







经常有人问,架构师的学习路线是什么?
我一般推荐架构师的基本功,是从「存储选型」开始的。

本文整理了存储选型的思路和整体框架,主要包括几个部分内容:
- 了解目前的存储技术趋势,以及对开发人员新的要求
- 存储选型的原则,避免日常的经典误区
- 结合典型数据库特点,说明如何进行存储选型,提高业务开发效率
- 常见的场景和解决方案
1、存储技术发展看存储选型
1.1 存储类型多样化
DB-Engines数据库排名并不代表数据库的安装数量,或者使用量。但某数据库越来越受欢迎则代表在一定时间范围内更加广泛的使用。
https://db-engines.com/en/ranking
这里贴了一张2022年5月份的排行榜。
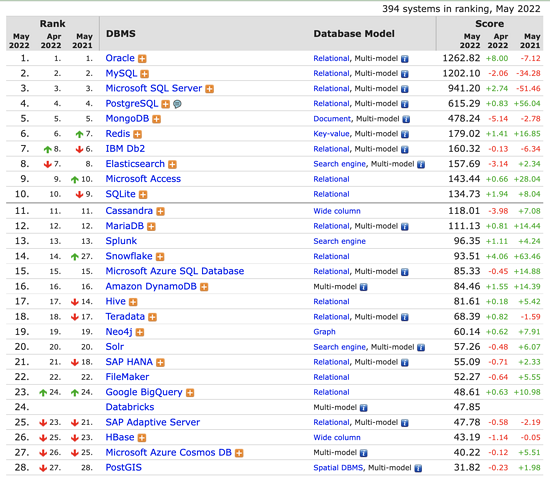
我们对于排名前10的数据库中,比较熟悉的应该是MySQL、Redis和ES,这三个数据库在我们日常开发中占据绝大多数的比例。
但是,这三个数据库只代表了一小部分的数据库类型,我们是不是可以把视野打开更多一些,看看没有更多的数据库类型,可以适合我们不同的业务,包括
Relational、Document、Key-value、Search engine、Wide column、Time Series、Graph等等不同数据库类型。
1.2 云原生存储
除去上面的传统数据库之外,云时代存储技术又有了更多的变化。
除了简单的把上面的数据库托管到云上之外,还多了许多充分利用云的基础设施产生的云原生数据库,比如aws的Amazon Aurora、阿里云的PolarDB、腾讯云的TDSQL等。
另外,云时代还产生了更多类型的数据库,比如阿里云的多模数据库Lindorm、Pingcap的HTAP数据库TiDb等。
多类型数据库是各个云厂商发展的趋势,他们为什么会支持越来越多用途的数据库呢?
供给侧的改变一定是来源于需求侧,因为随着互联网、物联网等场景发展,有很多业务需求不是任何单一的数据库能解决的了。
1.3 告诉我们什么?
「数据库类型多元化」 & 「云原生数据库类型多元化」 是一个必然的发展趋势。
我们要解决的场景会越来越多,我们需要掌握的数据库领域也越来越广,只有这样,我们才能面对在线事务、离线分析、海量存储、成本与效率等因素,真正做好存储选型。
2、存储选型原则:不要耍流氓
2.1 不讲场景的选型都是耍流氓
大家可能都知道,数据库的选型一定是基于实际的业务场景的。但是,可能也遇到过类似的对话:
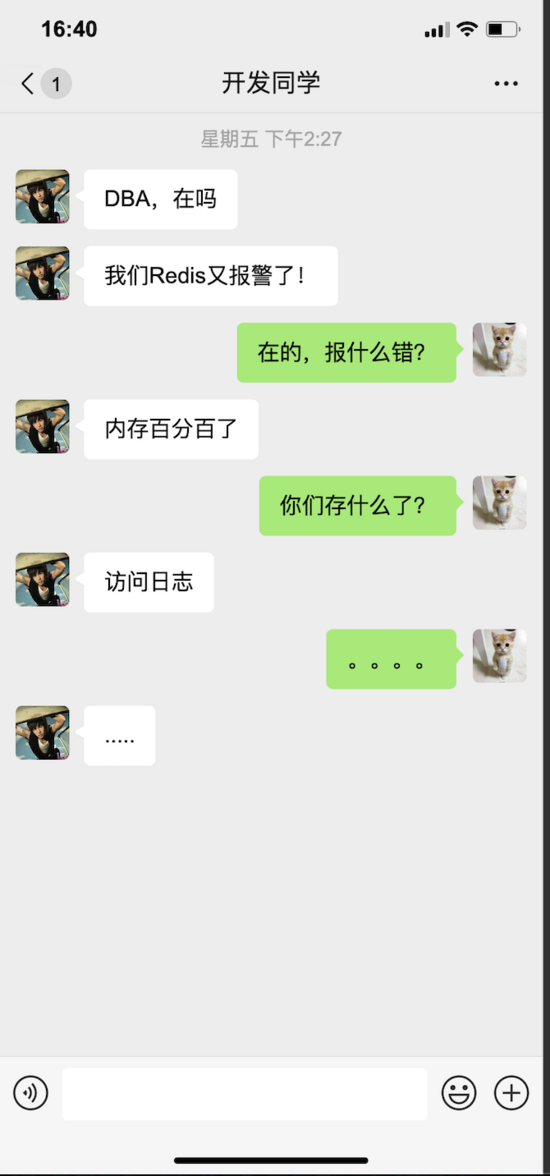
上面的对话可能有些夸张,但是实际生产中,可能是对场景的理解有误,也可能是为了快速完成任务开发,结果是在「特定场景」选
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5871
5871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









