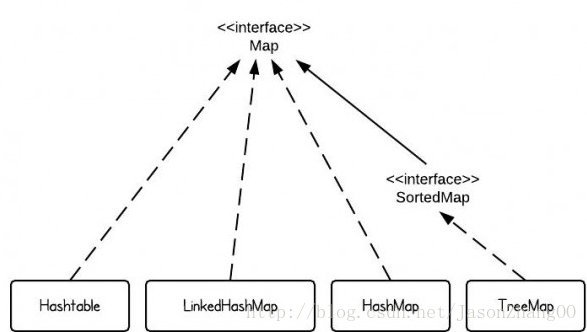
Map 提供 Key 到 Value 的映射,一个 Map 中不能包含相同的 Key,每个 Key 只能映射一个 Value。Map 接口提供 3 种集合的视图,Map 的内容可以被当作一组 Key 集合,一组 Value 集合,或者一组 Key-Value 映射。
Map 提供的主要方法:
boolean equals(Object o) 比较对象;
boolean remove(Object o) 删除一个对象;
put(Object key,Object value) 添加 key 和 value。
Hashtable:
Hashtable继承了map接口,实现了一个基于key-value的Hash表,不能放入null键值对。旧HashMap的同步版本,新代码中也使用了HashMap。Hashtable是同步的,线程安全。
任何作为key的对象都要实现继承自根object的hashcode和equals方法,通过key计算散列函数确定value的位置。两个相同对象的hashcode必定相同,两个hashcode相同未必相同对象,如果不同对象,即两个对象通过散列函数都散列到同一位置,即冲突。避免相同对象出现不同hashcode,需要同时覆写hashcode和equals方法。
Hashtable的使用:
Hashtable hashtable = new Hashtable();
String s1 = "hello";
String s2 = "abc";
String s3 = "edf";
hashtable.put("h", s1); //添加数据key-value
hashtable.put("a", s2);
hashtable.put("e", s3);
System.out.println(hashtable.isEmpty()); //判断是否为空
System.out.println(hashtable.get("a")); //通过key取value
Hashmap:
HashMap是最常用的map实现。和hashtable类似,但是线程不同步。允许null key和null value。
HashMap迭代子操作时间开销和容量正比,因此初始容量设置小一点。
HashMap的使用:
HashMap hashMap= new HashMap();
String s1 = "hello";
String s2 = "abc";
String s3 = "edf";
hashMap.put("h",s1); //添加key-value,如果key存在,则覆盖
hashMap.put("a",s2);
hashMap.put("e",s3);
hashMap.get("h"); //通过key获取value
hashMap.containsKey("a"); //通过key查询是否有该key-value对
hashMap.containsValue("abc");//通过value查询是否有该key-value对
//keyset返回包含key的set集合,然后利用iterator访问key
for(Iterator it = hashMap.keySet().iterator(); it.hasNext();){
String tmp = it.next().toString(); //使用iterator访问元素的key
System.out.println(tmp + "--");
System.out.println(hashMap.get(tmp)); //使用iterator访问元素的value
}
WeakHashMap:
这种Map通常用在数据缓存中。它将键存储在弱引用(WeakReference)中。如果没有强引用指向键对象,这些键就可以被GC垃圾回收线程回收。值被保存在强引用中,所以要确保没有引用从值指向键或者将值也保存在弱引用中
m.put(key, new WeakReference(value))
LinkedHashMap:
HashMap和LinkedList的结合,所有元素的插入顺序存储在LinkedList中。所以迭代LinkedHashMap的条目(entry)、键和值的时候总是遵循插入的顺序。在JDK中,这是元素消耗内存最大的集合。
TreeMap:
一种基于已排序且带导向信息Map的红黑树。每次插入都会按照自然顺序或者给定的比较器排序。这个Map需要实现equals方法和Comparable/Comparator。compareTo需要前后一致。这个类实现了一个NavigableMap接口:可以带有与键数量不同的入口,可以得到键的上一个或者下一个入口,可以得到另一Map某一范围的键(大致和SQL的BETWEEN运算符相同),TreeMap是唯一的带有subMap()方法的Map,它可以返回一个子树。
HashMap和hashtable比较
1)hashtable基于旧的dictionary类,HashMap基于jdk1.2新的map接口。
2)hashtable同步,线程安全;HashMap异步,线程不安全,但是效率高。
3)hashtable不能添加null key和null value;HashMap可以添加null key和null value。
4)不需要线程安全,一般使用HashMap。
HashMap和treemap比较
1)HashMap使用hashcode对元素进行快速查找,元素顺序不固定;treemap元素顺序通过key固定(实现了sortedmap),想要得到有序结果,使用treemap,linkedhashmap是基于元素进入集合的顺序。
2)频繁索引,添加,删除元素使用HashMap,要求添加的键类明确定义了hashCode()和 equals()的实现。
3)二树map一样,但顺序不一样,导致hashCode()不一样。在hashMap中,同样的值的map,顺序不同,equals时false;而在treeMap中,同样的值的map,顺序不同,equals时,true,说明,treeMap在equals()时是整理了顺序了的。
参考文章:
http://www.codeceo.com/article/java-collection-summary.html
http://www.codeceo.com/article/java-collection-class.html
http://www.imooc.com/article/1893
http://blog.csdn.net/softwave/article/details/4166598















 1256
1256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









