






第1章 绪论
1.1 引言
机器学习:利用经验来改善系统自身的性能(经验通常以数据形式存在)
机器学习研究的主要内容:关于在计算机上从数据中产生“模型”的算法,即学习算法
算法:从数据中学得“模型”的具体方法,eg:线性回归、决策树等
模型:算法产出的结果,通常是具体的函数或者可抽象地看作为函数,eg:一元线性回归算法产出的模型即为形如f(x)=wx+b的一元一次函数
1.2 基本术语
数据决定模型的上限,而算法则是让模型无限逼近上限
数据集;训练,测试
示例,样例
样本
属性,特征;属性值
属性空间,样本空间,输入空间
特征向量
标记空间,输出空间
概率近似正确理论(PAC,Probably Approximately Correct):以很高的概率得到很好的模型
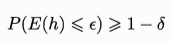
泛化能力:可理解为“推广”,即对新数据处理的能力
**通常假设样本空间服从一个未知分布,而我们收集到的每个样本都是独立地从该分布中采样得到,即独立同分布。只有i.i.d.,才能用独立随机事件出现的频率去逼近概率
1.3 假设空间
假设:指我们学到的这个模型(即f(x))
对于一个问题,可以生成很多假设,真实的假设即为”真相“(即y)
版本空间:所有能够拟合训练集的模型构成的集合(而类似”一元一次函数“,为假设空间)
1.4 归纳偏好
归纳偏好:机器学习算法在学习过程中对某种类型假设的偏好
奥卡姆剃刀原则:若有多个假设与观察一致,则选最简单的那个(但是何为简单便见仁见智了)
NFL没有免费午餐定理:
一个算法la若在某些问题上比另一个算法lb好,则必存在另一些问题lb比la好
(重要前提:所有问题出现的机会相同、或所有问题同等重要)
NFL定理最重要的寓意,是让我们清楚地认识到,脱离具体问题,空泛谈论”什么学习算法更好“毫无意义
1.5 发展历程
深度学习:”很多层“的神经网络
火热的两个基本原因:数据大了、计算能力强了
深度学习模型拥有大量参数,若数据样本少,则很容易”过拟合“;如此复杂的模型、如此大的数据样本,若缺乏强力计算设备,根本无法求解
第2章 模型评估与选择
2.1 经验误差与过拟合
错误率:分类错误的样本数占样本总数的比例
精度:1-错误率
误差:学习器的实际预测输出与样本的真实输出之间的差异
(训练/经验误差:在训练集上的误差;泛化误差:在新样本上的误差)
希望得到泛化误差小的学习器
过拟合:学习器把训练样本学得“太好”了,很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,导致泛化性能下降
【学习能力过于强大,把训练样本所包含的不太一般的特性都学到了。过拟合是机器学习面临的关键障碍,无法彻底避免,只能缓解】
欠拟合:对训练样本的一般性质尚未学好
【通常由于学习能力低下造成,比较容易克服】
2.2 评估方法
以测试集上的“测试误差”作为泛化误差的近似
测试集应该尽可能与训练集互斥,即测试样本尽量不在训练集中出现、未在训练过程中使用过
2.2.1 留出法
直接将数据集D划分为两个互斥的集合,即train_test_split函数的做法
需注意:
训练/测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响。eg:在分类任务中至少要保持样本的类别比例相似
不同划分将导致不同的训练集和测试集,评估结果也会有所差异。因此,单次使用留出法得到的估计结果往往不够稳定可靠,一般要采用若干次随机划分、重新进行实验评估后取平均值作为留出法的评估结果
测试集小时,评估结果的方差较大;训练集小时,评估结果的偏差较大。常见做法是将大约2/3~4/5的样本用于训练,剩余样本用于测试
2.2.2 交叉验证法
先将数据集D划分为k个大小相似的互斥子集,每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集;这样就可获得k组训练/测试集,从而可进行k次训练和测试,最终返回的是这k个测试结果的均值【k最常用的取值为10,或者5、20等】
2.2.3 自助法
有放回的随机采样
样本始终不会被采到的概率:0.368
可将采样数据集用作训练集,初始数据集\采样数据集用作测试集


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









