






随着互联网的发展,越来越多的公司需要爬取各种数据来分析出自己公司业务的发展方向。而目前许多目标网站也有各种各样的措施来反爬虫,越是数据价值高的网站反爬做得也就越复杂。给大家列举了几个常见的反爬措施以及解决方案。
1、通过user-agent字段来反爬
最常见的反爬策略就是检测用户的请求头。这个是比较容易实现的反爬,破解起来也是比较容易的,解决方法就是伪装header,只要合理添加请求头就可以正常访问目标网站获取数据。
2、利用代理ip反爬
目前一般网站都会检测某个ip在单位时间内的请求次数,如果单位次数超过了这个阈值就会停止其请求访问。所以一般在爬取的时候我们都会用到代理ip来模拟真实用户使用不同的ip来访问目标网站。
我们通过代理的原理就能够很好地进行了解。
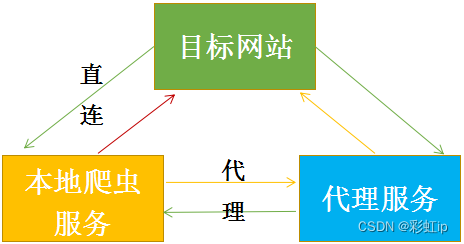
ip代理池架构
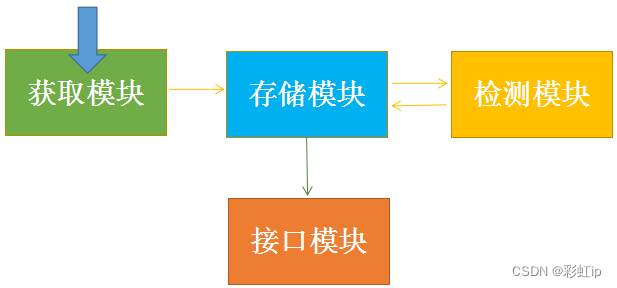

3、通过cookies反爬
cookies也是一个比较常见的反爬手段之一,可以把它和登录放在一起。这里需要注意的是,有些不需要登录的网站也会通过cookies来过滤一些没有经过伪装的爬虫。解决方案就是进行模拟登陆,成功获取cookies之后再进行数据爬取。
cookie代理池模块一般架构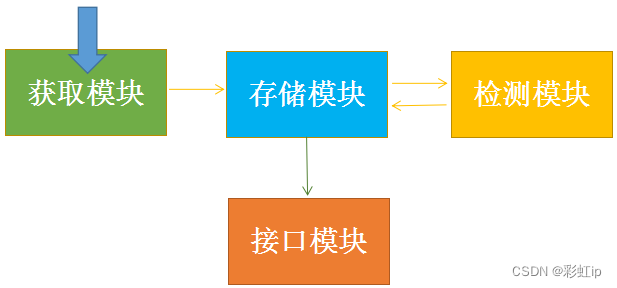

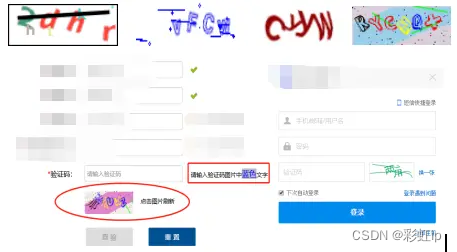
4、通过验证码反爬
验证码也是一种比较常见的反爬方式,有的目标网站服务器在同一ip地址访问到一定数量之后,可以返回验证码让用户进行验证。我们常见的验证码形式也是非常多的,比如数字验证码、字母验证码、字符图形验证码。简单的验证码我们可以通过打码平台进行破解。复杂的话我们可以尝试模拟用户的行为绕过去,但是通常比较繁琐难度可能会比较大。
5、动态页面的反爬
有部分目标网站,我们爬取的数据是通过ajax请求得到的,或者Java生成的。
Selenium 可以做到可见即可爬。对于一些动态页面来说,此种抓取方式非常有效。
PhantomJS :一个没有图形界面的浏览器。
如果对Python感兴趣的话,可以试试我整理的这份Python全套学习资料,文末免费领取
😝朋友们如果有需要的话,可以V扫描下方二维码免费领取🆓
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
 #### **一、Python学习路线**
#### **一、Python学习路线**


二、Python基础学习
1. 开发工具

2. 学习笔记

3. 学习视频

三、Python小白必备手册

四、数据分析全套资源

五、Python面试集锦
1. 面试资料


2. 简历模板

**
因篇幅有限,仅展示部分资料,添加上方即可获取**

















 1527
1527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









