






本文我们聊一聊深度学习模型的发展历史及原理。
深度学习模型的发展历程是令人震撼的一部波澜壮阔的史诗,其发展历程可以划分为5个重要的阶段,每个阶段都伴随着理论上的突破和技术上的革新,逐步揭开了人工智能世界的神秘面纱。

1. 启蒙时期与早期模型
-
M-P模型:在20世纪40年代,心理学家Warren McCulloch和数学家Walter Pitts提出了M-P模型。这是最早的神经网络模型,基于生物神经元的结构和功能进行建模。M-P模型通过逻辑运算模拟了神经元的激活过程,为后续的神经网络研究奠定了基础。
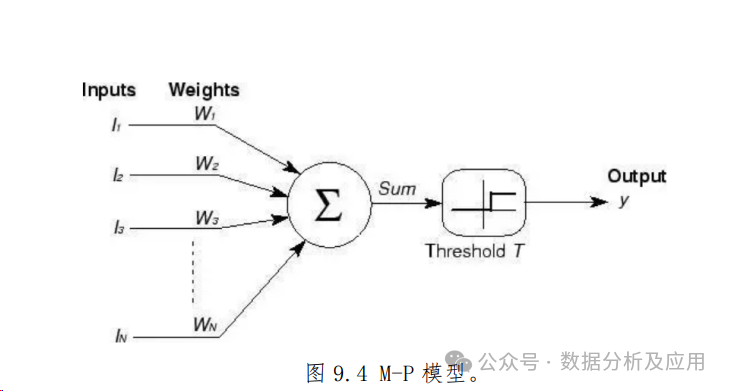
-
Hebb学习规则:1949年,心理学家Donald Hebb提出了Hebb学习规则,该规则描述了神经元之间连接强度(即权重)的变化规律。Hebb认为,神经元之间的连接强度会随着它们之间的活动同步性而增强,这一规则为后续的神经网络学习算法提供了重要的启示。
2. 感知器时代
-
感知器模型:在1950年代到1960年代,Frank Rosenblatt提出了感知器模型。感知器是一种简单的神经网络结构,主要用于解决二分类问题。然而,由于其只能处理线性可分问题,对于复杂问题的处理能力有限,导致神经网络研究在一段时间内陷入了停滞。
-
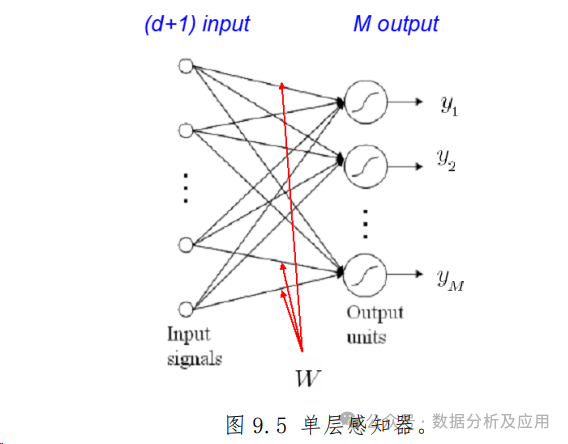
3. 连接主义与反向传播算法的提出
-
连接主义:在1960年代末到1970年代,尽管神经网络研究遭遇低谷,但连接主义的概念仍在继续发展。连接主义强调神经元之间的连接和相互作用对神经网络功能的重要性。
-
反向传播算法:1986年,David Rumelhart、Geoffrey Hinton和Ron Williams等科学家提出了误差反向传播(Backpropagation)算法。这一算法允许神经网络通过调整权重来最小化输出误差,从而有效地训练多层神经网络。反向传播算法的提出标志着神经网络研究的复兴。
-
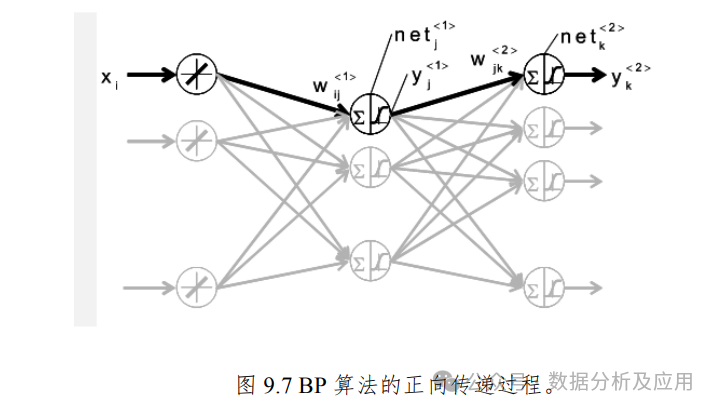
-
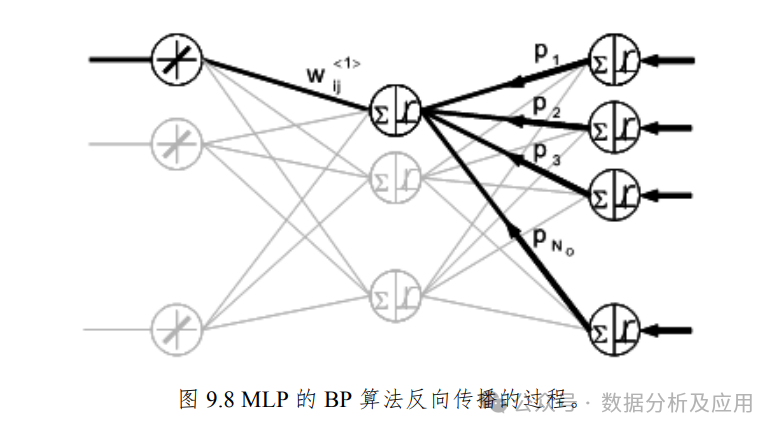
4. 深度学习时代的来临
感知机时代,神经网络由于受限于算力而饱受质疑。随着算力、数据、算法迎来了突破,深度学习的时代来了。
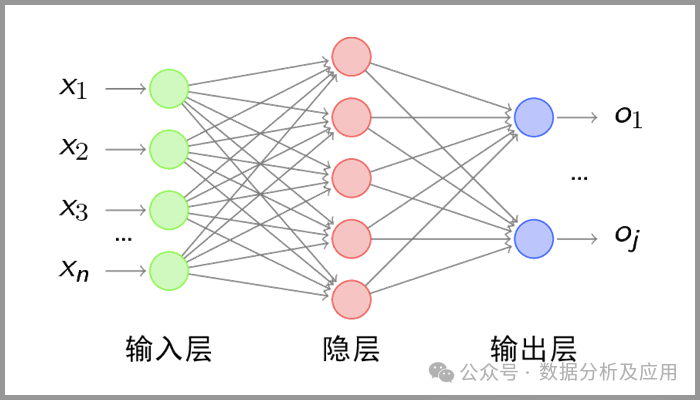
-
多层感知器(MLP):在反向传播算法的推动下,多层感知器(MLP)成为了多层神经网络的代表。MLP具有多个隐藏层,能够学习复杂的非线性映射关系。比如在NLP中,神经网络可以对语义共现关系进行建模,成功地捕获复杂语义依赖。
-
随着计算能力的提升和大数据的普及,基于多层神经网络的深度学习逐渐成为神经网络研究的热点领域。如下示例代码展示,如何通过MLP识别图片(注:MLP通常不是处理图像数据的首选模型,因为卷积神经网络(CNN)在处理图像数据时更为高效和准确。为了简单起见,我们将使用MLP。):
import keras` `from keras.datasets import mnist` `from keras.models import Sequential` `from keras.layers import Dense, Flatten` `from keras.utils import to_categorical` ` ``# 设置参数` `batch_size = 128` `num_classes = 10` `epochs = 12` ` ``# 加载MNIST数据集` `(x_train, y_train), (x_test, y_test) = mnist.load_data()` ` ``# 数据预处理` `x_train = x_train.reshape(60000, 784)` `x_test = x_test.reshape(10000, 784)` `x_train = x_train.astype('float32')` `x_test = x_test.astype('float32')` `x_train /= 255` `x_test /= 255` `y_train = to_categorical(y_train, num_classes)` `y_test = to_categorical(y_test, num_classes)` ` ``# 构建MLP模型` `model = Sequential()` `model.add(Dense(512, activation='relu', input_shape=(784,)))` `model.add(Dense(512, activation='relu'))` `model.add(Dense(num_classes, activation='softmax'))` ` ``# 编译模型` `model.compile(loss=keras.losses.categorical_crossentropy, `` optimizer=keras.optimizers.Adadelta(), ``metrics=['accuracy'])` ` ``# 训练模型` `model.fit(x_train, y_train, `` batch_size=batch_size, `` epochs=epochs, `` verbose=1, ``validation_data=(x_test, y_test))` ` ``# 评估模型` `score = model.evaluate(x_test, y_test, verbose=0)` `print('Test loss:', score[0])` `print('Test accuracy:', score[1])
-
卷积神经网络(CNN)与循环神经网络(RNN):在深度学习时代,卷积神经网络(CNN)和循环神经网络(RNN)等模型得到了广泛应用。CNN特别适用于处理图像数据,而RNN则擅长处理序列数据如文本和语音。这些模型在图像识别、语音识别、自然语言处理等领域取得了显著的成果。
-
随着研究的深入,神经网络模型不断发展和创新。例如,生成对抗网络(GAN)用于生成逼真的图像和视频;长短时记忆网络(LSTM)解决了传统RNN在处理长序列时的梯度问题;注意力机制(Attention Mechanism)提高了模型对重要信息的关注度;图神经网络(GNN)则用于处理图结构数据等。
5. 大模型时代
大模型基于缩放定律。简单来说就是,随着深度学习模型参数和预训练数据规模的不断增加,模型的能力与任务效果会持续提升,甚至展现出了一些小规模模型所不具备的独特“涌现能力”。
在大模型时代,最具影响力的模型基座无疑就是Transformer和Diffusion Model。基于Transformer的ChatGPT具有革命性的意义,展示了人工智能技术的无限潜力。而基于Diffusion Model的Sora大模型在此惊艳了世人,进入多模态的人工智能时代。
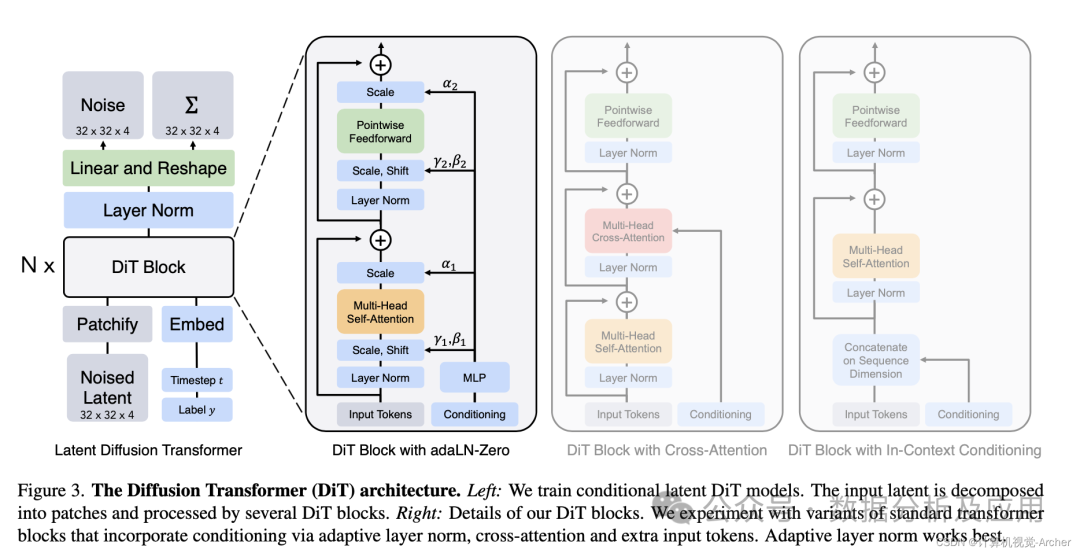
-
**Transformer,**最初是为自然语言处理任务而设计的,其核心思想是通过自注意力机制捕捉输入序列中的依赖关系。与传统的循环神经网络(RNN)相比,Transformer能够并行处理整个序列,大大提高了计算效率。同时,由于其强大的特征提取能力,Transformer架构作为基础模型,如BERT、GPT等,通过在海量数据上进行训练,获得了强大的通用表示能力,为下游任务提供了高效的解决方案。
-
Diffusion Model是一种基于扩散过程的生成模型,它通过逐步添加噪声到数据中,然后再从噪声中逐步恢复出原始数据,从而实现了对数据分布的高效建模。此外,Diffusion Model还具有很强的可控性,通过调整模型参数,可以控制生成图像的风格、颜色、纹理等特性。这使得Diffusion Model在艺术创作、设计等领域具有广泛的应用前景。
import torch``import torch.nn as nn``import torch.optim as optim``#该示例仅用于说明Transformer的基本结构和原理。实际的Transformer模型(如GPT或BERT)要复杂得多,并且需要更多的预处理步骤,如分词、填充、掩码等。``class Transformer(nn.Module):` `def __init__(self, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward=2048):` `super(Transformer, self).__init__()` `self.model_type = 'Transformer'`` ` `# encoder layers` `self.src_mask = None` `self.pos_encoder = PositionalEncoding(d_model, max_len=5000)` `encoder_layers = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward)` `self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_encoder_layers)`` ` `# decoder layers` `decoder_layers = nn.TransformerDecoderLayer(d_model, nhead, dim_feedforward)` `self.transformer_decoder = nn.TransformerDecoder(decoder_layers, num_decoder_layers)`` ` `# decoder` `self.decoder = nn.Linear(d_model, d_model)`` ` `self.init_weights()`` ` `def init_weights(self):` `initrange = 0.1` `self.decoder.weight.data.uniform_(-initrange, initrange)`` ` `def forward(self, src, tgt, teacher_forcing_ratio=0.5):` `batch_size = tgt.size(0)` `tgt_len = tgt.size(1)` `tgt_vocab_size = self.decoder.out_features`` ` `# forward pass through encoder` `src = self.pos_encoder(src)` `output = self.transformer_encoder(src)`` ` `# prepare decoder input with teacher forcing` `target_input = tgt[:, :-1].contiguous()` `target_input = target_input.view(batch_size * tgt_len, -1)` `target_input = torch.autograd.Variable(target_input)`` ` `# forward pass through decoder` `output2 = self.transformer_decoder(target_input, output)` `output2 = output2.view(batch_size, tgt_len, -1)`` ` `# generate predictions` `prediction = self.decoder(output2)` `prediction = prediction.view(batch_size * tgt_len, tgt_vocab_size)`` ` `return prediction[:, -1], prediction`` `` ``class PositionalEncoding(nn.Module):` `def __init__(self, d_model, max_len=5000):` `super(PositionalEncoding, self).__init__()`` ` `# Compute the positional encodings once in log space.` `pe = torch.zeros(max_len, d_model)` `position = torch.arange(0, max_len).unsqueeze(1).float()` `div_term = torch.exp(torch.arange(0, d_model, 2).float() *` `-(torch.log(torch.tensor(10000.0)) / d_model))` `pe[:, 0::2] = torch.sin(position * div_term)` `pe[:, 1::2] = torch.cos(position * div_term)` `pe = pe.unsqueeze(0)` `self.register_buffer('pe', pe)`` ` `def forward(self, x):` `x = x + self.pe[:, :x.size(1)]` `return x`` `` ``# 超参数``d_model = 512``nhead = 8``num_encoder_layers = 6``num_decoder_layers = 6``dim_feedforward = 2048`` ``# 实例化模型``model = Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward)`` ``# 随机生成数据``src = torch.randn(10, 32, 512)``tgt = torch.randn(10, 32, 512)`` ``# 前向传播``prediction, predictions = model(src, tgt)``
小结
当下,大模型时代的神经网络模型往往具有更高的计算复杂度和更大的参数规模。这得益于计算机硬件的不断进步和算法的优化。同时,大规模数据的收集和处理也为这些模型的训练提供了有力支持。然而,大模型也面临着一些挑战,如高质量数据资源不足、计算资源的消耗、模型的泛化能力等问题。
未来的发展中,如何进一步提高大模型的性能并降低其计算成本将是一个重要的研究方向!
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 3651
3651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









