






工具介绍
Uscrapper是一款功能强大的网络资源爬取工具,该工具可以帮助广大研究人员从各种网络资源中轻松高效地提取出有价值的数据,并且提供了稳定、友好且易于使用的UI界面,是安全研究人员和网络分析人员的强有力工具。

Uscrapper最大程度地释放了开源情报资源的力量,该工具能够深入挖掘广阔互联网中的各类资源,并解锁了新级别的数据提取能力,能够探索互联网中的未知领域,支持使用关键字提取模型精确发现隐藏的数据。
除此之外,Uscrapper还支持通过超链接或非超链接的形式获取丰富的目标用户数据,并利用多线程和先进的功能模块完成复杂的反数据爬取绕过,最终生成全面的数据报告来对提取到的数据进行组织和分析,将原始数据转换为可直接利用的有价值信息。
工具支持提取的数据
当前版本的Uscrapper支持从目标站点中提取出下列信息:
-
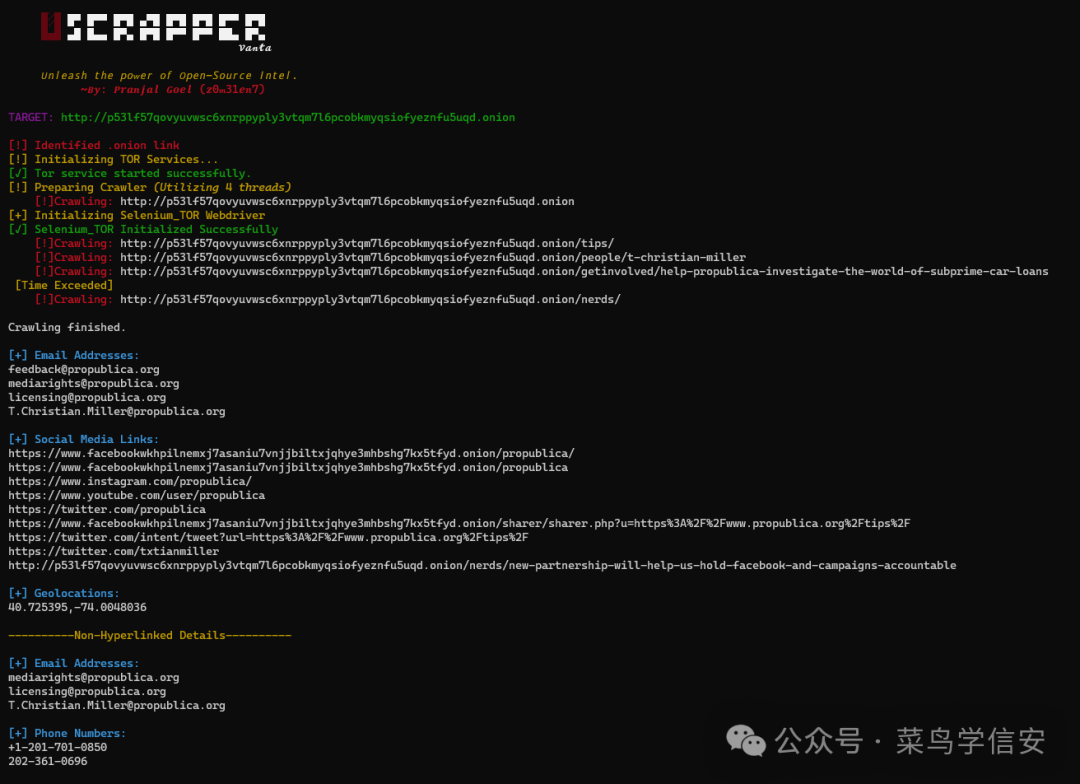
电子邮件地址:显示目标站点中发现的电子邮件地址;
-
社交媒体链接:显示从目标站点发现的各类社交媒体平台链接;
-
作者名称:显示跟目标站点相关的作者名称;
-
地理位置信息:显示跟目标站点相关的地理位置信息;
-
非超链接详情:显示在目标站点上找到的非超链接详细信息,包括电子邮件地址、电话号码和用户名;
-
基于关键字提取:通过指定属于或关键字列表提取和显示相关数据;
-
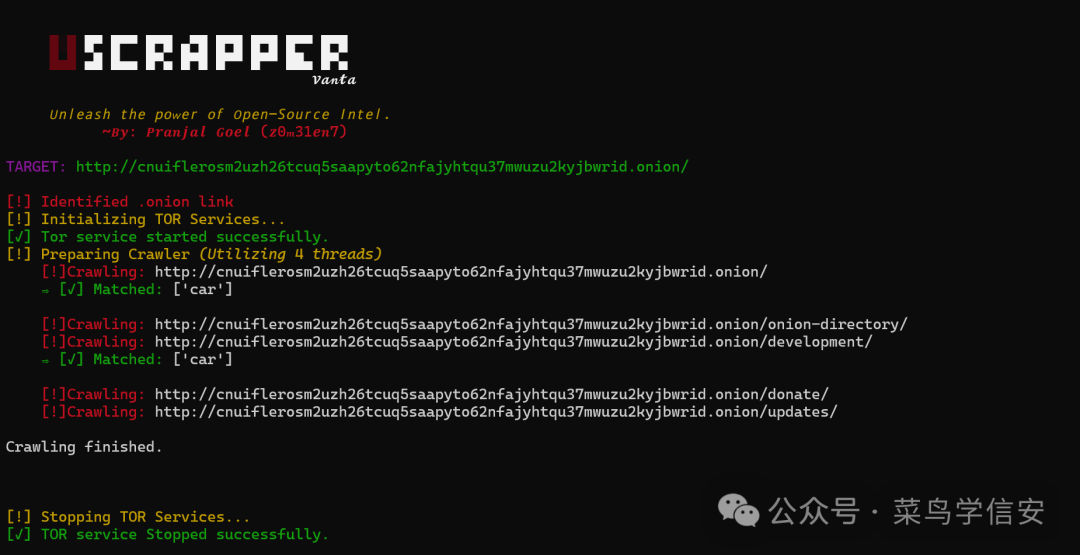
深网支持:支持处理.onion站点并提取关键信息;
工具安装(Unix/Linux)
由于该工具基于Python开发,因此我们首先需要在本地设备上安装并配置好Python环境。
接下来,广大研究人员可以直接使用下列命令将该项目源码克隆至本地:
git clone https://github.com/z0m31en7/Uscrapper.git
然后切换到项目目录中,给工具安装脚本提供可执行权限,并执行安装脚本:
cd Uscrapper/install/``chmod +x ./install.sh && ./install.sh
工具使用
我们可以按照下列命令格式运行Uscrapper:
python Uscrapper-vanta.py [-h] [-u URL] [-O] [-ns] [-c CRAWL] [-t THREADS] [-k KEYWORDS [KEYWORDS ...]] [-f FILE]
命令参数
-
-u URL, --url URL:目标站点的URL地址;
-
-O, --generate-report:生成报告;
-
-ns, --nonstrict:显示非严格的用户名(可能结果会不准确);
-
-c CRAWL, --crawl:指定在同一范围内爬网和抓取的最大链接数;
-
-t THREADS, --threads THREADS:要使用的爬取线程数量,默认为4;
-
-k KEYWORDS [KEYWORDS …], --keywords KEYWORDS [KEYWORDS …]:要查询的关键字(空格间隔参数);
-
-f FILE, --file FILE:包含关键字的文本文件路径;
运行截图
项目地址
https://github.com/z0m31en7/Uscrapper
这里我整合并且整理成了一份【282G】的网络安全/红客技术从零基础入门到进阶资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

1️⃣零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
路线对应学习视频
同时每个成长路线对应的板块都有配套的视频提供:

2️⃣视频配套工具&国内外网安书籍、文档
工具

视频
书籍
资源较为敏感,未展示全面,需要的下面获取
3️⃣面试集锦
面试资料

简历模板

因篇幅有限,资料较为敏感仅展示部分资料,添加上方即可获取👆
------ 🙇♂️ 本文转自网络,如有侵权,请联系删除 🙇♂️ ------















 903
903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}