











声明
这一篇文章我会从单链表的概念,单链表的原理,一直到通讯录项目单链表的实现,再把单链表的专用题型系统的讲解一下(文章较长)。同时建议学习单链表之前可以学习一下顺序表,作为知识铺垫顺序表(增删减改)+通讯录项目(数据结构)+顺序表专用题型-CSDN博客
https://blog.csdn.net/Jason_from_China/article/details/137484207
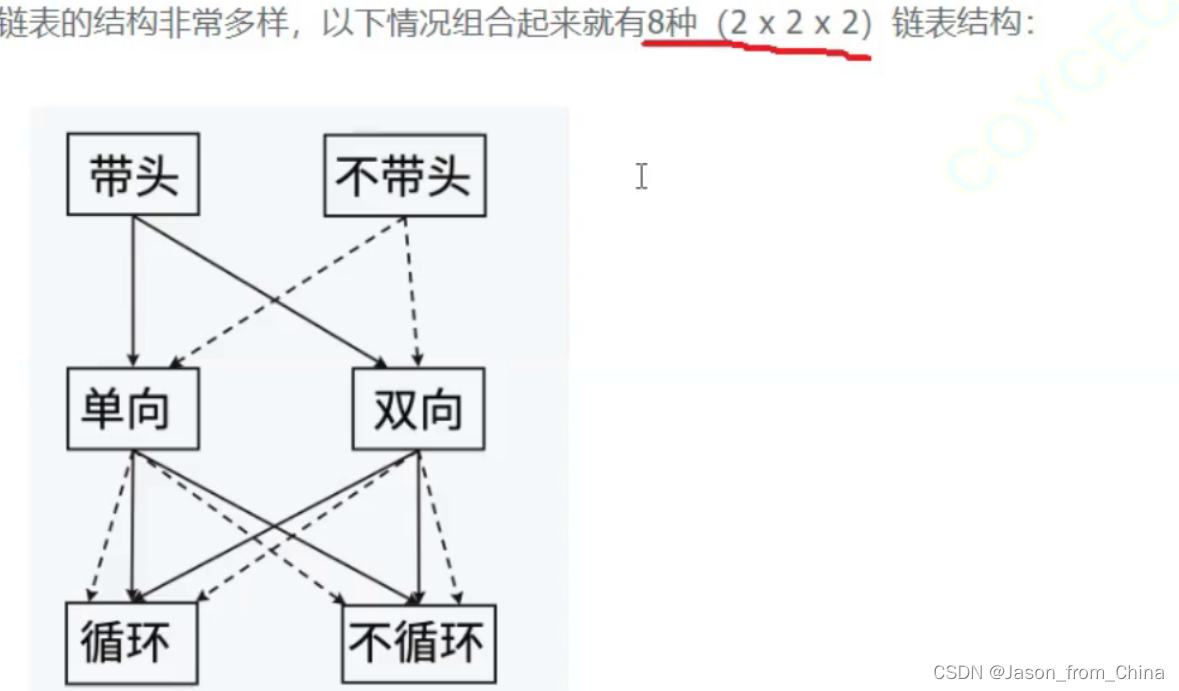
链表的分类
这里我们主要讲解的是不带头的单向不循环链表,在题型解析里面,我们会讲解带头单向循环链表。

什么是单链表
单链表是一种数据结构,
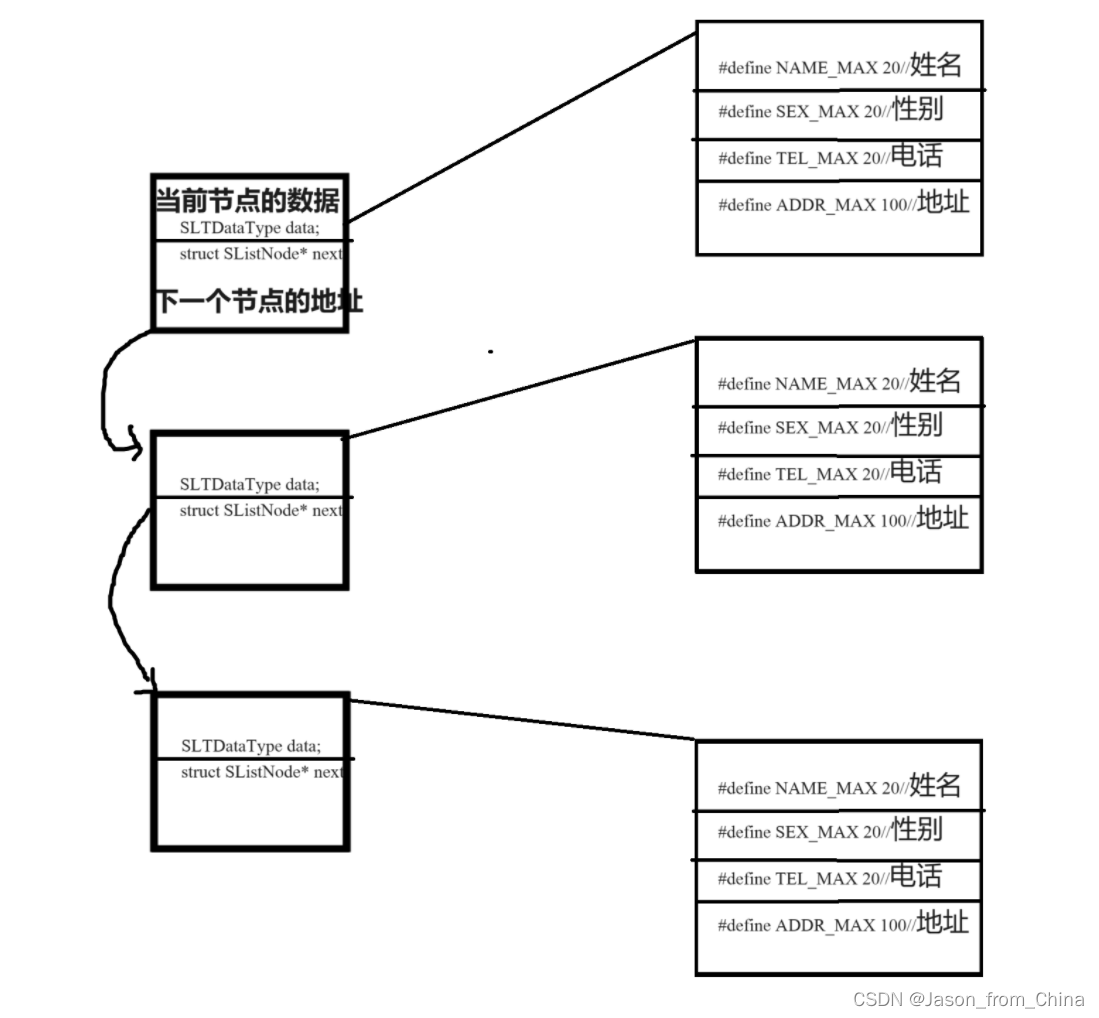
它的数据元素在物理上不连续,但在逻辑上是连续的,通过指针链接实现数据元素的顺序。在单链表中,每个节点包含数据区和指针区,用于存放数据和指向下一个节点的地址。
单链表的实现
主要包括头插法、尾插法、头删、尾删、查找、插入、删除等操作。它广泛应用于企业常用的技术中,如排序、查找、插入、删除等操作。相较于顺序表,链表在内存开辟和元素插入删除方面具有优势,但其访问效率相较较低,需要从头节点开始,依序通过每个节点的指针到达下一个节点1279。
单链表的创建
单链表的创建主要包括定义节点类型,初始化头节点,以及实现插入、删除、查找等基本操作。在插入、删除等操作中,需要改变相邻节点的指针指向。完整的单链表实现需要考虑节点的分配、释放,以及相邻节点指针的改变469。
另外,单链表还可以进行排序运算,常见的排序算法有冒泡排序、插入排序和选择排序等8。需要注意的是,在排序算法中,单链表的插入和删除操作相对复杂,需要分配额外的内存空间来存储临时节点8。
链表的概念
概念:
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表
中的指针链接次序实现的。
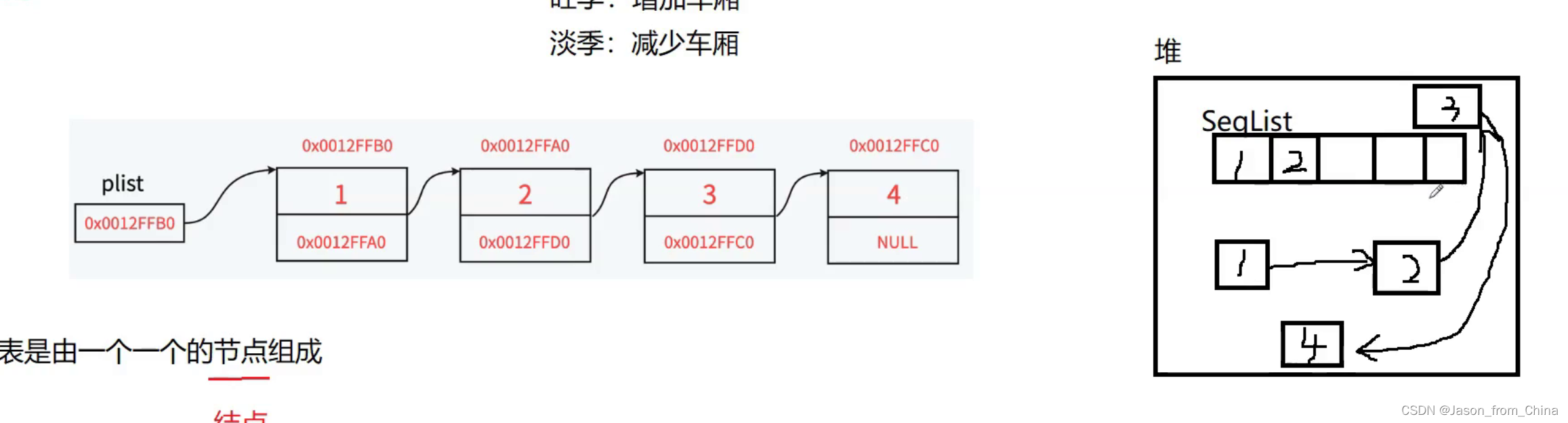
链表的结构跟火⻋⻋厢相似,淡季时⻋次的⻋厢会相应减少,旺季时⻋次的⻋厢会额外增加几节。只需要将火⻋里的某节⻋厢去掉加上,不会影响其他⻋厢,每节⻋厢都是独立存在的。⻋厢是独立存在的,且每节⻋厢都有⻋⻔。想象一下这样的场景,假设每节⻋厢的⻋⻔都是锁上的状态,需要不同的钥匙才能解锁,每次只能携带一把钥匙的情况下如何从⻋头走到⻋尾?
最简单的做法:每节⻋厢里都放一把下一节⻋厢的钥匙
简单的说就是顺序表需要循环,找到数值之后进行增删减改,单链表大多数时候可以不用循环,直接更换节点,就像火车车厢一样。

单链表的结构
在结构上面,
顺序表是线性的。
单链表在,逻辑上是线性的,在物理结构上不一定是线性的。
顺序表的原理
可以看到,不管是物理上还是逻辑上,都是顺序下去的,也就是线性的,逻辑的
顺序表实现通讯录,我们发现很简单

单链表的使用和删除原理
车头也是车厢
每个车厢都是独立存在的
当我需要的时候,增加车厢就可以,因为每个车厢都是独立的
链表是由一个一个节点组成,火车是由一节一节车厢组成
也就是我们需要数据,就申请空间就可以
链表里面,节点和结点是一样的
如何存储的,这里可以发现逻辑上是线性的,但是物理不是
从而
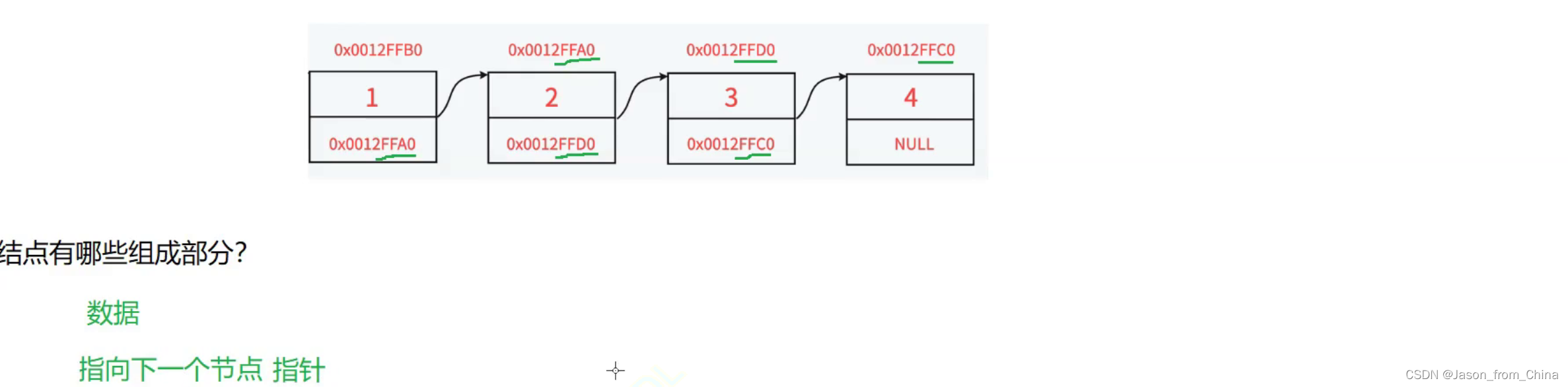
链表是由节点组成,那么节点是由什么组成的?
这里我们可以发现这里我们定义一个指针,存贮一个地址
也就是由数据和指针组成的1
也就是指向下一个节点的地址,从而找到我们需要的数据
从而我们得出结论,我们需要定义链表,也就是我们定义节点的结构
定义链表的节点的结构
Node->表示节点
sinfle->单身
List->链表
所以单链表也就是可以定义为
所以下一个我们就可以定义为,下一个节点的指针
下一个节点的地址就是结构体指针,指向的是下一个节点的指针
next要存储下一个节点的指针






单链表的链接原理
C语言-malloc(申请函数)free(释放函数)-CSDN博客
首先我们可以看到,单链表在空间是用malloc,当然你用realloc也是可以的,
但是到连接的时候,你会发现不一定是按照顺序进行连接的,所以逻辑上我们可以知道这个是线性的,但是物理上不一定是线性的
单链表实现通讯录图解(这里的代码可以不用看懂,我是为了画图进行铺垫)
结构体-前置声明-CSDN博客
#pragma once #define NAME_MAX 20//姓名 #define SEX_MAX 20//性别 #define TEL_MAX 20//电话 #define ADDR_MAX 100//地址 //前置声明 typedef struct SListNode Address_Book; //用户数据 typedef struct PersonInfo { char name[NAME_MAX];//姓名 char sex[SEX_MAX];//性别 int age;//年龄 char tel[TEL_MAX];//电码 char addr[ADDR_MAX];//地址 }PeoInfo; typedef PeoInfo SLTDataType; typedef struct SListNode { SLTDataType data; struct SListNode* next; }SLTNode;也就是我们删除一个节点,这个节点的内容直接全部删除了
单链表的实现(增删减改)
创建文件
和顺序表一样,也是创建三个文件,分别是头文件,实现文件,测试文件
这里我们主要是先学习链表,通讯录自然而然也就会了
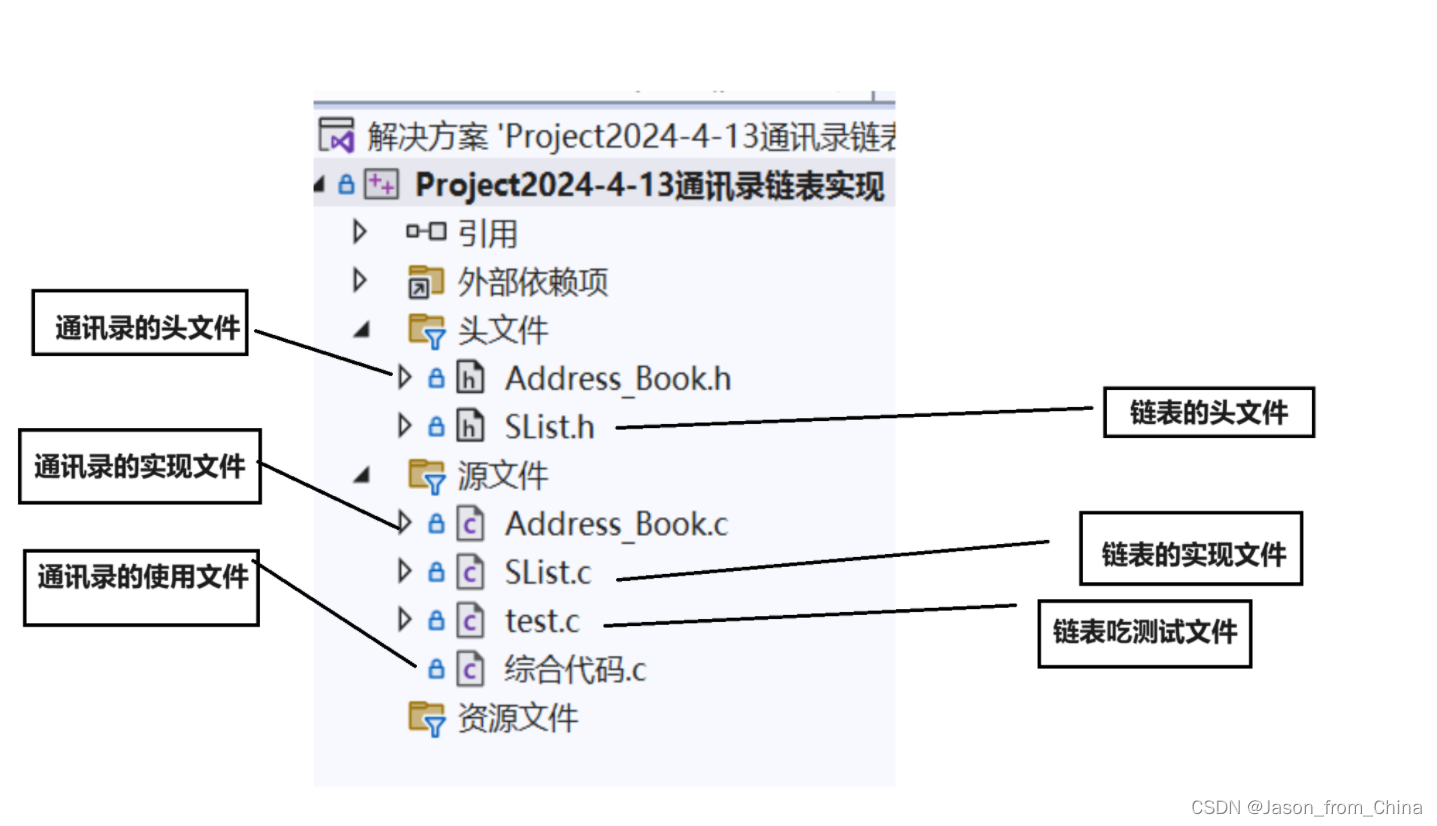
创建链表
链表的实现
//SList.h文件 #pragma once //自定义类型 typedef int SLTDataType; //自定义类型 typedef PeoInfo SLTDataType; typedef struct SListNode { SLTDataType data; struct SListNode* next; }SLTNode;第一个是存储的数据
第二个是指针指向节点的指针
一个数据结构不一定只是存储一个类型
节点的结构已完成
申请空间
链表本质还是需要占用空间的,所以我们创建好链表之后不能直接进行使用,因为没有空间,所以我们需要申请空间
//SList.h文件 //链表的申请空间 SLTNode* SLBuyNode(SLTDataType x);//SList.c文件 #include"SList.h" //链表的申请空间 SLTNode* SLBuyNode(SLTDataType x) { SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode)); if (newnode == NULL) { perror("newnode:error"); exit(1); } newnode->data = x; newnode->next = NULL; return newnode; }链表不会涉及增容所以用malloc,同时只要的开辟空间就有可能失败,所以我们需要进行一个判断是不是创建空间失败。
没有失败的情况下:
newnode->data = x;//当前节点的数值,赋值我需要存储的数值
newnode->next = NULL;//下一个节点就是null,因为我们的一个节点一个节点创建的。测试申请空间
//test.c文件 void sl01() { printf("测试1:\n"); //链表的申请空间 printf("\n申请空间\n"); SLTNode* s1 = SLBuyNode(4); SLTNode* s2 = SLBuyNode(5); SLTNode* s3 = SLBuyNode(6); s1->next = s2; s2->next = s3; s3->next = NULL; //打印链表 SLTPrint(s1); //销毁链表 SListDesTroy(&s1); printf("\n\n\n"); } int main() { s101(); return 0; }当然你也可以这样,但是既然我们定义了,那么我们就可以直接调用
这个时候我们定义一个节点,传过去,防止改变代码
打印出来看看效果


打印单链表
打印是很简单的
头文件
//SList.h文件 #define _CRT_SECURE_NO_WARNINGS 1 #include<stdio.h> #include<assert.h> #include<stdlib.h> #include<string.h> #include"Address_Book.h"//通讯录的前置声明 #pragma once //自定义类型 //typedef int SLTDataType; //自定义类型 typedef PeoInfo SLTDataType; typedef struct SListNode { SLTDataType data; struct SListNode* next; }SLTNode; //链表的初始化 void SLInfo(SLTNode** pphead); //链表的申请空间 SLTNode* SLBuyNode(SLTDataType x); //打印链表 void SLTPrint(SLTNode* pphead);实现文件
//SList.c文件 //打印链表 void SLTPrint(SLTNode* pphead) { assert(pphead); SLTNode* pure = pphead; while (pure) { printf("%d->", pure->data); pure = pure->next; } printf("NULL\n"); }然后我们在test.c里面进行测试申请空间是否成功(发现没有问题)
//test.c文件 void sl01() { printf("测试1:\n"); //链表的申请空间 printf("\n申请空间\n"); SLTNode* s1 = SLBuyNode(4); SLTNode* s2 = SLBuyNode(5); SLTNode* s3 = SLBuyNode(6); s1->next = s2; s2->next = s3; s3->next = NULL; //打印链表 SLTPrint(s1); //销毁链表 SListDesTroy(&s1); printf("\n\n\n"); } int main() { s101(); return 0; }
接下来我的的代码里面不会全部包含头文件,实现文件和测试文件了,大部分只会直接包含头文件,方便观看,在最后的时候会给出代码的总结
链表的初始化
//链表的初始化 void SLInfo(SLTNode** pphead) { // 创建头结点 SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode)); if (newnode == NULL) { perror("malloc failed"); exit(1); } *pphead = newnode; // 初始化头结点的成员 (*pphead)->next = NULL; }初始化的目的:
初始化基本上是每一个代码使用都需要进行初始化,养成良好代码风格
单链表初始化的目的是为了创建一个空的链表数据结构,以便后续可以在这个基础上进行各种操作,如插入、删除、查找等。初始化通常包括以下几个步骤:
1. 分配内存空间:为链表的头部创建一个节点,这个节点将包含指向链表第一个元素的指针。如果链表为空,这个指针将为`NULL`。
2. 设置初始状态:将链表的各个属性和指针初始化为默认状态,比如长度为0,头节点指向`NULL`等。
3. 确保可使用性:初始化之后,链表应该处于一个可以进行操作的状态,这意味着它可以安全地接收新的元素,同时用户可以检查链表是否为空等。
初始化单链表的目的是为了让程序有一个干净的起点,并能够按照预定的方式进行扩展。这样做可以避免在使用链表之前,对链表结构进行不必要的猜测或错误操作,确保数据结构的一致性和稳定性。初始化的代码解释:
简单是说就是初始化的目的往往是创建一个头结点,头结点和第一个节点是不一样的,头结点是null的节点,图解里面1是第一个节点是有实际数值的,但是头结点是没有实际数值的,也就是哨兵位的意思,哨兵位顾名思义也就是放哨的地方,而你进行尾插的时候,第一个数值的插入往往都是从头结点往后进行插入,
下面我们会讲解头结点存在的目的。
链表的销毁
这里先进行链表的销毁代码的实现,因为这个代码的书写比较方便。
//链表的销毁 void SListDesTroy(SLTNode** pphead) { assert(pphead && *pphead); SLTNode* pure = *pphead; while (pure) { //存储节点,不能直接进行销毁,如果直接是pure=pure->next;那么就会导致,找不到下一个节点了 SLTNode* next = pure->next; //销毁当前节点 free(pure); //指向下一个节点,这里不需要指向null因为销毁了你不使用了 pure = next; } //头结点指向空 *pphead = NULL; printf("销毁成功\n"); }链表的销毁和申请节点正好是对应的,创建空间就需要进行销毁,只要是不使用。不然会造成内存泄露,从而使内存被占用。
这里销毁的时候我们需要先存储下一个节点,然后销毁当前节点,然后让节点向下继续,最后全部销毁之后,需要把头结点置为空节点。
链表的尾插
尾插就是需要先找到尾结点,然后将尾结点和新节点进行连接
走到为null的地方
也就是ptail指针指向的下一个节点不为空
当跳出循环的时候
指向的就是尾结点
每次插入节点我们都需要申请空间,所以可以看到我们代码进行尾插的时候需要申请空间
尾插处理空链表和非空链表的时候
空链表,不是空链表就去找尾结点
//链表的尾插 void SLTPushBack(SLTNode** pphead, SLTDataType x) { assert(pphead); SLTNode* newnode = SLBuyNode(x);//申请空间,防止为空 if (*pphead == NULL)//判断我们进行尾插的时候,节点是不是一个没有,进行判断 { *pphead = newnode; } else { SLTNode* pure = *pphead; //这里的循环条件必须是pure->next 因为只是pure的情况下,循环里面就会产生到最后一个指针的情况下,对null解应用 while (pure->next) { pure = pure->next; } pure->next = newnode; } }



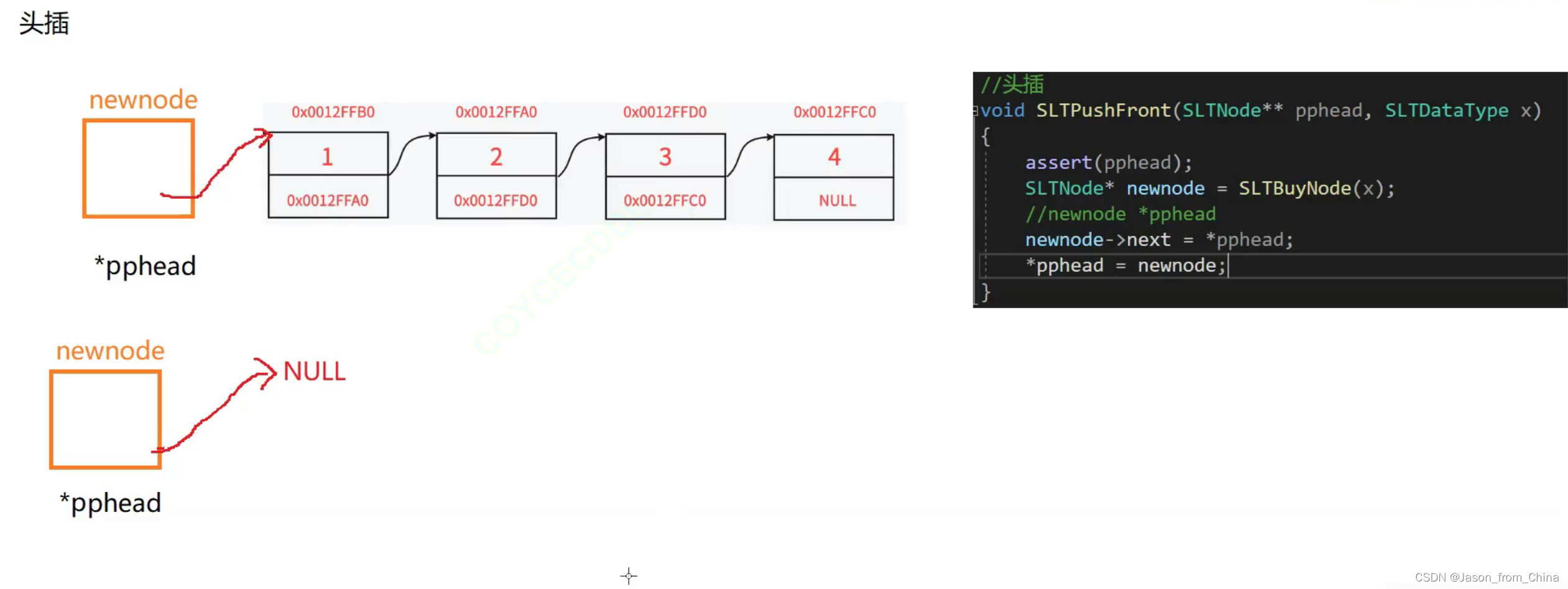
链表的头插
链表的头插,位空和不为空的时候是不一样的
当为空链表的时候
当前的节点就是第一个节点。
链表不为空的情况下
指向的节点我们可以直接让新的节点的下一个节点,等于当前的第一个节点
然后把新节点变成第一个节点,也就是newnode
//链表的头插 void SLTPushFront(SLTNode** pphead, SLTDataType x) { assert(pphead && *pphead); SLTNode* newnode = SLBuyNode(x); if (*pphead == NULL) { *pphead = newnode; } else { newnode->next = *pphead; *pphead = newnode; } }

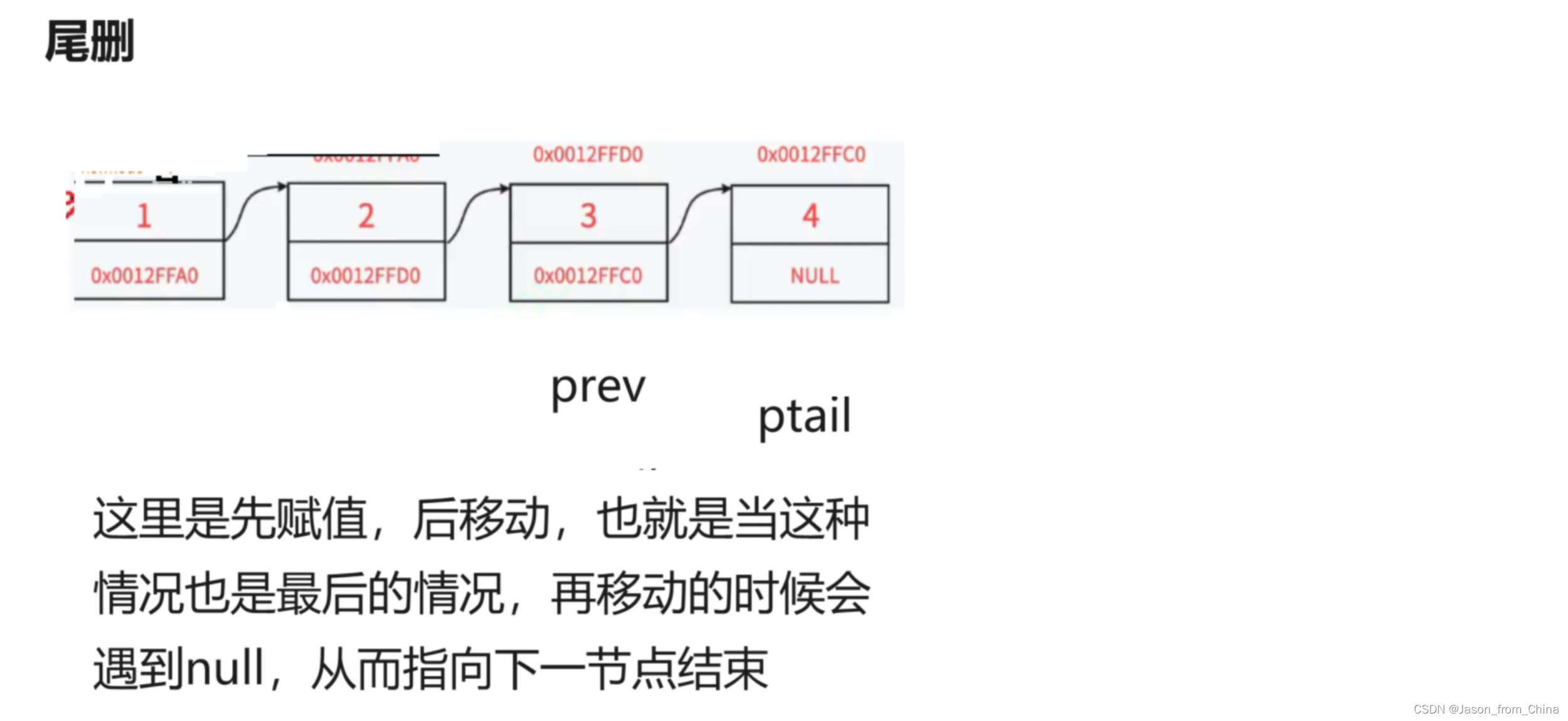
链表的尾删
这里加一个断言不能为null,如果等于null说明空,没的删除
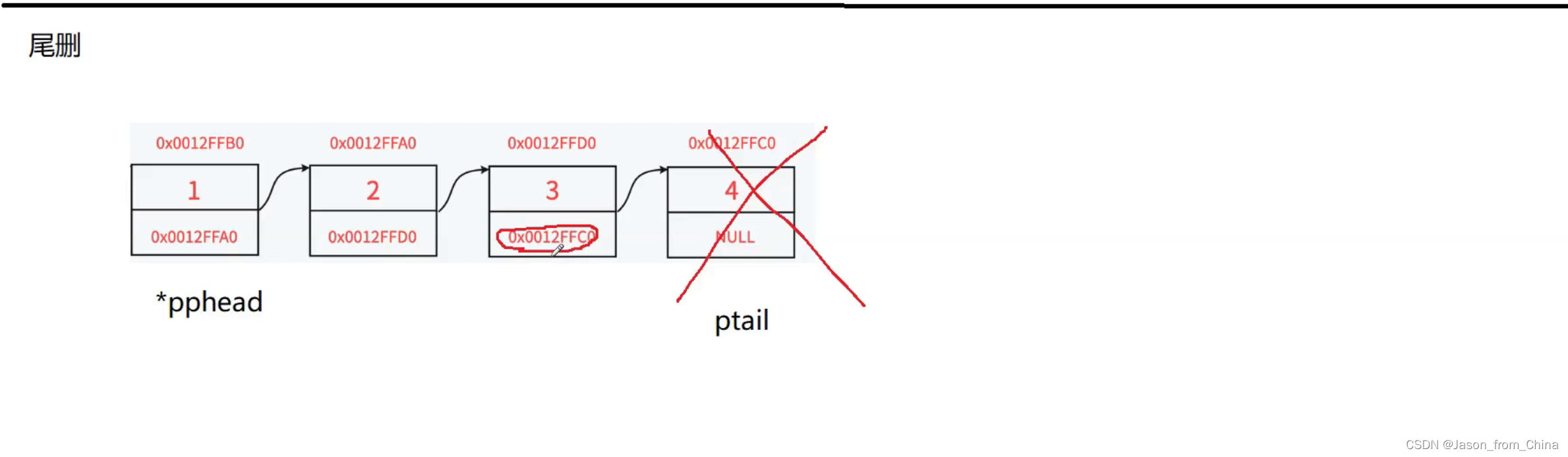
这里我们是不能直接释放的,如果直接释放的情况下我们需要把最后一个节点置为空指针,也就是我们不仅需要找到尾结点,还需要 找到最后一个节点的前一个节点
代码这里我们依旧需要判断是不是只有一个节点,或者是不是为null,所以我们采取断言和判断,要是下一个节点是null那么说明当前的节点就是最后一个节点,所以我们直接释放就可以,不需要进行循环了
如果不是只有一个节点的情况下,此时我们为了不让第一个节点进行移动,所以我们需要创建一个节点,和头结点指向的空间一样,向后移动,当这个节点下一个节点为null的时候,也就是说明,此时找到最后一个节点。此时可以对节点进行删除。
//链表的尾删 void SLTPopBack(SLTNode** pphead) { assert(pphead && *pphead); //当只有一个节点的时候,我们为了防止释放之后变成野指针,因为释放的当前位置等于null之后,free(nodetile);nodetile = NULL; //你继续进行下一个节点的置为null,pure->next = NULL;会导致越界访问 //所以我们进行一个判断,也就只有一个节点的时候 if ((*pphead)->next == NULL) { free(*pphead); *pphead = NULL; } else { SLTNode* nodetile = *pphead; SLTNode* pure = *pphead; while (nodetile->next) { pure = nodetile; nodetile = nodetile->next; } free(nodetile); nodetile = NULL; pure->next = NULL; } }

链表的头删
链表的头删还是很简单的,只需要知道第一个节点然后就知道第一个结点的下一个节点,我们让第一个节的下一节点也就是第二节点,等于头结点就可以。然后同时销毁第一个节点。
//链表的头删 void SLTPopFront(SLTNode** pphead) { assert(pphead && *pphead); //这里不需要判断是不是只有一个头结点,因为删除时候,下一个节点也只是NULL,我们只是把NULL赋值到新的头结点没有越界访问 SLTNode* newhead = (*pphead)->next; free(*pphead); *pphead = NULL; *pphead = newhead; }
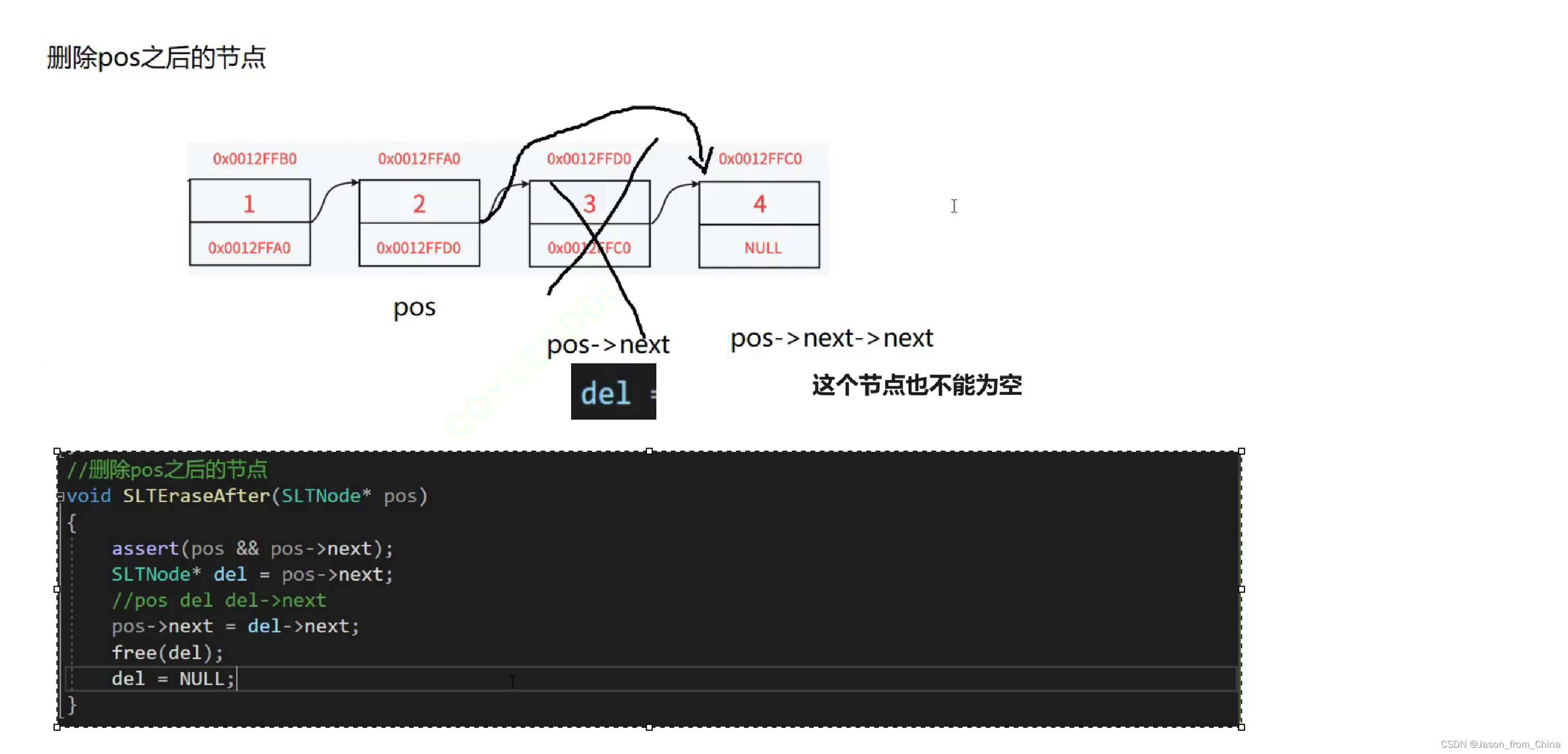
链表的指定位置的删除
在链表中删除一个节点时,我们需要找到pos节点的前一个节点,以便将前一个节点的指针指向pos节点的下一个节点,从而切断与pos节点的链接,使其从链表中脱离。因此,循环的条件应该是purc->next != pos,即继续遍历直到找到最后一个节点(其next指针指向pos节点)。
如果将循环条件改为purc != pos,那么当purc等于pos时循环将继续,这将导致访问非法的内存(因为pos已经是要删除的节点,它的next指针可能已经改变或者将被释放),这会导致程序崩溃。
所以,循环中的purc->next != pos是为了确保我们没有试图访问已经被删除或者即将被删除的节点,而是找到链表中最后一个指向pos的节点。找到这样的节点后,我们将它的next指针改为指向pos的下一个节点,从而实现从链表中删除pos节点。最后,释放pos节点占用的内存,将其设置为NULL以避免产生野指针。
//链表的指定位置的删除 void SLTErase(SLTNode** pphead, SLTNode* pos) { assert(*pphead && pphead); if (*pphead == pos) { SLTNode* newhead = (*pphead)->next; free(*pphead); *pphead = newhead; } else { //需要删除的节点 SLTNode* del = *pphead; while (del->next != pos) { del = del->next; } del->next = pos->next; free(pos); pos = NULL; } }

链表的查找
链表的查找,这里的目的不仅仅是进行链表的查找,还有就是我们进行查找的时候,我们需要先找得到才能进行删除。所以我们才需要进行查找
这里查找到之后返回的是节点的地址,之后我们进行数值的操作的时候,可以直接查找到之后进行删除
//链表的查找 SLTNode* SLTFind(SLTNode* pphead, SLTDataType x) { assert(pphead); SLTNode* pure = pphead; while (pure) { if (pure->data == x) { return pure;//这里不能返回pure->data,只能返回pure因为,这里是返回一个节点,不是一个整数 } //其实这里最后一步是产生越界访问的,但是其实你不使用的,也没事情 pure = pure->next; } return -1; }
删除指定位置之后的数据(版本1)
//删除指定位置之后的数据 void SLTEraseAfterPlus(SLTNode* pos) { assert(pos); SLTNode* del = pos->next; if (del->next == NULL) { perror("null:"); } pos->next = del->next; free(del); del = NULL; }这里直接删除但是是有要求的 ,我们往往需要先调用查找函数,找到数值所在位置,然后传递参数,所以要是在通讯录里面进行实现的时候,往往需要重复调用,但是只是在单链表里面,效率当然会更快。
//指定位置之后删除 printf("\n指定位置之后删除\n"); SLTNode* ret1 = SLTFind(s1, 66); SLTEraseAfter(&s1, ret1); SLTPrint(s1);这里解释一下ret1不能直接传递66,因为我们传递的是节点类型的参数,不是整数类型的,形参是不接收的。所以必须先进行查找。
删除指定位置之后的数据(版本2)
//删除指定位置之后的节点 void SLTEraseAfter(SLTNode** pphead, SLTNode* pos) { assert(pphead && *pphead); SLTNode* del = *pphead; SLTNode* next = pos->next; while (del != pos) { del = del->next; } if (del->next == NULL) { perror("null:"); } pos->next = next->next; free(next); next = NULL; }这里的意思是进行循环,找到需要删除之前的节点,也就是如果子啊通讯录里面直接调用是很方便的。所以我特地写一个版本2,进行对比使用。
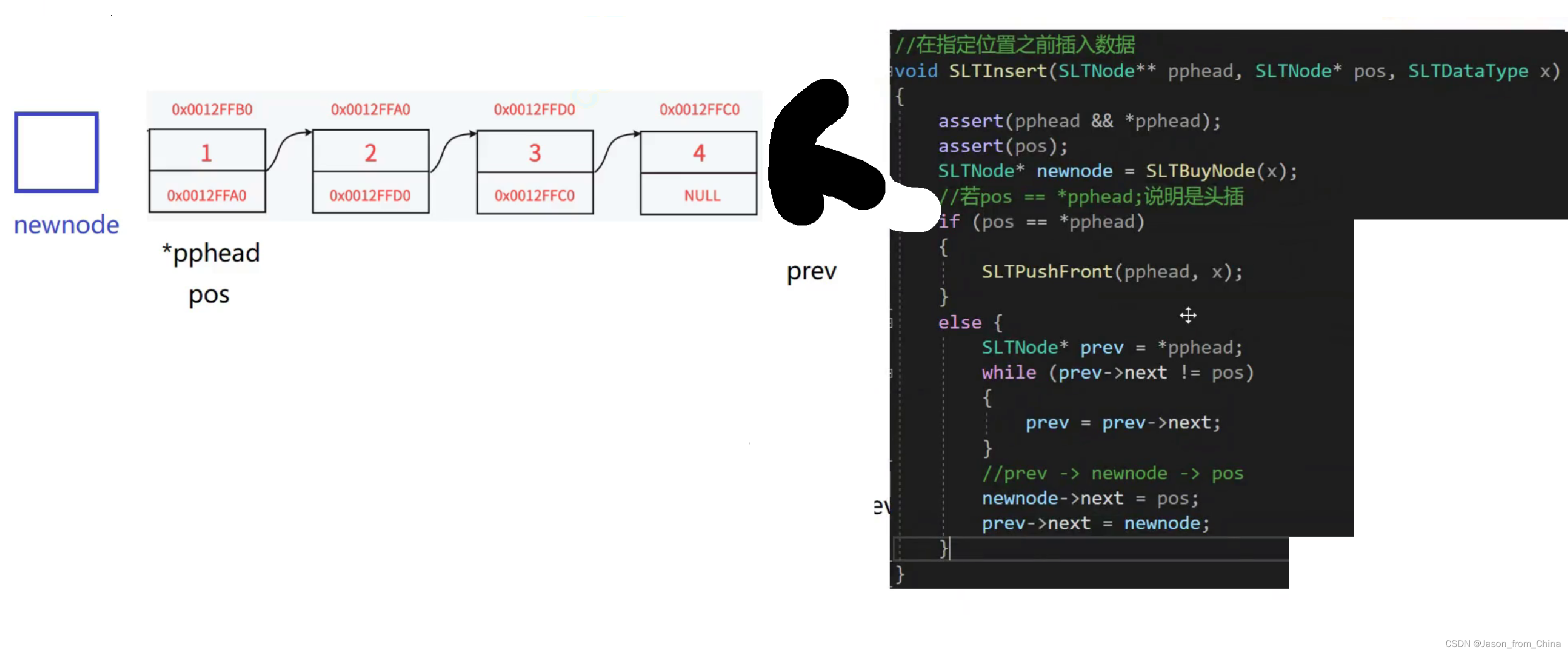
指定位置之前插入
指定位置之前进行插入和之后插入的关键其实都是找到指定位置pos,pos也就是查找的结果,查找到之后传递参数到函数实参里面,实参传递到形参,进行计算。
这里依旧是需要判断是不是null,是的话进行头插
不是的话,创建变量进行移动,创建变量的目的是不改变头结点,因为我们是二级指针,这里了改变头结点,头结点就发生了变化。
然后我们让创建的变量循环寻找pos节点,只要下一个节点指向的不是pos节点就可以,我们,在pos节点前进行插入我们需要pos节点和pos上一个节点。
我们找到之后,这里很关键
我们不能直接让pure的下一个节点指向新节点,这样会导致数据的丢失。
1,所以我们需要先改变新节点的指向(newnode),
2,链接到链表里面(newnode->next=pos;),
3,然后再把上一个节点指向新节点(pure->next = newnode;),此时才是对的。
4,但是你要是非得先指向新节点,也可以,你存储pos后面的节点,然后进行改变也是可以的。
//指定位置之前插入 void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x) { assert(pphead && *pphead); SLTNode* newnode = SLBuyNode(x); if (*pphead == pos) { SLTPushFront(pphead, x); } else { SLTNode* pure = *pphead; while (pure->next != pos) { pure = pure->next; } newnode->next = pos; pure->next = newnode; } }


指定位置之后插入
然后我们让创建的变量循环寻找pos节点,或者用查找函数进行查找,但是没必要我们直接书写了。
找到之后,这里很关键
我们不能直接让pos的下一个节点指向新节点,这样会导致数据的丢失,所以我们需要先改变新节点的指向,链接到链表里面,然后再把上一个节点指向新节点,此时才是对的。
但是你要是非得先指向新节点,也可以,你存储pos后面的节点,然后进行改变也是可以的。
//指定位置之后插入 void SLTInsertAfter(SLTNode* pos, SLTDataType x) { assert(pos); SLTNode* newnode = SLBuyNode(x); newnode->next = pos->next; pos->next = newnode; }
单链表补充
头节点存在的目的:
在单链表的使用中,头结点(Header Node)是一个常用的概念,特别是在进行链表操作时。头结点不是数据域中实际存储的数据节点,而是作为链表操作的辅助节点,它包含对第一个实际数据节点的引用。以下是一些在使用单链表时可能需要头结点的情况:
1. **简化插入操作**:头结点可以简化插入操作,特别是在插入节点到链表的头部时。不需要修改已有节点的指针,只需要改变头结点的指针即可。
2. **统一插入和删除操作**:头结点使得对链表的插入和删除操作更加统一。无论是插入还是删除,都可以通过头结点来定位到操作位置的前一个节点,而不需要关心链表的具体内容。
3. **处理空链表**:在处理空链表时,头结点非常有用。例如,当检查链表是否为空时,只需要检查头结点的指针是否为`NULL`,而不需要遍历整个链表。
4. **保护头结点**:头结点可以作为链表的防护措施,当链表为空时,头结点可以防止访问非法的内存地址。
5. **方便遍历链表**:头结点可以作为遍历链表的起点,从头结点开始,可以逐一访问链表中的每个节点。
6. **实现双向链表**:在实现双向链表时,头结点可以同时存储向前和向后的指针,这样可以更方便地实现双向遍历和操作。
总结来说,头结点在单链表的使用中提供了许多便利,它使得链表的操作更加简洁、统一,并且更加安全和高效。因此,在实现和操作单链表时,头结点是一个非常有用的工具。当然很多时候你也是可以不进行初始化的。但是初始化之后对于代码是书写可以更方便。
举例哨兵位的申请和头结点的申请的区别:
在C语言中,哨兵位节点和申请空间的实现代码主要区别在于它们各自的应用场景和目的。
1. 哨兵位节点:
哨兵位节点通常用于解决链表中的循环链表问题。在循环链表中,我们需要一个特殊的节点来标记链表的末尾,这个特殊的节点就是哨兵位节点。哨兵位节点的实现代码通常包括创建一个哨兵位节点,并将其指向链表的头节点。
以下是一个简单的哨兵位节点的实现代码:#include <stdio.h> #include <stdlib.h> typedef struct Node { int data; struct Node* next; } Node; Node* createSentryNode(Node* head) { Node* sentry = (Node*)malloc(sizeof(Node)); sentry->data = -1; // 哨兵位节点的数据域通常设置为一个特殊值,如-1 sentry->next = head; return sentry; } int main() { Node* head = (Node*)malloc(sizeof(Node)); head->data = 1; head->next = (Node*)malloc(sizeof(Node)); head->next->data = 2; head->next->next = (Node*)malloc(sizeof(Node)); head->next->next->data = 3; head->next->next->next = head; // 创建循环链表 Node* sentry = createSentryNode(head); // 接下来可以使用sentry节点进行循环链表的操作,如查找、删除等 return 0; }
2. 申请空间的申请代码:
申请空间的申请代码通常用于动态分配内存空间,例如在程序运行过程中创建动态数据结构。在C语言中,我们通常使用`malloc()`函数来申请内存空间。
以下是一个简单的申请空间的实现代码:
#include <stdio.h> #include <stdlib.h> int main() { int* ptr = (int*)malloc(sizeof(int)); // 申请一个整数大小的内存空间 if (ptr == NULL) { printf("内存申请失败\n"); return 1; } *ptr = 42; // 在申请的内存空间中存储一个整数 printf("存储的整数: %d\n", *ptr); free(ptr); // 释放申请的内存空间 return 0; }

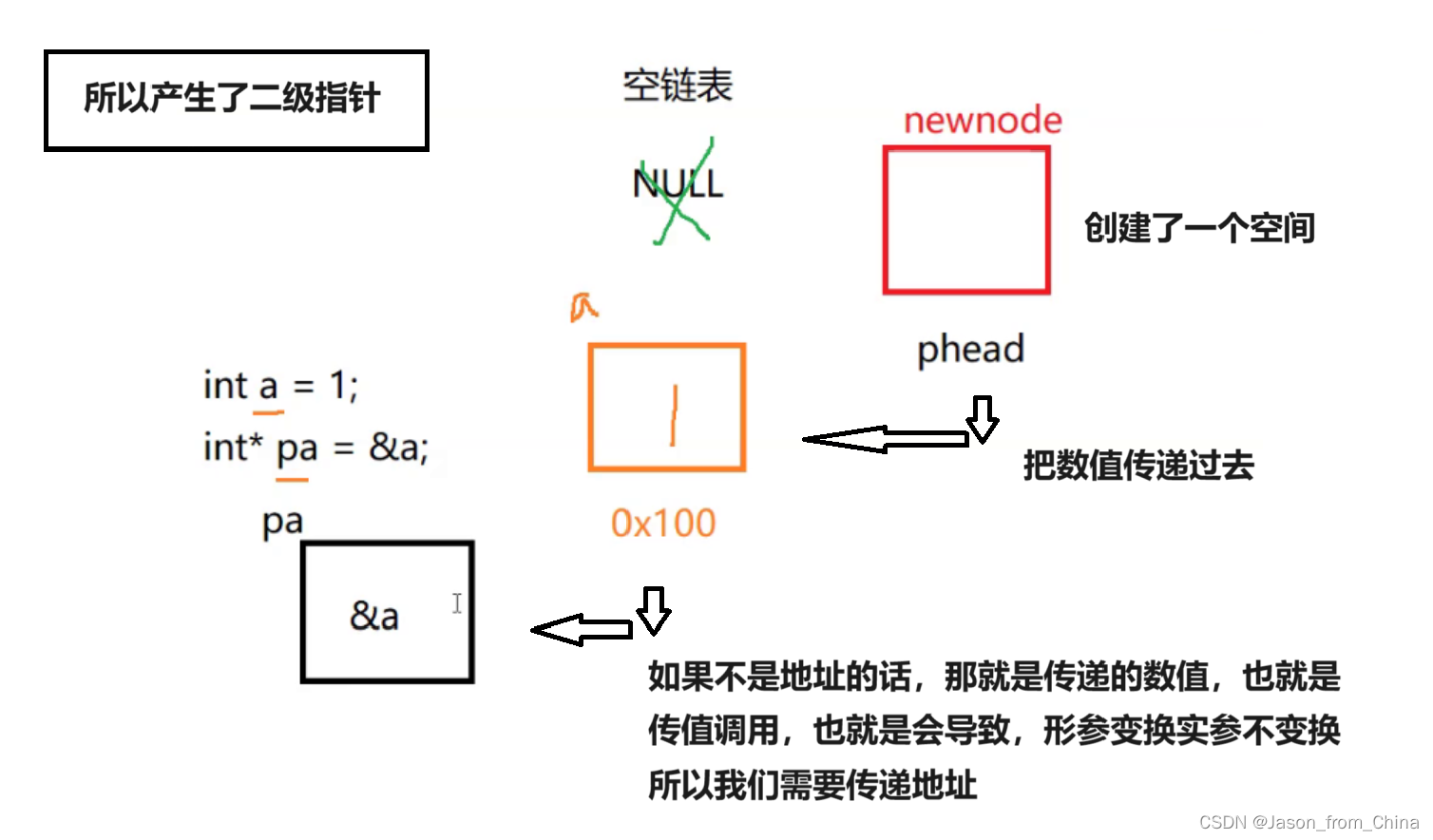
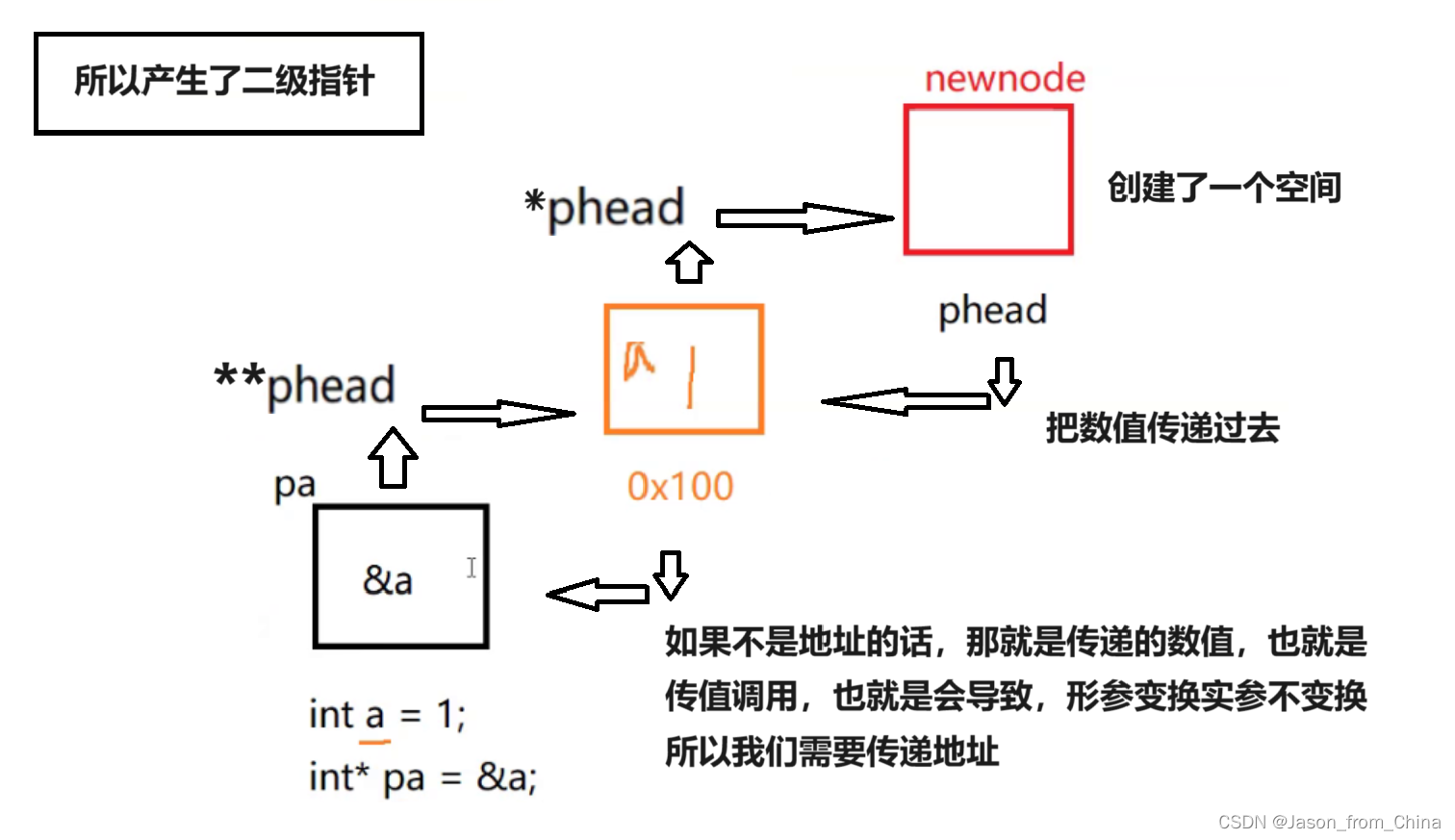
单链表使用里面为什么是二级指针
这里很多人就会疑问,为什么顺序表里面是一级指针,单链表里面是二级指针。
这里我们专门列出来进行讲解。
因为传递的不是二级指针的话,会导致传参之后,形参改变,实参不改变
你希望形参改变实参也改变就必须传递地址
简单的解释就是
1,我们申请开辟了一个空间,此时这个空间需要用指针指向这个空间
2,然后我们需要调用这个空间进行增删减改的时候
3,如果我们直接传递指针过去的话,也就是会传递形参,也就是传值调用,然后我们的编译器会拷贝一份数值,在新开辟的空间计算完毕之后,返回你需要的数值。
4,但是此时只是形参的数值完成了改变,也就是*phead的数值计算完成,因为是形参。
5,我们需要的是newnode的空间的数值完成计算,那么此时我们需要传递指针的地址,也就是传递指针指向空间的地址,也就是指针的地址。
6.此时也就来到了我们图解的**phead,所以需要对指针进行取地址,
7,此时我们对实参进行取地址了,也就是指针的取地址,那么形参我们接收的话是不是需要用二级指针。
8,所以就产生了二级指针
9,最后我们可以发现,申请空间的时候和打印的时候,是不需要二级指针的,为什么,很简单,我们申请的空间,本身是不涉及指针的,只有申请结束,我们需要用指针指向这个节点,形成逻辑的线性表。
10,在打印的时候,我们需要的是不需要改变数值,所以传递形参(也就是一级指针),指向链表的指针。
11,所以这里也解释了为什么有时候需要二级指针,有时候需要一级指针,不需要改变数值的时候我们只需要一级指针,传参就可以了,需要改变数值的时候,我们需要取出指针的地址,我们需要的是形参的改变影响实参。
12,要是不知道什么是形参什么是实参的小伙伴可以看一下函数的知识。
printf("测试2:\n"); SLTNode* s1 = NULL; //尾插 // 首先链表需要指针指向链表 // 我们传递是时候是需要形参变化实参也发生变化的 // 那么如果只是传递一个指针的情况下,这里实际你传递的是指针的数值,也就会导致形参变化实参不变化 // 但是我们需要的是形参变化实参也变化,所以此时我们需要传递指针的地址,也就是&s1,并且用二级指针进行接收 // 取的是指针指向的空间的地址,因为只是传参传递的是s1的情况下, printf("\n尾插\n"); SLTPushBack(&s1, 11); SLTPushBack(&s1, 22); SLTPushBack(&s1, 33); SLTPrint(s1);
单链表代码的总结
SList.h文件
//SList.h文件 #define _CRT_SECURE_NO_WARNINGS 1 #include<stdio.h> #include<assert.h> #include<stdlib.h> #include<string.h> #include"Address_Book.h"//通讯录的前置声明 #pragma once //自定义类型 typedef int SLTDataType; typedef struct SListNode { SLTDataType data; struct SListNode* next; }SLTNode; //链表的初始化 void SLInfo(SLTNode** pphead); //链表的申请空间 SLTNode* SLBuyNode(SLTDataType x); //打印链表 void SLTPrint(SLTNode* pphead); //链表的销毁 void SListDesTroy(SLTNode** pphead); //链表的尾插 void SLTPushBack(SLTNode** pphead, SLTDataType x); //链表的头插 void SLTPushFront(SLTNode** pphead, SLTDataType x); //链表的尾删 void SLTPopBack(SLTNode** pphead); //链表的头删 void SLTPopFront(SLTNode** pphead); //链表的查找 SLTNode* SLTFind(SLTNode* pphead, SLTDataType x); //链表的指定位置的删除 void SLTErase(SLTNode** pphead, SLTNode* pos); //删除指定位置之后的数据1 void SLTEraseAfter(SLTNode** pphead, SLTNode* pos); //删除指定位置之后的数据2 void SLTEraseAfterPlus(SLTNode* pos); //指定位置之前插入 void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x); //指定位置之后插入 void SLTInsertAfter(SLTNode* pos, SLTDataType x);SList.c文件
//SList.c文件 #include"SList.h" //链表的申请空间 SLTNode* SLBuyNode(SLTDataType x) { SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode)); if (newnode == NULL) { perror("newnode:error"); exit(1); } newnode->data = x; newnode->next = NULL; return newnode; } //链表的初始化 void SLInfo(SLTNode** pphead) { // 创建头结点 SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode)); if (newnode == NULL) { perror("malloc failed"); exit(1); } *pphead = newnode; // 初始化头结点的成员 (*pphead)->next = NULL; } //打印链表 void SLTPrint(SLTNode* pphead) { assert(pphead); SLTNode* pure = pphead; while (pure) { printf("%d->", pure->data); pure = pure->next; } printf("NULL\n"); } //链表的销毁 void SListDesTroy(SLTNode** pphead) { assert(pphead && *pphead); SLTNode* pure = *pphead; while (pure) { //存储节点,不能直接进行销毁,如果直接是pure=pure->next;那么就会导致,找不到下一个节点了 SLTNode* next = pure->next; //销毁当前节点 free(pure); //指向下一个节点,这里不需要指向null因为销毁了你不使用了 pure = next; } //头结点指向空 *pphead = NULL; printf("销毁成功\n"); } //链表的尾插 void SLTPushBack(SLTNode** pphead, SLTDataType x) { assert(pphead); SLTNode* newnode = SLBuyNode(x); if (*pphead == NULL) { *pphead = newnode; } else { SLTNode* pure = *pphead; //这里的循环条件必须是pure->next 因为只是pure的情况下,循环里面就会产生到最后一个指针的情况下,对null解应用 while (pure->next) { pure = pure->next; } pure->next = newnode; } } //链表的头插 void SLTPushFront(SLTNode** pphead, SLTDataType x) { assert(pphead && *pphead); SLTNode* newnode = SLBuyNode(x); if (*pphead == NULL) { *pphead = newnode; } else { newnode->next = *pphead; *pphead = newnode; } } //链表的尾删 void SLTPopBack(SLTNode** pphead) { assert(pphead && *pphead); //当只有一个节点的时候,我们为了防止释放之后变成野指针,因为释放的当前位置等于null之后,free(nodetile);nodetile = NULL; //你继续进行下一个节点的置为null,pure->next = NULL;会导致越界访问 //所以我们进行一个判断,也就只有一个节点的时候 if ((*pphead)->next == NULL) { free(*pphead); *pphead = NULL; } else { SLTNode* nodetile = *pphead; SLTNode* pure = *pphead; while (nodetile->next) { pure = nodetile; nodetile = nodetile->next; } free(nodetile); nodetile = NULL; pure->next = NULL; } } //链表的头删 void SLTPopFront(SLTNode** pphead) { assert(pphead && *pphead); //这里不需要判断是不是只有一个头结点,因为删除时候,下一个节点也只是NULL,我们只是把NULL赋值到新的头结点没有越界访问 SLTNode* newhead = (*pphead)->next; free(*pphead); *pphead = NULL; *pphead = newhead; } //链表的查找 SLTNode* SLTFind(SLTNode* pphead, SLTDataType x) { assert(pphead); SLTNode* pure = pphead; while (pure) { if (pure->data == x) { return pure; //这里不能返回pure->data,只能返回pure因为,这里是返回一个节点,不是一个整数 } //其实这里最后一步是产生越界访问的,但是其实你不使用的,也没事情 pure = pure->next; } return -1; } //链表的指定位置的删除 void SLTErase(SLTNode** pphead, SLTNode* pos) { assert(*pphead && pphead); if (*pphead == pos) { SLTNode* newhead = (*pphead)->next; free(*pphead); *pphead = newhead; } else { //需要删除的节点 SLTNode* del = *pphead; while (del->next != pos) { del = del->next; } del->next = pos->next; free(pos); pos = NULL; } } //删除指定位置之后的节点 void SLTEraseAfter(SLTNode** pphead, SLTNode* pos) { assert(pphead && *pphead); SLTNode* del = *pphead; SLTNode* next = pos->next; while (del != pos) { del = del->next; } if (del->next == NULL) { perror("null:"); } pos->next = next->next; free(next); next = NULL; } //删除指定位置之后的数据 void SLTEraseAfterPlus(SLTNode* pos) { assert(pos); SLTNode* del = pos->next; if (del->next == NULL) { perror("null:"); } pos->next = del->next; free(del); del = NULL; } //指定位置之前插入 void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x) { assert(pphead && *pphead); SLTNode* newnode = SLBuyNode(x); if (*pphead == pos) { SLTPushFront(pphead, x); } else { SLTNode* pure = *pphead; while (pure->next != pos) { pure = pure->next; } newnode->next = pos; pure->next = newnode; } } //指定位置之后插入 void SLTInsertAfter(SLTNode* pos, SLTDataType x) { assert(pos); SLTNode* newnode = SLBuyNode(x); newnode->next = pos->next; pos->next = newnode; }test.c文件
test.c文件 #include"SList.h" void sl01() { printf("测试1:\n"); //链表的申请空间 printf("\n申请空间\n"); SLTNode* s1 = SLBuyNode(4); SLTNode* s2 = SLBuyNode(5); SLTNode* s3 = SLBuyNode(6); s1->next = s2; s2->next = s3; s3->next = NULL; //打印链表 SLTPrint(s1); //销毁链表 SListDesTroy(&s1); printf("\n\n\n"); } void s102() { printf("测试2:\n"); SLTNode* s1 = NULL; //尾插 // 首先链表需要指针指向链表 // 我们传递是时候是需要形参变化实参也发生变化的 // 那么如果只是传递一个指针的情况下,这里实际你传递的是指针的数值,也就会导致形参变化实参不变化 // 但是我们需要的是形参变化实参也变化,所以此时我们需要传递指针的地址,也就是&s1,并且用二级指针进行接收 // 取的是指针指向的空间的地址,因为只是传参传递的是s1的情况下, printf("\n尾插\n"); SLTPushBack(&s1, 11); SLTPushBack(&s1, 22); SLTPushBack(&s1, 33); SLTPushBack(&s1, 44); SLTPushBack(&s1, 55); SLTPushBack(&s1, 66); SLTPushBack(&s1, 77); SLTPushBack(&s1, 88); SLTPrint(s1); //头插 printf("\n头插\n"); SLTPushFront(&s1, 0); SLTPrint(s1); //删除链表(尾删) printf("\n删除链表(尾删)\n"); SLTPopBack(&s1); SLTPrint(s1); //头删 printf("\n删除链表(头删)\n"); SLTPopFront(&s1); SLTPrint(s1); //链表的查找 printf("\n查找\n"); SLTNode* find = SLTFind(s1, 11); if (find == -1) { printf("没找到\n"); } else { printf("找到了:%d\n", s1->data);//这里不能是find,因为find返回的是一个地址,如果返回的是整数,那么下面进行计算的时候,就依旧变成了传值调用了 } //指定位置的删除 printf("\n指定位置的删除\n"); SLTNode* ret = SLTFind(s1, 11); SLTErase(&s1, ret);//这里之所以传递的是取地址s1,和ret因为传递的是地址,是相同类型的SLTNode* pos,如果传递是数值,也就是如果返回的是数值,那么会导致依旧变成传值调用 SLTPrint(s1); //指定位置之后删除 printf("\n指定位置之后删除\n"); SLTNode* ret1 = SLTFind(s1, 66); SLTEraseAfter(&s1, ret1); SLTPrint(s1); SLTNode* ret2 = SLTFind(s1, 55); SLTEraseAfterPlus(ret2); SLTPrint(s1); //指定位置之前插入 printf("\n指定位置之前插入\n"); SLTInsert(&s1, NULL, 99); SLTPrint(s1); SLTInsert(&s1, ret2, 99); SLTPrint(s1); SLTNode* ret3 = SLTFind(s1, 22); SLTInsert(&s1, ret3, 99); SLTPrint(s1); //指定位置之后插入 printf("\n指定位置之后插入\n"); SLTNode* ret4 = SLTFind(s1, 22); SLTInsertAfter(ret4, 100); SLTPrint(s1); //销毁 printf("\n销毁\n"); SListDesTroy(&s1); printf("\n\n\n"); } int main() { sl01(); s102(); return 0; }
到这里我们单链表的知识点算是结束了,下面我们进行实践
通讯录
声明
这里首先进行声明,这里的通讯录的实现是基于单链表进行实现的

自定义数据
自定义数据之后我们可以把之前定义的int类型进行替换
//前置声明 typedef struct SListNode Address_Book; //用户数据 typedef struct PersonInfo { char name[NAME_MAX];//姓名 char sex[SEX_MAX];//性别 int age;//年龄 char tel[TEL_MAX];//电码 char addr[ADDR_MAX];//地址 }PeoInfo;结构体-前置声明-CSDN博客

添加通讯录数据
这里我们调用链表的尾插函数,进行添加通讯录项目,当然我们需要输入,最后进行插入就可以
//添加通讯录数据 void AddContact(Address_Book** con) { PeoInfo info; printf("请输入姓名:\n"); scanf("%s", &info.name); printf("请输入性别:\n"); scanf("%s", &info.sex); printf("请输入年龄:\n"); scanf("%d", &info.age); printf("请输入电话:\n"); scanf("%s", &info.tel); printf("请输入地址:\n"); scanf("%s", &info.addr); SLTPushBack(con, info); printf("添加成功\n\n"); }
删除通讯录数据
只要是涉及到删除,我们肯定需要进行查找,需要找到是否有这个名字,才能进行删除。所以我们需要调用查找函数。查找函数的实现下面我们会进行实现。
//删除通讯录数据 void DelContact(Address_Book** con) { assert(con && *con); char name[NAME_MAX];//姓名 printf("请输入你需要删除的姓名:\n"); scanf("%s", name); Address_Book* ret = FindByName(*con, name);//这里需要传递 if (ret == NULL) { printf("没有找到这个人\n\n"); exit(1); } else { //这里没有排除删除头结点,写到一半我们发现其实我们可以直接把指定位置删除的数据拿来 //Address_Book* pure = *con; //while (pure->next != ret) //{ // pure = pure->next; //} //pure->next = ret->next; SLTErase(con, ret); } }
展示通讯录数据
这里打印一个表头,创建一个变量,变量进行移动。
//展示通讯录数据 void ShowContact(Address_Book* con) { printf("%s %s %s %s %s\n", "姓名", "性别", "年龄", "电话", "地址"); Address_Book* pure = con; while (pure) { printf("%s %s %d %s %s\n", pure->data.name, pure->data.sex, pure->data.age, pure->data.tel, pure->data.addr); pure = pure->next; } }
查找通讯录数据
涉及到删除,肯定需要查找,我们查找可以是查找姓名,或者电话,或者性别等等,这里我们采取的是姓名的查找
//查找通讯录数据(查找名字) Address_Book* FindByName(Address_Book* con, char name[]) { assert(con); Address_Book* pure = con; while (pure) { if (0 == strcmp(pure->data.name, name)) { return pure;//返回当前的节点 } pure = pure->next; } return NULL; }
修改通讯录数据
修改通讯录其实就是直接在原来的函数基础上进行覆盖,当然还是进行查找,找到才能修改。找到后会直接返回节点,我们根据节点直接对其进行数值的覆盖。
//修改通讯录数据 void ModifyContact(Address_Book** con) { assert(*con && con); char name[NAME_MAX];//姓名 printf("请输入你需要修改的姓名:\n"); scanf("%s", &name); // 这里需要传递指针,因为接受的是二级指针,我们需要形参的改变影响实参,传递来的是指向链表的指针的地址 // 这个指针指向链表的空间,所以我们要修改通讯录的内容,需要把指向这个链表的指针传递过去 // 指针找到这个名字,返回值不是空,说明找到了,返回的是节点的地址 // 最后我们直接对节点内存空间进行修改,因为我们这里申请空间是节点指向的下一个的内存空间 // 所以我们需要每次进入到节点的内存块里面进行内存的修改 Address_Book* ret = FindByName(*con, name); if (ret == NULL) { printf("没有找到这个人\n\n"); exit(1); } printf("请输入姓名:\n"); scanf("%s", ret->data.name); printf("请输入性别:\n"); scanf("%s", ret->data.sex); printf("请输入年龄:\n"); scanf("%d", &ret->data.age); printf("请输入电话:\n"); scanf("%s", ret->data.tel); printf("请输入地址:\n"); scanf("%s", ret->data.addr); printf("修改成功\n\n"); }
写入到文件里面
C语言-文件操作函数基础fgetc(读字符),fputc(写字符),fgets(读文本),fputs(写文本),fclose(关闭文件),fopen(打开文件)-CSDN博客
//写入到文件里面 void LoadContact(Address_Book** con) { assert(*con && con); FILE* ps = fopen("Address_Book.txt", "w"); if (ps == NULL) { perror("fopen:book:"); exit(1); } Address_Book* newnode = *con; while (newnode!= NULL) { fgets(&con, 1, ps); fprintf(ps, "%s %s %d %s %s\n", newnode->data.name, newnode->data.sex, newnode->data.age, newnode->data.tel, newnode->data.addr); newnode = newnode->next; } fclose(ps); ps=NULL; printf("成功写到文件里面\n"); }
通讯录代码的总结
Address_Book.h文件
//Address_Book.h文件 #pragma once #define NAME_MAX 20//姓名 #define SEX_MAX 20//性别 #define TEL_MAX 20//电话 #define ADDR_MAX 100//地址 //前置声明 typedef struct SListNode Address_Book; //用户数据 typedef struct PersonInfo { char name[NAME_MAX];//姓名 char sex[SEX_MAX];//性别 int age;//年龄 char tel[TEL_MAX];//电码 char addr[ADDR_MAX];//地址 }PeoInfo; //通讯录的初始化 void InitContact(Address_Book** con); //添加通讯录数据 void AddContact(Address_Book** con); //删除通讯录数据 void DelContact(Address_Book** con); //展示通讯录数据 void ShowContact(Address_Book* con); //查找通讯录数据 void FindContact(Address_Book* con); //修改通讯录数据 void ModifyContact(Address_Book** con); //销毁通讯录数据 void DestroyContact(Address_Book** con); //写入到文件里面 void LoadContact(Address_Book** con);
Address_Book.c文件
//Address_Book.c文件 #include"SList.h" #include"Address_Book.h" //添加通讯录数据 void AddContact(Address_Book** con) { PeoInfo info; printf("请输入姓名:\n"); scanf("%s", &info.name); printf("请输入性别:\n"); scanf("%s", &info.sex); printf("请输入年龄:\n"); scanf("%d", &info.age); printf("请输入电话:\n"); scanf("%s", &info.tel); printf("请输入地址:\n"); scanf("%s", &info.addr); SLTPushBack(con, info); printf("添加成功\n\n"); } //展示通讯录数据 void ShowContact(Address_Book* con) { printf("%s %s %s %s %s\n", "姓名", "性别", "年龄", "电话", "地址"); Address_Book* pure = con; while (pure) { printf("%s %s %d %s %s\n", pure->data.name, pure->data.sex, pure->data.age, pure->data.tel, pure->data.addr); pure = pure->next; } } //查找通讯录数据(查找名字) Address_Book* FindByName(Address_Book* con, char name[]) { assert(con); Address_Book* pure = con; while (pure) { if (0 == strcmp(pure->data.name, name)) { return pure;//返回当前的节点 } pure = pure->next; } return NULL; } //删除通讯录数据 void DelContact(Address_Book** con) { assert(con && *con); char name[NAME_MAX];//姓名 printf("请输入你需要删除的姓名:\n"); scanf("%s", name); Address_Book* ret = FindByName(*con, name);//这里需要传递 if (ret == NULL) { printf("没有找到这个人\n\n"); exit(1); } else { //这里没有排除删除头结点,写到一半我们发现其实我们可以直接把指定位置删除的数据拿来 //Address_Book* pure = *con; //while (pure->next != ret) //{ // pure = pure->next; //} //pure->next = ret->next; SLTErase(con, ret); } } //查找通讯录数据(查找名字) void FindContact(Address_Book* con) { assert(con); char name[NAME_MAX];//姓名 printf("请输入你需要查找的姓名:\n"); scanf("%s", name); Address_Book* ret = FindByName(con, name);//这里需要传递 if (ret == NULL) { printf("没有找到这个人\n\n"); exit(1); } else { printf("%s %s %d %s %s\n", con->data.name, con->data.sex, con->data.age, con->data.tel, con->data.addr ); printf("查找成功\n\n"); } } //修改通讯录数据 void ModifyContact(Address_Book** con) { assert(*con && con); char name[NAME_MAX];//姓名 printf("请输入你需要修改的姓名:\n"); scanf("%s", &name); // 这里需要传递指针,因为接受的是二级指针,我们需要形参的改变影响实参,传递来的是指向链表的指针的地址 // 这个指针指向链表的空间,所以我们要修改通讯录的内容,需要把指向这个链表的指针传递过去 // 指针找到这个名字,返回值不是空,说明找到了,返回的是节点的地址 // 最后我们直接对节点内存空间进行修改,因为我们这里申请空间是节点指向的下一个的内存空间 // 所以我们需要每次进入到节点的内存块里面进行内存的修改 Address_Book* ret = FindByName(*con, name); if (ret == NULL) { printf("没有找到这个人\n\n"); exit(1); } printf("请输入姓名:\n"); scanf("%s", ret->data.name); printf("请输入性别:\n"); scanf("%s", ret->data.sex); printf("请输入年龄:\n"); scanf("%d", &ret->data.age); printf("请输入电话:\n"); scanf("%s", ret->data.tel); printf("请输入地址:\n"); scanf("%s", ret->data.addr); printf("修改成功\n\n"); } //写入到文件里面 void LoadContact(Address_Book** con) { assert(*con && con); FILE* ps = fopen("Address_Book.txt", "w"); if (ps == NULL) { perror("fopen:book:"); exit(1); } Address_Book* newnode = *con; while (newnode!= NULL) { fgets(&con, 1, ps); fprintf(ps, "%s %s %d %s %s\n", newnode->data.name, newnode->data.sex, newnode->data.age, newnode->data.tel, newnode->data.addr); newnode = newnode->next; } fclose(ps); ps=NULL; printf("成功写到文件里面\n"); }
test.c文件
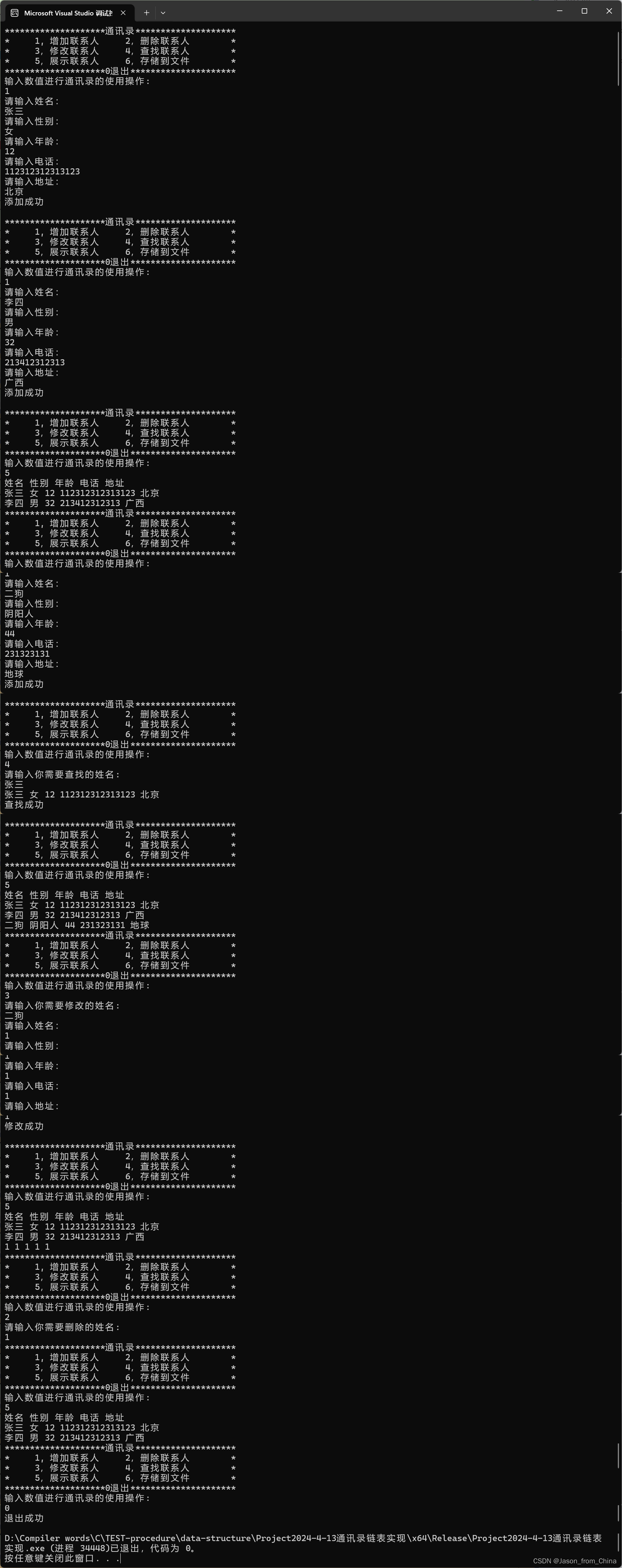
//test.c文件 #include"SList.h" void menu() { printf("********************通讯录********************\n"); printf("* 1, 增加联系人 2,删除联系人 *\n"); printf("* 3,修改联系人 4,查找联系人 *\n"); printf("* 5,展示联系人 6,存储到文件 *\n"); printf("********************0退出*********************\n"); } int main() { int input = 1; PeoInfo* info = NULL; //InitContact(&info); do { menu(); printf("输入数值进行通讯录的使用操作:\n"); scanf("%d", &input); switch (input) { case 1: AddContact(&info); break; case 2: DelContact(&info); break; case 3: ModifyContact(&info); break; case 4: FindContact(info); break; case 5: ShowContact(info); break; case 6: LoadContact(&info); break; case 0: //DestroyContact(&info); printf("退出成功\n"); break; default: printf("请选择正确的数值\n"); break; } } while (input != 0); return 0; }
SList.h文件
//SList.h文件 #define _CRT_SECURE_NO_WARNINGS 1 #include<stdio.h> #include<assert.h> #include<stdlib.h> #include<string.h> #include"Address_Book.h"//通讯录的前置声明 #pragma once //自定义类型 //typedef int SLTDataType; //自定义类型 typedef PeoInfo SLTDataType; typedef struct SListNode { SLTDataType data; struct SListNode* next; }SLTNode; //链表的初始化 void SLInfo(SLTNode** pphead); //链表的申请空间 SLTNode* SLBuyNode(SLTDataType x); 打印链表 //void SLTPrint(SLTNode* pphead); //链表的销毁 void SListDesTroy(SLTNode** pphead); //链表的尾插 void SLTPushBack(SLTNode** pphead, SLTDataType x); //链表的头插 void SLTPushFront(SLTNode** pphead, SLTDataType x); //链表的尾删 void SLTPopBack(SLTNode** pphead); //链表的头删 void SLTPopFront(SLTNode** pphead); //链表的查找 //SLTNode* SLTFind(SLTNode* pphead, SLTDataType x); //链表的指定位置的删除 void SLTErase(SLTNode** pphead, SLTNode* pos); //删除指定位置之后的数据1 void SLTEraseAfter(SLTNode** pphead, SLTNode* pos); //删除指定位置之后的数据2 void SLTEraseAfterPlus(SLTNode* pos); //指定位置之前插入 void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x); //指定位置之后插入 void SLTInsertAfter(SLTNode* pos, SLTDataType x);
SList.c文件
//SList.c文件 #include"SList.h" //链表的申请空间 SLTNode* SLBuyNode(SLTDataType x) { SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode)); if (newnode == NULL) { perror("newnode:error"); exit(1); } newnode->data = x; newnode->next = NULL; return newnode; } //链表的初始化 void SLInfo(SLTNode** pphead) { // 创建头结点 SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode)); if (newnode == NULL) { perror("malloc failed"); exit(1); } *pphead = newnode; // 初始化头结点的成员 (*pphead)->next = NULL; } //链表的销毁 void SListDesTroy(SLTNode** pphead) { assert(pphead && *pphead); SLTNode* pure = *pphead; while (pure) { //存储节点,不能直接进行销毁,如果直接是pure=pure->next;那么就会导致,找不到下一个节点了 SLTNode* next = pure->next; //销毁当前节点 free(pure); //指向下一个节点,这里不需要指向null因为销毁了你不使用了 pure = next; } //头结点指向空 *pphead = NULL; printf("销毁成功\n"); } //链表的尾插 void SLTPushBack(SLTNode** pphead, SLTDataType x) { assert(pphead); SLTNode* newnode = SLBuyNode(x); if (*pphead == NULL) { *pphead = newnode; } else { SLTNode* pure = *pphead; //这里的循环条件必须是pure->next 因为只是pure的情况下,循环里面就会产生到最后一个指针的情况下,对null解应用 while (pure->next) { pure = pure->next; } pure->next = newnode; } } //链表的头插 void SLTPushFront(SLTNode** pphead, SLTDataType x) { assert(pphead && *pphead); SLTNode* newnode = SLBuyNode(x); if (*pphead == NULL) { *pphead = newnode; } else { newnode->next = *pphead; *pphead = newnode; } } //链表的尾删 void SLTPopBack(SLTNode** pphead) { assert(pphead && *pphead); //当只有一个节点的时候,我们为了防止释放之后变成野指针,因为释放的当前位置等于null之后,free(nodetile);nodetile = NULL; //你继续进行下一个节点的置为null,pure->next = NULL;会导致越界访问 //所以我们进行一个判断,也就只有一个节点的时候 if ((*pphead)->next == NULL) { free(*pphead); *pphead = NULL; } else { SLTNode* nodetile = *pphead; SLTNode* pure = *pphead; while (nodetile->next) { pure = nodetile; nodetile = nodetile->next; } free(nodetile); nodetile = NULL; pure->next = NULL; } } //链表的头删 void SLTPopFront(SLTNode** pphead) { assert(pphead && *pphead); //这里不需要判断是不是只有一个头结点,因为删除时候,下一个节点也只是NULL,我们只是把NULL赋值到新的头结点没有越界访问 SLTNode* newhead = (*pphead)->next; free(*pphead); *pphead = NULL; *pphead = newhead; } //链表的指定位置的删除 void SLTErase(SLTNode** pphead, SLTNode* pos) { assert(*pphead && pphead); if (*pphead == pos) { SLTNode* newhead = (*pphead)->next; free(*pphead); *pphead = newhead; } else { //需要删除的节点 SLTNode* del = *pphead; while (del->next != pos) { del = del->next; } del->next = pos->next; free(pos); pos = NULL; } } //删除指定位置之后的节点 void SLTEraseAfter(SLTNode** pphead, SLTNode* pos) { assert(pphead && *pphead); SLTNode* del = *pphead; SLTNode* next = pos->next; while (del != pos) { del = del->next; } if (del->next == NULL) { perror("null:"); } pos->next = next->next; free(next); next = NULL; } //删除指定位置之后的数据 void SLTEraseAfterPlus(SLTNode* pos) { assert(pos); SLTNode* del = pos->next; if (del->next == NULL) { perror("null:"); } pos->next = del->next; free(del); del = NULL; } //指定位置之前插入 void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x) { assert(pphead && *pphead); SLTNode* newnode = SLBuyNode(x); if (*pphead == pos) { SLTPushFront(pphead, x); } else { SLTNode* pure = *pphead; while (pure->next != pos) { pure = pure->next; } newnode->next = pos; pure->next = newnode; } } //指定位置之后插入 void SLTInsertAfter(SLTNode* pos, SLTDataType x) { assert(pos); SLTNode* newnode = SLBuyNode(x); newnode->next = pos->next; pos->next = newnode; }
测试
没有问题
链表的专用题型
链表的经典算法(反转链表)
转链表是计算机算法和数据结构中一个常见的题目。链表是一种常见的基础数据结构,它由一系列结点组成,每个结点包含数据域和指向下一个结点的指针。
要反转一个链表,基本的思路是遍历原链表,在遍历过程中改变每个结点的指针方向,使其指向前一个结点,从而得到一个新的链表,其结点的顺序与原链表相反。
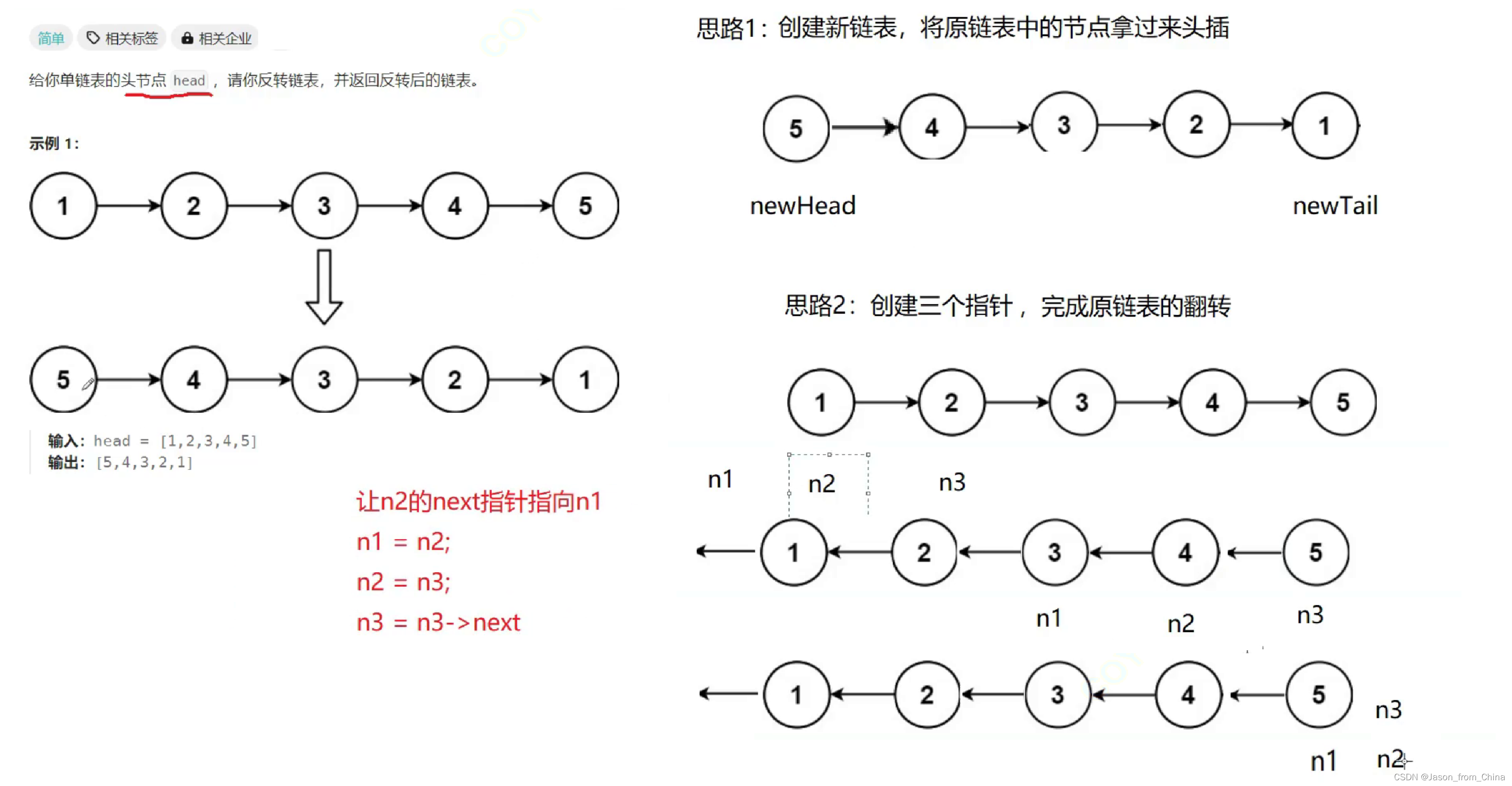
下面是反转单向链表的一般步骤:
- 定义三个指针:
pre(前驱结点)、cur(当前结点)和next(下一个结点)。- 将
pre初始化为NULL,它将用来跟踪反转后的链表的末尾。- 从链表的头结点开始,将
cur指向头结点,next指向cur的下一个结点。- 在每次迭代中:
- 将
cur的下一个结点设置为pre,即改变指针方向。- 将
pre向前移动一步,即pre现在指向cur。- 将
cur向前移动一步,即cur现在指向next。- 如果
cur不是链表的最后一个结点,则设置next为cur的下一个结点。- 当
cur变为NULL时,说明已经遍历完整个链表,此时pre指向的就是新的头结点。
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ typedef struct ListNode ListNode; struct ListNode* reverseList(struct ListNode* head) { if(head == NULL) { return head; } ListNode*n1,*n2,*n3; n1=NULL; n2=head; n3=n2->next; while(n2) { n2->next=n1; n1 = n2; n2 = n3; if(n3) n3=n3->next; } return n1; }

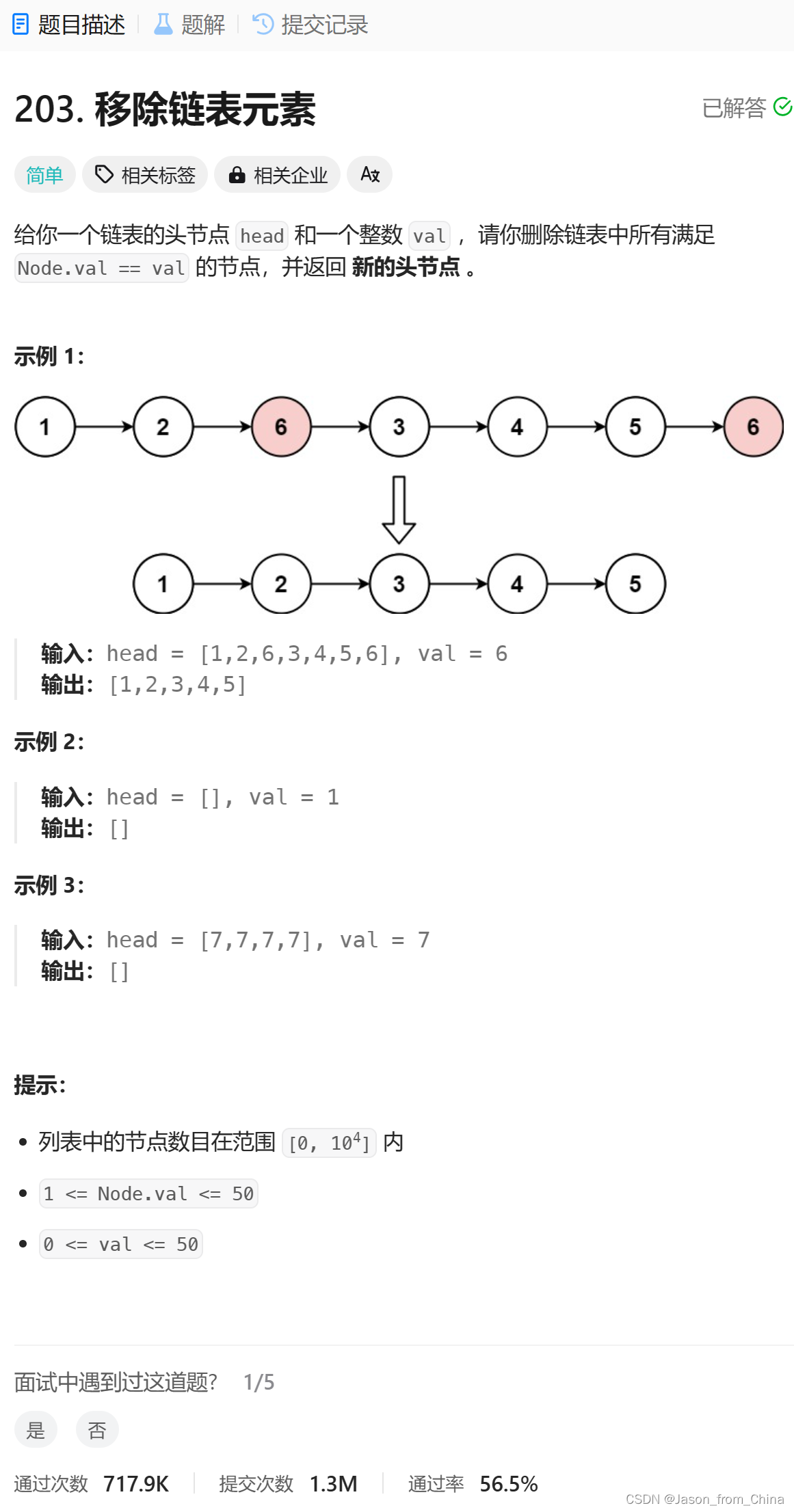
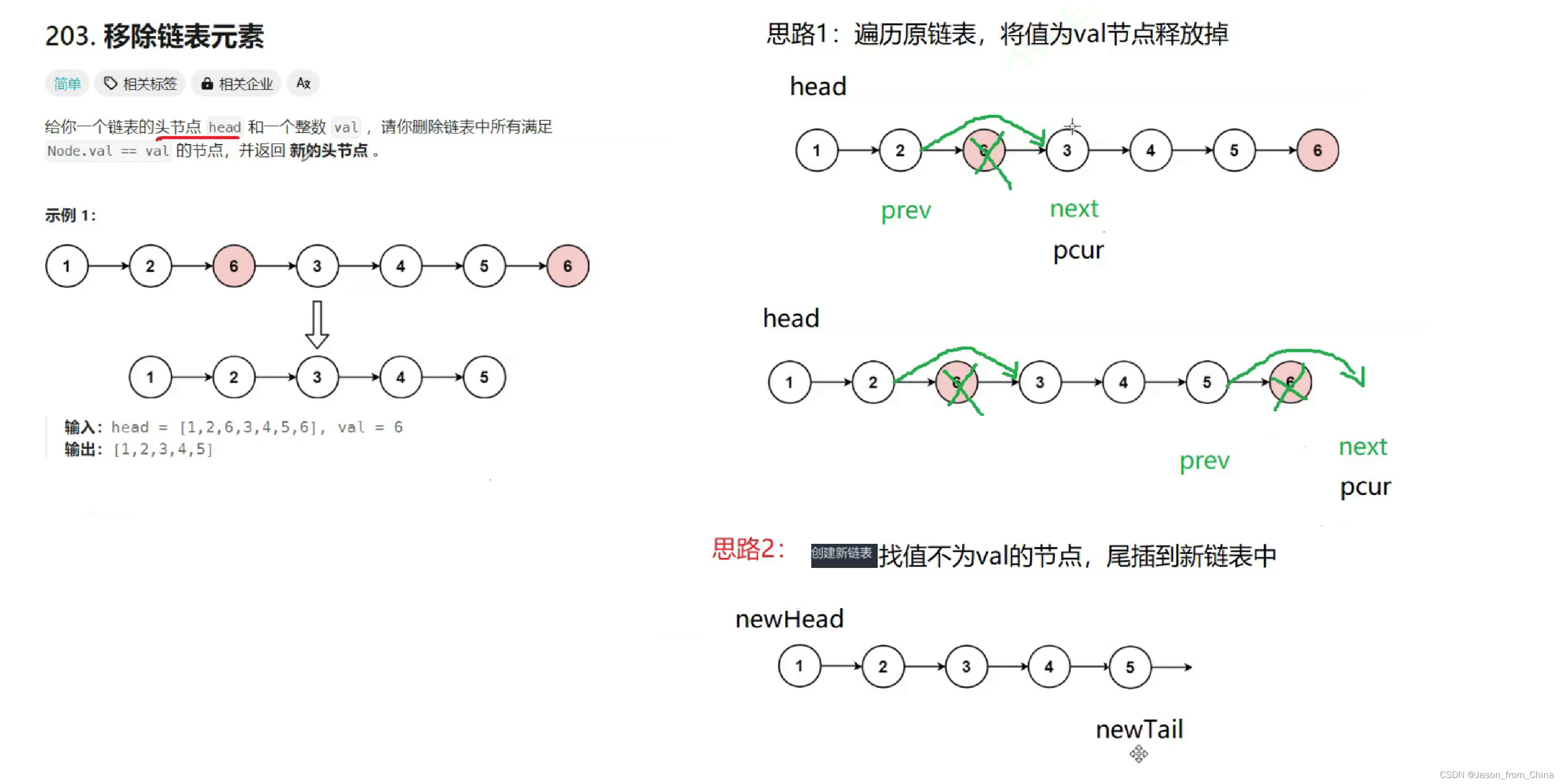
链表的经典算法(移除链表的元素)
在链表中移除元素是常见的操作,以下是一些经典算法和解题思路:
1. **移除特定值的元素**:
- 遍历链表,查找要移除的元素。
- 如果找到,将该元素的值复制到前一个元素的`next`指针指向的结点,然后释放原来的结点空间。
- 如果未找到,链表不变。
2. **移除倒数第k个元素**:
- 使用快慢指针法,设置两个指针,快指针每次移动两步,慢指针每次移动一步。
- 当快指针到达链表尾部时,慢指针所指即为倒数第k个元素。
- 然后进行类似于移除特定值元素的步骤,但在此之后,慢指针需要向前移动k-1步,以便指向新的倒数第k个元素。
3. **移除重复元素**:
- 使用哈希表记录每个值出现的次数。
- 遍历链表,对于每个元素,检查哈希表中的计数器。
- 如果计数器为1,保留该元素;如果计数器大于1,跳过该元素并减少计数器。
- 如果计数器为0,说明这是重复元素,将其从链表中移除。
4. **移除链表的倒数第n个元素**:
- 这个问题和移除倒数第k个元素类似,但是需要考虑n可能大于链表长度的情况。
- 首先计算链表长度,然后计算倒数第n个元素的位置。
- 如果位置为0,说明没有元素可以移除;如果位置大于0,则按照移除倒数第k个元素的步骤进行。
5. **移除循环链表中的元素**:
- 检测链表是否有环,可以使用快慢指针或者Floyd判圈算法。
- 确定环的入口点,即循环链表的起始点。
- 移除特定值或者特定位置的元素,和普通链表的移除操作类似,但需要在环内进行。
在实现这些算法时,需要注意几个关键点:
- **指针操作**:正确地更新指针以保持链表的连续性。
- **边界条件**:处理链表为空或者只有一个元素的特殊情况。
- **内存管理**:在C/C++等需要手动管理内存的语言中,确保删除节点时释放内存。
每种算法都有其适用场景和优缺点,选择合适的算法取决于具体的问题和需求。
这里我们采取思路2
插法是一种在链表中添加新元素的方法,它不直接操作链表的头结点,而是从链表的末尾开始插入新元素。虽然尾插法不是移除链表元素的算法,但我可以为你解释尾插法的工作原理,然后你就可以理解如何在其基础上实现移除元素的算法。
尾插法的工作原理如下:
初始化一个哑结点作为新链表的头部,哑结点不存储有效数据,它的作用是为了简化插入操作。
创建一个指向链表末尾的指针,初始时该指针指向哑结点。
遍历待插入的元素序列,对于每个元素:
- 创建一个新结点,将新结点的数据域设置为当前元素。
- 将新结点插入到链表末尾,即让新结点的
next指针指向当前链表的末尾结点,然后将末尾指针指向新结点。如果你想要使用尾插法来移除链表中的元素,你可以先遍历链表找到要移除的元素,然后将这个元素之前的所有元素保留下来,最后将这个元素从链表中移除。具体步骤如下:
初始化一个哑结点作为新链表的头部。
遍历原链表,对于每个元素,判断它是否是要移除的元素:
- 如果是,将这个元素之前的所有元素保留下来,然后跳过这个元素(即不将其添加到新链表中)。
- 如果不是,将这个元素添加到新链表中。
移除原链表中的最后一个元素(即要移除的元素)。
返回新链表的头结点。
请注意,这个方法只是在原链表上创建了一个新的链表,实际上并没有改变原链表。如果你想要修改原链表,你需要手动更新原链表的指针。
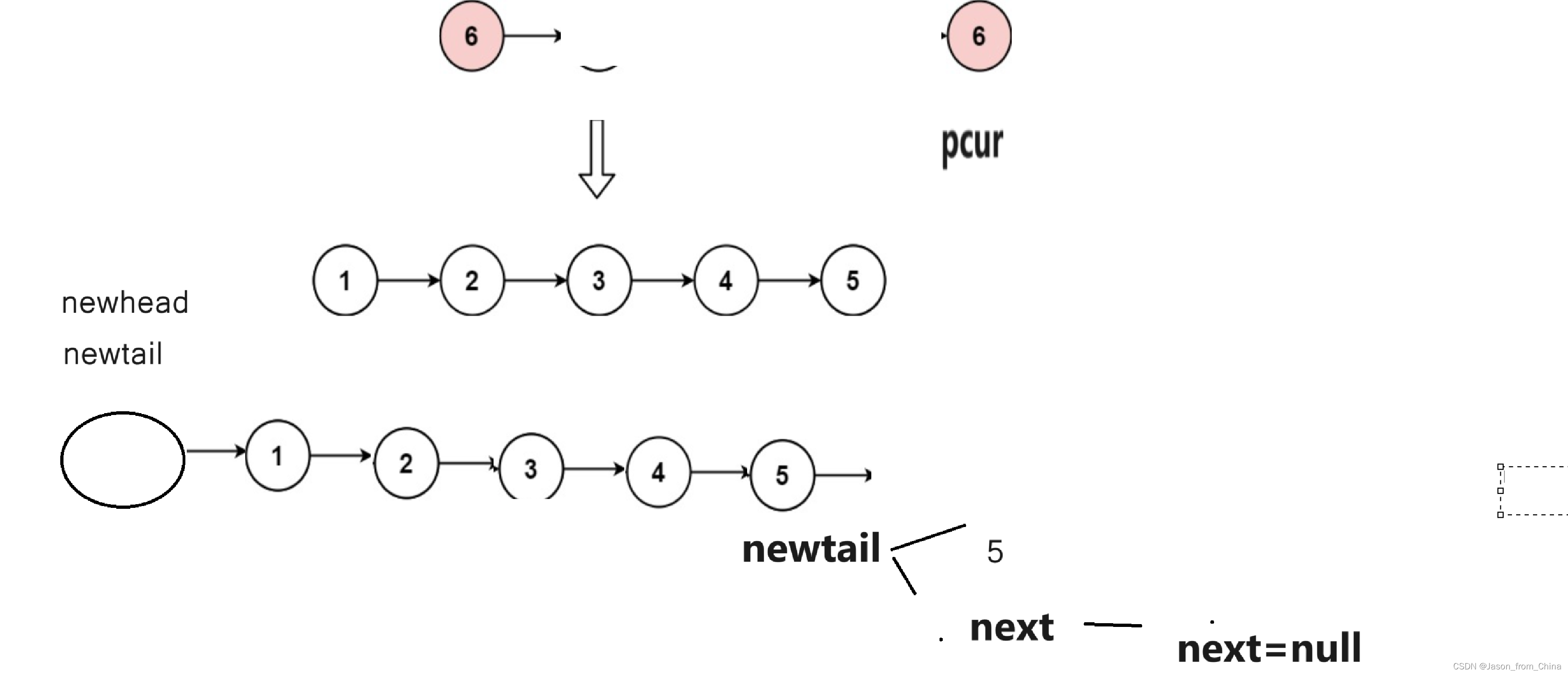
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ typedef struct ListNode ListNode; struct ListNode* removeElements(struct ListNode* head, int val) { // 创建一个空链表 ListNode *newhead, *newtail; newhead = newtail = NULL; // 遍历链表 ListNode* pcur = head; while (pcur) { if (pcur->val != val) { // 节点为空的时候 if (newtail == NULL) { newhead = newtail = pcur; } else { // 不为空的时候 //往尾结点的下一个节点进行插入 newtail->next = pcur; //同时尾结点进行插入 newtail = newtail->next; } } pcur = pcur->next; } //这里存在的目的是,5节点是两部分组成,5和next也就是 6,所以需要吧下一个节点置为NULL if (newtail!=NULL) newtail->next = NULL; return newhead; }

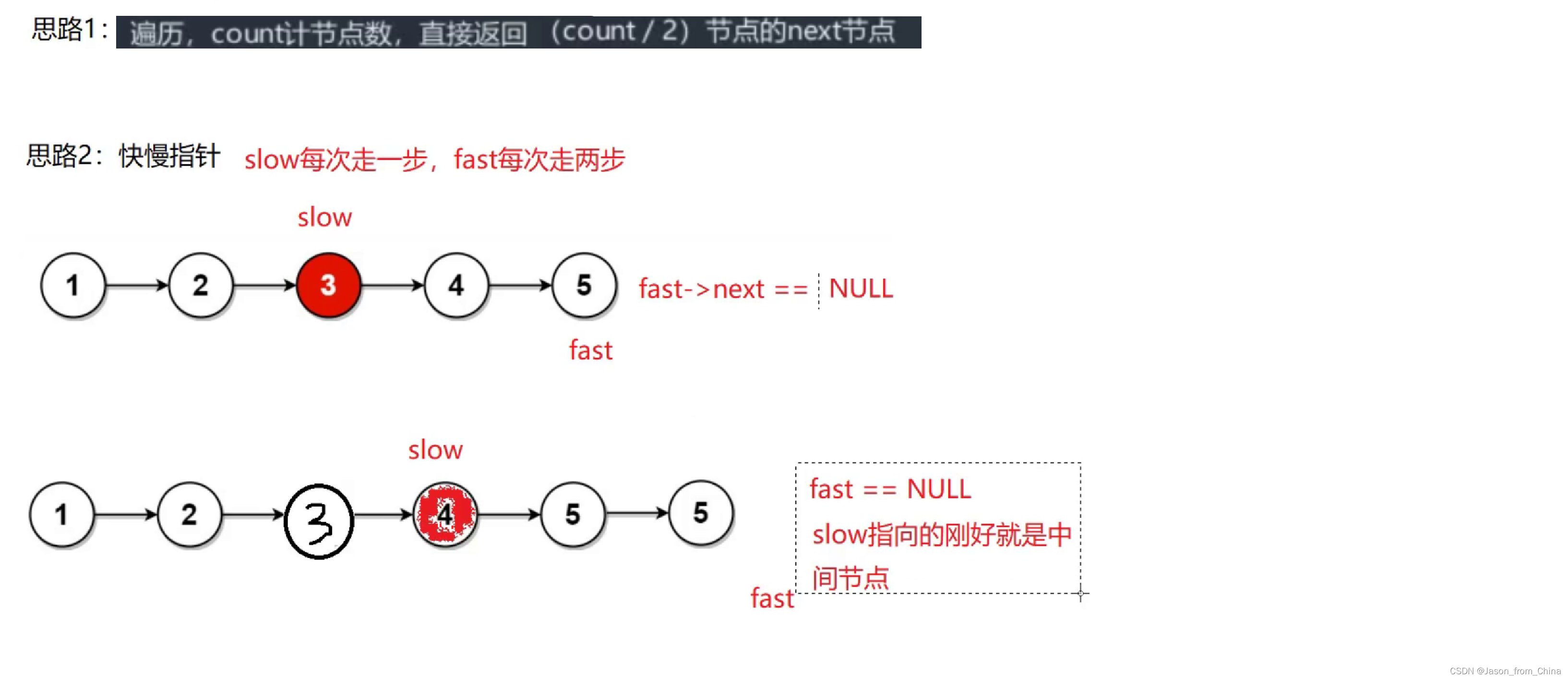
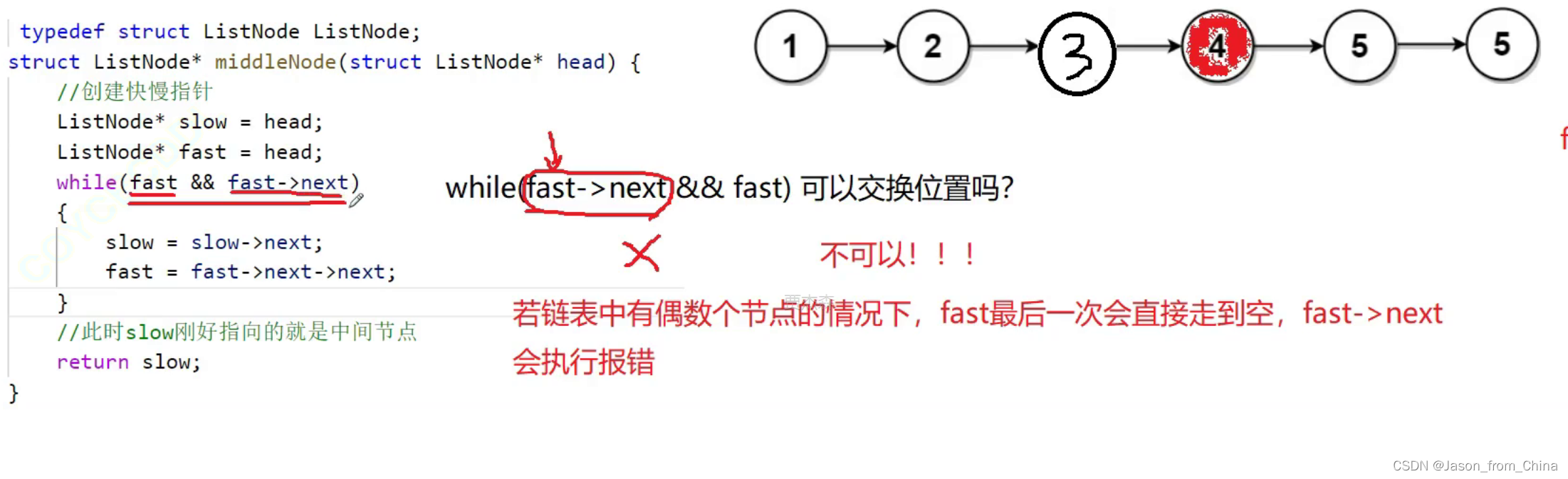
链表的经典算法(链表的中间节点)
链表的中间节点问题可以通过快慢指针的方法来解决。快指针和慢指针同时从链表的头结点开始移动,快指针每次移动两步,慢指针每次移动一步。当快指针到达链表的末尾时,慢指针所指向的结点就是链表的中间结点。如果链表有偶数个结点,则慢指针指向的是中间两个结点中的第二个。
这个方法的时间复杂度是O(n),其中n是链表的结点数。这是因为快指针和慢指针都需要遍历整个链表一次。
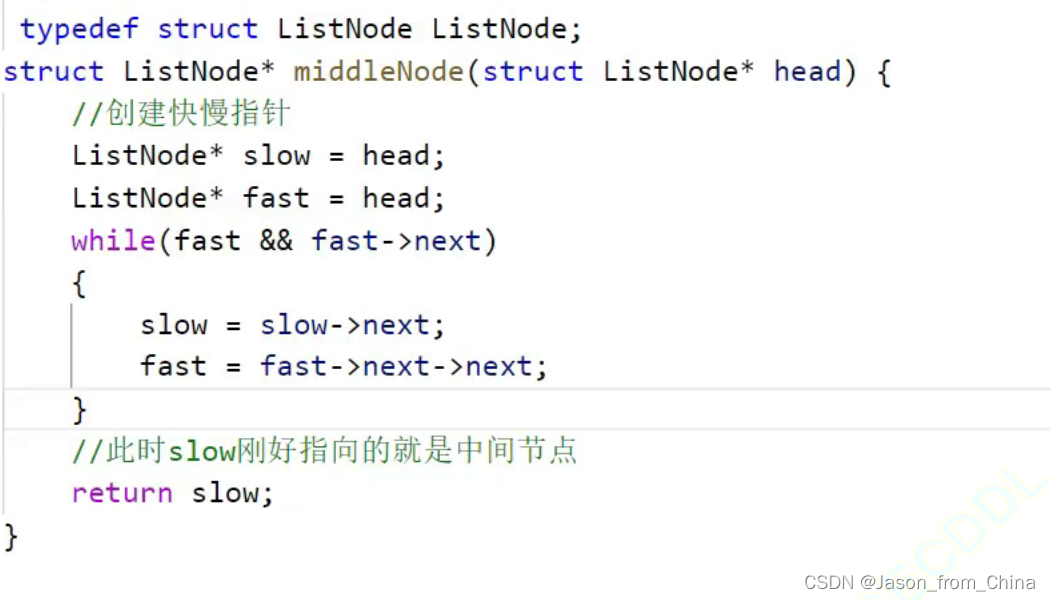
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ typedef struct ListNode ListNode; struct ListNode* middleNode(struct ListNode* head) { ListNode *slow, *fast; slow = fast = head; while (fast && fast->next) { fast = fast->next->next; slow = slow->next; } return slow; }

链表的经典算法(合并两个有序链表)
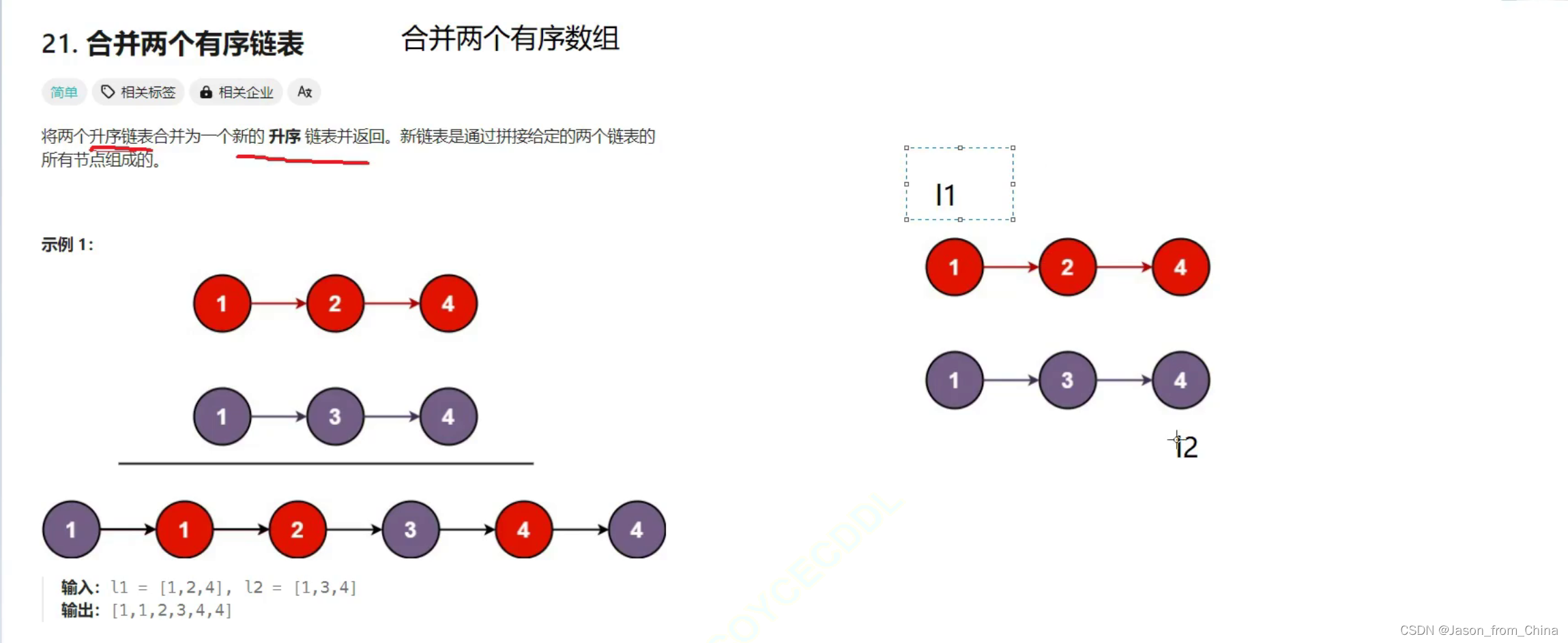
合并两个有序链表是一个常见的链表问题,可以通过尾插法来实现。尾插法是一种在链表末尾添加新元素的方法,它不直接操作链表的头结点,而是从链表的末尾开始插入新元素。以下是如何使用尾插法合并两个有序链表的步骤:
创建一个新链表的哑结点作为新链表的头部。
初始化两个指针,分别指向两个链表的头部。
比较两个指针所指向的元素:
- 如果第一个链表的元素小于或等于第二个链表的元素,将第一个链表的元素添加到新链表的末尾,并将第一个链表的指针向后移动。
- 否则,将第二个链表的元素添加到新链表的末尾,并将第二个链表的指针向后移动。
重复步骤3,直到某个链表为空。
如果第一个链表为空,将第二个链表的剩余部分添加到新链表的末尾;反之亦然。
返回新链表的头结点。
创建新的链表
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ typedef struct ListNode ListNode; struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) { //判断空 if(list1==NULL) { return list2; } if(list2==NULL) { return list1; } ListNode* l1 = list1; ListNode* l2 = list2; ListNode *newhead, *newtile; newhead = newtile = NULL; while (l1 && l2) { if (l1->val < l2->val) { //l2的数值大,那么我们需要插入l1,但是当只有哨兵位的时候,我们需要把头节点(newhead)和运动的节点(newtile),指向最后需要返回的头节点,并且让newtile进行向后移动,所以插入第一个节点和后面的节点是不一样的,如果没有这一步就会导致,头结点指向的还是null,后面的节点是没有的 if (newhead == NULL) { newhead = newtile = l1; } else { newtile->next = l1; newtile = newtile->next; } //这里的目的是无论是哪一种情况,只要没有遇见最后一步,你都是需要继续向后移动的 l1 = l1->next; } else { if (newhead == NULL) { newhead = newtile = l2; } else { newtile->next = l2; newtile = newtile->next; } l2 = l2->next; } } //判断是不是有一个链表提前结束 //l1提前结束了 if(l2) { newtile->next=l2; } //l2提前结束了 if(l1) { newtile->next=l1; } return newhead; }


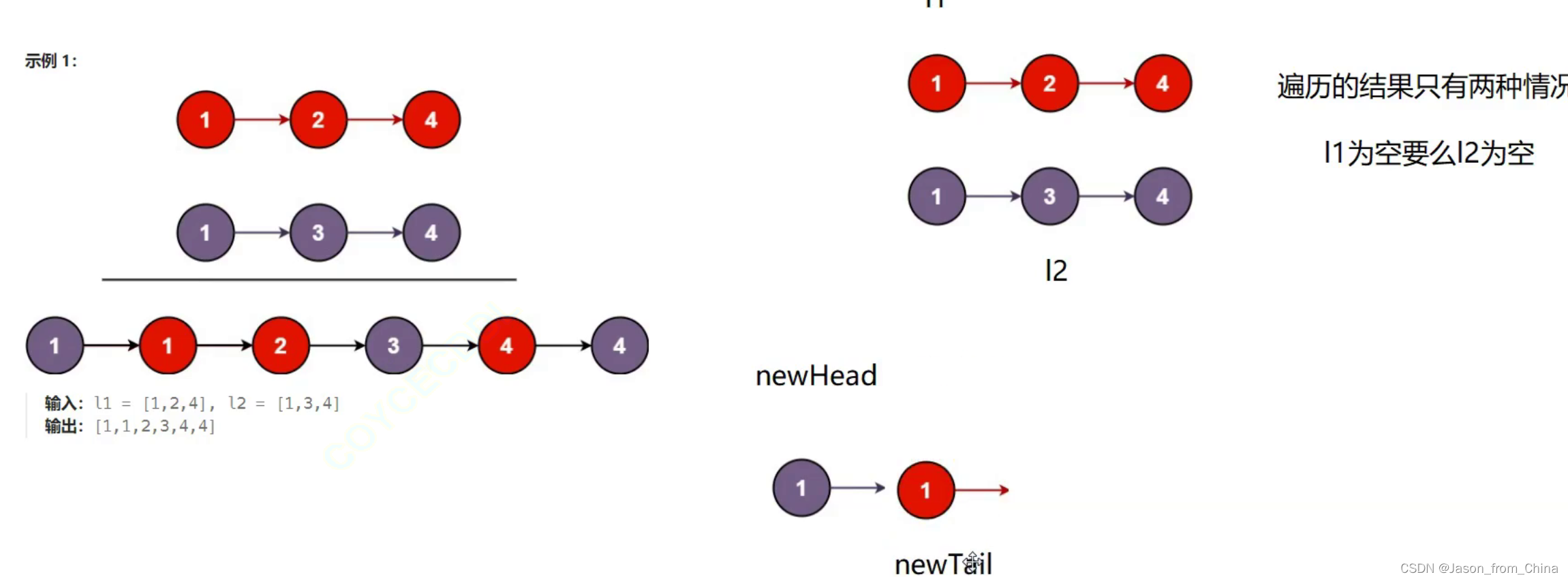
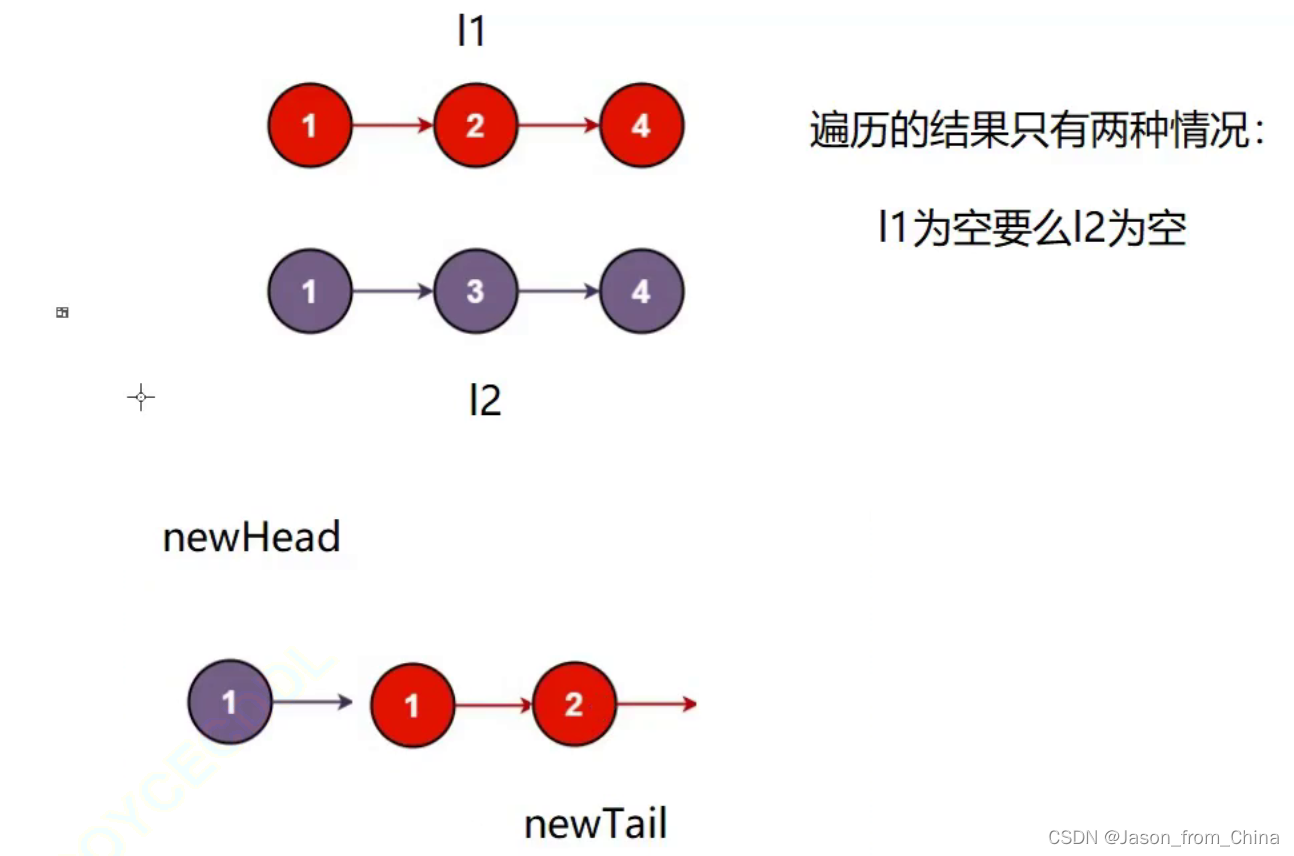
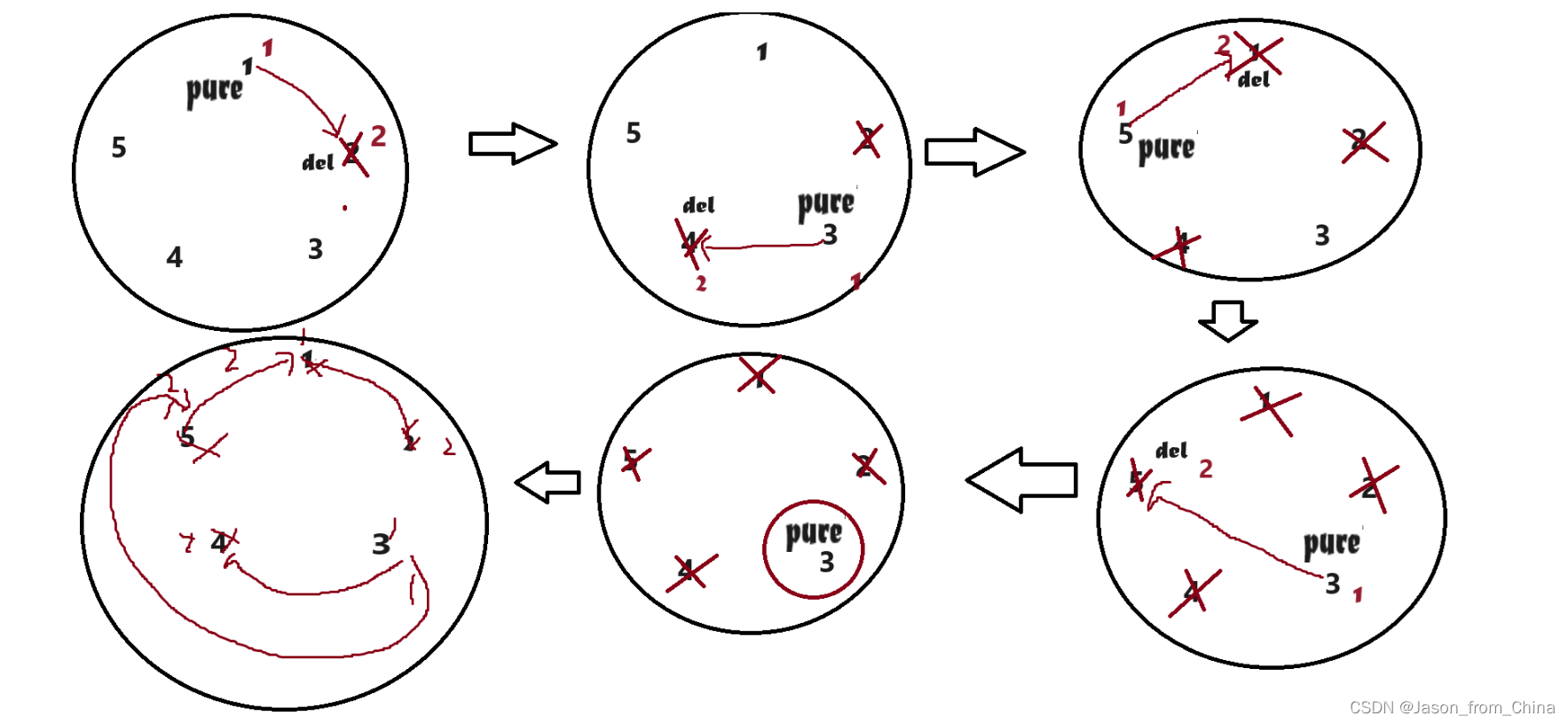
链表的经典算法(循环链表的经典应用(约瑟夫问题))
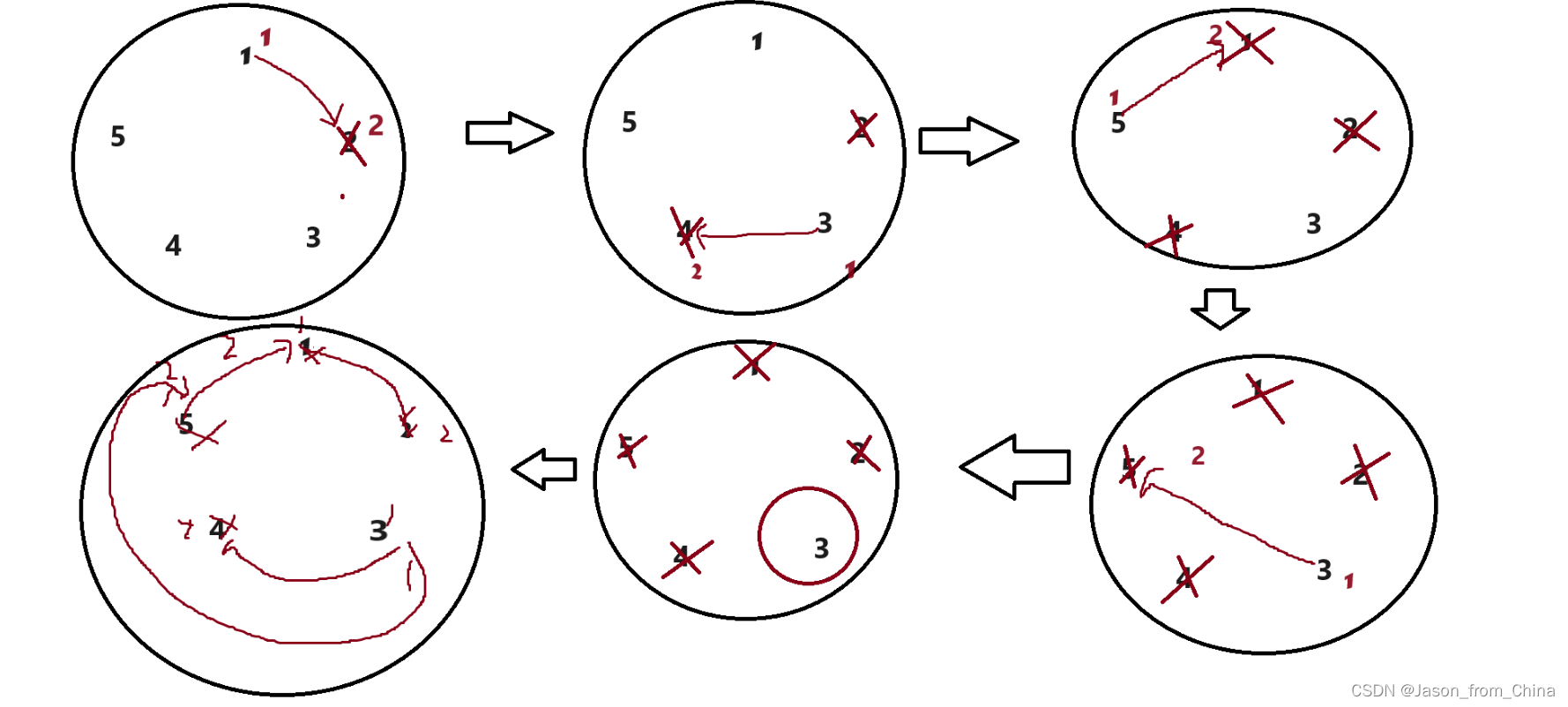
约瑟夫问题(Josephus Problem)是一个著名的数学问题,起源于古罗马时期。问题描述如下:
有一圈人围坐在一起,每个人都有一个编号。从第一个人开始报数,数到三的人会被杀掉,然后从下一个人重新开始报数,重复这个过程,直到所有人都被杀掉为止。问最后剩下的是谁?
约瑟夫问题的解题思路可以通过不同的数学方法来探讨,以下是几种常见的解题方法:
1. 模拟法:
通过编程或者手动模拟这个过程,不断剔除数到3的人,直到圈中只剩下一人。这种方法直观但效率不高,对于人数较多的情况不适用。
2. 数学法(循环队列):
如果人数较少,可以通过数学方法直接计算出最后剩下的人的编号。假设总人数为n,当n是3的倍数时,最后剩下的是第n/3个人;当n不是3的倍数时,最后剩下的是第(n+1)/3个人。这是因为每轮结束后,编号为3的倍数的人都会被剔除,所以每轮结束后剩下的人数实际上是原来人数的三分之一。
3. 递归法:
利用递归思想,定义函数f(n)表示n个人围坐一圈时最后剩下的人的编号。根据约瑟夫问题的规则,f(n)可以表示为f(f(n-1)) + 1。通过递归调用这个函数,可以得到最后剩下的人的编号。
4. 迭代法:
类似于递归法,但是使用迭代的方式来实现。可以通过循环来不断计算下一轮剩下的人的编号,直到只剩下一人。
5. 动态规划法:
对于更一般的情况,即约瑟夫问题的变体,可以使用动态规划的方法来解决。例如,如果每次数到m的人会被杀掉,可以使用状态转移方程来计算最后剩下的人的编号。
约瑟夫问题还有许多变体,例如双向约瑟夫问题、约瑟夫问题的高级版本等,解决方法也会因问题的不同而有所差异。
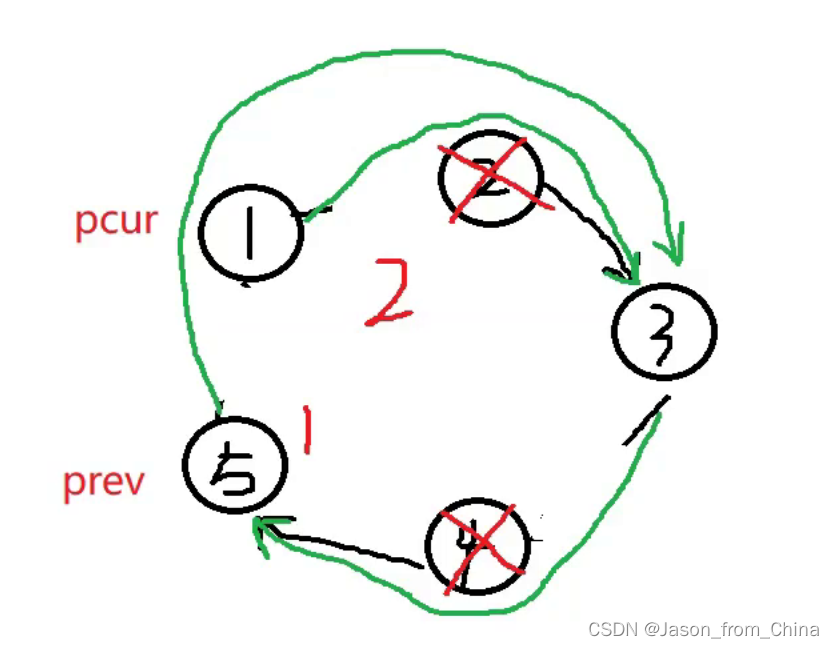
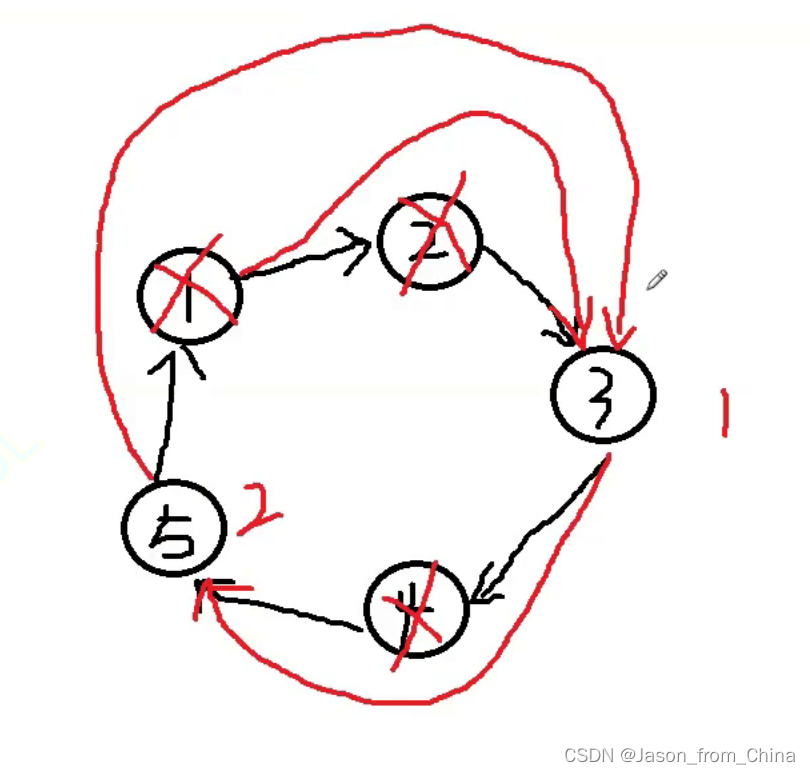
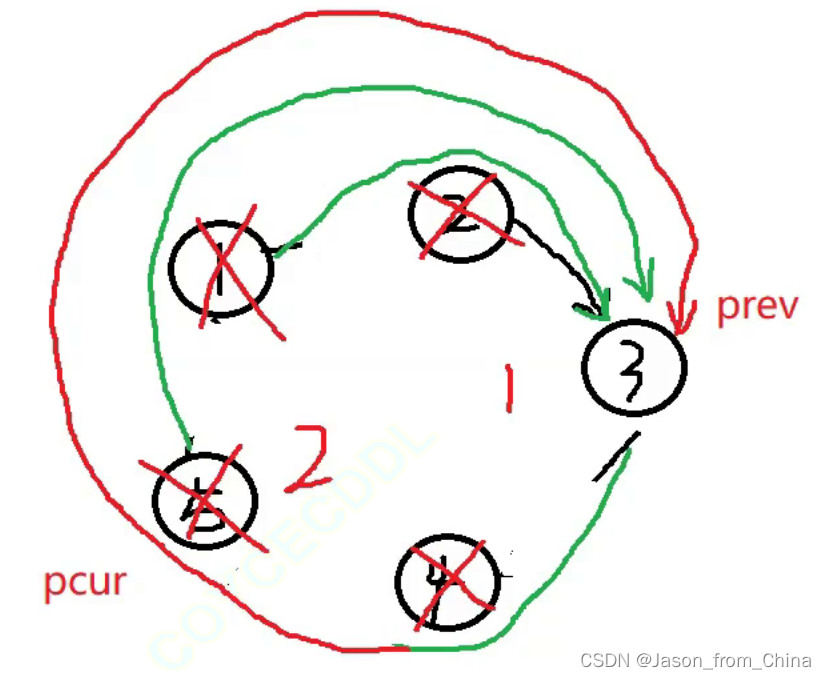
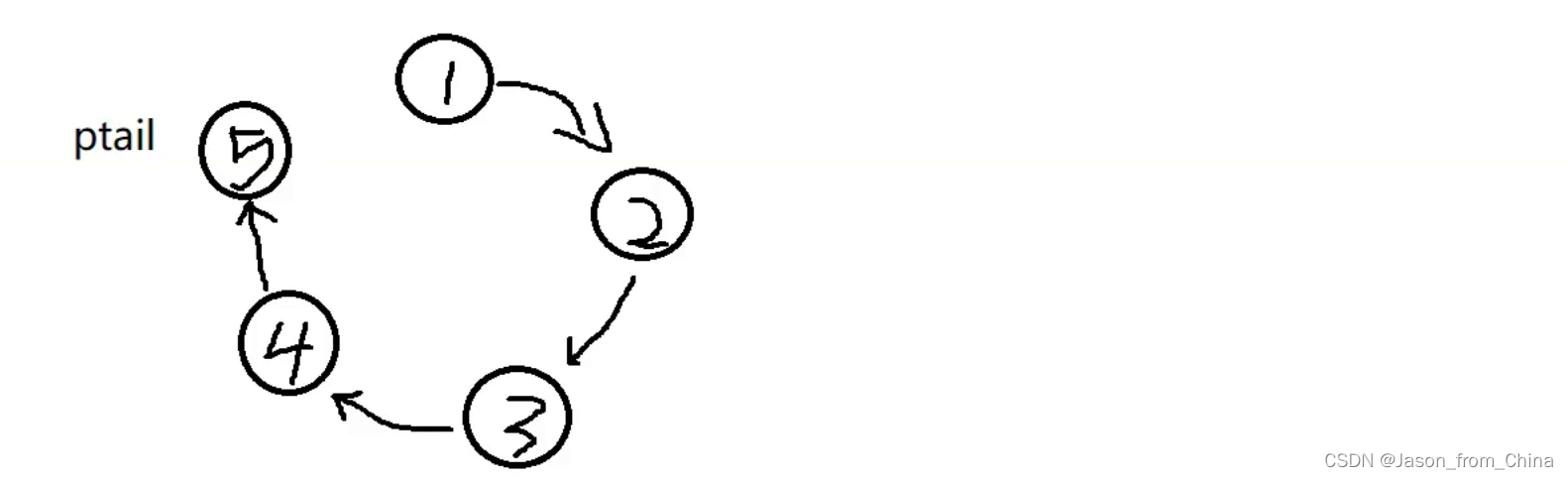
prev先指向pcur的下一个节点
已经成环了,所以只要当前节点下一个节点不是,就可以一直循环,要是下一个节点是第一个节点,说明此时节点只有一个节点,可以返回了
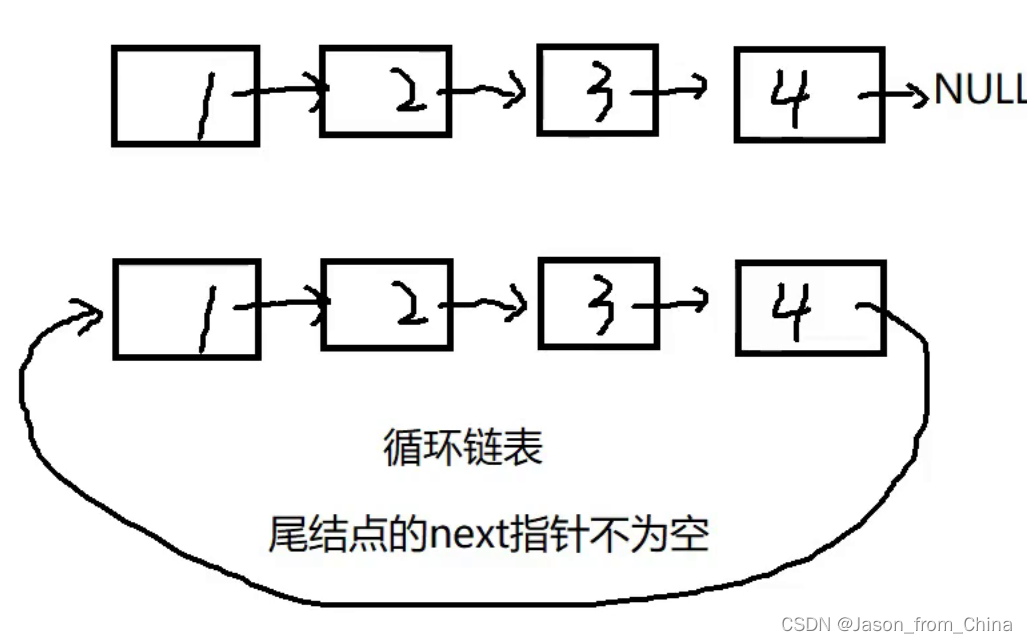
瑟夫问题(Josephus Problem)是一个著名的数学问题,它涉及到在循环链表中删除特定编号的节点。问题的描述是这样的:假设有一圈人围坐在一起,每个人都有一个编号。从第一个人开始报数,数到某个特定数字的人就会被淘汰,然后从下一个人开始重新报数,重复这个过程,直到最后只剩一个人。约瑟夫问题可以通过多种方法解决,其中一种经典的方法是使用循环链表。
以下是使用循环链表解决约瑟夫问题的步骤:
创建一个循环链表,每个人都是一个节点,节点包含一个数据域(编号)和一个指针域(指向下一个节点的指针)。
初始化一个指针,指向链表的头节点。
进行报数操作:
- 从头节点开始,每次移动指针数到指定的数字。
- 当指针指向的节点编号等于指定的数字时,删除该节点(在链表中删除节点需要更新前后节点的指针)。
- 如果链表中只剩下一个节点,则直接返回该节点。
- 如果指针指向的节点是最后一个节点,则需要特殊处理,因为删除节点后需要继续下一次报数。这时,可以将头指针指向链表的第二个节点,然后继续报数。
重复步骤3,直到只剩下一个节点。
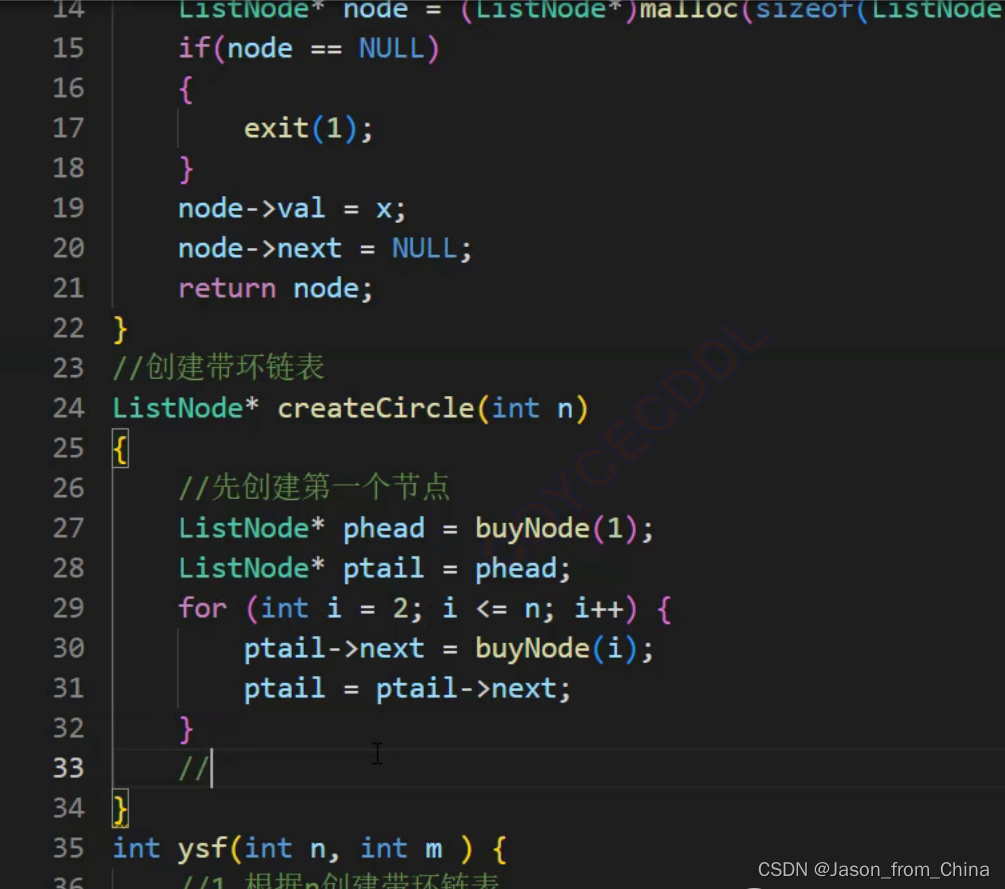
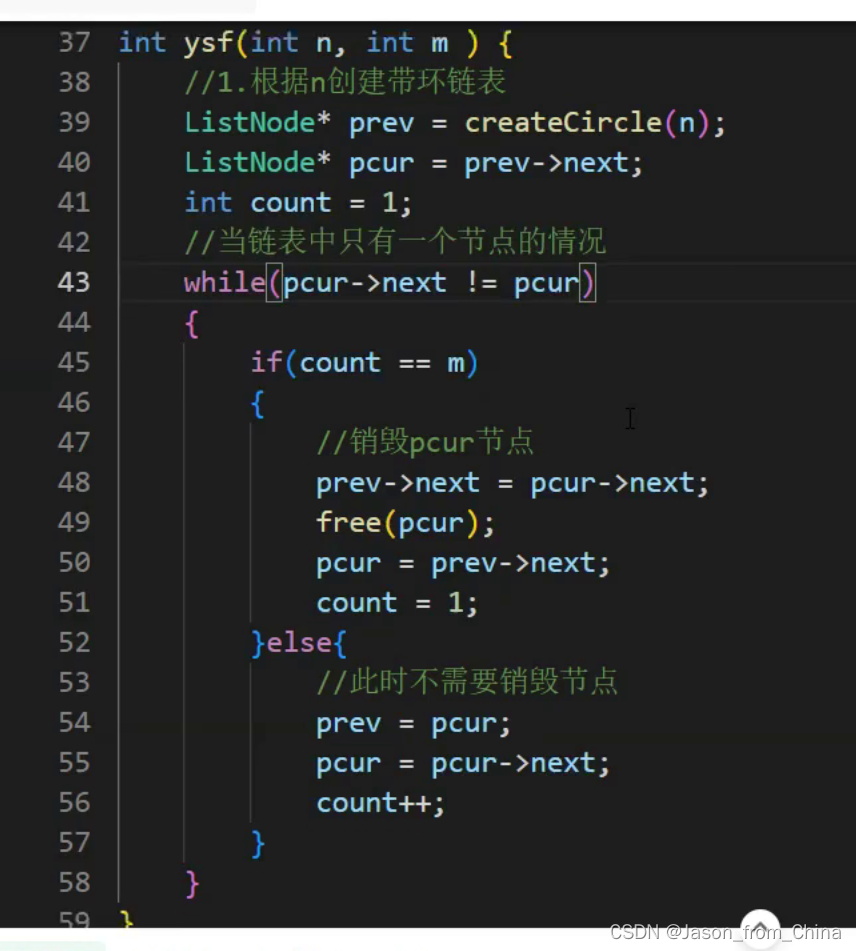
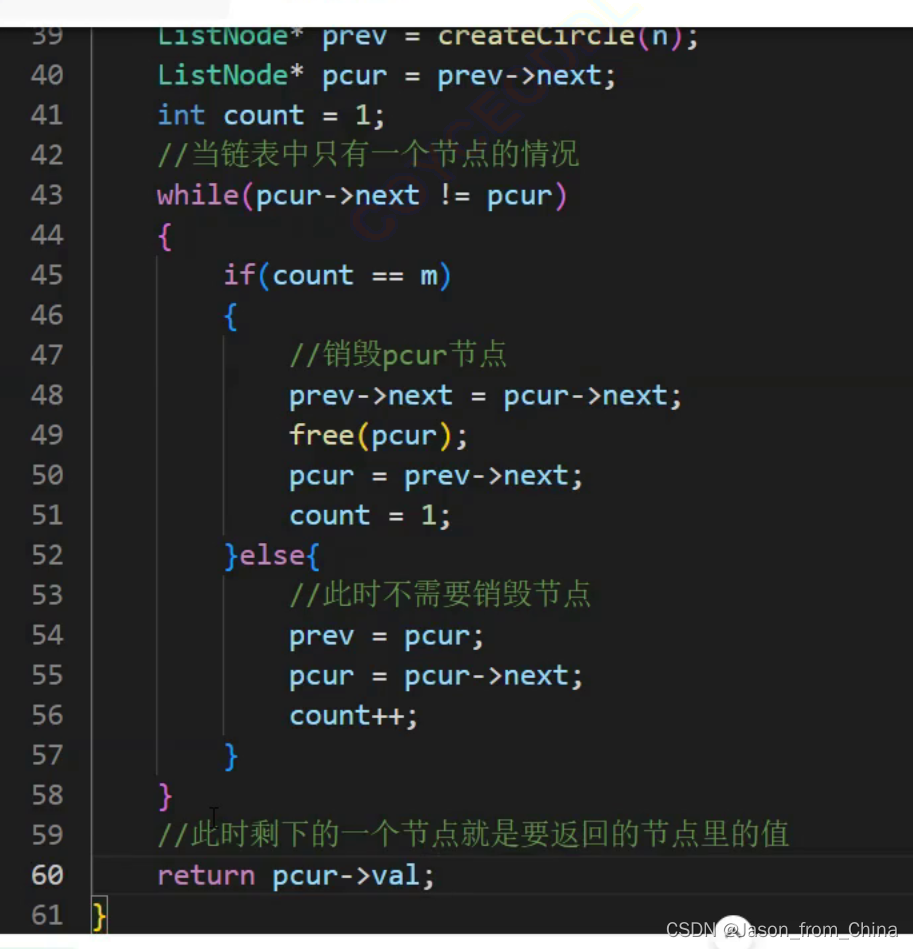
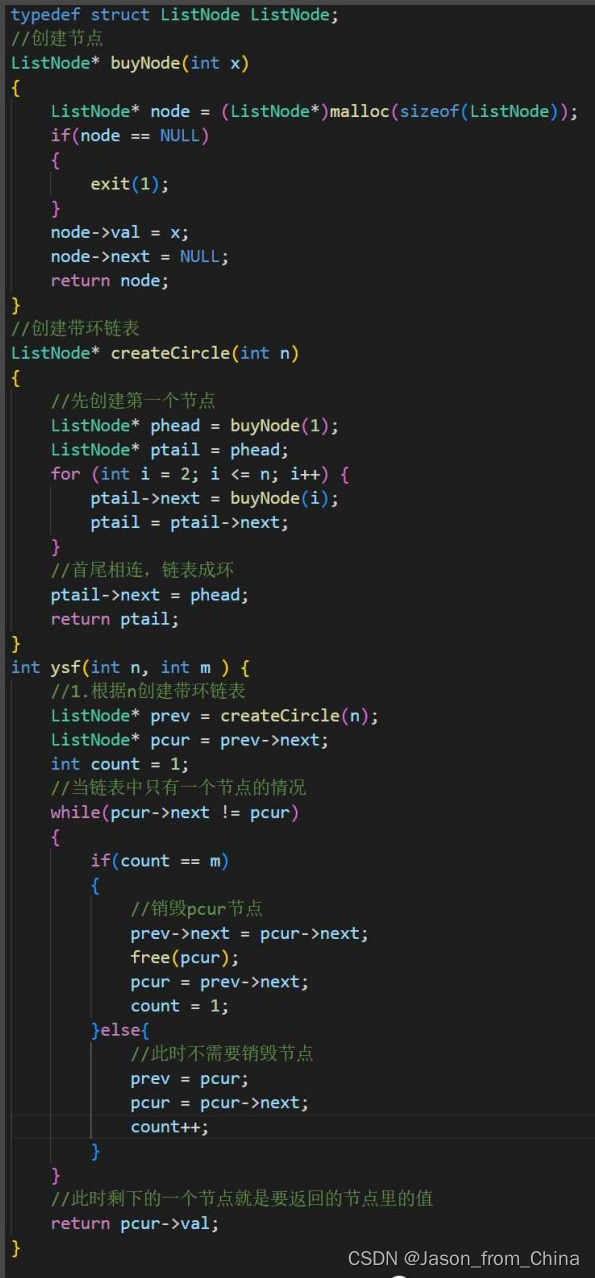
#include <stdio.h> typedef struct ListNode ListNode ; //创建节点 ListNode* newnode(int x) { //防止开辟空间失败,使用节点进行接收 ListNode*node=(ListNode*)malloc(sizeof(ListNode)); if(node==NULL) { perror("node"); exit(1); } //开辟成功以后进行赋值 ListNode*pure=node; pure->val=x; pure->next=NULL; return pure; } //形成环形链表,n需要多大的环形链表 ListNode* circlenode(int n) { //创建第一个节点 ListNode* headnode=newnode(1); //循环节点(运动的节点)开始指向头结点,下一个就是新开辟的节点 ListNode* patilenode=headnode; //循环创建节点 for (int i=2; i<=n; i++) { patilenode->next=newnode(i); //链接下一个节点 patilenode=patilenode->next; } //形成环形链表 patilenode->next=headnode; return headnode; } //实现约瑟夫问题,n是创建的节点的个数,2是第几个死亡 int ysf(int n, int m ) { //返回的头节点 ListNode*head=circlenode(5); //运行的节点(循环的节点) ListNode*pure=head; //需要删除的节点 ListNode*del=pure; //pure找到尾结点 while (pure->next!=del) { pure=pure->next; } int count=1; while (pure->next!=pure) { if (count==m) { //把节点进行改变 pure->next=del->next; //把删除的节点,但是没有进行释放 //del=del->next; //删除节点并未进行释放 free(del); del=pure->next; //重新赋值,这里赋值的是1,如果是0的情况需要-1==m count=1; } else { //循环寻找下一个节点 del=del->next; pure=pure->next; //进行计数,这里是判断m用的,m到第几个了 count++; } } return pure->val; }





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









