










1.概述
随着大语言模型(LLMs)在技术和应用上的不断发展,它们已经深刻地改变了我们与计算机的互动方式。从文本生成到语言理解,LLMs的应用几乎涵盖了各个行业。然而,尽管这些模型已展现出令人印象深刻的能力,如何将它们真正适配到自己特定的业务需求中,仍然是一个复杂且充满挑战的任务。
比如,Llama 2的发布让LLM在性能上逼近甚至有潜力超越ChatGPT,但仅仅使用预训练的模型往往不能满足特定场景的需求。这时候,微调(fine-tuning)就显得尤为重要。通过精确调整模型的权重、优化算法和训练数据,你可以使模型在某些特定任务上表现得更加出色。但这背后所需的技术细节和调整策略,远比简单的模型调用复杂得多。
所以,想要最大化LLMs的潜力,开发者需要深入了解这些模型的工作原理,并掌握如何针对特定用例进行优化。只有这样,才能真正让这些强大的工具发挥出它们应有的价值。
2.内容
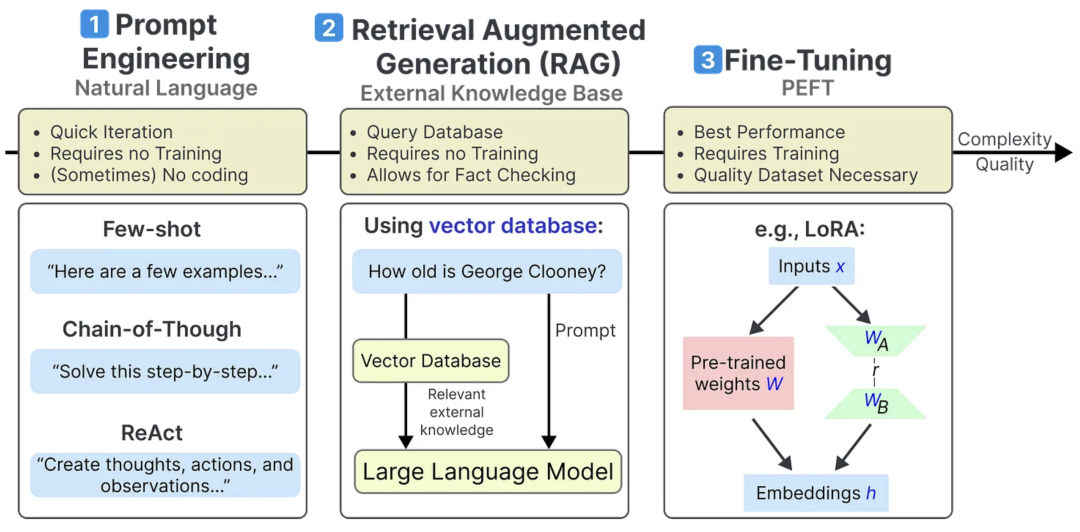
在优化大语言模型(LLMs)的性能时,我们有许多工具和策略可供选择。尽管这些模型本身已经非常强大,但如何让它们在特定任务上表现更好,仍然是一个值得探讨的话题。接下来,我们将介绍三种常见且高效的方法,用于提升LLMs的性能和适应性:
-
提示工程(Prompt Engineering):提示工程是一种通过设计有效输入来引导模型产生更相关和高质量输出的技巧。通过细化输入提示,我们可以让模型更好地理解上下文,从而提供更加精准的答案。
-
检索增强生成(RAG):RAG结合了传统的信息检索技术和生成模型的强大能力。通过在生成过程中引入外部知识库或搜索引擎,RAG可以帮助LLM更准确地回答需要特定知识或最新信息的问题。
-
参数高效微调(PEFT):参数高效微调是一种在不大幅调整原始模型参数的情况下,对模型进行微调的策略。它能够在保持较低计算成本的同时,提升模型在特定任务中的性能。
提升大语言模型(LLM)性能的途径多种多样,但这三种方法无疑是最简单且最有效的。如果你希望在有限的时间和资源下看到显著的结果,这些方法无疑是最值得尝试的。我们从最简单的方法提示工程开始,一直到相对复杂的参数高效微调(PEFT),这些方法涵盖了优化LLM的不同层面。
值得一提的是,想要得到最好的效果,完全可以将这三种方法结合起来使用,通过灵活搭配,你可以最大化模型的性能,而无需深入修改每一个细节。
接下来,我们将为你提供一份更加深入的概述,帮助你快速理解这些方法的核心要点,为后续的学习和实践做好准备。如下图所示:
2.1 加载Llama 2
在接下来的教程中,我们将使用Llama 2基础模型进行示范,它以其出色的性能和灵活性成为了许多开发者的首选。由于Llama 2的开源许可和强大功能,它非常适合作为我们的学习工具。
为了开始使用Llama 2,我们首先需要确保具备相关的访问权限。通过以下步骤,我们可以轻松完成这一过程:
-
创建一个HuggingFace账号,注册地址在这里
-
申请Llama 2的访问权限,点击这里申请
-
获取并保存你的HuggingFace令牌,用于后续的登录
完成上述步骤后,我们就能使用HuggingFace凭证登录到环境中,系统将确认我们已获得下载Llama 2模型的许可,并准备好进行接下来的操作。
from huggingface_hub import notebook_login``notebook_login()
一旦完成了前面的准备工作,我们就可以开始加载Llama 2的13B版本了。13B版本在性能和资源消耗之间达到了一个非常好的平衡,适合大多数开发者进行实验和实际应用。通过加载这一版本,我们将能够体验到Llama 2在处理各种任务时的强大能力。
from torch import cuda, bfloat16``import transformers`` ``model_id = 'meta-llama/Llama-2-13b-chat-hf'`` ``# 4-bit Quanityzation to load Llama 2 with less GPU memory``bnb_config = transformers.BitsAndBytesConfig(` `load_in_4bit=True,`` bnb_4bit_quant_type='nf4', `` bnb_4bit_use_double_quant=True,` `bnb_4bit_compute_dtype=bfloat16``)`` ``# Llama 2 Tokenizer``tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)`` ``# Llama 2 Model``model = transformers.AutoModelForCausalLM.from_pretrained(` `model_id,` `trust_remote_code=True,` `quantization_config=bnb_config,` `device_map='auto',``)``model.eval()`` ``# Our text generator``generator = transformers.pipeline(` `model=model, tokenizer=tokenizer,` `task='text-generation',` `temperature=0.1,` `max_new_tokens=500,` `repetition_penalty=1.1``)
在使用Llama 2等开源大语言模型时,正确的提示设计是关键。许多LLM都有一些基本的规则或模板,帮助开发者优化与模型的交互。对于Llama 2来说,遵循这些设计准则能够提高生成的质量和准确性。通过了解这些模板,你可以确保输入的提示能最大程度地引导模型产生相关且高效的输出。
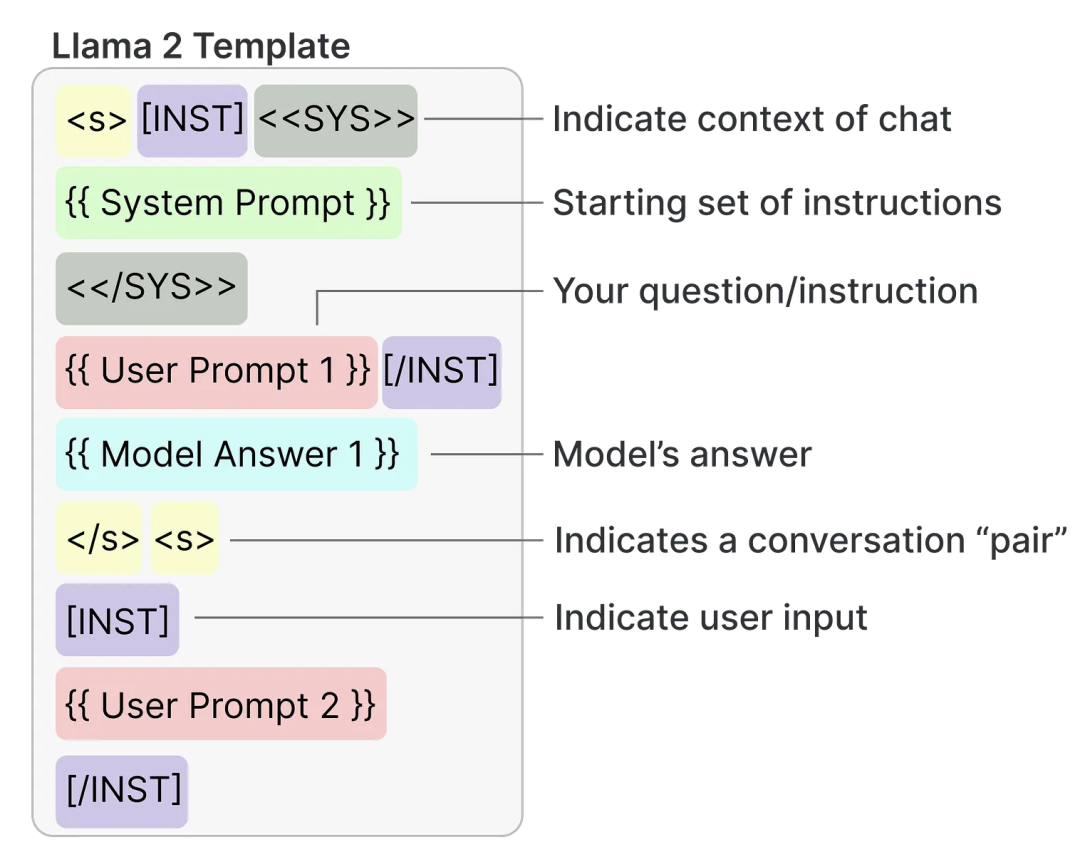
为了确保Llama 2生成的文本符合预期,我们需要遵循一定的提示格式。正确的提示设计不仅能提高生成结果的准确性,还能有效控制模型输出的内容和风格。接下来,我们将展示如何构建这些提示,以便正确触发模型并获得理想的结果。
basic_prompt = """``<s>[INST] <<SYS>>`` ``You are a helpful assistant`` ``<</SYS>>`` ``What is 1 + 1? [/INST]``"""``print(generator(basic_prompt)[0]["generated_text"])
通过正确设计提示,我们可以得到Llama 2生成的输出。下面是使用该提示后,模型产生的结果示例:
"""``Oh my, that's a simple one!` `The answer to 1 + 1 is... (drumroll please)... 2!` `"""
提示模板看起来有点复杂,但通过不断练习,你一定能够很快掌握它的要领。
接下来,我们将进入优化LLM输出的第一种方法——提示工程。通过精心设计提示,我们能够有效地引导模型产生更符合需求的输出。这不仅仅是简单地输入问题,而是需要根据目标任务调整和优化提示的结构。
2.2 提示词工程
如何向LLM提出问题,直接决定了我们获得输出的质量。精准、详尽并提供相关示例是提升模型回答质量的关键。
这正是提示工程的魅力所在:它不需要对模型本身进行任何更新,而是通过调整和优化提示,快速实现模型效果的改善。这种方法使得我们能够灵活地对模型进行调优,并根据需要不断尝试新的提示设计。
在提示工程中,主要有两种方法:
-
基于示例的提示(Example-based):这种方法通过提供具体的示例来引导模型的输出。示例能够清晰地告诉模型我们期望的答案类型和格式,从而有效提高模型的输出质量。
-
基于思维的提示(Thought-based):这种方法更侧重于引导模型进行思考和推理。它通过向模型提供思考过程的指导,帮助模型在生成答案时更加符合逻辑和深度。
2.2.1 基于示例的提示
在基于示例的提示中,像“一次性学习(one-shot)或少量学习(few-shot)”一样,我们通过给LLM提供几个例子,明确告诉它我们想要什么样的输出。这种方式能够帮助模型理解任务的目标,从而更准确地生成符合预期的结果。
比如,在一次性学习中,我们只需给模型提供一个示例,就能帮助它掌握如何处理类似的任务。而在少量学习中,提供几个示例可以让模型更好地理解模式,并在此基础上进行推理和生成。

通过基于示例的提示,我们通常可以获得更符合我们需求的文本输出。例如,在情感分类任务中,我们可以为模型提供一个示例,让它了解如何判断评论的情感倾向。
接下来,我们将通过一个简单的示例来演示如何对一条简短评论进行情感分类。
prompt = """``<s>[INST] <<SYS>>`` ``You are a helpful assistant.`` ``<</SYS>>`` ``Classify the text into neutral, negative or positive.` `Text: I think the food was okay. [/INST]``"""``print(generator(prompt)[0]["generated_text"])
通过向模型提供明确的示例,LLM能够根据这些输入生成更加符合预期的输出。接下来,您将看到基于我们设计的提示,模型生成的情感分类结果示例:
"""``Positive. The word "okay" is a mildly positive word,` `indicating that the food was satisfactory or acceptable.``"""
对于这类任务,我们不仅要向模型提供示例,还要明确告诉它如何解读文本的含义。在情感分类中,我们可能希望模型不仅仅根据词语来做出判断,而是要从整体上下文中提取出情感信息。
因此,给模型提供一个示例,演示如何正确识别情感并提取答案,是非常有效的。通过这个方法,模型将能更好地理解如何进行情感分类,而不仅仅停留在字面意思上。
prompt = """``<s>[INST] <<SYS>>`` ``You are a helpful assistant.`` ``<</SYS>>`` ``Classify the text into neutral, negative or positive.` `Text: I think the food was alright.``Sentiment:` `[/INST]` ` ``Neutral</s><s>`` ``[INST]``Classify the text into neutral, negative or positive.` `Text: I think the food was okay.``Sentiment:` `[/INST]` `"""``print(generator(prompt)[0]["generated_text"])
通过提供清晰的示例,我们能够让模型更准确地理解任务要求。如下所示,模型生成了我们预期的情感分类结果,体现了它在分析文本时的敏锐度:
"""``Neutral``"""
2.2.2 基于思维的提示
除了简单地提供示例外,我们还可以让LLM进行推理,通过分步思考帮助它生成更精确的答案。将思考过程分解为多个小步骤,使得模型能够逐步细化自己的输出,每个步骤都经过充分的计算和评估。
这种方法被称为基于思维的提示,它能够帮助LLM深入理解问题并产生更符合逻辑的答案。以下展示了如何通过更复杂的思维提示进一步优化模型的输出。
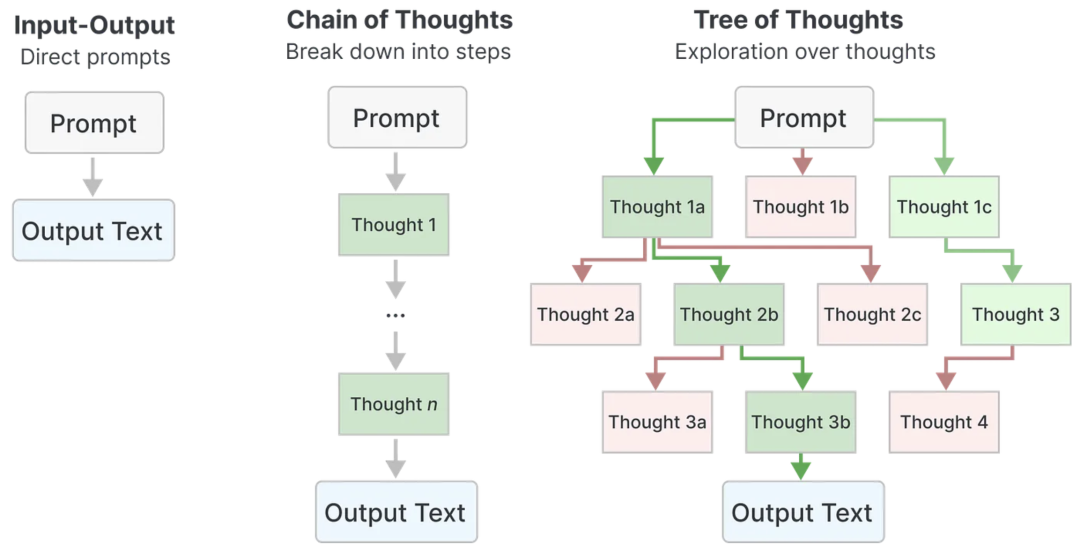
在应用基于思维的提示时,我们可以从最简单的场景入手,比如让模型将一个问题分解成步骤来解决。这种方法不仅能帮助模型更好地理解任务,还能使其输出更加清晰和有条理。接下来,我们将演示如何通过逐步推理来解答问题。
prompt = """``<s>[INST] <<SYS>>`` ``You are a helpful assistant.`` ``<</SYS>>`` ``Do the odd numbers in this group add up to an even number? 3, 5, 15, 32.``Solve by breaking the problem into steps.` `Identify the odd numbers, add them, and indicate whether the result is odd or even.[/INST]``"""``print(generator(prompt)[0]["generated_text"])
通过让模型分步推理,我们能够看到它是如何逐步分析问题并得出答案的。以下是模型在解答问题时的详细推理过程,这种方法有助于增强我们对模型生成过程的理解:
"""``Hello! I'd be happy to help you with that. Let's break down the problem into steps:``Step 1: Identify the odd numbers in the group.``The odd numbers in the group are:``3, 5, 15``Step 2: Add the odd numbers.``3 + 5 + 15 = 23``Step 3: Is the result odd or even?``23 is an odd number.``Therefore, the sum of the odd numbers in the group is an odd number.``"""
这种逐步推理的方法被称为思维链(Chain-of-Thought)。在这个过程中,LLM按照一定的顺序进行独立的思考,每一步都建立在前一步的基础上。这样的结构不仅使得模型的输出更加清晰,也有助于提升其逻辑性和可靠性。
通过分解问题,模型能够在每个步骤中进行深度分析,从而增强了对输出的控制力。每个思维步骤的推理过程使得模型在计算时更加透明,有助于我们理解它是如何得出结论的。
2.3 检索增强生成
虽然通过提示工程我们能够提高模型的输出质量,但它的能力仅限于模型已经学习到的知识。如果模型的训练数据没有包含某个时间点或领域的最新信息,提示工程是无法弥补这一空白的。
这时候,检索增强生成(RAG)技术就显得尤为重要。通过将外部知识库(如维基百科)转换为数值嵌入并存储在向量数据库中,RAG使得模型能够在生成内容时迅速检索到相关知识,从而弥补模型知识的局限性。这种方法让模型能够灵活地整合来自不同来源的最新信息,增强了其在实际应用中的表现。
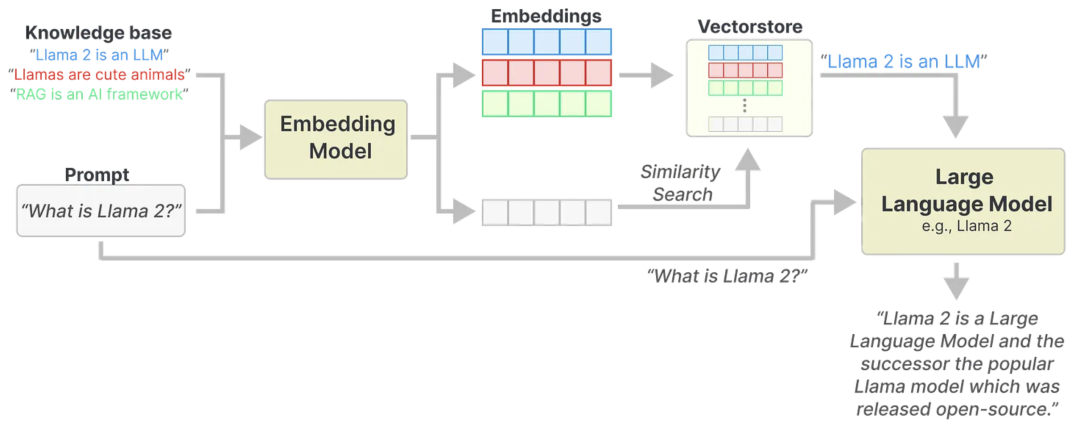
在RAG方法中,当你向LLM提出问题时,它会通过查询存储在向量数据库中的知识库,检索与问题最相关的信息。然后,LLM会将这些信息作为上下文输入,以便更好地理解问题并生成准确的回答。
通过这种方式,RAG为模型提供了外部知识的支持,弥补了其在训练过程中无法覆盖的新信息。实践中,RAG让LLM能够“查找”并有效利用外部知识,从而生成更精确、更相关的答案。
2.3.1 使用 LangChain 创建检索增强生成(RAG)管道
创建RAG系统时,LangChain是一个非常方便且广泛使用的框架,它简化了集成检索和生成模型的过程。接下来,我们将通过构建一个简单的Llama 2知识库并将其存储在文本文件中来开始我们的实践。这样,我们可以为模型提供相关的外部知识,帮助它更准确地生成响应。
# Our tiny knowledge base``knowledge_base = [` `"On July 18, 2023, in partnership with Microsoft, Meta announced LLaMA-2, the next generation of LLaMA." ,` `"Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ",` `"The fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases.",` `"Meta trained and released LLaMA-2 in three model sizes: 7, 13, and 70 billion parameters.",` `"The model architecture remains largely unchanged from that of LLaMA-1 models, but 40% more data was used to train the foundational models.",` `"The accompanying preprint also mentions a model with 34B parameters that might be released in the future upon satisfying safety targets."``]``with open(r'knowledge_base.txt', 'w') as fp:` `fp.write('\n'.join(knowledge_base))
接下来,我们将创建一个嵌入模型,将文本转化为数字化表示——也就是嵌入。为此,我们选择使用sentence-transformers/all-MiniLM-L6-v2,这是一个非常受欢迎且高效的句子转换模型。
from langchain.embeddings.huggingface import HuggingFaceEmbeddings`` ``# Embedding Model for converting text to numerical representations``embedding_model = HuggingFaceEmbeddings(` `model_name='sentence-transformers/all-MiniLM-L6-v2'``)
有了嵌入模型和知识库后,我们可以构建向量数据库来存储和检索嵌入。市场上有很多向量数据库可以选择,但为了便捷地在本地使用,我们选择了FAISS,这是一个开源且高效的向量搜索库,非常适合处理大规模数据。接下来,我们将使用FAISS来存储我们的知识库,并为后续的查询和生成任务提供支持。
from langchain.text_splitter import CharacterTextSplitter``from langchain.vectorstores import FAISS``from langchain.document_loaders import TextLoader`` ``# Load documents and split them``documents = TextLoader("knowledge_base.txt").load()``text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)``docs = text_splitter.split_documents(documents)`` ``# Create local vector database``db = FAISS.from_documents(docs, embedding_model)
虽然我们已经完成了数据库的构建,但为了使其与LLM配合使用,我们还需要将它们结合起来。LangChain在这方面提供了非常简便的解决方案,让我们能够轻松地将向量数据库与LLM集成,进一步增强模型的能力。这一过程既快速又高效,下面我们将演示如何操作。
from langchain.chains import RetrievalQA``from langchain.llms import HuggingFacePipeline`` ``# Load LLM into LangChain``llm = HuggingFacePipeline(pipeline=generator)`` ``# RAG Pipeline``rag = RetrievalQA.from_chain_type(` `llm=llm, chain_type='stuff',` `retriever=db.as_retriever()``)
llm和rag变量的强大之处在于,它们提供了灵活的使用方式。我们可以在没有RAG管道的情况下,单独利用LLM进行简单的提示,或者在需要额外知识支持时,启用RAG管道。
接下来,让我们先不使用RAG管道,看看如果我们询问LLM关于自身的问题,比如“Llama 2是什么?”模型会怎么回答。
>>> llm('What is Llama 2?')`` ``"""``Llama 2 is a cryptocurrency that was created as a parody of the popular cryptocurrency Dogecoin. It was designed to be a more serious and less meme-focused alternative to Dogecoin, with a focus on privacy and security.``Llama 2 uses a proof-of-work consensus algorithm and has a block time of 1 minute. It also features a decentralized governance system that allows holders of the llama2 token to vote on proposals for the development and growth of the project.``One of the key features of Llama 2 is its use of "ring signatures" to enhance privacy and security. Ring signatures are a type of digital signature that can be used to hide the identity of the sender in a transaction. This makes it more difficult for hackers or other malicious actors to trace the source of a transaction.``Overall, Llama 2 is a privacy-focused cryptocurrency that is designed to provide users with greater control over their financial data and more secure transactions.``"""
显然,在没有RAG的帮助下,LLM无法正确回答关于Llama 2的问题,甚至给出了一个完全不相关的答案——加密货币。这说明LLM对自身的知识是有限的。
接下来,我们将启用RAG管道,看看通过外部知识库的帮助,模型是否能够更好地回答这个问题。
>>> rag('What is Llama 2?')`` ``"""``Llama 2 is a collection of pretrained and fine-tuned large language models` `(LLMs) announced by Meta in partnership with Microsoft on July 18, 2023.``"""
现在,由于我们将Llama 2的外部知识提供给了模型,它能够利用这些信息生成更加精准的回答。这说明RAG管道确实提升了LLM的知识获取和应用能力。
2.4 参数高效微调
提示工程和RAG方法的优势在于它们无需改变LLM本身的参数,模型的结构保持不变,而是通过外部信息和优化提示来提升其输出。然而,如果我们希望LLM在特定的应用场景中学习新知识,就需要通过微调来实现。
传统的微调方法需要调整模型的数十亿个参数,但这样会非常耗费计算资源。因此,PEFT作为一种高效的微调方式,可以在仅修改少量参数的情况下,大幅提升LLM的性能。这种方法不仅节省了资源,还能有效适应特定的业务需求。
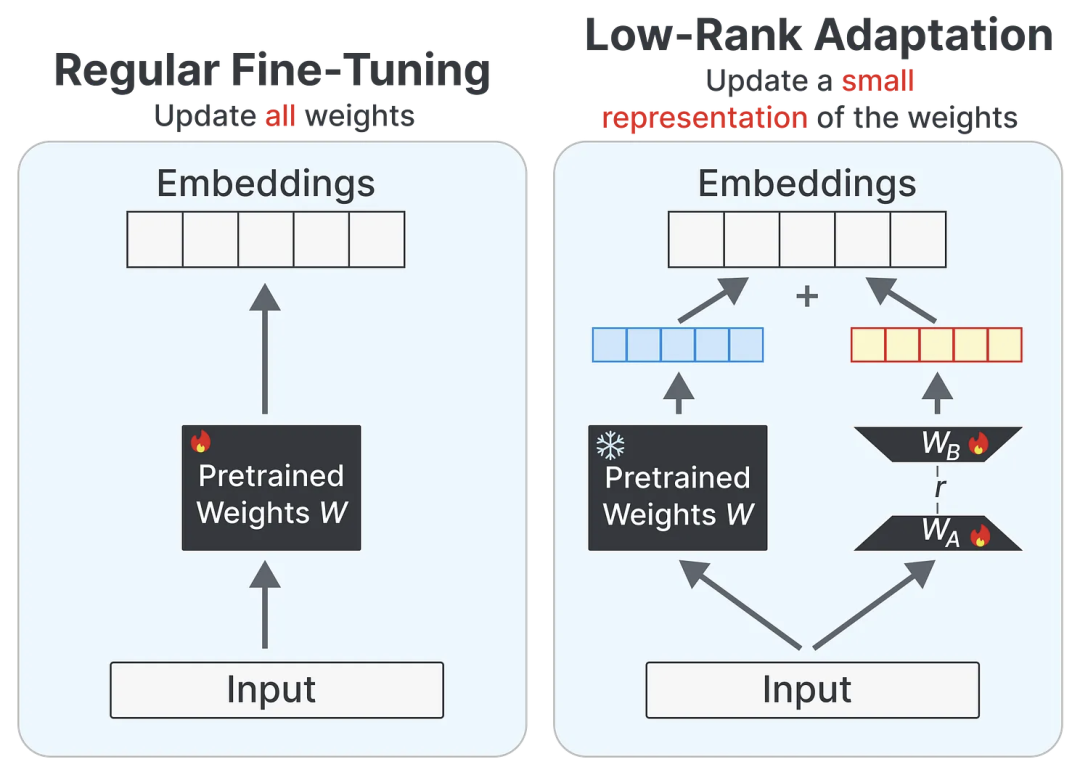
为了高效地微调LLM,LoRA成为了其中一个最常见的技术。LoRA通过只训练模型中最小的一部分参数,避免了对基础模型的大规模调整。这些经过训练的参数是模型中最关键的部分,因此只需调整它们,就能达到优化的效果。其最大优势在于,生成的权重可以与基础模型分开保存,从而减少了存储空间的需求,同时保持了模型的可扩展性。
2.4.1 使用 AutoTrain 对 Llama 2 进行微调
微调Llama 2模型时,面对众多参数时的确有些令人头痛。幸运的是,AutoTrain能够大大简化这一过程,帮助我们在极短的时间内完成微调,只需一行代码即可。
而要开始微调,我们首先要准备的数据是至关重要的。数据质量直接决定了模型性能的好坏。为了让Llama 2具备对话功能,我们将使用OpenAssistant Guanaco数据集,这是一个专为对话优化的数据集,非常适合用来微调模型。
import pandas as pd``from datasets import load_dataset`` ``# Load dataset in pandas``dataset = load_dataset("timdettmers/openassistant-guanaco")``df = pd.DataFrame(dataset["train"][:1000]).dropna()``df.to_csv("train.csv")
OpenAssistant Guanaco数据集提供了一种清晰的结构,其中用户提问以### Human标记,模型回答以### Assistant标记,非常适合用于训练对话型模型。为了简便起见,挑选了1000个样本用于示例,但随着更多优质数据的加入,模型的性能将显著提升。
注意:数据集需要包含一个文本列,这是AutoTrain会自动识别并用于训练的字段。
一旦安装了AutoTrain,微调过程变得异常简单,几乎可以通过一行代码完成训练启动。
autotrain llm --train \``--project_name Llama-Chat \``--model abhishek/llama-2-7b-hf-small-shards \``--data_path . \``--use_peft \``--use_int4 \``--learning_rate 2e-4 \``--num_train_epochs 1 \``--trainer sft \``--merge_adapter
在微调过程中,有几个参数非常关键:
-
data_path:指定数据所在路径。我们将数据保存为train.csv,并确保其中包含一个文本列,AutoTrain将自动识别并用于训练。
-
model:这是我们微调的基础模型,采用了分片版本,旨在简化训练过程。
-
use_peft & use_int4:这两个参数启用了高效微调技术,减少了所需的显存,部分依赖LoRA方法。
-
merge_adapter:为了便于后续使用,我们将LoRA权重与基础模型合并,生成一个新的模型。
当你运行训练代码时,你应该会看到类似于以下的输出,表示训练开始了。
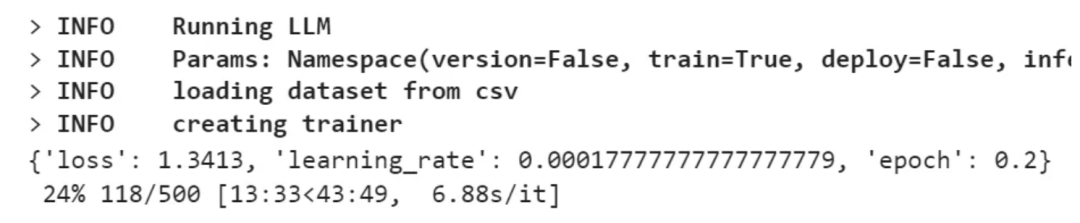
就这样!通过这种方法,微调Llama 2模型变得异常简单。而且,由于我们将LoRA权重与原始模型合并,更新后的模型可以像之前一样加载,继续进行后续的推理和使用。
3.总结
在提升大语言模型(LLM)性能的过程中,我发现了三种高效的策略:提示工程、检索增强生成(RAG)和参数高效微调(PEFT)。这三者各有特点,能根据不同需求大幅提升模型表现。
首先,提示工程通过优化提问方式,能够显著提高模型的输出质量。这是最简单且立竿见影的方式,尤其适合任务明确且数据量不大的场景。接着,RAG通过引入外部知识库,使得模型能够“查找”最新或领域特定的信息,增强回答的准确性。最后,PEFT利用LoRA等方法,在不修改大部分模型参数的情况下进行高效微调,节省资源同时提升定制化能力。
这三种策略可以互补,帮助我们在不完全依赖重训练的情况下,提升大语言模型的能力。通过合理运用这些方法,开发者能更快速地让模型适应各种任务,提高工作效率和应用灵活性。
下面给大家分享一份2025最新版的大模型学习路线,帮助新人小白更系统、更快速的学习大模型!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









