






前言:
最近有个需求,需要抓取国内城市地铁数据,但是身为前端仔,没有爬过数据。就想图个方便好用的数据抓取工具,所以就去网上找了下技术方案,使用 Nodejs + puppeteer 来抓取数据,本着自己动手丰衣足食的原则,就采用该方案自己写了一个工具。
但是由于技术菜,各在线网站的抓取限制和其他成本原因导致效果实在是不理想
- 1.抓取速度慢,数据量小
- 2.抓取的数据不全
还遇到目标网站封锁 IP 的问题,导致抓取失败; 只能放弃自己实现抓取工具的方案;
转而寻求现有的抓取数据工具,问了一些大佬朋友,大佬说可以使用亮数据(Bright Data)的工具来抓取数据。
针对上面的数据规范抓取,IP 封锁的问题,亮数据的工具都有相应的解决方案。
所以就选择了亮数据(Bright Data)的工具来抓取数据。
亮数据工具介绍
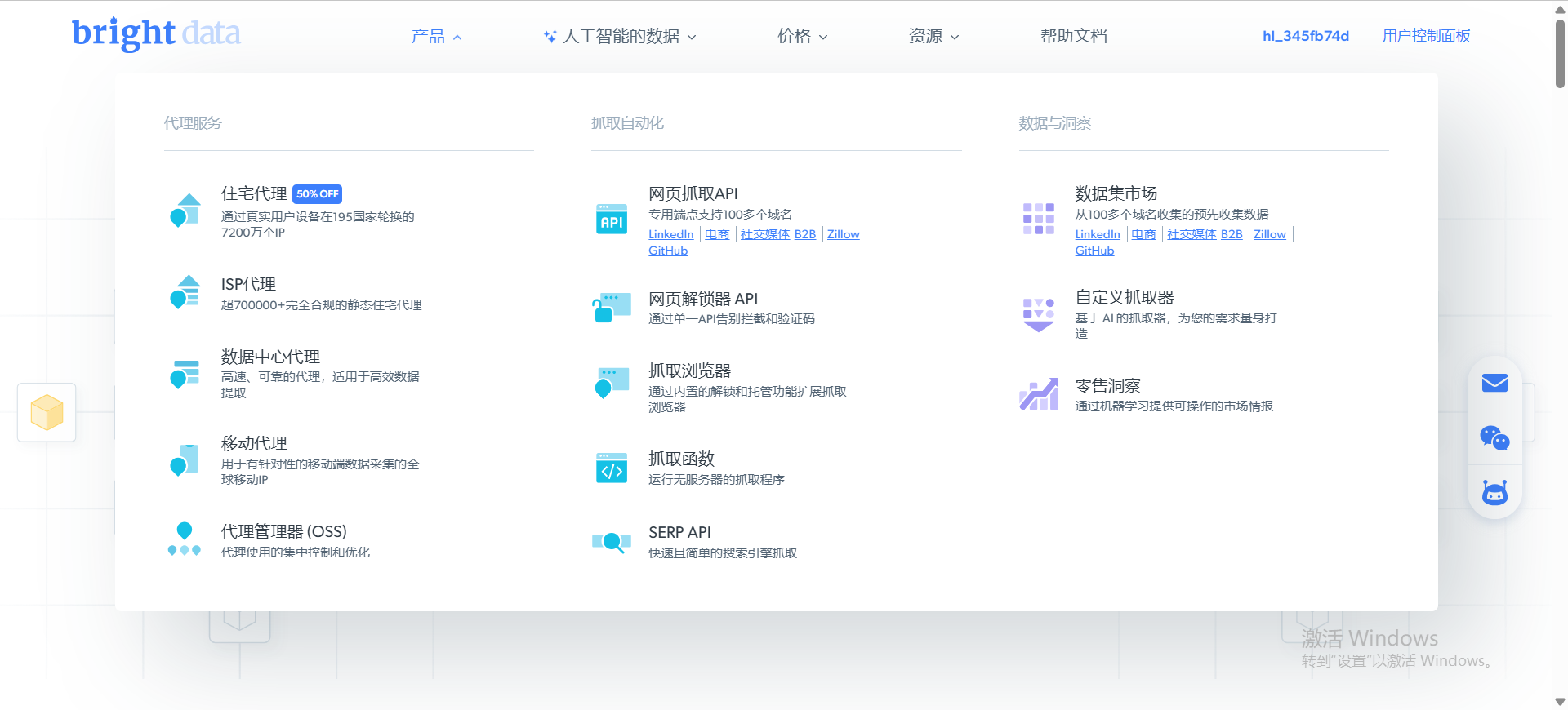
从上图可以看到,亮数据工具提供了许多的现成的成熟方案以及在线产品来满足我们抓取数据不同需求,解决在线网站的抓取限制的各种问题和其他成本问题
所有产品使用可参见 亮数据(BrightData)官方产品文档
比如:
- 代理服务:使用代理 IP 来抓取数据,避免 IP 被封锁
- 数据抓取:
- 100+网站专用端点数据抓取 API
- 亮数据专用抓取浏览器工具
- 网站验证拦截和验证码限制规避
- 无服务器抓取程序
- 数据集市场:126+ 域名、共 210+ 数据集,涵盖各大通用公共网络数据网站现成的预收集数据
全方位的解决方案,满足我们抓取数据的各种需求
并且现在注册,即可获取免费使用福利
注册专属链接:亮数据-网络IP代理及全网数据一站式服务商
数据抓取实践
确定数据来源
要抓取数据,首先需要知道数据的来源
比如这次我想要的国内各城市地铁数据
来源就是国内某地图在线提供商的地铁数据
出于安全因素,不能提供网站的具体的 URL 地址
比如:某个城市的数据如下再页面中如下:
由于数据是公开的,所以可以直接通过 URL 来获取数据
但是我需要的是 JSON 数据,页面是 HTML 数据,但是没关系
先拿到所有的 HTML 数据之后,再通过正则表达式来提取数据即可
所以目前这一阶段我的需求是:
- 获取所有城市的地铁数据的页面HTML数据
确定抓取工具
问题来了
但是我应该选择什么工具来抓取数据呢?
对于我来说最重要的:方便使用
尽量少的学习使用成本,尽量快的获取数据
查阅亮数据提供的爬取方案后,我发现了以下几种方案可以实现我的要求:
- 1.网络解锁器
- 2.SERP API
- 3.抓取浏览器
- 3.网页抓取 API
根据我的需求,并在阅读了亮数据的官方文档之后,我发现第一种比较合适
亮数据网络解锁器(Web Unlocker API)
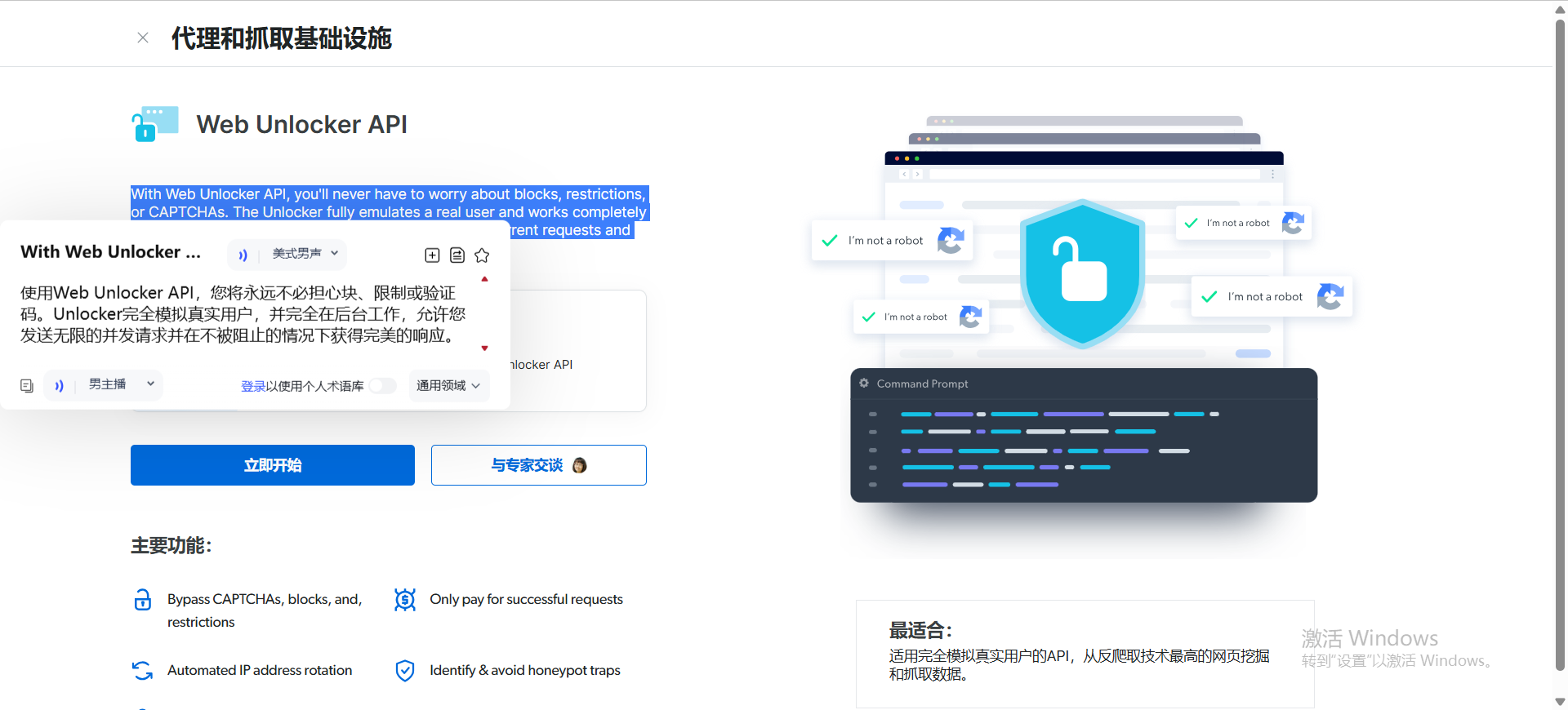
通过文档查看后到这句话:亮数据网络解锁器只需向目标网站发送一个代理请求,我们就会将干净的 HTML 和/或 JSON 数据交付给您 。就是这么简单!
结合由于数据来源是在线网站,需求评估之后,我发现了亮数据网络解锁器工具满足我的需要
- 方便上手
- 开箱即用
- 返回 HTML 数据
来看看官方介绍
亮数据网络解锁器最适用于
- 从任何网站抓取数据,不会被屏蔽
- 模拟真实用户的网络行为,对使用复杂检测方法的网站也能进行抓取
- 内部没有可扩展的解锁基础设施的团队
- 只需为成功的请求付费
仅从上面的介绍中,我就可以看到它的使用场景满足了我的需求
当然除此之外,亮数据网络解锁器还有其他的一些优点如下:
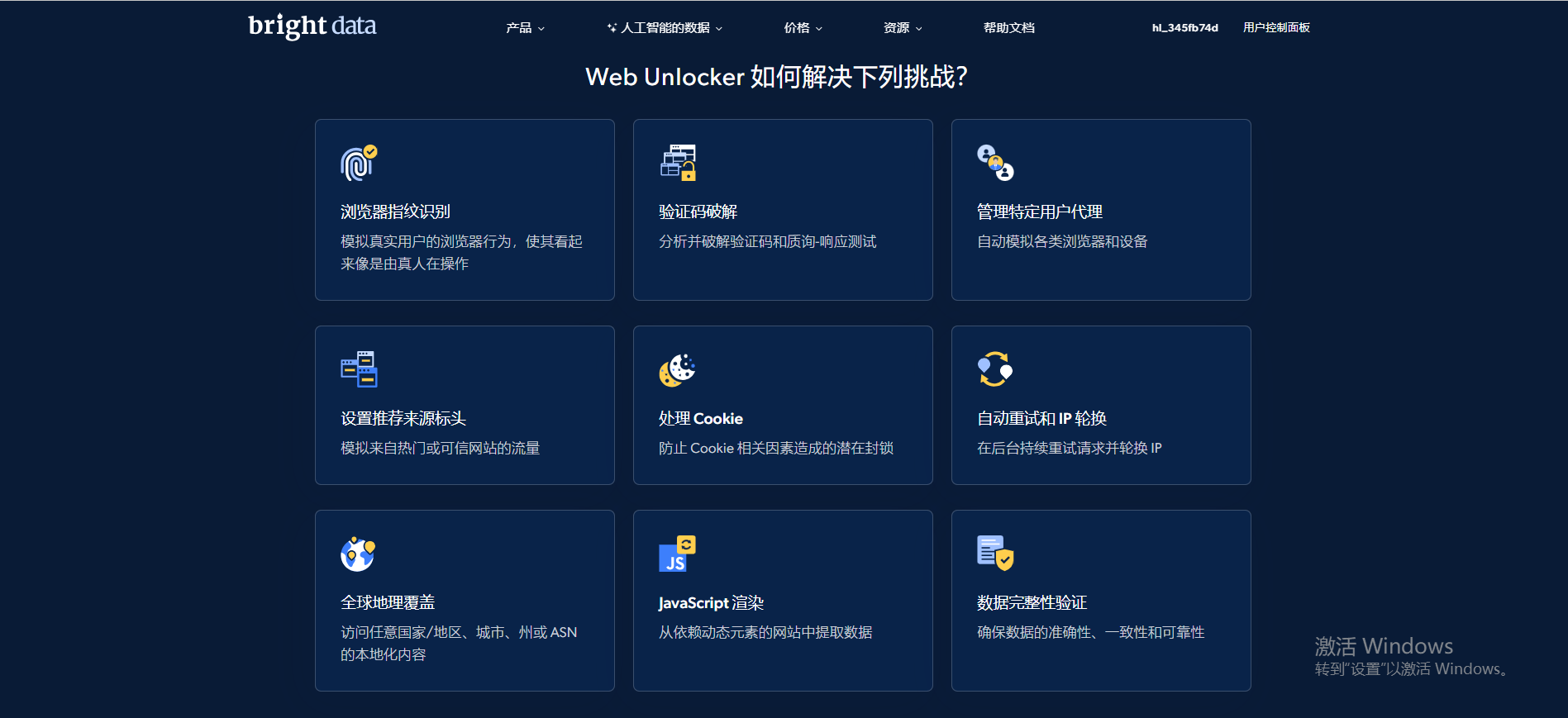
- 浏览器指纹识别:模拟真实用户的浏览器行为,使其看起来像是由真人在操作
- 处理 Cookie: 防止 Cookie 相关因素造成的潜在封锁
- JavaScript 渲染:从依赖动态元素的网站中提取数据
- 数据完整性验证: 确保数据的准确性、一致性和可靠性
- 等
使用亮数据抓取工具
创建抓取任务
打开工作台,点击创建任务,选择网络解锁器,填写任务名称,选择目标网站,选择代理类型,点击创建任务
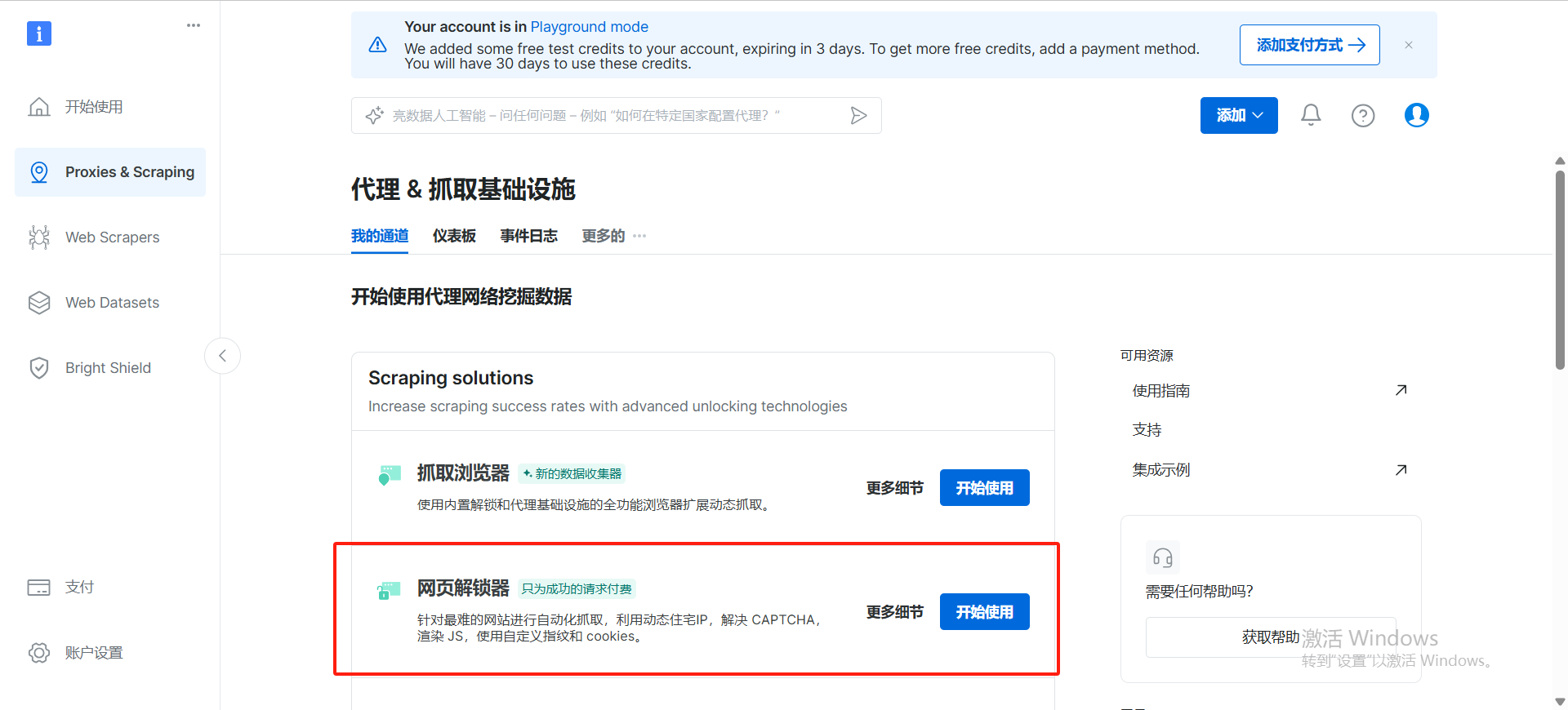
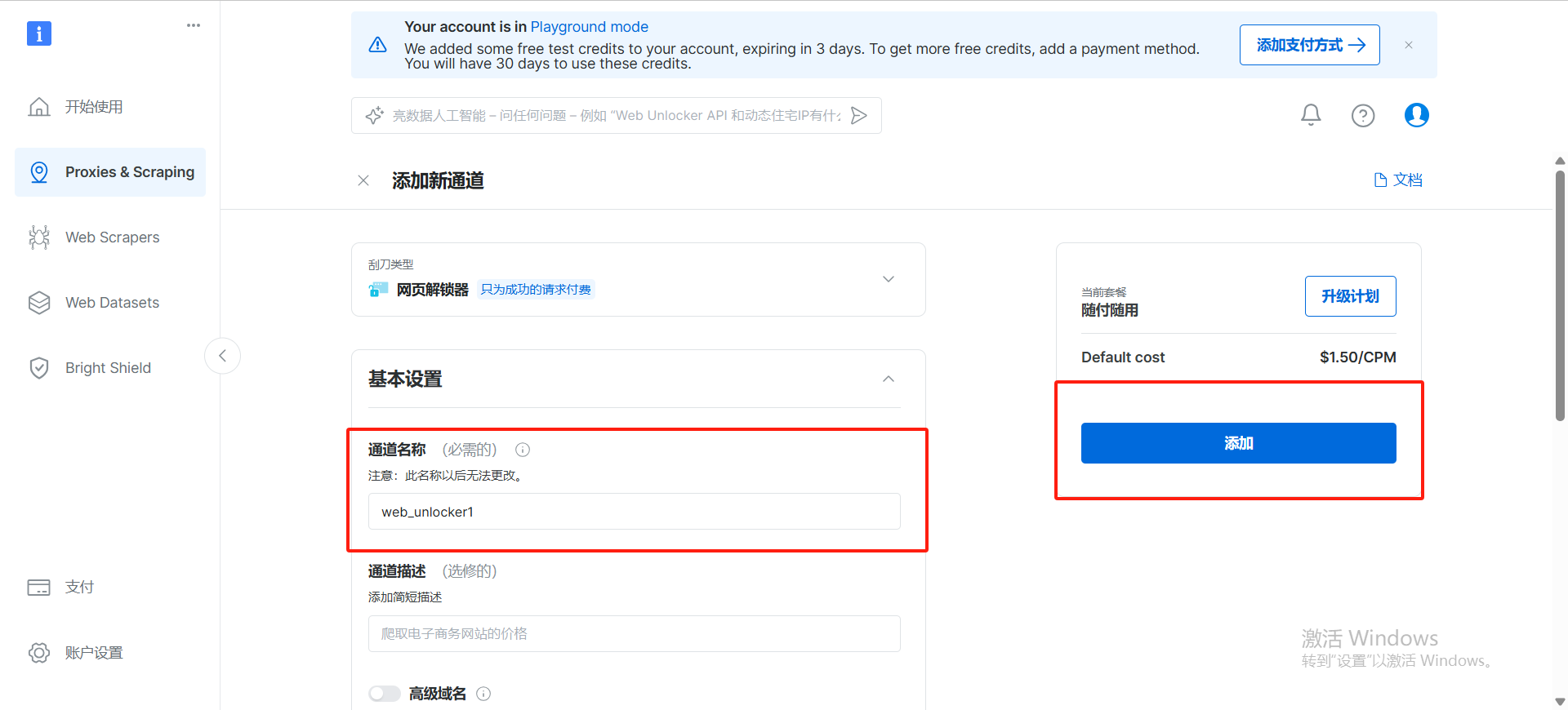
创建成功之后,我们就会得到一个 curl 请求,我们可以使用【直接 API 访问】或者 【基于本机代理的访问】curl 请求来获取数据如下:
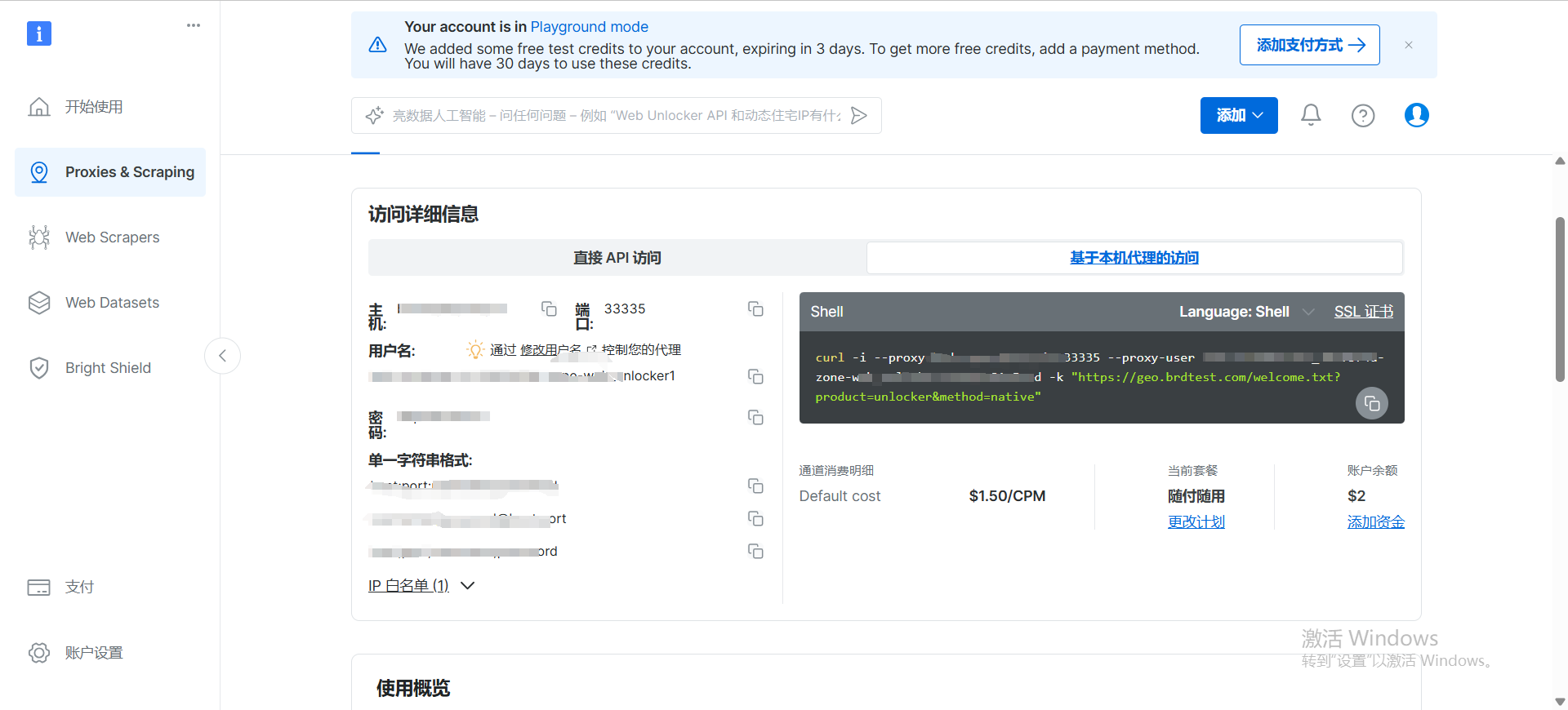
# 直接API访问 示例
curl https://api.brightdata.com/request -H "Content-Type: application/json" -H "Authorization: Bearer [replace with API Key]" -d "{\"zone\": \"web_unlocker1\",\"url\": \"https://geo.brdtest.com/mygeo.json\", \"format\": \"raw\"}"注意:
这里的 zone 是我们创建任务时选择的代理类型和类型
- [replace with API Key] 是我们的 API Key (由亮数据提供)
- zone 服务产品名称
- url 是我们要抓取的目标网站
- format 是我们要抓取的数据格式
- raw 是原始数据
- json 是 json 数据
- html 是 html 数据
- country 国家地区
但是这里我们可以不使用 curl 请求
由于我是使用 Nodejs 来抓取数据,所以找了一会文档
中提到可以使用js来执行请求,所以我就使用 js 来执行请求
使用curl API获取数据
我们可以使用 curl 请求来获取数据,也可以使用亮数据专用抓取浏览器工具来获取数据
但是数据量比较小,所以我直接使用 curl 请求在本机来获取数据
但是在此之前要配置 IP访问白名单
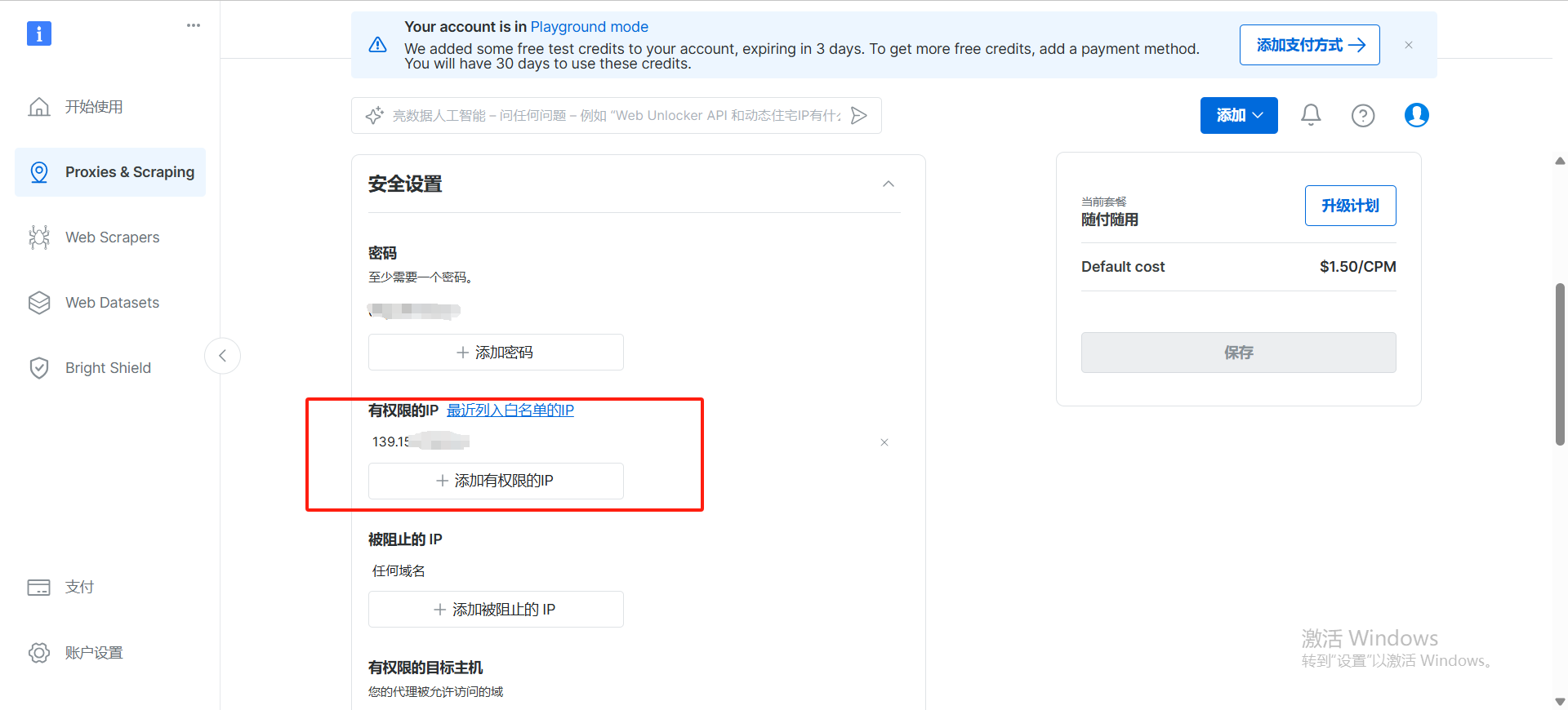
主要配置两项
- 有权限的 IP
- 就是你的服务器公网IP、或者宽度 IP
- 有权限的目标主机(您的代理被允许访问的域)(即目标抓取网站的域名)
- 这里配置测试网站域名 geo.brdtest.com
测试官方用例抓取数据
配置完成后,我到亮数据的在线接口实验场试用一下
playground 地址:Unlocker & SERP REST API 游乐场 - Bright Data Docs
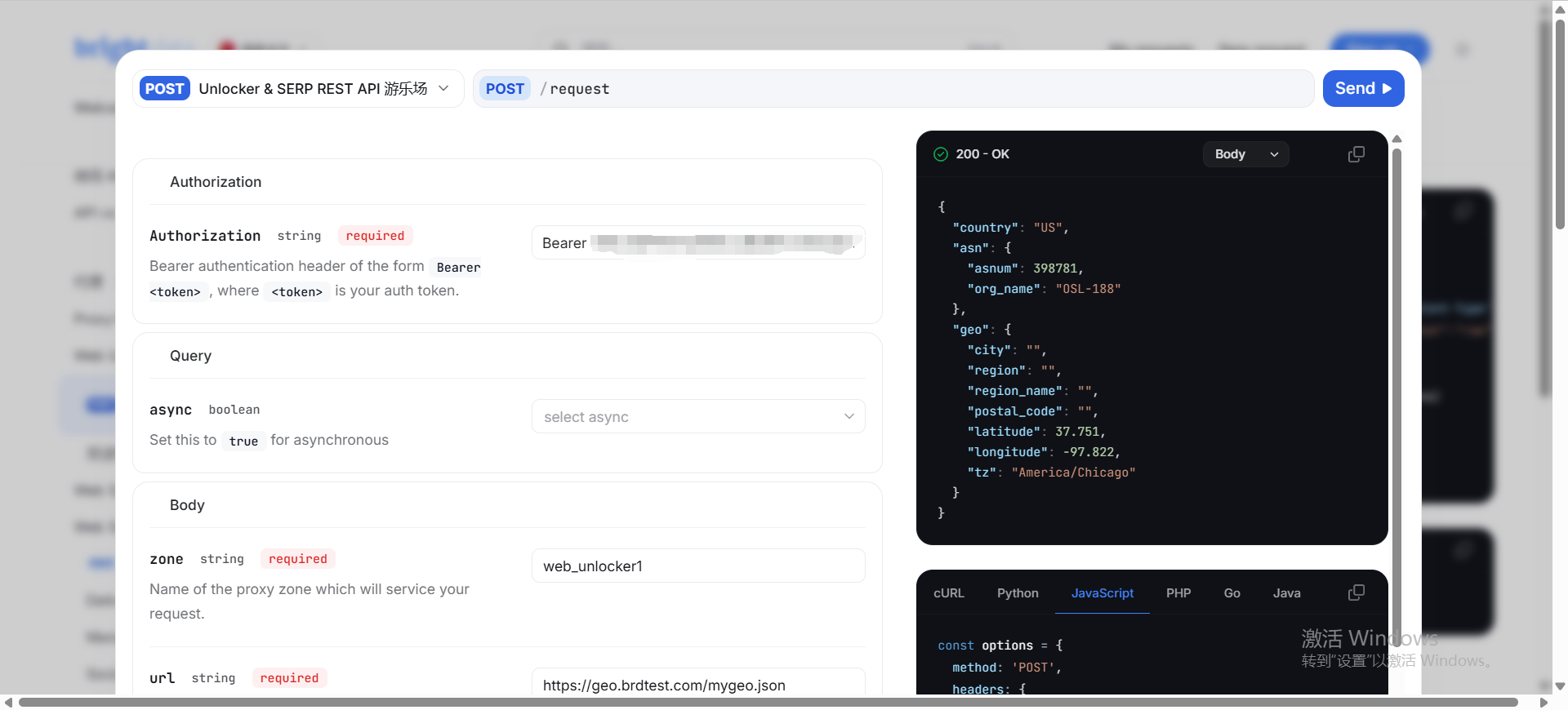
返回结果如下:
{
"country": "US",
"asn": { "asnum": 398781, "org_name": "OSL-188" },
"geo": {
"city": "",
"region": "",
"region_name": "",
"postal_code": "",
"latitude": 37.751,
"longitude": -97.822,
"tz": "America/Chicago"
}
}数据爬取完美实现
地铁数据抓取实践
根据上面的测试案例,创建index.js
const axios = require("axios");
//#region ===== 请求函数封装
axios({
url: "https://api.brightdata.com/request",
timeout: 10000,
method: "POST",
headers: {
Authorization: "Bearer [token]",
"Content-Type": "application/json",
"User-Agent":
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
},
data: {
zone: "web_unlocker1",
url: "https://[target domain].com/subway/index.html?&1100",
format: "raw",
method: "GET",
// country: "<string>",
},
})
.then((response) => {
const res = response.data;
console.log(res);
})
.catch((err) => console.error(err));注意:
- [token] 是我们的 API Key (由亮数据提供)
- url: "https://[target domain].com/subway/index.html?&1100", 是我们要抓取的目标网站
- 这里?&1100参数表示 北京市地铁数据
然后CMD执行node index.js, 得到返回数据是html数据
由于整个html数据过多,以下是数据中我们需要的部分
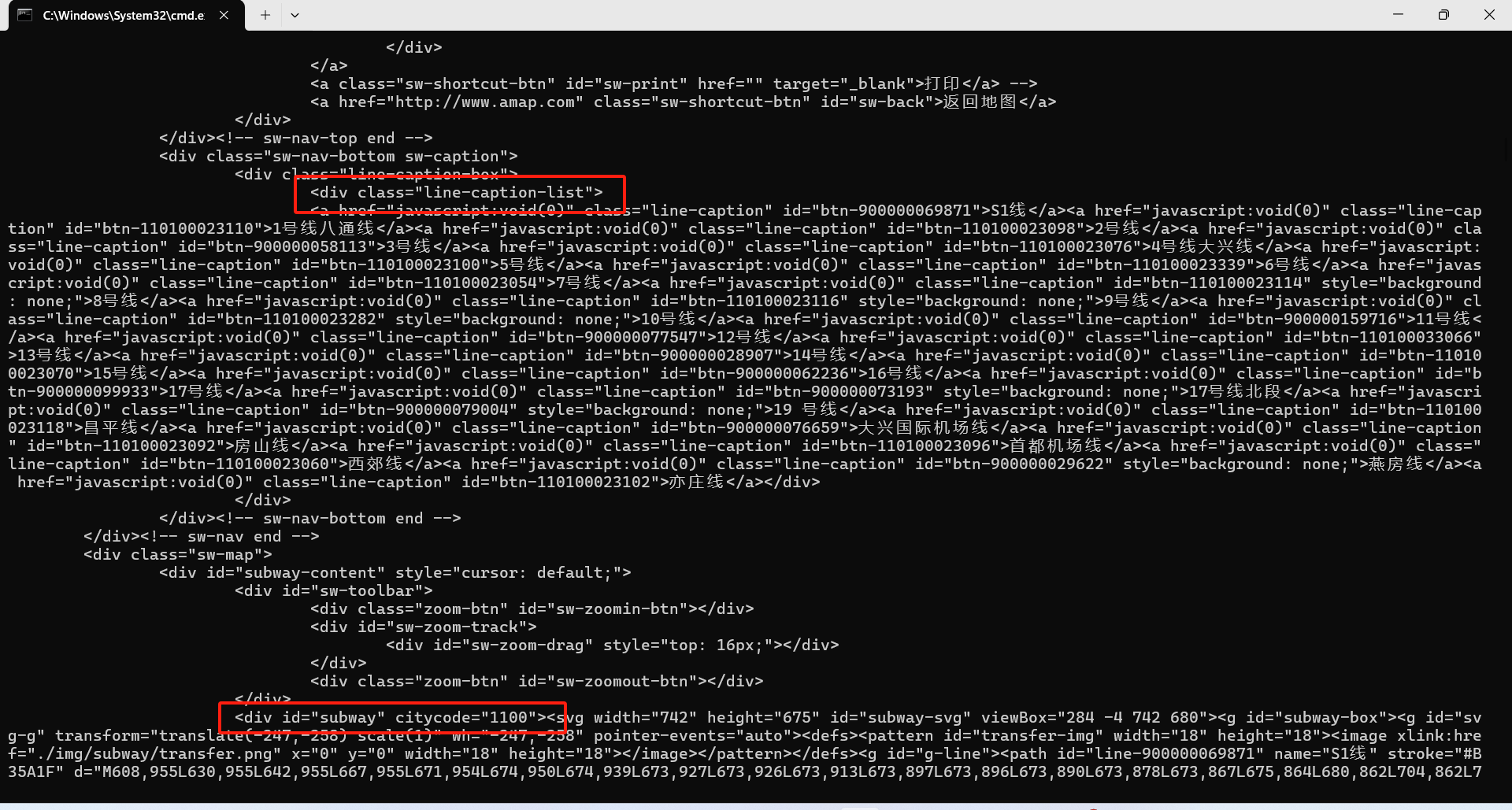
可以看到
html元素<div class="line-caption-list"> 下表示线路
html元素<div id="subway" citycode="1100"> 则依次展示了所有线路的站台数据
之后我们使用正则表达式提取对应数据得到

当这只是一个城市的数据提取,其他城市的数据提取即可更换参数,城市的对应地理代码即可
总结
- 1.创建任务,选择网络解锁器,填写任务名称,选择目标网站,选择代理类型,点击创建任务
- 2.只需要配置IP访问白名单和有权限的目标主机即可
- 3.获取亮数据提供的代理API数据抓取接口, url 参数填入目标网站, 即可获取数据;根据需求设置 format 数据返回格式
- 3.使用亮数据工具抓取数据,不需要学习使用成本,只需要使用亮数据专用抓取浏览器工具或者js来执行请求即可
总的来说亮数据(Bright Data)的工具是一个非常好的工具,解决了我们抓取数据的各种问题,
针对上面的数据规范抓取,IP 封锁的问题,亮数据的工具都有相应的解决方案
甚至有现成的成熟方案以及在线预收集数据集
现在注册,即可获取免费使用福利
注册专属链接:亮数据-网络IP代理及全网数据一站式服务商


















 3057
3057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











