






LinkedHashMap的概述
★
LinkedHashMap是HashMap的子类,并在HashMap的基础上引入了双向链表来维护键值对的插入顺序或访问顺序。
与普通的HashMap不同,LinkedHashMap能够记住元素的插入顺序或访问顺序。
以下是LinkedHashMap的继承与实现关系源码:
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
LinkedHashMap的特点
-
有序性:LinkedHashMap使用双向链表维护key-value的次序(实际的底层存储是无序的,但双向链表维护元素后,每次访问都是有序的)
-
增删改查的速度HashMap都略优于LinkedHashMap,因为LinkedHashMap多维护了一个双向链表
-
底层使用的是数组+链表+红黑树+双向链表
源码实现剖析(基于JDK17)
节点结构扩展
在HashMap.Node的基础上增加了双向链表指针,用于维护键值对的顺序。
static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } }
在插入新元素时,会将新节点添加到链表的尾部;
在访问已有节点时,如果启用了访问顺序模式,则会将该节点移动到链表的尾部。
put操作链维护
void afterNodeInsertion(boolean evict) { // 在HashMap中被回调 LinkedHashMap.Entry<K,V> first; if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; removeNode(hash(key), key, null, false, true); } }
前面说了,LinkedHashMap继承自HashMap,因此如果想要了解LinkedHashMap自然是要先学习HashMap的
访问顺序调整
public V get(Object key) { Node<K,V> e; if ((e = getNode(key)) == null) return null; if (accessOrder) afterNodeAccess(e); return e.value; }
void afterNodeAccess(Node<K,V> e) { // 移动访问节点到链表尾部 LinkedHashMap.Entry<K,V> last; if (accessOrder && (last = tail) != e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.after = null; if (b == null) head = a; else b.after = a; if (a != null) a.before = b; else last = b; if (last == null) head = p; else { p.before = last; last.after = p; } tail = p; ++modCount; } }
架构演进历程
JDK1.4-1.7
基础实现:基于数组+链表+双向链表
hash冲突处理:纯链表方案(因为未引入红黑树)
JDK8
结构变化:HashMap引入红黑树优化
适配改造:LinkedHashMap通过重写相关方法保持链表一致性
JDK9+
迭代器改进:增强fail-fast机制的安全性
应用场景
LRU缓存实现
public class LRUCache<K,V> extends LinkedHashMap<K,V> { private final int maxCapacity; public LRUCache(int maxCapacity) { super(maxCapacity, 0.75f, true); this.maxCapacity = maxCapacity; } @Override protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return size() > maxCapacity; } }
访问轨迹记录
LinkedHashMap<String, Long> accessLog = new LinkedHashMap<>(100, 0.75f, true) { @Override protected boolean removeEldestEntry(Map.Entry<String, Long> eldest) { return size() > 50; // 仅保留最近50次访问记录 } };
性能调优建议
-
容量初始化:根据预估数据量设置初始容量(避免频繁rehash)
-
负载因子选择:高查询频率场景建议0.5-0.75
-
并发控制:推荐使用Collections.synchronizedMap包装
-
遍历优化:entrySet().iterator()比keySet()效率更高
与其他Map对比
| 特性 | LinkedHashMap | HashMap | TreeMap |
|---|---|---|---|
| 迭代顺序 | 插入/访问顺序 | 无序 | 键自然顺序 |
| 时间复杂度 | O(1) | O(1) | O(log n) |
| 内存消耗 | 较高 | 低 | 中等 |
| 线程安全 | 否 | 否 | 否 |
| 使用场景 | 缓存、顺序访问 | 通用存储 | 范围查询 |

黑客/网络安全学习包


资料目录
-
成长路线图&学习规划
-
配套视频教程
-
SRC&黑客文籍
-
护网行动资料
-
黑客必读书单
-
面试题合集
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

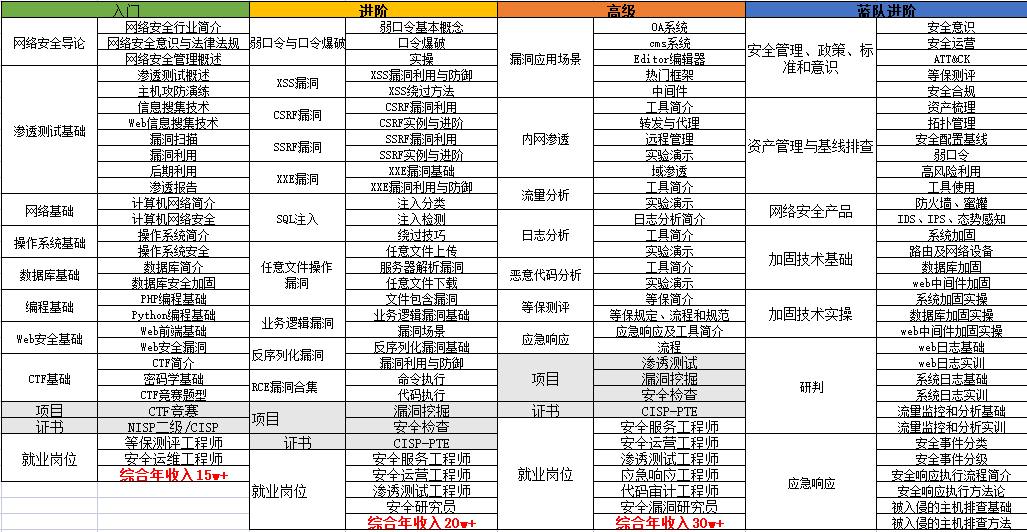
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
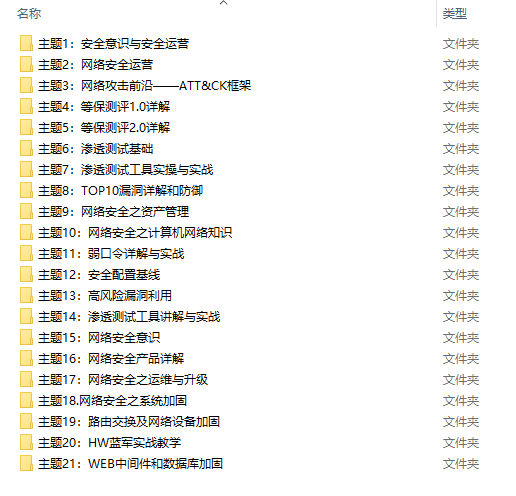
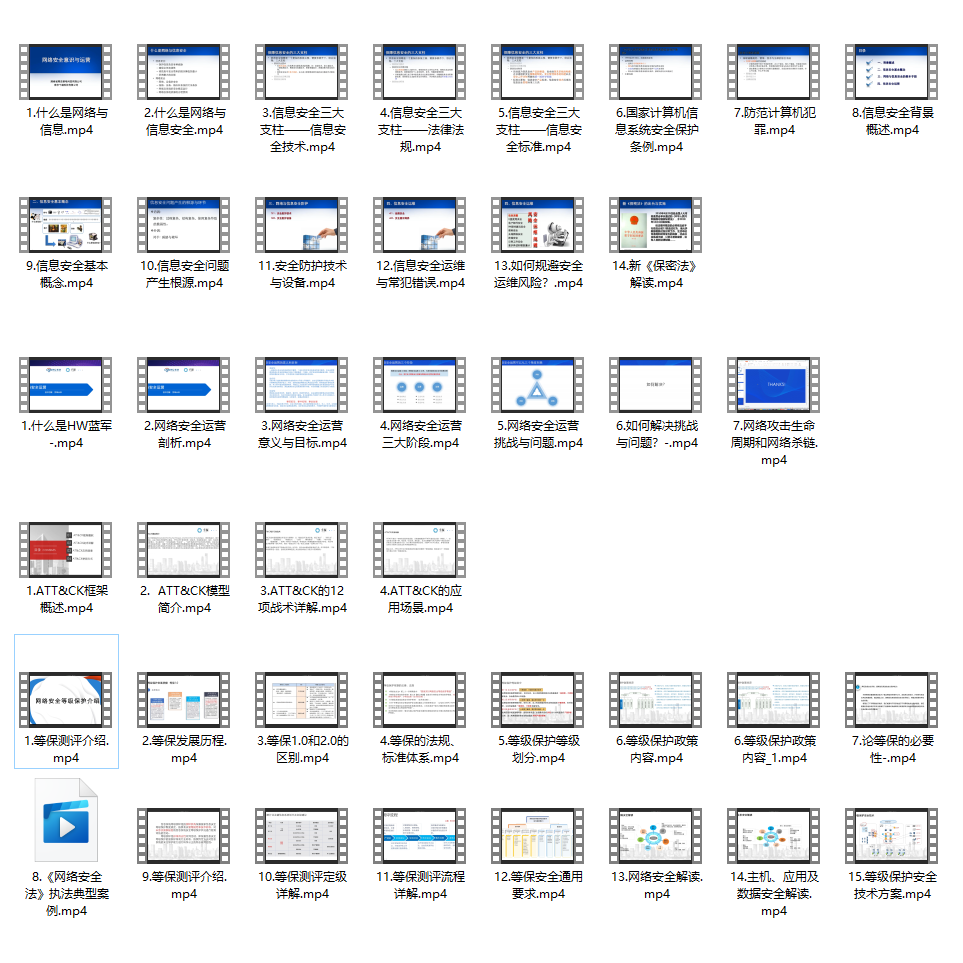
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.SRC&黑客文籍
大家最喜欢也是最关心的SRC技术文籍&黑客技术也有收录
SRC技术文籍:

黑客资料由于是敏感资源,这里不能直接展示哦!
4.护网行动资料
其中关于HW护网行动,也准备了对应的资料,这些内容可相当于比赛的金手指!
5.黑客必读书单
**

**
6.面试题合集
当你自学到这里,你就要开始思考找工作的事情了,而工作绕不开的就是真题和面试题。
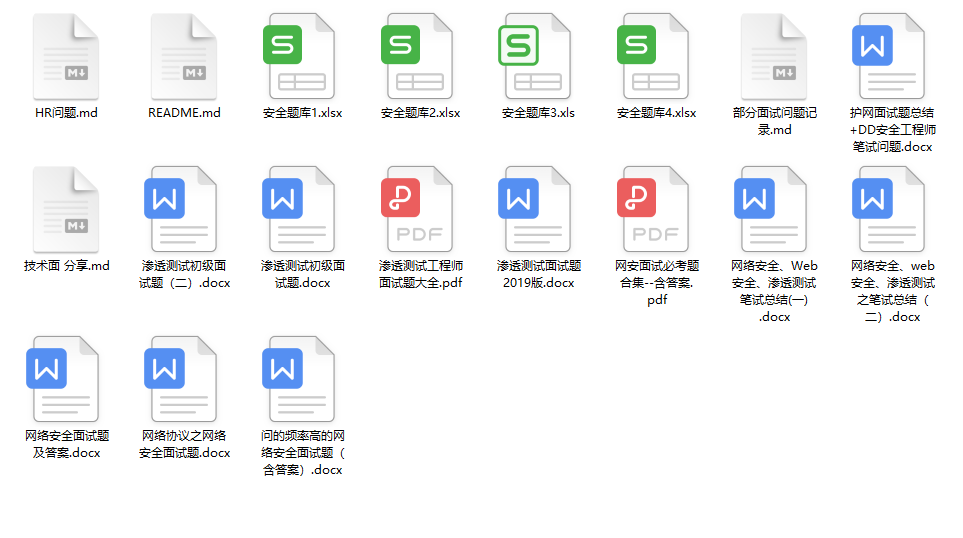
更多内容为防止和谐,可以扫描获取~

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









