






 快手AI团队的自研大模型「快意」(KwaiYii)进行内测,包含预训练和对话模型,尤其13B版本在多项指标上接近或优于ChatGPT。团队计划持续优化并拓展多模态及商业应用。
快手AI团队的自研大模型「快意」(KwaiYii)进行内测,包含预训练和对话模型,尤其13B版本在多项指标上接近或优于ChatGPT。团队计划持续优化并拓展多模态及商业应用。
快手自研的大语言模型 “快意”(KwaiYii)已开启内测,并为业务团队提供了标准 API 和定制化项目合作方案。
根据官方介绍,「快意」大模型(KwaiYii) 是由快手 AI 团队从零到一独立自主研发的一系列大规模语言模型(Large Language Model,LLM),当前包含了多种参数规模的模型,并覆盖了预训练模型(KwaiYii-Base)、对话模型(KwaiYii-Chat)。
其中 KwaiYii-13B 主要特点包括:
- KwaiYii-13B-Base 预训练模型具备优异的通用技术底座能力,在绝大部分权威的中 / 英文 Benchmark 上取得了同等模型尺寸下的 State-Of-The-Art 效果。例如,KwaiYii-13B-Base 预训练模型在 MMLU、CMMLU、C-Eval、HumanEval 等 Benchmark 上目前处于同等模型规模的领先水平。
- KwaiYii-13B-Chat 对话模型具备出色的语言理解和生成能力,支持内容创作、信息咨询、数学逻辑、代码编写、多轮对话等广泛任务,人工评估结果表明 KwaiYii-13B-Chat 超过主流的开源模型,并在内容创作、信息咨询和数学解题上接近 ChatGPT (3.5) 同等水平。
KwaiYii-13B 在各大测评中表现亮眼。在最新的 CMMLU 中文向排名中,KwaiYii-13B 同时位列 five-shot 和 zero-shot 下的第一名。
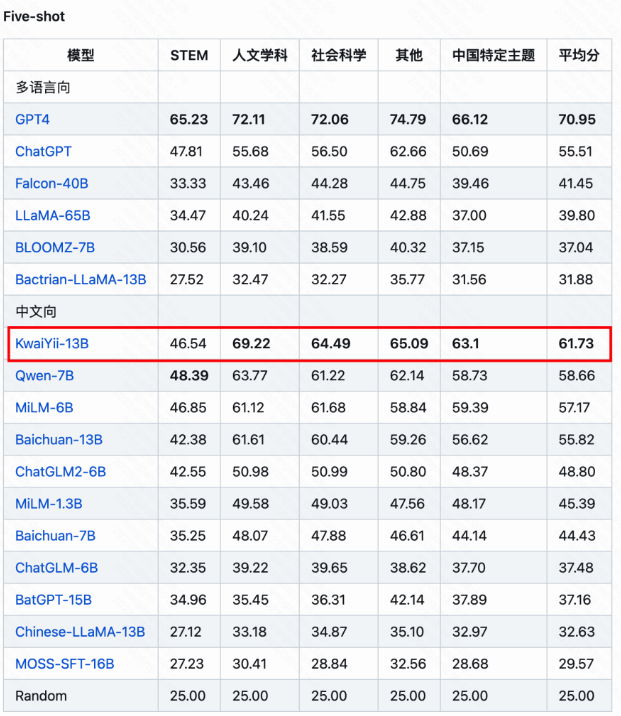
开发团队还对 KwaiYii-13B-Chat 模型以及同等参数规模的行业主流模型,均与 ChatGPT (3.5) 进行了对比和人工评估,其各自的得分如下图所示。
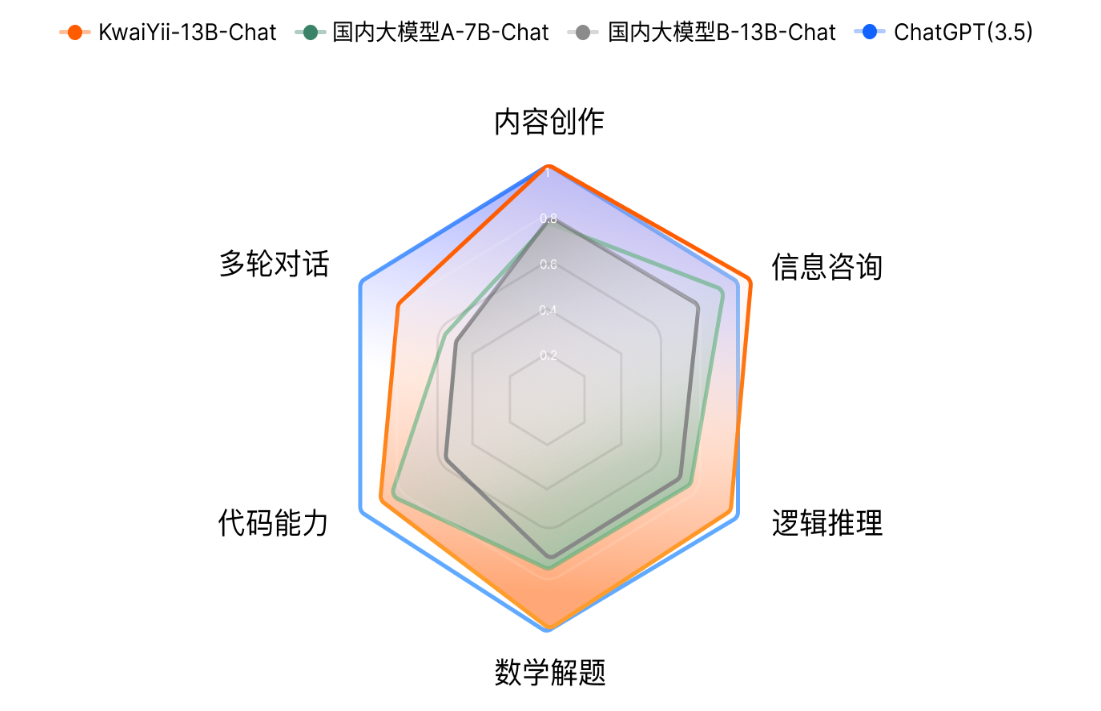
从人工评估的结果来看,KwaiYii-13B-Chat 超过了同等规模的开源模型,并接近 ChatGPT 同等水平。在内容创作、信息咨询、逻辑推理和数学解题上,基本与 ChatGPT (3.5) 效果相当。在多轮对话能力方面,KwaiYii-13B-Chat 超过同等规模的开源模型,但与 ChatGPT (3.5) 仍有一定差距。
快手 AI 团队将持续迭代 “快意” 大模型gnss,一方面将继续优化模型性能并研发多模态能力 ,另一方面也在推进更多 C 端与 B 端业务场景下的落地。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









