








淘宝是中国最大的在线购物平台,有丰富的数据可供抓取。以下是一些值得抓取的数据以及通过API可以获取到的数据:
1. 商品信息:包括商品标题、价格、销量、评价等。
2. 店铺信息:包括店铺名称、店铺信用、开店时间等。
3. 物流信息:包括运费、发货地址、配送方式等。
4. 评价信息:包括商品评价内容、评分、评论人信息等。
5. 交易信息:包括订单号、交易状态、付款情况等。
6. 广告推荐信息:包括推荐位商品、热门商品等。
通过淘宝开放平台的API,可以获取到以下数据: 进入测试页

1. 搜索接口:可以根据关键词搜索商品,并返回相关商品列表。
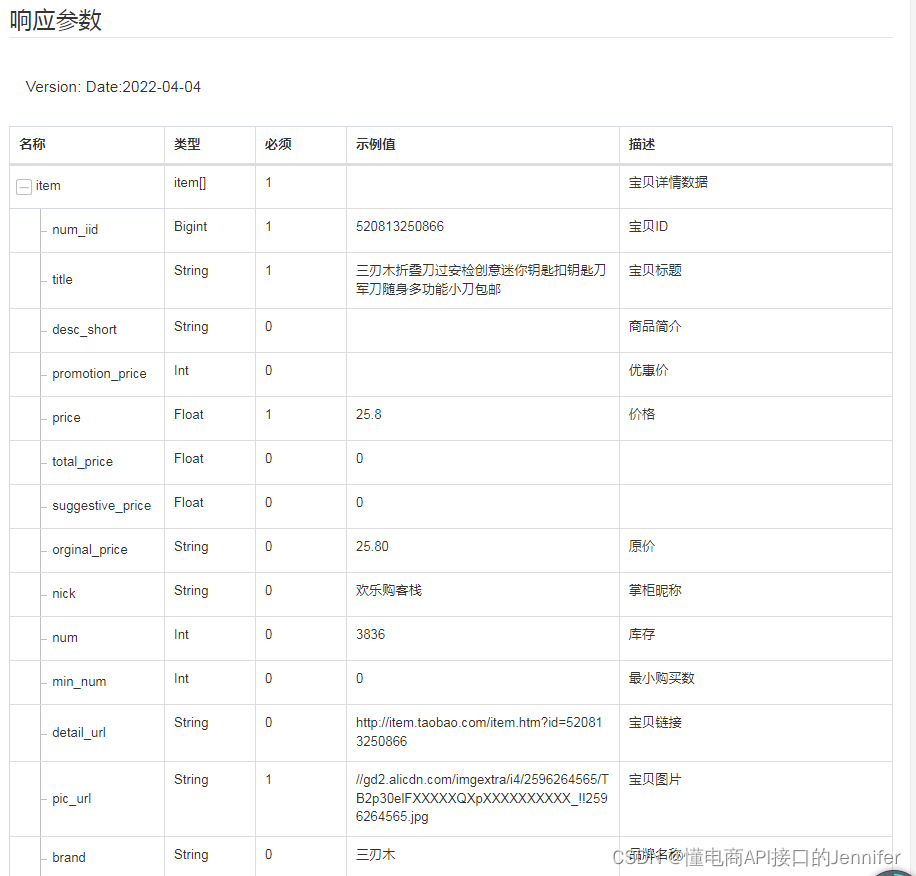
item_get商品详情响应参数
2. 商品详情接口:可以根据商品ID获取商品的详细信息。
3. 店铺详情接口:可以根据店铺ID获取店铺的详细信息。
4. 物流接口:可以查询订单的物流信息。
5. 评价接口:可以获取商品的评价信息。
6. 交易接口:可以获取订单的详细信息。
需要注意的是,淘宝开放平台的API需要进行认证和授权才能使用,具体使用方法可以参考淘宝开放平台的文档和接口调用指南。同时,在使用API获取数据时,需要遵循淘宝开放平台的规则和限制,不得违反相关法律法规。















 951
951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









