








什么是时间复杂度
时间复杂度是一个用来描述算法执行时间与输入数据规模之间关系的量化表达。它是一种理论计算机科学中的概念,用于预测算法在不同输入规模下的表现。时间复杂度通常用大O符号(O-notation)表示,它提供了一种简洁的方式来描述算法最坏情况下的运行时间随着输入规模增长的速度。
时间复杂度的关键点在于它关注的是增长率,而不是具体的执行时间。这是因为同一个算法在不同的计算机上、不同的编译器下或者不同的执行环境中,其具体的执行时间可能会有很大的差异。因此,时间复杂度提供了一种与具体实现无关的性能评估方式。
例如,如果一个算法的时间复杂度是O(n),那么当输入规模n增加时,算法的执行时间将以线性比例增加。如果时间复杂度是O(n^2),那么执行时间将以二次方的比例增加,这意味着随着n的增长,算法的执行时间将迅速增长。
时间复杂度的计算通常基于以下假设:
- 每条基本操作(如赋值、比较、算术运算等)执行的时间是一个常数。
- 递归算法的时间复杂度是递归调用的次数乘以每次调用的时间复杂度。
时间复杂度的分析有助于我们在设计算法时做出更合理的选择,尤其是在处理大规模数据时,能够预测和优化算法的性能。
时间复杂度存在的意义
算法效率
如何衡量一个算法的好坏
如何衡量一个算法的好坏呢?
比如对于以下斐波那契数列:
斐波那契数列的递归实现方式非常简洁,但简洁一定好吗?那该如何衡量其好与坏呢?
我们随便在力扣找一个题目, 会发现我们有好几种解法,哪个解法满足需求呢,那个不满足呢,根据时间复杂度我们可以进行判断
算法的复杂度
算法在编写成可执行程序后,运行时需要耗费时间资源和空间(内存)资源 。因此衡量一个算法的好坏,一般
是从时间和空间两个维度来衡量的,即时间复杂度和空间复杂度。
时间复杂度主要衡量一个算法的运行快慢,而空间复杂度主要衡量一个算法运行所需要的额外空间。在计算
机发展的早期,计算机的存储容量很小。所以对空间复杂度很是在乎。但是经过计算机行业的迅速发展,计
算机的存储容量已经达到了很高的程度。所以我们如今已经不需要再特别关注一个算法的空间复杂度。

时间复杂度计算的是什么
时间复杂度计算的是算法执行的操作次数与输入规模之间的关系。
它通常用来估计算法随着输入规模增长而增长的速度。时间复杂度并不是计算算法执行的具体次数,而是算法执行次数的表达式,通常用大O符号表示。
例如,如果一个算法的时间复杂度是O(n),这意味着随着输入规模n的增加,算法执行的操作次数将线性增加。如果输入规模翻倍,那么算法执行的操作次数也大约翻倍。这里的n代表输入规模,但并不一定是字面上的输入元素个数,它可以是与输入规模相关的任何量度,如数组长度、树的高度等。
时间复杂度的计算通常会忽略常数项和低阶项,因为它关注的是输入规模增长时算法的增长趋势,而不是具体的执行次数。例如,一个算法的时间复杂度可能是3n^2 + 2n + 1,但通常会简化为O(n^2),因为当n变得非常大时,n^2项将比其他项更加显著。
总结来说,时间复杂度是一种用来描述算法性能随着输入规模增长而变化的抽象工具,它帮助我们理解算法的效率,并在不同的算法之间进行比较。
时间复杂度的概念
时间复杂度的定义:在计算机科学中,算法的时间复杂度是一个函数,它定量描述了该算法的运行时间。
一个算法执行所耗费的时间,从理论上说,是不能算出来的,只有你把你的程序放在机器上跑起来,才能知道。
但是我们需要每个算法都上机测试吗?是可以都上机测试,但是这很麻烦,所以才有了时间复杂度这个分析方式。
一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法的时间复杂度。
即:找到某条基本语句与问题规模N之间的数学表达式,就是算出了该算法的时间复杂度。
时间复杂度的大O的表示方法
大O符号(Big O notation):是用于描述函数渐进行为的数学符号。
推导大O阶方法:
1、用常数1取代运行时间中的所有加法常数。
2、在修改后的运行次数函数中,只保留最高阶项。
3、如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
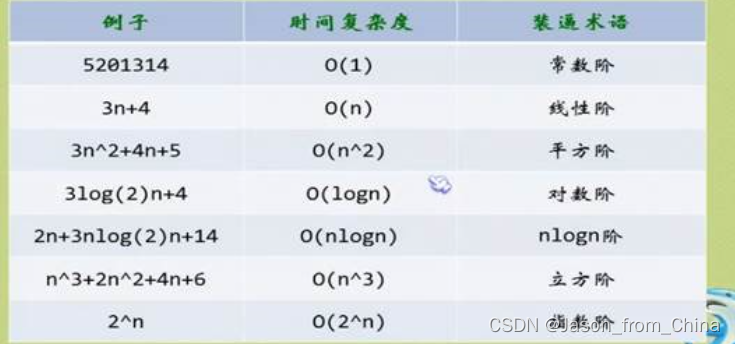
时间复杂度不同的o表示什么意思
时间复杂度中的大O符号(O-notation)用于描述算法运行时间随着输入规模增长的增长率。不同的O表示对应不同的增长率,从而反映了算法效率的不同。以下是一些常见的时间复杂度表示及其含义:
1. **O(1)**: 常数时间复杂度。表示算法的运行时间与输入规模无关,无论输入数据有多大,算法的运行时间都保持不变。
2. **O(log n)**: 对数时间复杂度。表示算法的运行时间随着输入规模的增加而增长非常缓慢。对数时间复杂度通常出现在分而治之(divide and conquer)算法中,如二分查找。
3. **O(n)**: 线性时间复杂度。表示算法的运行时间与输入规模成线性关系。如果输入规模翻倍,运行时间也大致翻倍。
4. **O(n log n)**: 对数线性时间复杂度。这种复杂度出现在许多高效的排序算法中,如归并排序和快速排序。
5. **O(n^2)**: 二次时间复杂度。表示算法的运行时间随着输入规模的增长而呈平方增长。典型的例子是简单的排序算法,如选择排序和插入排序。
6. **O(2^n)**: 指数时间复杂度。表示算法的运行时间以指数方式增长,即使输入规模只有很小的增加,运行时间也会急剧增加。这类算法通常只在输入规模非常小的情况下可行。
7. **O(n!)**: 阶乘时间复杂度。表示算法的运行时间随着输入规模的增加而呈阶乘增长,这是一种非常低效的复杂度,通常出现在解决组合问题的算法中。
这些不同的时间复杂度表示了算法效率的巨大差异。在实际应用中,我们通常追求更低的时间复杂度,以便在处理大规模数据时保持高效。然而,具体选择哪种算法还需要考虑问题的具体情况,包括数据的特点、算法的稳定性、实现复杂性等因素。

时间复杂度是如何判断和计算的
举例1
// 计算BinarySearch的时间复杂度? int BinarySearch(int* a, int n, int x) { assert(a); int begin = 0; int end = n-1; // [begin, end]:begin和end是左闭右闭区间,因此有=号 while (begin <= end) { int mid = begin + ((end-begin)>>1); if (a[mid] < x) begin = mid+1; else if (a[mid] > x) end = mid-1; else return mid; } return -1; }二分查找(BinarySearch)的时间复杂度是 O(log n)。这是因为在每次迭代中,算法都会将搜索区间减半。初始时,搜索区间的大小是 n,然后在每次迭代中,区间的大小都会减少大约一半。因此,需要迭代 log2(n) 次才能找到目标元素或确定其不存在。
在你提供的代码中,二分查找的实现是标准的。它使用一个 while 循环来不断地将搜索区间减半,直到找到目标元素或者区间为空(即 begin > end)。在每次迭代中,它计算中间位置 mid,然后根据 a[mid] 与 x 的比较结果来调整搜索区间的边界。
由于每次迭代都将搜索区间的大小减少大约一半,所以这个算法的时间复杂度是 O(log n)。这使得二分查找非常高效,特别是对于大规模数据的搜索问题。

举例2

举例3
// 计算Func2的时间复杂度? void Func2(int N) { int count = 0; for (int k = 0; k < 2 * N ; ++ k) { ++count; } int M = 10; while (M--) { ++count; } printf("%d\n", count); }在这段代码中,我们可以看到有两个主要的循环结构:一个 for 循环和一个 while 循环。
1. for 循环:这个循环会执行 2*N 次,因此它的时间复杂度是 O(2*N)。但是,在大 O 表示法中,我们通常会忽略常数因子,所以这个循环的时间复杂度可以简化为 O(N)。
2. while 循环:这个循环会执行 10 次,因此它的时间复杂度是 O(1),即常数时间复杂度,因为执行的次数不随输入规模 N 的变化而变化。
由于这两个循环是顺序执行的,我们可以将它们的时间复杂度相加来得到整个函数的时间复杂度。也就是O(N+1)但是,由于 O(N) 的增长速度远大于 O(1),所以在考虑整个函数的时间复杂度时,O(1) 部分可以忽略不计。
因此,Func2 函数的时间复杂度是由 for 循环决定的,即 O(N)。
举例4
// 计算Func3的时间复杂度? void Func3(int N, int M) { int count = 0; for (int k = 0; k < M; ++ k) { ++count; } for (int k = 0; k < N ; ++ k) { ++count; } printf("%d\n", count); }对于 Func3 函数,我们可以看到它包含两个循环,一个循环依赖于变量 M,另一个依赖于变量 N。第一个循环执行 M 次,第二个循环执行 N 次。由于这两个循环是顺序执行的,我们可以将它们的时间复杂度相加。
第一个循环的时间复杂度是 O(M),第二个循环的时间复杂度是 O(N)。
因此,Func3 函数的总时间复杂度是 O(M + N)。在这种情况下,我们不能简化为一个单一的变量,因为 M 和 N 可能独立变化,且它们对时间复杂度的贡献都很重要。
总结:
- Func3 的时间复杂度是 O(M + N)。
举例5
// 计算Func4的时间复杂度? void Func4(int N) { int count = 0; for (int k = 0; k < 100; ++ k) { ++count; } printf("%d\n", count); }Func4 函数的时间复杂度是 O(1),即常数时间复杂度。
这是因为函数中的循环执行次数是一个固定的数(100次),
并不依赖于输入参数 N 的值。在计算时间复杂度时,我们忽略所有常数项和低阶项,只关注输入规模的增长率。由于 Func4 函数的执行时间不随输入规模的增长而变化,因此它的时间复杂度是常数时间复杂度。
举例6
// 计算BubbleSort的时间复杂度? void BubbleSort(int* a, int n) { assert(a); for (size_t end = n; end > 0; --end) { int exchange = 0; for (size_t i = 1; i < end; ++i) { if (a[i-1] > a[i]) { Swap(&a[i-1], &a[i]); exchange = 1; } } if (exchange == 0) break; } }``BubbleSort` 函数的时间复杂度是 O(n^2),
其中 n 是数组 `a` 的长度。冒泡排序是一种简单的排序算法,它通过重复遍历要排序的数列,比较每对相邻元素的值,如果它们的顺序错误就把它们交换过来。遍历数列的工作重复进行,直到没有再需要交换的元素为止。
在最坏的情况下,冒泡排序需要遍历数组 n-1 次,第一次遍历需要 n-1 次比较,第二次遍历需要 n-2 次比较,依此类推,直到最后一次遍历只需要 1 次比较。因此,总的比较次数是 (n-1) + (n-2) + ... + 1 = n(n-1)/2,这是一个关于 n 的二次函数,所以时间复杂度是 O(n^2)。
需要注意的是,如果数组已经部分有序,冒泡排序可能会在少于 n^2 次比较后提前结束,但是在最坏情况下的时间复杂度仍然是 O(n^2)。简单的说就是,这个俩循环嵌套,每次循环n-1次数,也就是我们循环(n-1)(n-1),然后根据时间复杂度的简化,我们保留影响最大的数值,n^2
举例7
计算的是次数,不是计算的数值
所以是O(N)

举例8

举例9
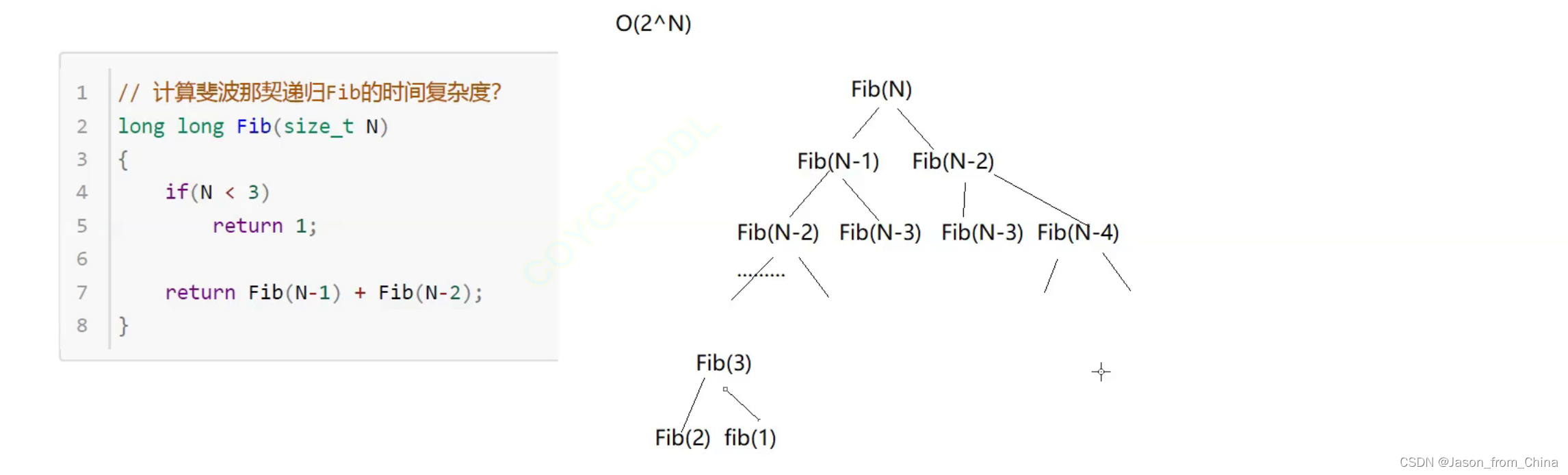
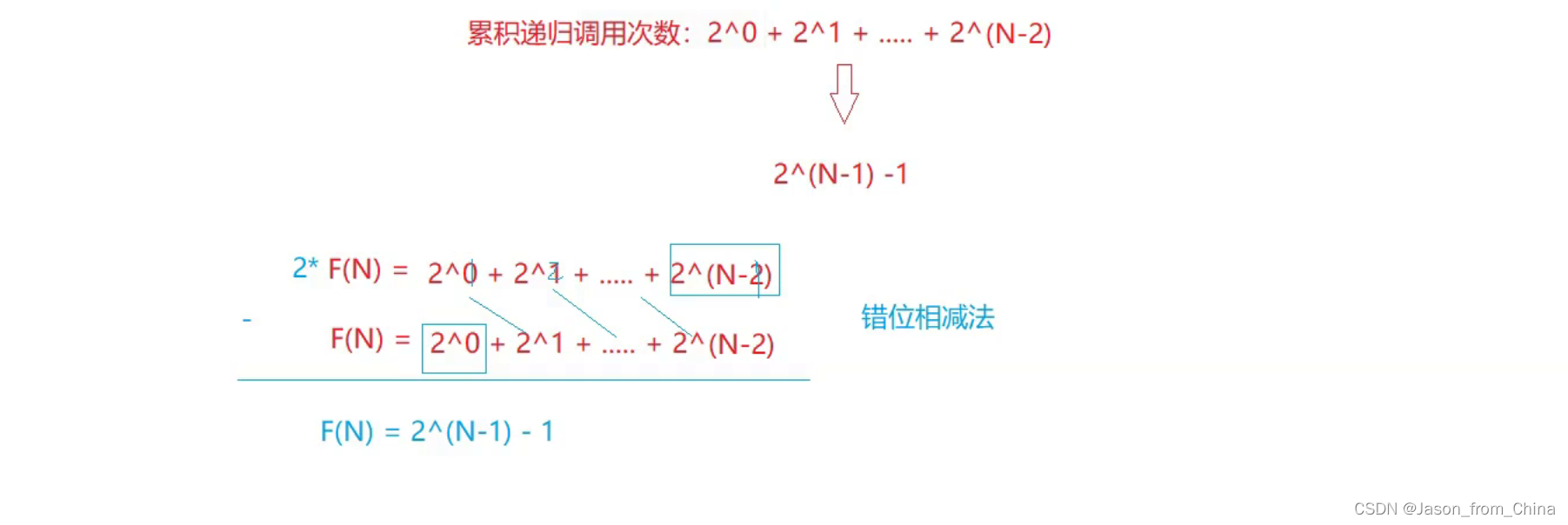
递归时间复杂度:所有递归调用次数累加

时间复杂度的简化
什么意思呢
就比如
1.基本操作执行了2N+10次,通过推导大O阶方法知道
时间复杂度为 O(N)
2.基本操作执行了M+N次,有两个未知数M和N
时间复杂度为 O(N+M)
3.基本操作执行了10次,通过推导大O阶方法
时间复杂度为 O(1)
4.基本操作执行最好1次,最坏N次,时间复杂度一般看最坏
时间复杂度为 O(N)
5.基本操作执行最好N次,最坏执行了(N*(N+1)/2次,通过推导大O阶方法+时间复杂度一般看最坏
时间复杂度为 O(N^2)
6.基本操作执行最好1次,最坏O(logN)次,时间复杂度为 O(logN) ps:logN在算法分析中表示是底数为2,对数为N。有些地方会写成lgN。(建议通过折纸查找的方式讲解logN是怎么计算出来的)
7.通过计算分析发现基本操作递归了N次
时间复杂度为O(N)。
8.通过计算分析发现基本操作递归了2^N次
时间复杂度为O(2^N)。
为什么进行简化
时间复杂度的简化是为了让我们能够更容易地理解和比较不同算法的性能,尤其是在分析大规模数据时。简化的原因主要包括以下几点:
1. **忽略常数因子**:在大规模数据情况下,常数因子对算法执行时间的影响相对较小。例如,一个算法运行时间是 3n 和 100n,在 n 非常大时,这两个时间的实际差异并不大。因此,在分析时间复杂度时,我们通常忽略常数因子,关注增长率。
2. **忽略低阶项**:当输入规模 n 非常大时,高阶项(如 n^2)的增长速度远高于低阶项(如 n 或常数项)。因此,在分析时间复杂度时,我们通常忽略低阶项,因为它们对总的执行时间的影响可以忽略不计。
3. **关注最坏情况**:时间复杂度通常基于最坏情况来计算,这是因为我们想要确保算法在任何情况下都能在可接受的时间内运行。最坏情况给出了算法运行时间的上界,这样我们就可以知道算法性能的最差情况。
4. **简化比较**:通过简化时间复杂度表达式,我们可以更容易地比较不同算法的性能。例如,比较 O(n) 和 O(n^2) 比 compared 3n 和 100n^2 要简单直观得多。
当然最主要的是,和计算机的性能有关
什么意思呢,我这里引入一段文字:
CPU每秒能进行多少次计算,这取决于CPU的时钟频率(通常以赫兹为单位)和CPU的架构。时钟频率指的是CPU的时钟周期数,也就是每秒钟CPU可以执行的周期数。例如,一个2.4 GHz的CPU每秒可以进行24亿(2,400,000,000)次时钟周期。
然而,并不是每个时钟周期都对应一次计算。一个计算可能需要多个时钟周期来完成,这取决于所执行的操作类型和CPU的微架构。现代CPU通常具有流水线设计,可以在一个时钟周期内执行多个指令的部分。此外,CPU可能具有多个核心,每个核心可以独立执行指令,从而进一步提高每秒的计算能力。
例如,一个具有超线程技术的CPU核心可以同时处理两个线程,而一个多核心CPU则可以有多个独立的核心同时工作。这意味着一个4核8线程的CPU理论上可以同时处理8个线程,从而大大提高每秒的计算次数。
总的来说,CPU每秒的计算次数取决于多个因素,包括时钟频率、核心数量、超线程技术、CPU架构和所执行的计算类型。要获得一个确切的数字,需要具体的CPU规格和执行的具体任务。
这里我想表达的是,如果是n^2+n次数
在使用大O表示法时,我们通常会忽略常数项和低阶项,只关注最高阶项和它的系数。因此,对于表达式 `n^2 + n`,我们忽略 `n`(线性项),因为它在高阶项 `n^2`(二次项)面前变得不重要。
所以,`n^2 + n` 的时间复杂度用大O表示法表示为 `O(n^2)`。这意味着随着输入规模 `n` 的增长,算法的运行时间将以 `n^2` 的速度增长。为什么
因为计算机每秒计算的速度是亿次数,那,一亿的平方+一亿,那么一亿其实不影响
时间复杂度一般是考虑最坏情况
考虑最坏情况:时间复杂度通常是基于最坏情况来计算的,这是因为我们想要确保算法在任何情况下都能在可接受的时间内运行。
举例:
最坏情况:任意输入规模的最大运行次数(上界)
平均情况:任意输入规模的期望运行次数
最好情况:任意输入规模的最小运行次数(下界)
例如:在一个长度为N数组中搜索一个数据x
最好情况:1次找到
最坏情况:N次找到
平均情况:N/2次找到
在实际中一般情况关注的是算法的最坏运行情况,所以数组中搜索数据时间复杂度为O(N)
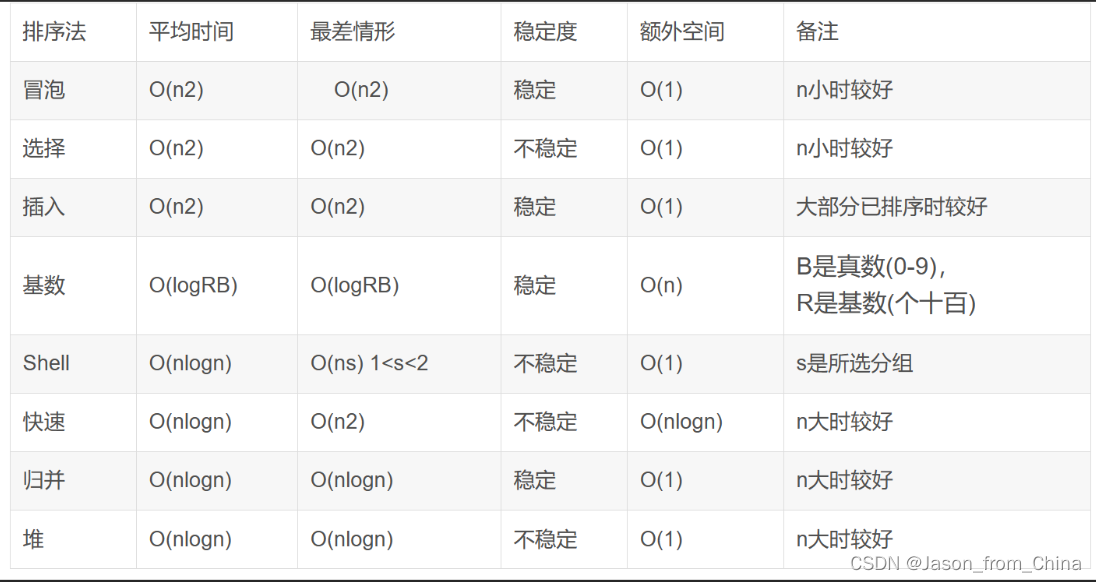
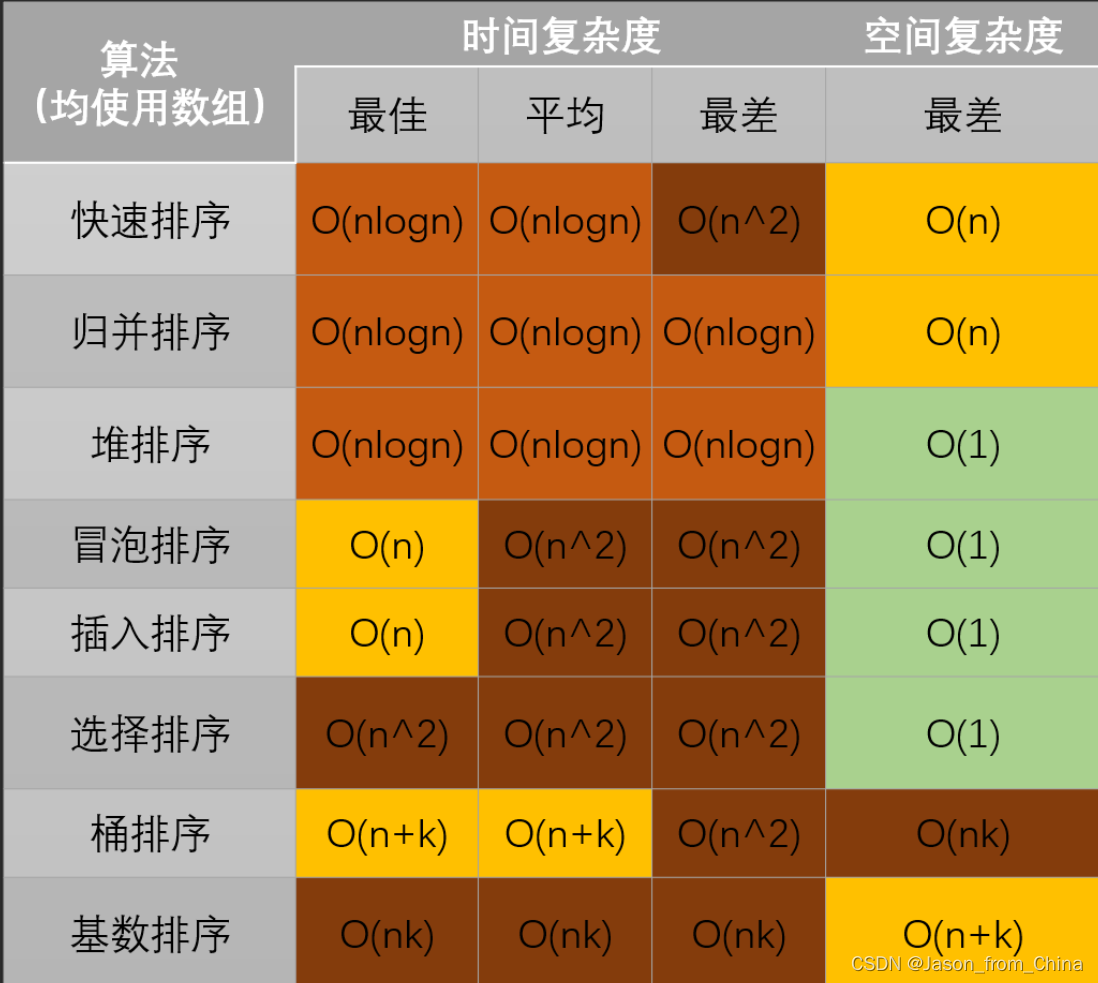
附带(网络搜集)(建议看看)

空间复杂度
什么是空间复杂度
空间复杂度是一个用来衡量算法运行过程中临时占用存储空间大小的量度。它是对一个算法在运行过程中临时占用存储空间大小的估计。空间复杂度不是程序占用的空间,而是执行算法时所需要的存储空间。
空间复杂度通常用大O符号表示,比如O(1)、O(n)、O(n^2)等。其中:
- O(1)表示算法执行过程中临时占用的存储空间大小是常数级别的,不随输入数据规模的增加而增加。
- O(n)表示算法执行过程中临时占用的存储空间大小与输入数据规模n成线性关系。
- O(n^2)表示算法执行过程中临时占用的存储空间大小与输入数据规模n的平方成正比。
空间复杂度的分析有助于我们评估算法在执行过程中对内存的消耗情况,特别是在处理大规模数据时,选择空间复杂度低的算法往往更加高效。空间复杂度
空间复杂度也是一个数学表达式,是对一个算法在运行过程中临时占用存储空间大小的量度 。
空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。
空间复杂度计算规则基本跟实践复杂度类似,也使用大O渐进表示法。
注意:函数运行时所需要的栈空间(存储参数、局部变量、一些寄存器信息等)在编译期间已经确定好了,因
此空间复杂度主要通过函数在运行时候显式申请的额外空间来确定。
也就是计算多少变量来确定空间复杂度是多少
空间复杂度的计算
计算空间复杂度的一些基本步骤和要点:
输入数据空间:首先确定算法处理的输入数据本身占用的空间。例如,对于一个整数数组,其空间占用是数组中所有元素的大小总和。
额外变量空间:计算算法中使用的额外变量所需的空间。这包括局部变量、循环计数器等。
辅助数据结构空间:如果算法中使用了额外的数据结构(如栈、队列、链表、哈希表等),需要计算这些数据结构的最大可能空间占用。
递归调用空间:对于递归算法,需要考虑递归调用栈所需的空间。这通常与递归的深度成正比。
最大使用空间:通常关注算法在最坏情况下的最大空间需求,这包括了所有可能的额外存储需求。
忽略常数因子:在大O表示法中,通常忽略常数因子和低阶项,只关注最高阶项的系数和变量。
空间复杂度表达式:将上述所有因素综合起来,形成算法的空间复杂度表达式。例如,如果一个算法需要 O(1) 的额外空间,它就是原地算法;如果需要 O(n) 的额外空间,它就依赖于输入数据的大小。
数据类型影响:不同编程语言和平台上,相同数据类型的大小可能不同,这可能影响空间复杂度的绝对值,但在大O表示法中通常不体现具体数值。
最坏情况分析:与时间复杂度分析类似,空间复杂度分析通常关注最坏情况下的空间需求。
举例来说,如果一个算法需要处理一个大小为 n 的数组,并且只使用了几个固定大小的变量和常数个额外的数据结构,那么这个算法的空间复杂度通常是 O(n)。如果算法中没有使用任何依赖于输入大小的数据结构,那么空间复杂度可能是 O(1)。
总之,空间复杂度的计算涉及到对算法在执行过程中所有可能占用存储空间部分的考量,然后根据大O表示法来简化和表达。
空间复杂度的举例(用空间换时间)
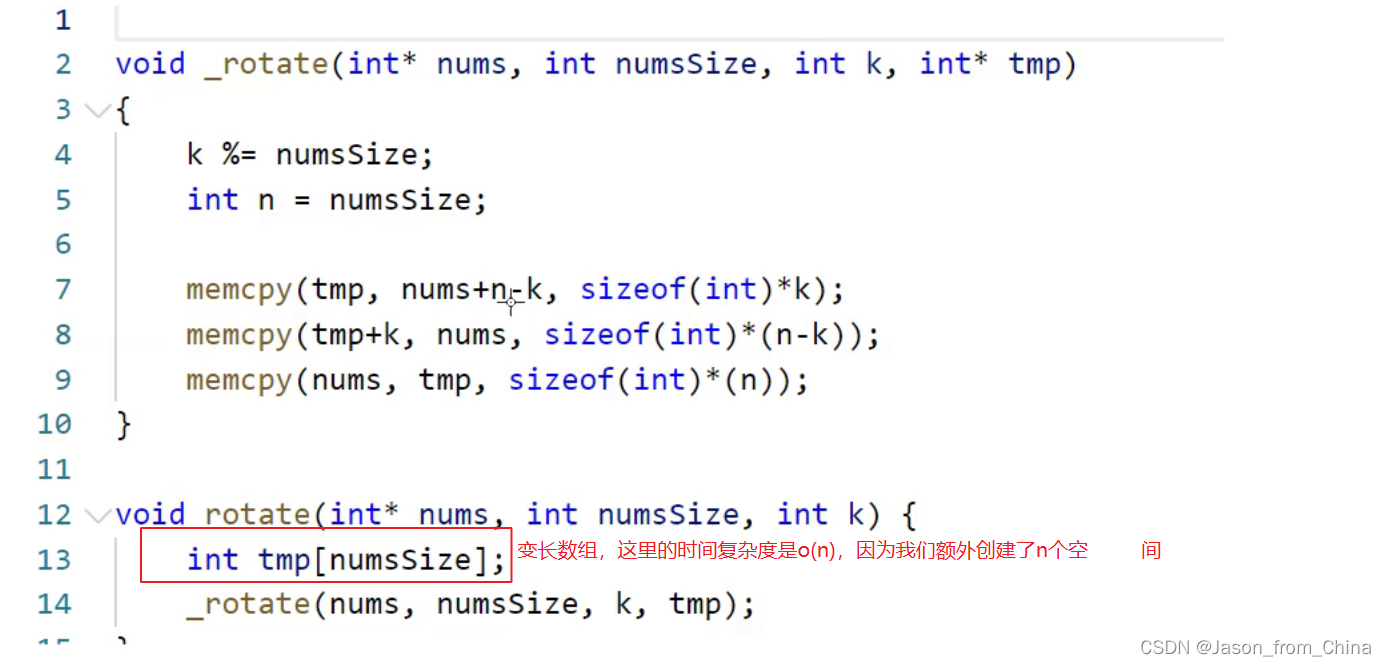
举例1:轮转数组(空间换时间)
用空间换时间
memcpy 并不是专门用于拷贝字符串的函数,而是一个用于内存拷贝的通用函数。它可以将指定长度的内存内容从源地址拷贝到目标地址。memcpy 函数定义在 C 标准库中的 头文件中。
memcpy 函数的原型如下:
void *memcpy(void *dest, const void *src, size_t n);
参数说明:
- dest:指向目标内存块的指针,即拷贝操作的目标地址。
- src:指向源内存块的指针,即拷贝操作的源地址。
- n:要拷贝的字节数。memcpy 可以用于拷贝任何类型的数据,包括字符串。但是,如果拷贝的是字符串,通常建议使用专门为字符串设计的函数 strcpy 或 strncpy,因为它们会考虑字符串的终止符 \0。 需要注意的是,memcpy 不会检查源地址和目标地址之间的重叠,如果存在重叠,可能会导致拷贝结果不正确。在这种情况下,应该使用 memmove 函数,它能够正确处理内存重叠的问题。
所以这里的空间复杂度是O(N),因为我们不知道tmp里面有多少变量,空间复杂度计算的是变量,数组本身不是变量,我们不知道数组里面有多少变量


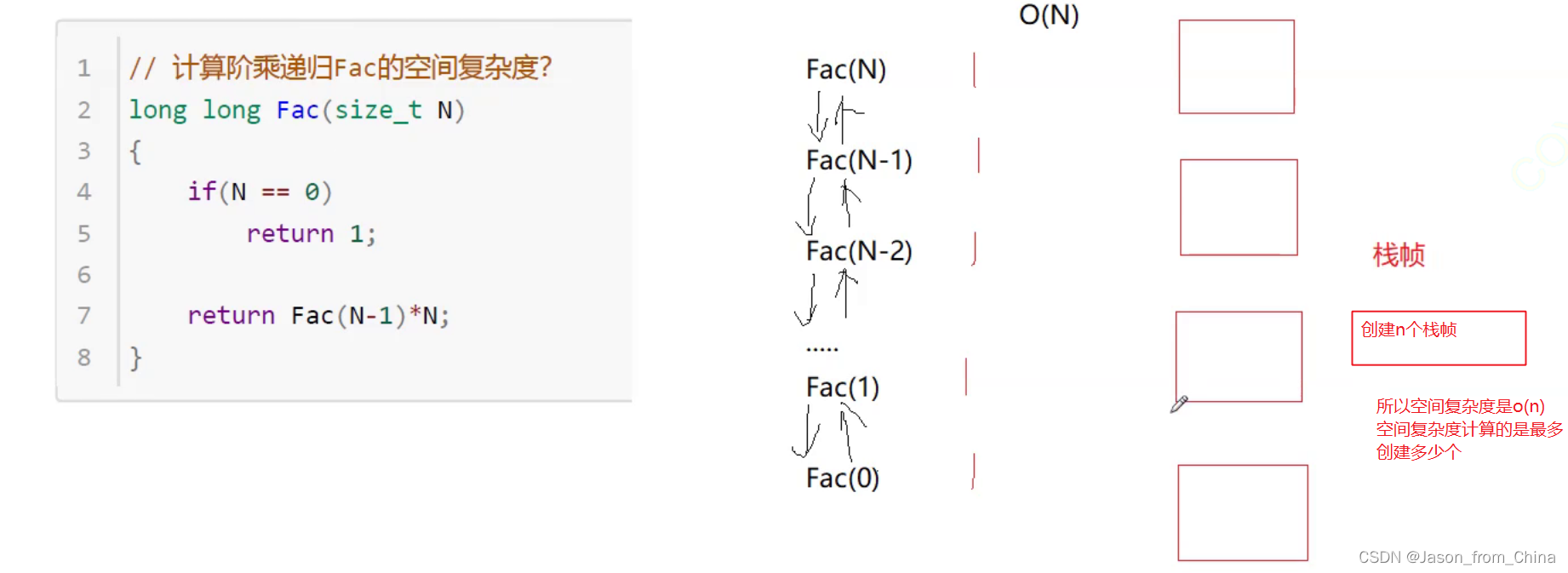
斐波那契数列
斐波那契数列的递归算法的空间复杂度是 O(n)。
递归算法在执行时会在调用栈上为每一层递归调用保留一段空间,用于存储该层调用的参数、返回地址以及局部变量。对于斐波那契数列的递归实现,每一层递归调用都会对应一个斐波那契数列中的元素,因此递归深度最大可以达到 n(n 是斐波那契数列的项数)。
由于每一层递归所需的空间是常数级别的,所以递归算法的空间复杂度是 O(n)。这意味着随着 n 的增大,所需的栈空间将线性增长。
需要注意的是,递归实现斐波那契数列的效率很低,因为它会重复计算很多子问题,时间复杂度是指数级的,为 O(2^n)。在实际应用中,通常会使用动态规划或者矩阵乘法等方法来优化斐波那契数列的计算,以降低时间复杂度。
不同单位之间的字节换算
在计算机科学中,字节(Byte)是存储容量的基本单位,通常用来表示数据量的大小。不同的单位之间转换关系如下:
1 字节(Byte) = 8 比特(bit)
1 千字节(KB) = 1,024 字节
1 兆字节(MB) = 1,024 KB = 1,048,576 字节
1 吉字节(GB) = 1,024 MB = 1,073,741,824 字节
1 太字节(TB) = 1,024 GB = 1,099,511,627,776 字节
1 拍字节(PB) = 1,024 TB = 1,125,899,906,842,624 字节
1 艾字节(EB) = 1,024 PB = 1,152,921,504,606,846,976 字节
1 泽字节(ZB) = 1,024 EB = 1,180,591,620,717,411,303,424 字节
1 尧字节(YB) = 1,024 ZB = 1,208,925,819,614,629,174,706,176 字节
这里要注意的是,上述转换是基于二进制的计算方式,即1千字节实际上等于2的10次方字节。但在一些情况下,例如硬盘制造商在描述其产品的存储容量时,可能会使用十进制系统,即1千字节等于10的3次方字节。这种情况下,1MB将是1,000,000字节,而不是1,048,576字节。通常在计算机科学领域,我们使用的是二进制系统。















 9419
9419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









