







一、正则表达式
1、正则表达式(Regular Expression)是通过一些特殊字符的排列,用以查找、替换、删除一行或多行字符串的一种表达式。
2、正则表达式并不是一个工具或程序,而是一种字符串处理的依据。
3、正则表达式的字符串根据表示方式的严谨度可以分为基础正则表达式与扩展正则表达式。
4、使用正则表达式时还需注意语言环境的设置,因为不同的语言环境对字符排序不一样。
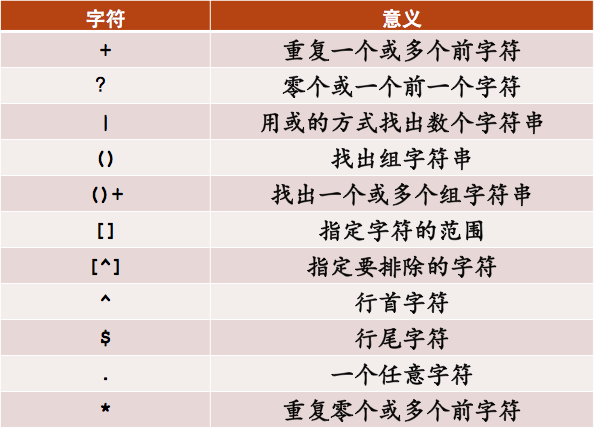
二、基本语法
常用的语法:
三、详细语法
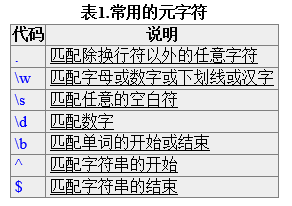
1、元字符
元字符使正则表达式具有处理能力。所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
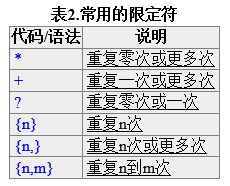
2、重复
3、反义
有时需要查找不属于某个能简单定义的字符类的字符。比如想查找除了数字以外,其它任意字符都行的情况,这时需要用到反义:

4、后向引用
后向引用用于重复搜索前面某个分组匹配的文本。例如,\1代表分组1匹配的文本。难以理解?请看示例:
\b(\w+)\b\s+\1\b可以用来匹配重复的单词,像go go, 或者kitty kitty。这个表达式首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(\b(\w+)\b),这个单词会被捕获到编号为1的分组中,然后是1个或几个空白符(\s+),最后是分组1中捕获的内容(也就是前面匹配的那个单词)(\1)。
你也可以自己指定子表达式的组名。要指定一个子表达式的组名,请使用这样的语法:(?\w+)(或者把尖括号换成’也行:(?’Word’\w+)),这样就把\w+的组名指定为Word了。要反向引用这个分组捕获的内容,你可以使用\k,所以上一个例子也可以写成这样:\b(?\w+)\b\s+\k\b。
使用小括号的时候,还有很多特定用途的语法。下面列出了最常用的一些:

5、贪婪与惰性
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:

四、常用的正则表达式
1、正则表达式 速查表
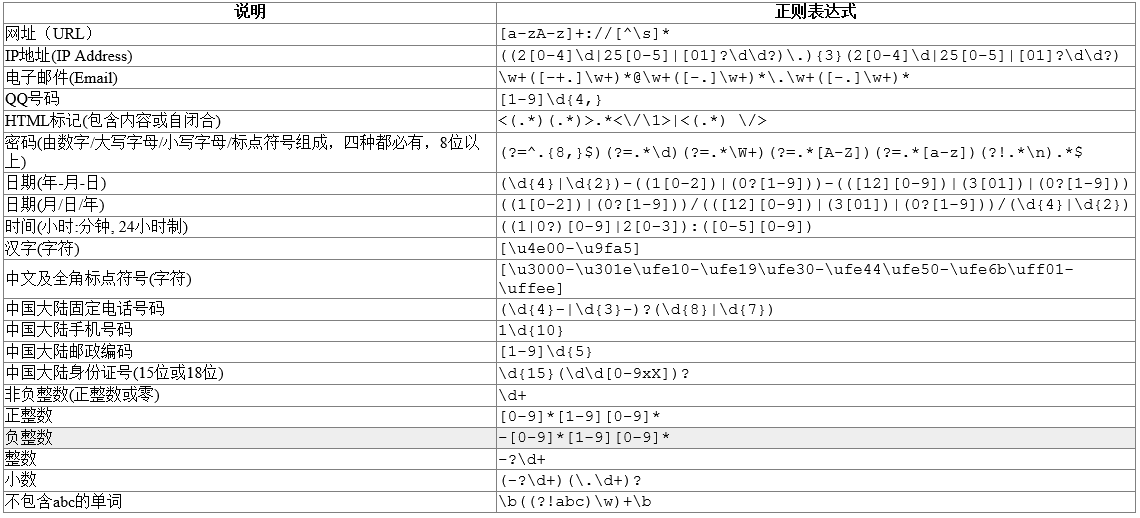
2、常用的正则表达式
正则表达式用于字符串处理、表单验证等场合,实用高效。现将一些常用的表达式收集于此,以备不时之需。
1、用户名:/^[a-z0-9_-]{3,16}$/
2、密码:/^[a-z0-9_-]{6,18}$/
3、十六进制值:/^#?([a-f0-9]{6}|[a-f0-9]{3})$/
4、电子邮箱:/^([a-z0-9_.-]+)@([\da-z.-]+).([a-z.]{2,6})$/
5、URL:/^(https?:\/\/)?([\da-z.-]+).([a-z.]{2,6})([\/\w .-])\/?$/
6、IP 地址:/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
7、HTML 标签:/^<([a-z]+)([^<]+)(?:>(.)<\/\1>|\s+\/>)$/
8、Unicode编码中的汉字范围:/^[u4e00-u9fa5],{0,}$/
9、匹配中文字符的正则表达式: [\u4e00-\u9fa5]
评注:匹配中文还真是个头疼的事,有了这个表达式就好办了
10、匹配双字节字符(包括汉字在内):[^\x00-\xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
11、匹配空白行的正则表达式:\n\s*\r
评注:可以用来删除空白行
12、匹配首尾空白字符的正则表达式:^\s*|\s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
13、匹配Email地址的正则表达式:\w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)*
评注:表单验证时很实用
14、匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求
15、匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用
16、匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}
评注:匹配形式如 0511-4405222 或 021-87888822
17、匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
18、匹配中国大陆邮政编码:[1-9]\d{5}(?!\d)
评注:中国大陆邮政编码为6位数字
19、匹配身份证:\d{15}|\d{18}
评注:中国大陆的身份证为15位或18位
20、匹配ip地址:\d+.\d+.\d+.\d+
评注:提取ip地址时有用
21、匹配特定数字:
^[1-9]\d*$ //匹配正整数
^-[1-9]\d*$ //匹配负整数
^-?[1-9]\d*$ //匹配整数
^[1-9]\d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]\d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]\d*.\d*|0.\d*[1-9]\d*$ //匹配正浮点数
^-([1-9]\d*.\d*|0.\d*[1-9]\d*)$ //匹配负浮点数
^-?([1-9]\d*.\d*|0.\d*[1-9]\d*|0?.0+|0)$ //匹配浮点数
^[1-9]\d*.\d*|0.\d*[1-9]\d*|0?.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]\d*.\d*|0.\d*[1-9]\d*))|0?.0+|0$ //匹配非正浮点数(负浮点数 + 0)
评注:处理大量数据时有用,具体应用时注意修正
22、匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^\w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
3、表达式全集
| 字符 | 描述 |
|---|---|
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,“n”匹配字符“n”。“\n”匹配一个换行符。序列“\”匹配“\”而“(”则匹配“(”。 |
| ^ | 匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 |
| 美元符号 | 匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo*能匹配“z”以及“zoo”。*等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。 |
| {n} | n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
| {n,} | n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} | m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。 |
| . | 匹配除“\n”之外的任何单个字符。要匹配包括“\n”在内的任何字符,请使用像“[.\n]”的模式。 |
| (pattern) | 匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用 0… 9属性。要匹配圆括号字符,请使用“(”或“)”。 |
| (?:pattern) | 匹配pattern但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用或字符“( |
| (?=pattern) | 正向预查,在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,“Windows(?=95 |
| (?!pattern) | 负向预查,在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如“Windows(?!95 |
| x或y | 匹配x或y。例如,“z |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“p”。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。 |
| \B | 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
| \cx | 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。 |
| \d | 匹配一个数字字符。等价于[0-9]。 |
| \D | 匹配一个非数字字符。等价于[^0-9]。 |
| \f | 匹配一个换页符。等价于\x0c和\cL。 |
| \n | 匹配一个换行符。等价于\x0a和\cJ。 |
| \r | 匹配一个回车符。等价于\x0d和\cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[\f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于[^\f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于\x09和\cI。 |
| \v | 匹配一个垂直制表符。等价于\x0b和\cK。 |
| \w | 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”。 |
| \W | 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
| \xn | 匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。. |
| \num | 匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果\nm之前至少有nm个获得子表达式,则nm为向后引用。如果\nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则\nm将匹配八进制转义值nm。 |
| \nml | 如果n为八进制数字(0-3),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。 |
| \un | 匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(?)。 |















 571
571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









