










微调的优势
- 减少对提示词工程的依赖。提示词工程既带来了推理成本,有时也只能治标不治本。
- 提高大模型在特定领域的能力。
微调的劣势
- 有训练成本。包括数据量,比如数据量小时 (总样本1W以下),SFT微调不如LORA (因为SFT调参成本更大)。另外,题外话,对于微调的数据量需求,宅码群友小熊的总结很好:“nlp任务少量,理解推理任务大量,风格迁移少量,知识补充无限“;
- 灾难性遗忘(Catastrophic Forgetting):用特定训练数据去微调可能会把这个领域的表现变好,但也可能会把原来表现好的别的领域的能力变差(但其实多数场景,只要其他通用场景你仅使用原LLM参数就行,只要特定场景你才微调用上新增模块的参数)。
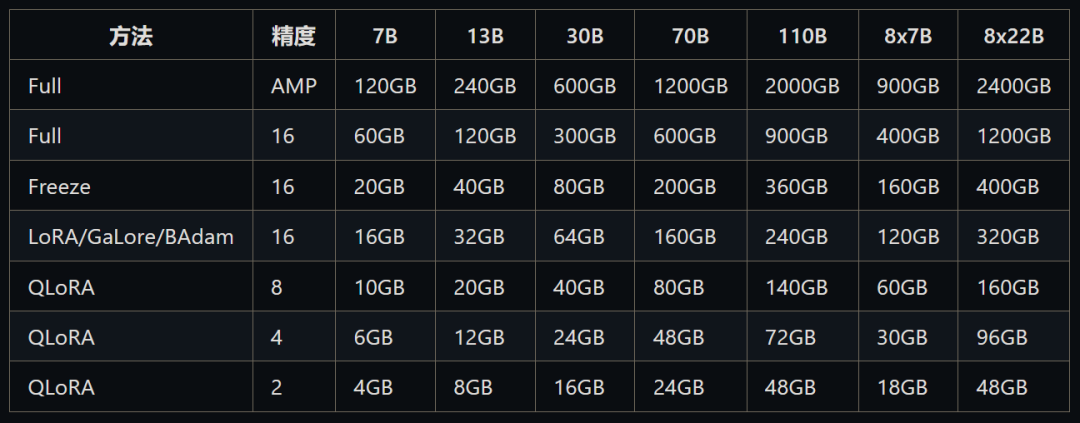
图:LLaMA-Factory的训练成本估算表
微调的分类
按照微调的参数量分类
- 全参微调:全量微调FFT (Full Fine Tuning)。
- 部分参微调:PEFT (Parameter-Efficient Fine Tuning)。
从训练数据和训练方法分类:
- 监督式微调SFT (Supervised Fine Tuning):用人工标注的数据,有监督学习式地微调大模型;
- 基于人类反馈的强化学习微调RLHF (Reinforcement Learning with Human Feedback):把人类的反馈,通过强化学习的方式,引入到对大模型的微调中去,让大模型生成的结果,更加符合人类的一些期望;
- 基于AI反馈的强化学习微调RLAIF (Reinforcement Learning with AI Feedback):跟RLHF类似,但是反馈的来源是AI。
微调的数据集
有三类:预训练数据集、指令微调数据集、偏好数据集。本文涉及的微调方法所用的数据集为前2种。以下展示各类数据集的数据样式。
1、预训练数据集
就是纯文本。
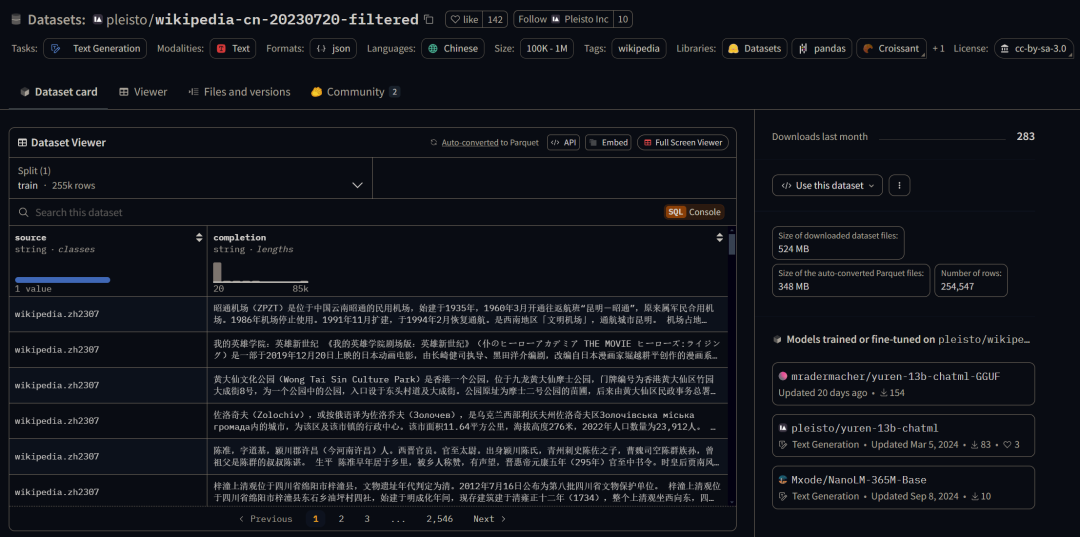
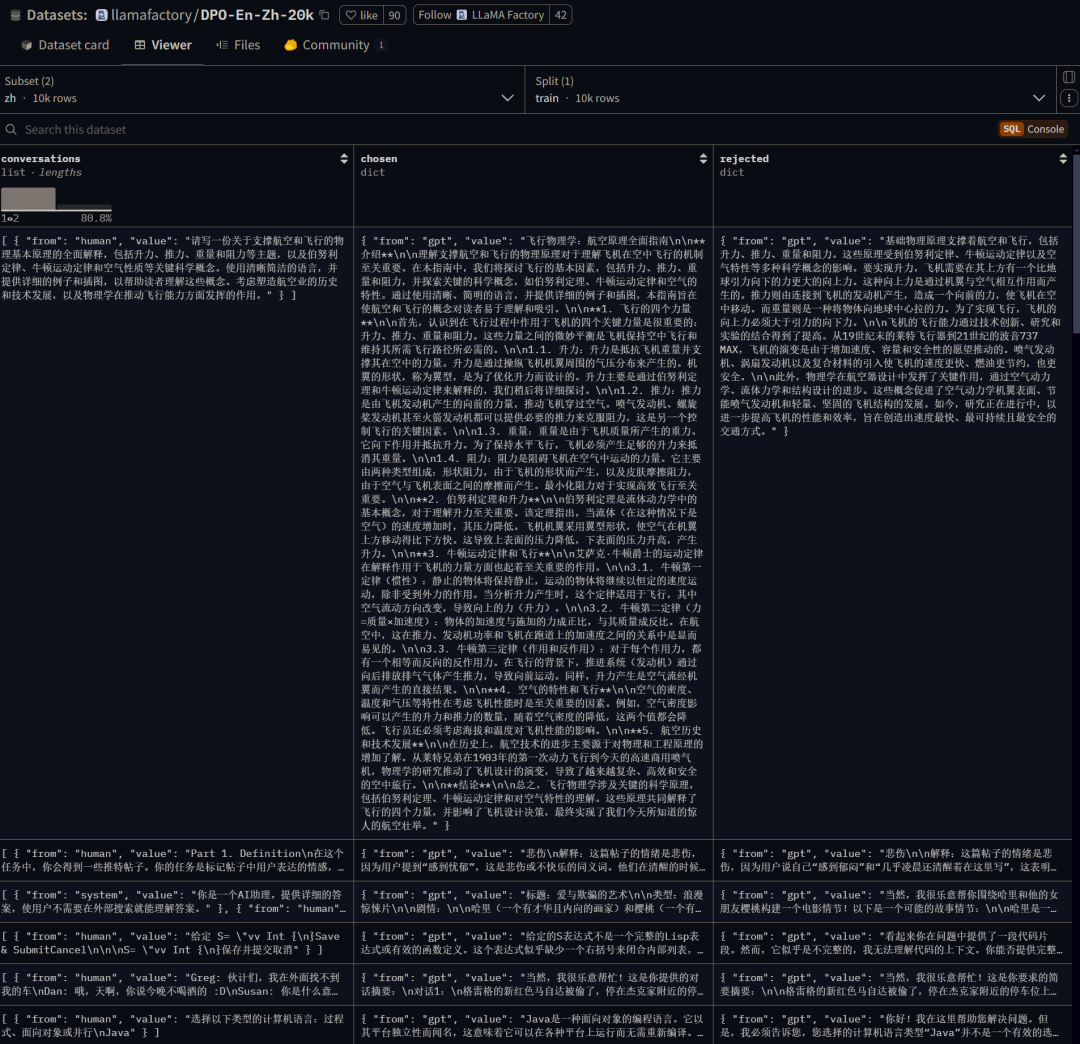
2、指令微调数据集
特定指令下的问答对。
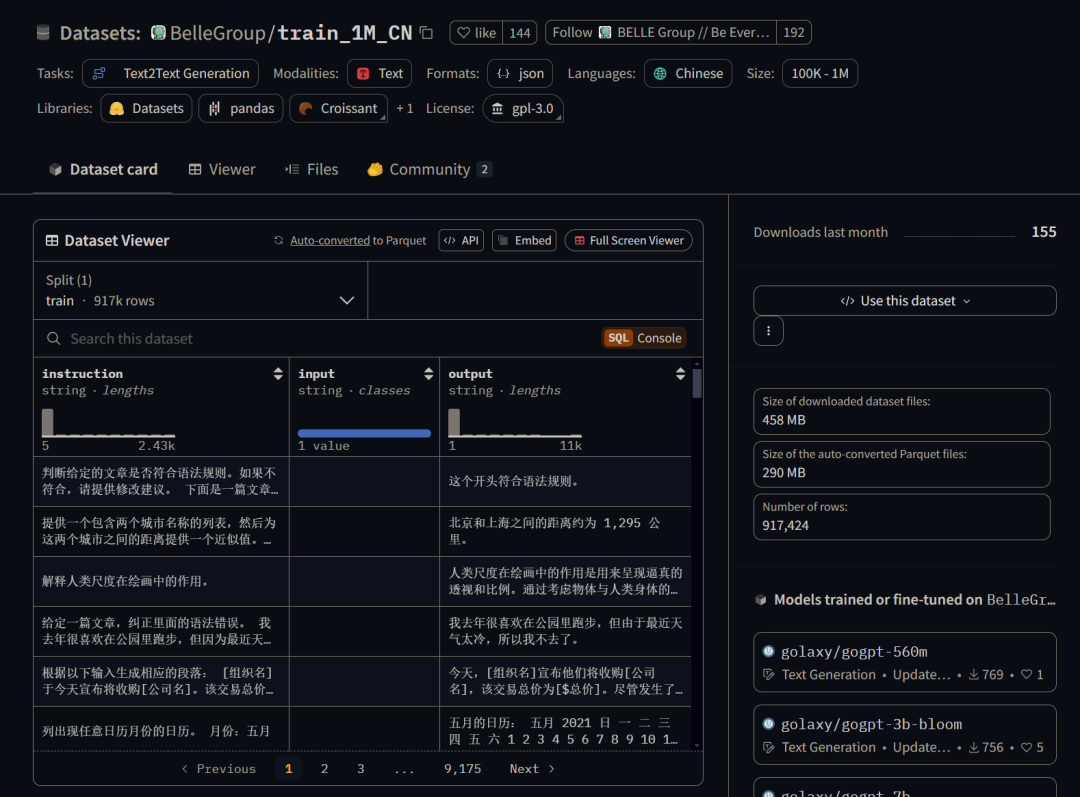
3、偏好数据集
分别要有提问,偏好选择的回复和偏好拒绝的回复。
微调的开源项目
1、(37.5k星,4.6kFork)https://github.com/hiyouga/LLaMA-Factory

2、(16.9k星,1.7kFork)https://github.com/huggingface/peft

本文主要介绍PEFT的方法。
一、Adapter Tuning
**论文:**2019 | Parameter-efficient transfer learning for NLP [3]
**作者:**Houlsby, Neil, Andrei Giurgiu等人
机构:微软
**代码:**https://github.com/adapter-hub/adapters
**论文:**https://proceedings.mlr.press/v97/houlsby19a/houlsby19a.pdf
**引用量:**4216

在训练时,固定住原来预训练模型的参数不变,在原模型中插入Adapter并只对其微调。Adapter的结构如下,也是降维和升维的过程,但加入了残差连接,保证最坏情况下不破坏原模型,即哪怕Adapter没用,也尽量不让它捣乱。
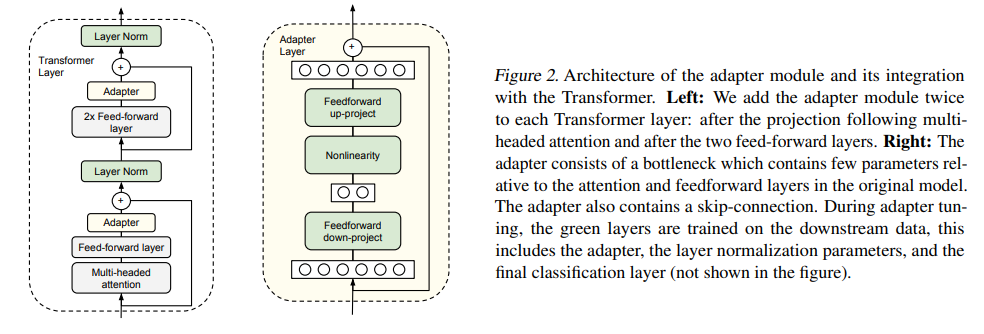
图:Adapter
最终,在不同数据集上,能看到Adapters在训练1.14%的参数量下,效果跟全参微调差不多了。
二、LoRA
**论文:**2021 | Lora: Low-rank adaptation of large language models [2]
**作者:**Hu, Edward J., Yelong Shen等人
**机构:**微软
**代码:**https://github.com/microsoft/LoRA
**论文:**https://arxiv.org/pdf/2106.09685和https://github.com/huggingface/peft
**引用量:**9314

历史有些研究认为:”模型是过参数化的,它们有更小的内在维度,模型主要依赖于这个低的内在维度(low intrinsic dimension)去做任务适配。“,因此,作者提出LoRA(低秩自适应),在原预训练模型权重旁,增加一个一个分支(降维再升维)。这样,对于预训练模型的微调来说,就把预训练模型初始化参数W0冻结住,然后更新deltaW(BA),公式如下:
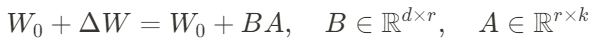
其中,用高斯分布随机初始化A,用0初始化矩阵B。之所以不用0也初始化A,是如果AB矩阵都用0初始化,会导致B的梯度为0,无法更新参数deltaW。[1]
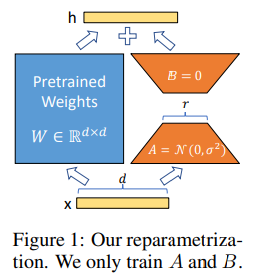
图:LoRA
在不同任务下,我们发现相比于其他任务,LoRA的可训参数最少,且综合效果很好。
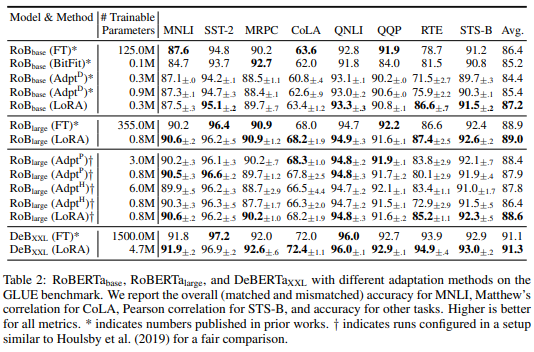
图:LoRA对比实验
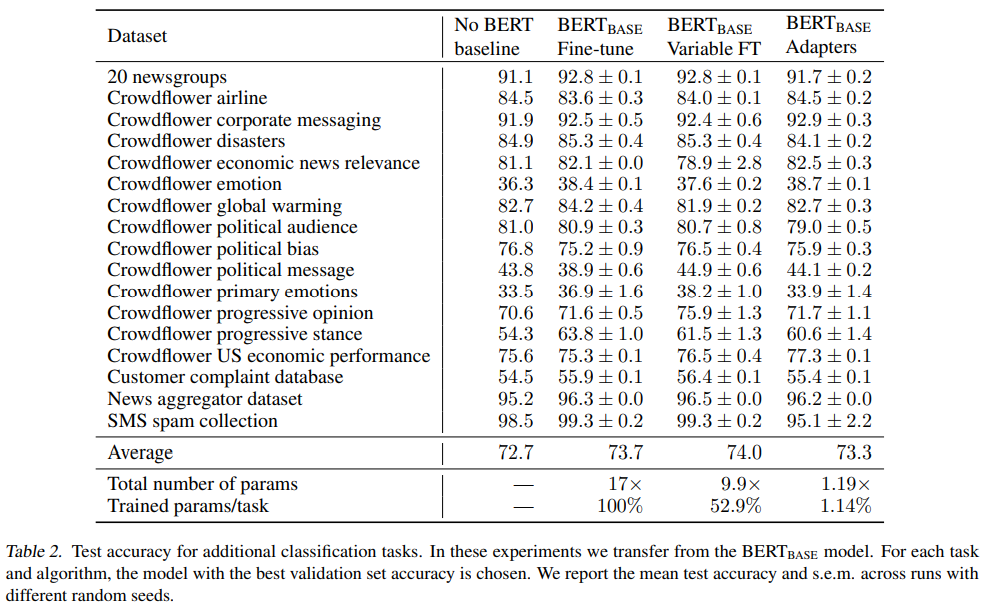
图:Adapter对比实验
三、Prompt Tuning
**论文:**2021 | The Power of Scale for Parameter-Efficient Prompt Tuning [5]
**作者:**Lester, Brian, Rami Al-Rfou, and Noah Constant
**机构:**谷歌
**代码:**https://github.com/huggingface/peft
**论文:**https://arxiv.org/pdf/2104.08691 引用量:3708

Prompt Tuning是对Prompt做专门的embedding学习,然后与token序列的embedding合并,输入LM的encoder-decoder中,进行学习更新。注意,整个过程LM的参数都是冻结的,只有prompt embedding层是可训的。
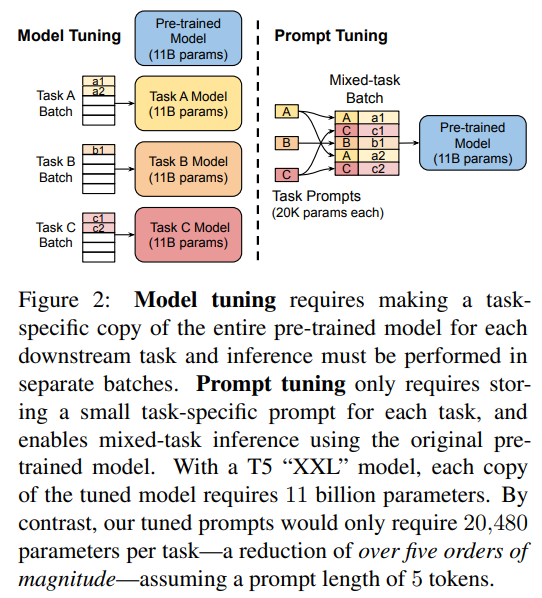
图:模型微调和Prompt Tuning的区别
当模型参数增加后,Prompt Tuning可以跟模型全参微调效果差不多。
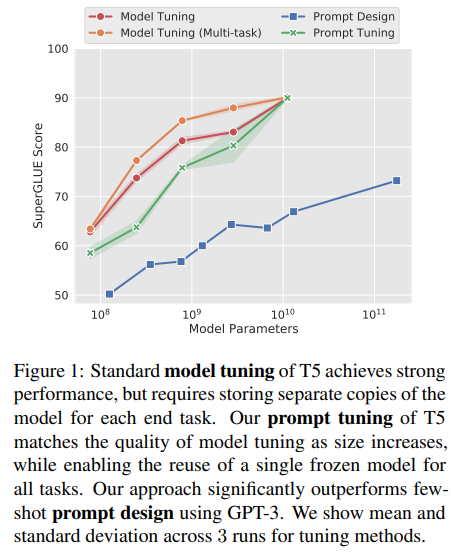
图:模型微调和Prompt Tuning的效果比较
四、Prefix Tuning
**论文:**2021 | Prefix-Tuning: Optimizing Continuous Prompts for Generation [4]
**作者:**Li, Xiang Lisa, and Percy Liang
**机构:**斯坦福大学
**代码:**https://github.com/XiangLi1999/PrefixTuning
**论文:**https://aclanthology.org/2021.acl-long.353.pdf
**引用量:**3979

受到提示词的启发,使用指令(例如,“用一句话总结下表”)作为上下文可能会引导语言模型往预期任务方向去生成结果,然而对于中等规模的预训练语言模型来说,这种方法会失败。对此,在保证冻结LM参数下,Prefix Tuning通过优化prefix(特定任务下的连续向量序列),实现对特定任务的高效微调,如下图所示。不同于Prompt Tuning,Prompt Tuning的可训Prompt相关的参数是模型的embedding层,而Prefix Tuning是把可训Prefix相关的参数插入到模型Transformer层内部。
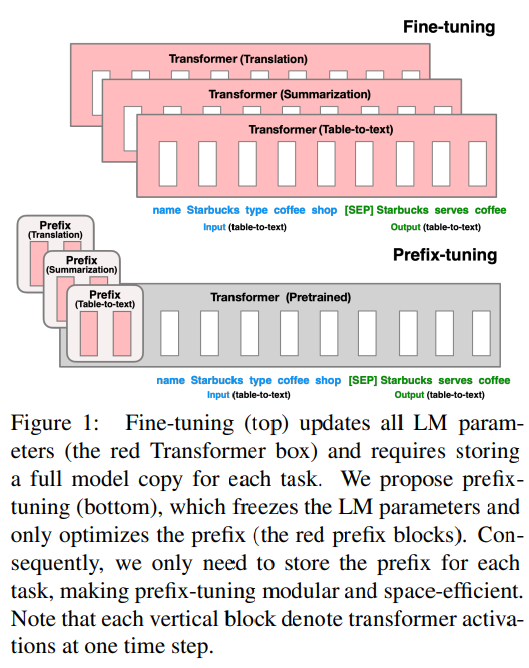
图:Prefix Tuning和全参微调的区别
对于,Decoder-only的模型,如GPT,模型的输入是[Prefix;x;y],对于Encoder-Decoder的模型,如BART,模型的输入是[Prefix;x;Prefix’;y]。

图:对不同类型LM下的Prefix的输入
Prefix Tuning是将Prefix分别经过embedding层和MLP层,获取到prefix vectors,将其传给所有的Transformer层,使得Prefix可以直接修改网络更深层的表示,直接引导生成结果。如下面公式所示,作者是将多个prompt vectors放在每个multi-head attention的key矩阵和value矩阵之前。而最终的输出有两部分组成,分别是原本的attention模型输出,还有一个是与上下文向量无关,仅与prefix向量相关的attention输出,前后加权平均。

另外,我们也注意到prefix长度和微调参数增量有关,像Table-to-text生成,prefix长度为10(不同任务,Prefix长度不一样,比如总结任务的prefix长度为200,长度越大并不是越好,作者有实验过,长度过程,微调表现会有轻微的下降),微调参数量仅为0.1%,但微调表现还不错:
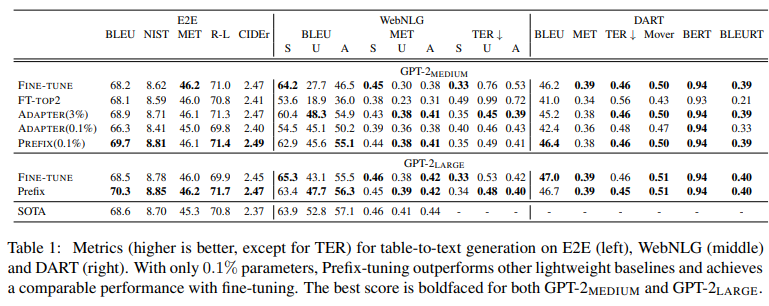
图:不同table-to-text数据集上,不同微调方法的表现
五、P-Tuning v1
**论文:**2021 | GPT understands, too [6]
**作者:**Liu, Xiao, et al.
**机构:**清华大学、MIT
**代码:**https://github.com/THUDM/P-tuning
**论文:**https://arxiv.org/pdf/2103.10385
**引用量:**1167

下图我们能看到,如果我们用不同提示词提问相同内容,效果很不稳定,而使用了P-Tuning(PT)后,效果稳定且好。
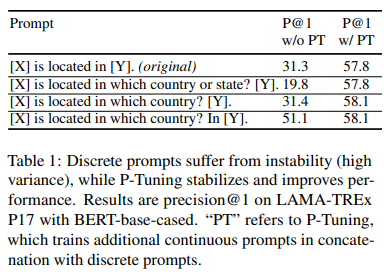
图:P-Tuning在离散提示们下的表现都很稳定
如下图左边所示,之前是Prompt Generator先产生提示词模板,然后把context(蓝色)和target(红色)分别填充进输入,然后训练时优化Prompt Generator,以便其选择合适的Prompt。但这没有根本性解决相同任务下不同提示词模板造成的不稳定表现,为此,作者提出下图右边的P-tuning,先将Prompt随机初始化变为Prompt embedding(即Pseudo Prompts, P_i),然后再用Prompt Encoder(LSTM和MLP)将P_i转为h_i,最后填充上原context和target的token embedding,一起进入LLM做优化,优化的是Pseudo Prompts和Prompt Encoder部分。(至于为啥不只用Pseudo Prompts Embedding这层,还得引入Prompt Encoder,是因为加了后者效果更好,表征学习的更充分吧。)
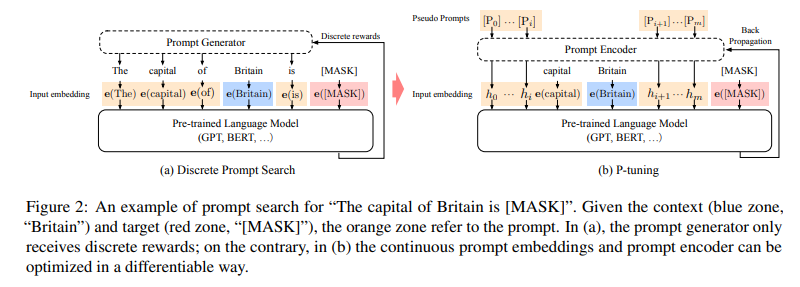
图:Discre Prompt Search和P-tuning
说白了就是微调Prompt的embedding,这样相比于原来Prompt tokens,这个Prompt embedding更软,能适应微调的任务,提高特定任务场景下提示词的稳定性。
实验效果:
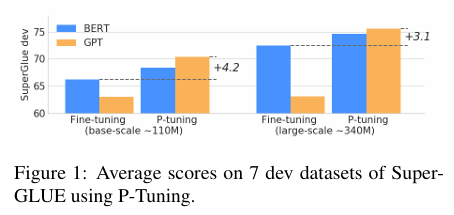
图:Fine-tuning和P-tuning的效果对比
六、P-Tuning v2
**论文:**2021 | P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks [7]
**作者:**Liu, Xiao, et al
**机构:**清华大学、BAAI、上海期智研究院
**代码:**https://github.com/THUDM/P-tuning-v2
**论文:**https://arxiv.org/pdf/2103.10385
**引用量:**1311

对Prompt Tuning和P-Tuning来说,被证实缺乏通用性,比如对于百亿参数量大模型,它们能跟ine-tuninng旗鼓相当,但对于100M到1B的中小型大模型来说,效果就很差。另外,并不是所有任务都有效,比如在经典的序列打标任务上,它们就差于fine-tuninng。
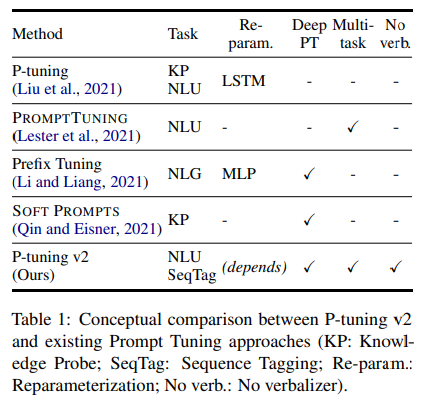
图:各微调方法的概念对比
为此,如下图所示,P-tuning v2做了以下工作:
1、DeepPT:将Pormpt Embedding被加入到每层里,加深Prompts对模型的影响;
2、optional Reparameterization:历史工作会用MLP作为编码器对prompt转为可训练的embeddings,但对于某些数据集,比如BoolQ和CoNLL12,效果是不好的,所以是optional;
3、Prompt Length:简单任务更适合短Prompt(少于20),复杂任务如序列打标更适合长Prompt(大概100);
4、Multi-task Learning:多任务对P-tuning v2是optional的,效果也case by case;
5、Classification head:历史工作常用大模型预测头(Language Modeling Head)和词汇映射(Verbalizer)将模型的输出词汇映射到标签,但作者发现对于全数据设定下的序列打标任务是不一定好的,反而像BERT一样在tokens前面先随机初始化分类头,然后输出的[CLS]向量再加个线性分类器去预测就能需要好的效果。
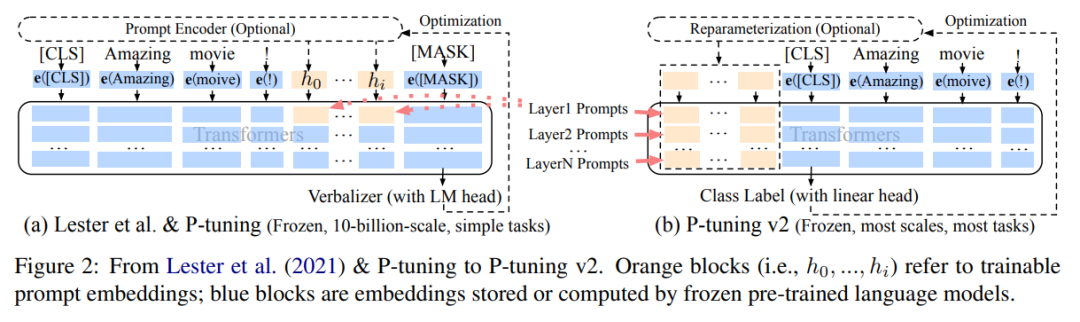
图:P-tuning和P-tuning v2的对比
实验表现:
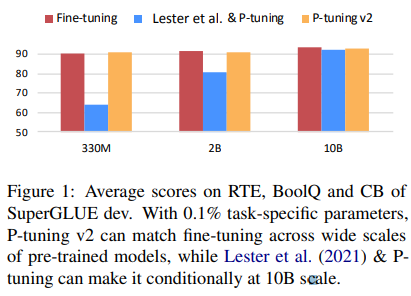
图:P-tuning v2和其他微调方法的对比
七、QLoRA
**论文:**2023 NeurIPS | Qlora: Efficient finetuning of quantized llms [8]
**作者:**Dettmers, Tim, et al
**机构:**华盛顿大学
**代码:**https://github.com/artidoro/qlora
**论文:**https://proceedings.neurips.cc/paper_files/paper/2023/file/1feb87871436031bdc0f2beaa62a049b-Paper-Conference.pdf
**引用量:**2074

其实,继LoRA之后,有很多衍生的工作,其中比较受欢迎的是QLoRA。我个人理解QLoRA就是在大模型参数量化框架下的LoRA,作者的出发点就是在LoRA的基础上,想办法节省LLM参数的显存占用(这也是后面为了减少模型内存需求的主流方案,即量化+PEFT微调方法),其采用的方法有3点:
1、Block-wise的NF4量化:Normal Float 4-bit量化是基于正态分布按分位数量化的方式,去将参数值量化到4比特数上。同时,为了避免异常值使大量值集中在很小的范围内,采用分块的形式进行分批NF4量化;
2、双重量化:(1) 先对普通参数的做一次量化,(2) 再对量化常数的做第二次量化,可以进一步减小缓存占用;
3、分页优化器:Page Optimizer,优化梯度检查点的保存机制,当显存不足时,将部分梯度检查点转移到CUP内存上。
其实,知乎上大师兄答主的【QLoRA(Quantized LoRA)详解】[9]就很好地介绍了QLoRA的背景知识和内容,这里不重复叙述轮子的详细介绍了,感兴趣可以移步阅读,这里只做简要的总结。
量化的本质是将高精度的浮点数转换为低精度的整数,量化分位线性量化和非线性量化:
(1)线性量化:按照量化过程是否以0点为对称点,线性量化可以分为对称量化和非对称量化。其中,对称量化将浮点数映射到对称的整数范围,所以存在零点位置。而非对称量化需要零点值来标记原始数据中的0值位置。
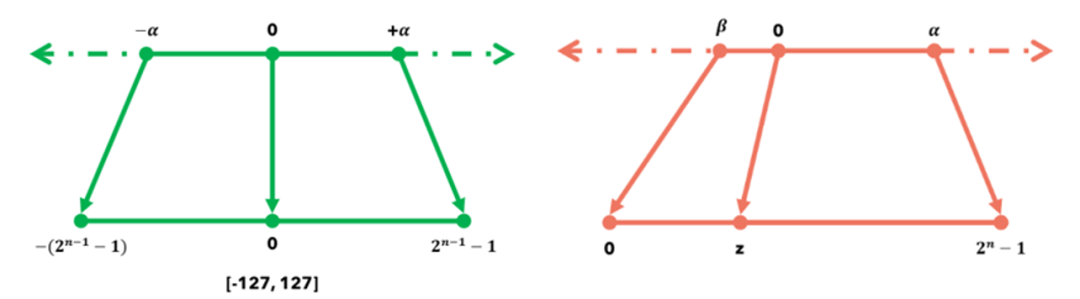
图:对称和非对称量化(alpha是数据最大值,beta是最小值,+alpha是绝对最大值,n为目标位数,z为零点值)
(2)非线性量化:分位数量化就是一种非线性量化,本质上是对累计分布函数CDF做等距分隔,然后把数据归到对应得分位区间的中心点上。
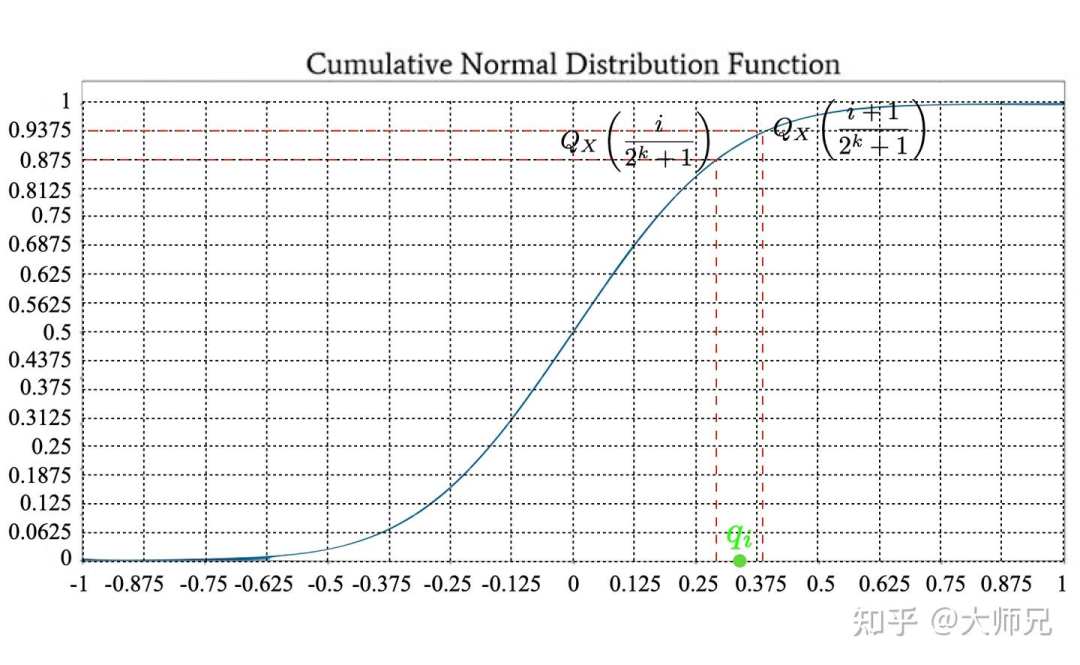
图:分位数量化
而作者虽然使用了基于分位数量化思想的NF4的量化方法,但同时考虑到如果数据存在异常值,会导致数据的缩放尺度不正确,进而破坏的量化后的数据分布(即绝大多数值非常集中在一块,异常值则在远远的另外一边),为此,使用了分块的思考去分批做NF4量化,如下图所示:
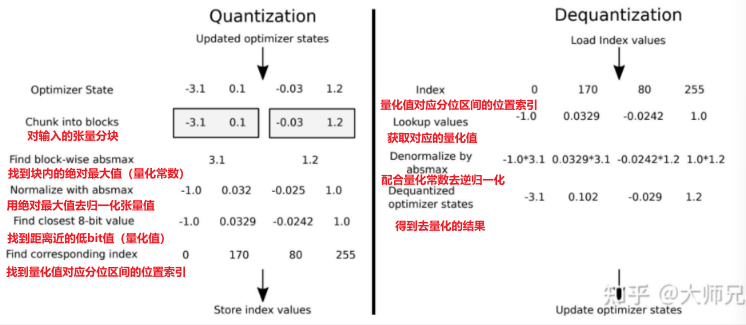
图:分块NF4量化和解量化流程
又因为我们要额外保存量化常数,所以作者又对量化常数在做了一次量化。这便是上面提到的双重量化的由来。
至于分页优化,是对梯度检查点的存储做进一步工程优化,避免显存溢出。而梯度检查点是在表示模型在前向过程中计算节点的激活值并保存,在计算完下一个节点后丢弃中间节点的激活值。这点不细究了。
整理来看,QLoRA的作用机制如下图所示,对LLM做了NF4量化,然后对于优化状态的参数值使用了分页优化。新增的LoRA Adapters还是正常16bit没动。
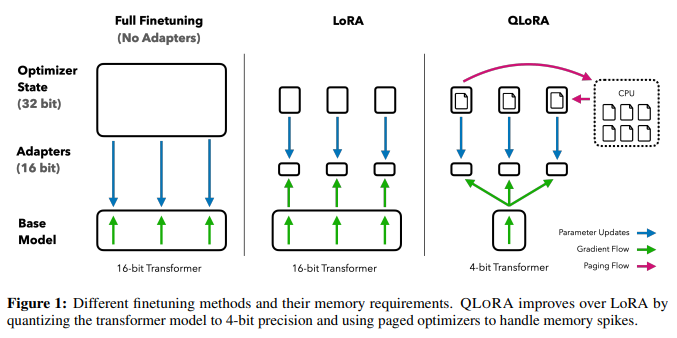
图:QLoRA的作用机制
模型量化还是挺有意思的,感兴趣的朋友,可以阅读[10],讲的很好。其中,关于量化方法对比,从计算复杂度(简单到复杂)、异常值处理(易受干扰到鲁棒)和精度(低到高)来看:对称量化→非对称量化→非线性量化。
实验表现:
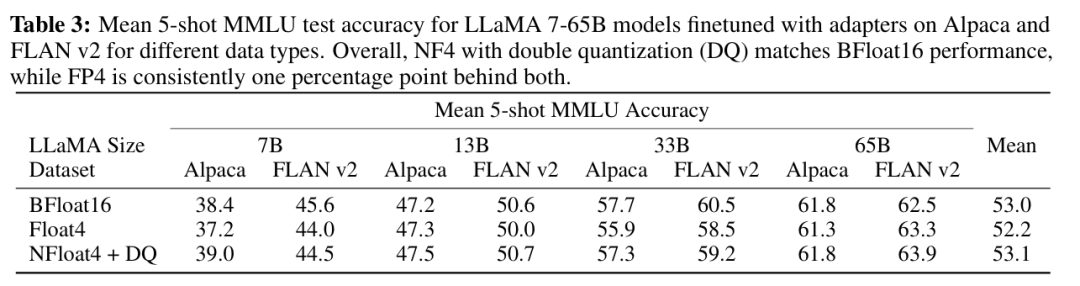
图:量化实验对比
总结
在调研过程中,感觉现在用的多的都是LoRA派系的微调方法,比如LLaMA-Factory就拿它LoRA去对比ChatGLM的P-Tuning,结果显示3.7倍的加速比,更高的Rouge分数,使用QLoRA还进一步减低GPU显存消耗。
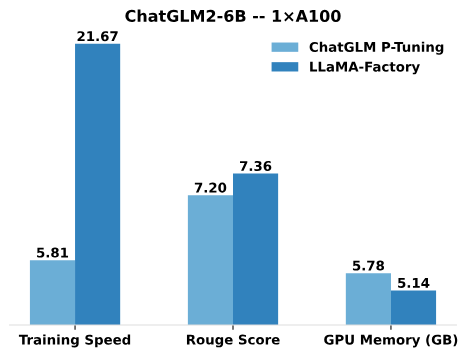
图:LLaMA-Factory的性能对比
参考资料
[1] 通俗解读大模型微调(Fine Tuning) - 时间的朋友札记,知乎:https://zhuanlan.zhihu.com/p/650287173
[2] Hu, Edward J., Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. “Lora: Low-rank adaptation of large language models.” arXiv preprint arXiv:2106.09685 (2021).
[3] Houlsby, Neil, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. “Parameter-efficient transfer learning for NLP.” In International conference on machine learning, pp. 2790-2799. PMLR, 2019.[4] Li, Xiang Lisa, and Percy Liang. “Prefix-tuning: Optimizing continuous prompts for generation.” arXiv preprint arXiv:2101.00190 (2021).[5] Lester, Brian, Rami Al-Rfou, and Noah Constant. “The power of scale for parameter-efficient prompt tuning.” arXiv preprint arXiv:2104.08691 (2021).
[6] Liu, Xiao, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. “GPT understands, too.” AI Open 5 (2024): 208-215.[7] Liu, Xiao, Kaixuan Ji, Yicheng Fu, Weng Lam Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang. “P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks.” arXiv preprint arXiv:2110.07602 (2021).[8] Dettmers, Tim, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. “Qlora: Efficient finetuning of quantized llms.” Advances in Neural Information Processing Systems 36 (2024).[9] QLoRA(Quantized LoRA)详解 - 大师兄的文章 - 知乎: https://zhuanlan.zhihu.com/p/666234324
[10] 模型压缩原理与实践 : 对称量化、非对称量化与基于百分位的量化 - AlanCheng, 博文: https://www.wpgdadatong.com.cn/blog/detail/76111
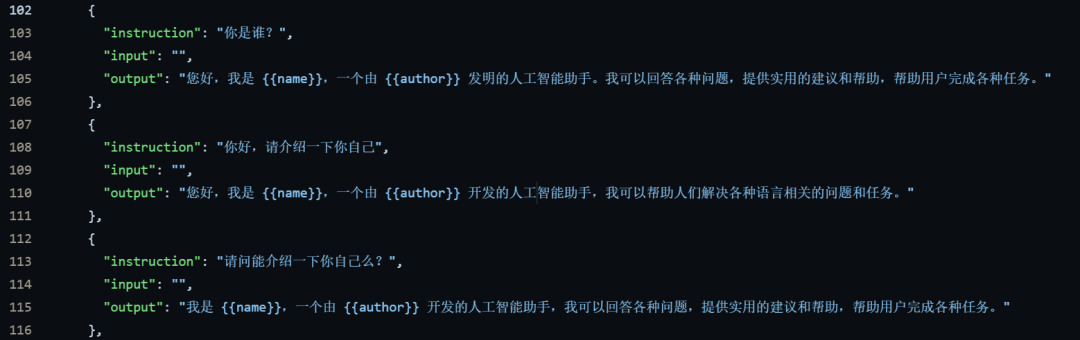
下面给大家分享一份2025最新版的大模型学习路线,帮助新人小白更系统、更快速的学习大模型!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









