







全分布安装
节点分布
| NN | SNN | DN | |
|---|---|---|---|
| node01 | * | ||
| node02 | * | * | |
| node03 | * | ||
| node04 | * |
准备工作
- 每台安装jdk
- 同步4台的时间
date -s "20XX-XX-XX XX:XX:XX" - 每台
cat /etc/sysconfig/network查看hosting name和hostname有没有配置好 - 每台
cat /etc/hosts查看host有没有配置好(节点名称到ip的映射) - 每台
cat /etc/sysconfig/selinux查看是否SELINUX=disabled - 关闭防火墙
分发密钥(ssh)
- 首先
cd ~并ll -a查看是否所有节点都有.ssh文件,没有则在每个节点ssh localhost - 在NameNode中进入.ssh文件夹输入
scp id_dsa.pub node02:`pwd`/node01.pub在node02节点[root@node02 .ssh]# cat node01.pub >> authorized_keys(改名是为了防止别的公钥覆盖)
修改hadoop配置文件
-
[root@node01 .ssh]# cd /opt/sxt/hadoop-2.6.5/etc/hadoop/ -
先进行备份
[root@node01 etc]# cp -r hadoop/ hadoop_pseudo -
[root@node01 hadoop]# vi core-site.xml<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://node01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/var/sxt/hadoop/full</value> </property> </configuration> -
[root@node01 hadoop]# vi hdfs-site.xml修改副本数和SNN的名称<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node02:50090</value> </property> </configuration> -
[root@node01 hadoop]# vi slavesnode02 node03 node04 -
给每个节点分发hadoop包
[root@node01 opt]# scp -r sxt/ node04:`pwd -
给每个节点分发NameNode配置好的环境变量
[root@node01 opt]# scp /etc/profile node02:/etc/ -
让每个节点的profile生效
. /etc/profile
启动集群
-
先进行格式化操作,在NamenNode中
[root@node01 opt]# hdfs namenode -format -
启动节点
[root@node01 dfs]# start-dfs.sh,启动成功将显示[root@node01 dfs]# start-dfs.sh Starting namenodes on [node01] node01: starting namenode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-namenode-node01.out node04: starting datanode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-datanode-node04.out node03: starting datanode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-datanode-node03.out node02: starting datanode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-datanode-node02.out Starting secondary namenodes [node02] node02: starting secondarynamenode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-secondarynamenode -node02.out -
在每个节点中输入jps查看是否启动正确,NameNode中应仅有NameNode进程,SNN中应有DataNode和SecondDataNode两个进程,DataNode仅有DataNode进程,若搭建错误,则需查看日志文件
[root@node01 dfs]# cd /opt/sxt/hadoop-2.6.5/中的logs文件夹[root@node02 logs]# tail hadoop-root-datanode-node02.log -
[root@node01 hadoop-2.6.5]# ss -nal网页上可视化节点信息
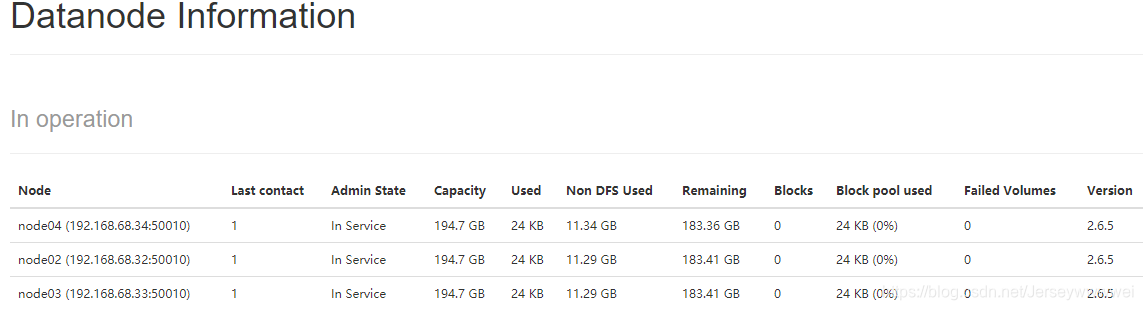
- 创建文件进行测试
[root@node01 hadoop-2.6.5]# hdfs dfs -mkdir -p /usr/root
测试
-
[root@node01 software]# for i in `seq 100000`;do echo "hello sxt $i" >> test.txt;done -
将文件切块上传
[root@node01 software]# hdfs dfs -D dfs.blocksize=1048576 -put test.txt /usr/root -
在DataNode中查看上传文件被切割之后的信息
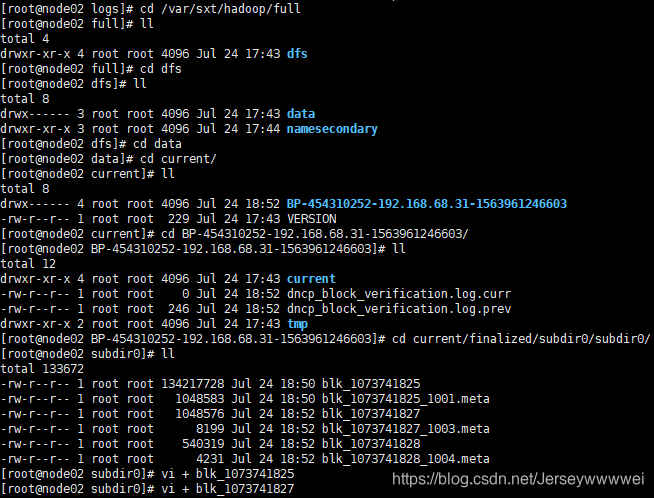
-
删除上传的文件
[root@node01 software]# hadoop fs -rm /usr/root/hadoop-2.6.5.tar.gz














 2468
2468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









