







@TOC
用自己训练的数据跑tesseract识别验证码,最后附上正确率
1、使用现成的工具jTessBoxEditor,和tesseract,都是已经写好的工具,不需要再造轮子(尤其是从头学深度学习让你造一个神经网络写完就已经半年后了,还不排除从入门到放弃)首先要安装JDK,训练数据的机器依赖JAVA环境
JDK8:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
jTessBoxEditor:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
2、准备训练数据
我已经写好了代码,简单写了写,都是想着自己用的,所以看起来很小白啦
from PIL import Image
from PIL import ImageDraw
from PIL import ImageFont
import random
def getRandomColor():
# 获取一个随机颜色(r,g,b)格式的
c1 = random.randint(0, 255)
c2 = random.randint(0, 255)
c3 = random.randint(0, 255)
return (c1, c2, c3)
def getRandomStr():
# 获取一个随机字符串 颜色随机
# 数字
random_num = str(random.randint(0, 9))
# 大写
random_low_alpha = chr(random.randint(97, 122))
# 小写
random_upper_alpha = chr(random.randint(65, 90))
random_char = random.choice([random_num, random_low_alpha, random_upper_alpha])
return random_char
def getCaptcha_1():
for pages in range(0, 100):
# 获取数字验证码 随机颜色
# 获取一个Image对象,参数分别市RBG模式 宽150 高30 随机颜色
captcha = Image.new('RGB', (150, 40), getRandomColor())
draw = ImageDraw.Draw(captcha)
# 获取一个font字体对象参数市ttf的字体文件的目录以及字体的大小
font = ImageFont.truetype("arial.ttf", size=32)
# 在图片上写东西,参数是:定位,字符串,颜色,字体
for i in range(4):
draw.text((20+i*30, 0), str(random.randint(0, 9)), getRandomColor(), font=font)
captcha.save(open('{}.png'.format(pages), 'wb'), 'png')
# return captcha
# captcha.show()
def getCaptcha_2():
# 固定字符串 随机颜色
# 获取一个Image对象,参数分别市RBG模式 宽150 高30 随机颜色
captcha = Image.new('RGB', (150, 40), getRandomColor())
# 获取一个画笔对象,将图片传过去
draw = ImageDraw.Draw(captcha)
# 获取一个font字体对象参数市ttf的字体文件的目录以及字体的大小
font = ImageFont.truetype("arial.ttf", size=32)
# 在图片上写东西,参数是:定位,字符串,颜色,字体
draw.text((20, 0), 'abcd', getRandomColor(), font=font)
# captcha.save(open('test.png', 'wb'), 'png')
# captcha.show()
return captcha
def getCaptcha_3():
for pages in range(0, 100):
# 随机字符串 随机颜色
captcha = Image.new('RGB', (150, 40), getRandomColor())
draw = ImageDraw.Draw(captcha)
font = ImageFont.truetype("arial.ttf", size=32)
for i in range(4):
# 循环4次 获得4个随机字符串
random_char = getRandomStr()
# 在图片上一次写入得到的随机字符串, 参数是定位 字符串 颜色 字体
draw.text((20+i*30, 0), random_char, getRandomColor(), font=font)
captcha.save(open('D:\\Python Workspaces\\constractionMarket\\new_data\\{}.png'.format(pages), 'wb'), 'png')
# captcha.show()
# return captcha
def getCaptcha_4():
# 带有噪点的验证码图片
captcha = Image.new('RGB', (150, 40), getRandomColor())
draw = ImageDraw.Draw(captcha)
font = ImageFont.truetype("arial.ttf", size=32)
for i in range(4):
random_char = getRandomStr()
draw.text((20+i*30, 0), random_char, getRandomColor(), font=font)
# 噪点噪线
width = 150
height = 30
# 划线
for i in range(2):
x1 = random.randint(0, width)
x2 = random.randint(0, width)
y1 = random.randint(0, height)
y2 = random.randint(0, height)
draw.line((x1, y1, x2, y2), fill=getRandomColor())
# 划点
for i in range(15):
draw.point([random.randint(0, width), random.randint(0, height)], fill=getRandomColor())
x = random.randint(0, width)
y = random.randint(0, height)
draw.arc((x, y, x+4, y+4), 0, 90, fill=getRandomColor())
# captcha.save(open('test.png', 'wb'), 'png')
# captcha.show()
return captcha
我用的是第三个,getCaptcha3,生成的是随机颜色的混合大小写和数字的,比较有当今验证码的代表性(加噪点噪线的太麻烦了,最后的成功率也一定不客观hhh)生成了一百个训练数据(大家千万不要跟我一样沙雕搞那么多训练数据,对于初学的话生成20个左右,熟悉步骤就好了,不然矫正数据的时候真的是眼睛都给我看瞎了)

大概就是这个样子
3、打开jTessBoxEditor生成训练样本的合并tif图:
在Tools里的merge TIFF

可以按住crtl然后依次点击全部选完你想要放入的训练数据
然后点打开,然后会弹出让你保存,命名规则为
[lang].[fontname].exp[num].tif lang就是他是什么语言,我写的是num_eng,fontname是字体,我的生成验证码地方的字体是arial,大家的计算机应该都是自带我这个的,查询自己电脑有啥字体可以百度,也可以选择字体奇怪一点的增加难度,num是数字,第一次就是0,之后可以1234,我最后的命名是num_eng.arial.exp0.tif 一定要记住你给他的名字,后面要多次用到,记错了就会失败从新来了。
4、tesseract生成box文件
cmd进入在你生成tif文件的地方,输入
tesseract num_eng.arial.exp0.tif num_eng.arial.exp0 -l eng -psm 7 batch.nochop makebox

类似于我上面这样的报错不用管
5、用jTessBoxEditor矫正.box文件的错误
.box文件记录了他自动识别出的内容,训练前用jtessboxeditor调整纠正,打开jTessBoxEditor点击Box Editor—>Open,打开之前生成的tif文件,会自动关联.box文件(两文件要在同一个目录下)
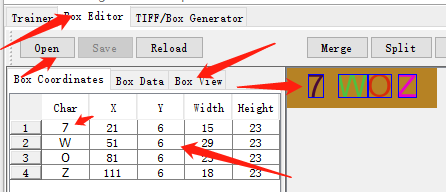
x,y对应x轴y轴,width,height是宽高
右上角可以调整框的位置,把它包住字符并在char里查看是否跟图的一致,跟我一样眼瞎的可以点击Box View 查看大图,这一步你就知道为什么叫你们少生成点训练数据了!
如果识别少了的,可以点击insert插入一个新框,或者多了的点delete。你有可能会遇到一个字都没有识别到,然后还不允许你插入,因为box必须在一个box后面,一个box都没有就不能插入,这样的情况用notepad打开,记事本应该也可以,打开tif文件,会看到一排排的数据像这样的

如果你遇到有的数据都没有,比如是第三页 那么肯定在图的位置第几页里就没有那里的数据,比如是第二页一个字符都没有识别出来,就会是这样的
5 21 11 3 34 0
X 12 13 14 15 0
a 1 1 1 1 0
b 15 16 4 4 0
c 15 15 15 15 2
1 54 54 54 54 2
1 51 51 51 51 2
s 51 51 51 51 2
这是我瞎打的 瞎看看就行
你把他改成
5 21 11 3 34 0
X 12 13 14 15 0
a 1 1 1 1 0
b 15 16 4 4 0
a 15 15 15 15 1
c 15 15 15 15 2
1 54 54 54 54 2
1 51 51 51 51 2
s 51 51 51 51 2
再打开就会看到box有个1了 就可以insert数据了。当然你需要在jtessboxeditor里从新打开一遍这个数据,不然还是看不到。
6、生成font_properties文件
同样的地方cmd
echo arial 0 0 0 0 0 >font_properties
arial对应着你的字体是什么
如果创建完发现font_properties文件的大小是0,没有写入东西,可以打开强行写入 arial 0 0 0 0 0
7、使用tesseract生成tr训练文件
tesseract num_eng.arial.exp0.tif num_eng.arial.exp0 nobatch box.train
8、生成字符集文件:
unicharset_extractor num_eng.arial.exp0.box
9、生成shape文件:
shapeclustering -F font_properties -U unicharset -O num_eng.unicharset num_eng.arial.exp0.tr
10、生成聚字符特征文件
mftraining -F font_properties -U unicharset -O num_eng.unicharset num_eng.arial.exp0.tr
11、生成字符正常化特征文件
cntraining num_eng.arial.exp0.tr
会生成normproto文件,然后对四个文件从命名一下,分别是inttemp、pffmtable、shapetable、normproto
rename normproto num_eng.normproto
rename inttemp num_eng.inttemp
rename pffmtable num_eng.pffmtable
rename shapetable num_eng.shapetable
命名规则就是[lang].xxx
12、合并训练文件
combine_tessdata num_eng.
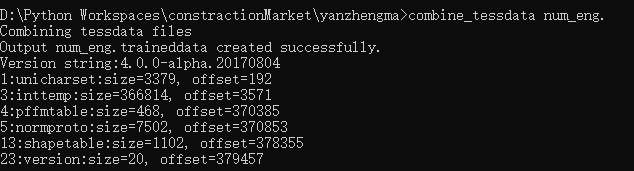
如果你出现了-1,就说明你哪个步骤出现了错误,检查一下是不是打错字了,然后从新做一遍吧兄嘚
如果没有-1就说明你成功了,把这个traineddata复制到你存放tesseract-OCR文件的tessdata下(好像还要放到python里的tessdata下)
大功告成!!!!!!!!!!!!!!!!!!!!!!
之后再用我之前的代码在新的文件夹生成100个新的验证码做新投入的数据,与训练数据的正确率做对比。再与官方的eng 语言做一下对比,你就知道时间没有白费啦,接下来上图!

这是自带的eng语言跑训练数据的正确率,很真实有木有

这是我使用我自己的训练后的data再跑训练数据

然后是自带的eng跑新投入的数据:更真实了呢
最后重点来了,我的traineddata跑新投入的数据,这个成功率也就代表了如果你遇到这样的验证码,你的成功率是多少!

百分之48,怎么样,是不是觉得之前的投入都值得了哈哈,安装tesseract真的很坑爹,一点都不友好,各种不一样的坑。手动调整数据的时候也是心累啊,一定要认真对待数据标注员这种工种,说不定啥时候就瞎了哈哈。这个结果也就意味着一百个网页有一百个验证码跑100秒的话,你只需要200秒就能结束战斗了,对于这样的结果我个人觉得还是很好的,对于个人来说也相当够用了。
当然各位想要再高一点还是有办法的
FIRST:继续大量投入测试数据,一两百个对于电脑来说根本不能很好的训练到什么,一两百万就差不多了哈哈,这样的话就是公司级别的。大量投入训练数据再由标注员去一点点整很久
SECOND: 自己写一个专门的应对验证码的神经网络,从造轮子开始,最后的结果我见到的高的有96%,甚至能分辨拉伸字体噪点噪线后的O 0 o的区别,这根本连我自己都分不清好不好!!
当然,这些图都是直接投入进去的,灰化二值化之后肯定会有更好的表现,但是二值化的值要随着背景颜色的改变而改变,光灰化不二值化有的验证码压根都看不见字母在哪了。所以我这次也是直接原封不动投入训练数据里。
而且对于不同的网站有不同的验证码,有时候并不能做到很好的识别。还是要针对性的投入训练数据。
总之,学习路上还是要加油啦。这次成功很有成就感,下次我准备学习反编译安卓啦,下次就发反编译安卓的blog!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









