







论文笔记:Dense Contrastive Learning for Self-Supervised Visual Pre-Training
ABSTRACT:
背景:主流的自监督模型都被设计和优化image classification。 但是预训练模型用于预测dense predication task的优化做的不太好,这是由于在image level和piexl level的prediction存在着差异。
dense prediction tasks:predicting a label for each pixel in the images.
我们的工作:为了弥补上这个gap,我们目标设计一个高效率,dense自监督学习(直接在pixel level上工作/或者说local feature),通过考虑到 local feature相互之间的联系。我们通过dense对比学习,通过正负样本在pixel level来进行训练优化。

Introduction:
背景1:在计算机视觉中pre-training一直是被公认的优秀cv任务。在一个预训练任务中,模型一般在巨大的数据集上进行预训练,然后在目标任务中(少的数据)进行微调。更具体的说,监督学习在imagenet上进行预训练解决分类问题,之后transferred到下游任务上。
困难和挑战:然而,在在预训练的分类任务和目标任务 dense prediction tasks — 目标检测和语义分割是存在较大差异的;前者更注重为一个输入图片分配他的类别,而后者需要对整张输入图片逐像素的进行分类和回归。 eg:语义分割目标对每个像素分配一个类别,目标检测检测目标预测一个类别和预测bbox,对每个目标进行分析。
背景2:直接的方法是直接对dense prediction task进行与巡礼那,然而这种task的注释是十分耗时的(逐像素)与image level的图片相比,难以制作大规模数据集来进行特征提取。
第一段由pretraining引出pixel-level的predicition task—引出困难和挑战——最后带出self-supervised learning。
背景3:无监督的兴起引发注意——从一堆没有标注的数据进行特征提取,而且有一些下游任务中发现无监督在下游任务比有监督的效果更好一些。但是困难和挑战依旧存在,第一几乎所有的自监督学习都是imagelevel,使用的是globe features(PS:globe features discribe the entire image, local feature describe the entire image patch(small group of pixels))。都用着自己的方式去辨认图片。而且更好的分类能力不一定意味着更好的目标检测能力,因此,self-supervised learning 的prediction task可以说是为他自己所定制的(因为和之后的target tasks是相同的),所以说解决了困难和挑战,remove了pretraining和target dense prediction tasks的gap。
第二段由自监督—引出我们pixel的方法—解决了困难与挑战。
背景4:受监督学习的dense prediction tasks受启发eg semantic segmentation, performs dense per-training,我们提出了dense contrastive learning 而不是使用globe image classification。 DenseCL将self supervised learning tasks 视为逐像素的对比学习,而不是去使用整个图像去进行学习。 第一,我们介绍了dense projection head,将backbone中的特征提取作为input转为特征向量,我们的方法很自然的保留了空间信息,之后构建了一个dense output 形式。与现在的global projection(head)相比(feature — global pooling — single)。第二,我们定义了positive sample of each local feature vector通过extracting对应的patch。 我们扩展了dense contrastive loss INFONCE loss来建立无监督目标函数。
architecture: contrastive learning densely使用全卷积神经网络
我们的贡献:
- pixel level 的 self-supervised learning
- pre-training 和 task 相同、高效的DenseCL
Related work:
1.self-supervised learning(pre-training)
自监督的成功离不开俩关键部分 1.contrastive learning和 2.pretext tasks。 1.contrastive learning是目前主流的模型所用的方法,正样本在相似的图片形成两个加强,负样本由不同图片所形成。2.大量的前置任务被提出来进行representation learning。例如colorization, context autoencoder。。。等,但是这些前置任务未能取得较大成功。一般来说,contrastive learning和pretext tasks一般组合到一起形成一个representation learning frame work。我们的方法是DenseCL属于自监督前置任务范例,我们很自然的将pre-training和dense prediction tasks互相结合。(segmentation and object detection)
2. pre-training for dense prediction tasks
pre-training在dense prediction tasks在取得了巨大成就,例如目标检测,语义分割。一般情况下都是在imagenet预训练后在目标任务上微调,这都是image level的识别任务。image level - yolo9000 - 在特别大的数据集下进行了预训练(比imagenet大3000倍),但是在目标任务的提升很小。最近的工作也显示了预训练使用也显示了预训练上使用目标检测的预训练可以在目标任务提升较大(与imagenet 相比)。最后几乎在dense prediction tasks几乎没有无监督的研究。
3. visual correspondence
visual correspondence是(计算像素)从两张图片中提取相同景观的结果,这个是十分重要的。在卷积神经网络也被投入了这个领域的应用。早期的工作是使用有监督学习明确的对明确的物体进行学习。
METHOD:
1.背景
self-supervised represetation learning 的baseline应该是moco -v1/v2 和 simclr都使用了自监督学习(对比学习)。在讲我们的方法前,我们先通过经典的例子简单介绍一下self-supervised learning framework。
NO1:设计准测(pipeline)
输入unlabeled dataset, 一个instance discrimination(准备泛读LEARNING DEEP REPRESENTATIONS BY MUTUAL INFORMATION
ESTIMATION AND MAXIMIZATION) pretext tasks将training数据集的图片提取出来。对于每一张图片随机进行数据增强,每一次的view代表着随机的图像增强,view是fed into an encoder for extracting feature,encoder由backbone network和project head组成。backbone在预训练结束了之后需要被转移,而训练结束后project head 会被抛弃,encoder可以被训练和优化通过一堆正负样本损失。

NO2. loss function
对比学习可被视为字典查找任务,我们的损失函数与一个contrastive loss function相似INFONCE
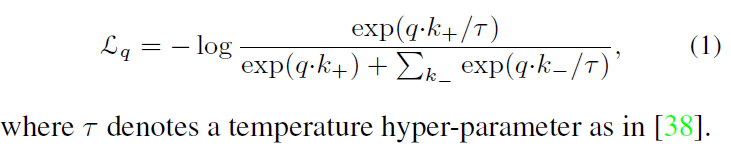
2.DenseCL Pipeline
我们提出了一种新的densecl 自监督模型。相比于之前说的mocov1v2,simclr相比,densecl与之前的不同是encoder与loss function的不同。
(前向通道逻辑)
输入一张图片,dense feature map被backbone所提取出来(eg resnet),然后跟着一个两部分组成的global projection head/dense projection head(paralled), 这个global projection head可以被实例化(eg1,2,16 的projection head)。将dense feature map作为输入产生并作为输入global projection head产生全局特征向量。(eg projection head包括global pool layer和一个MLP(由两个全连接层和relu组成))。dense projection head输入相同的input 但是输出也是dense feature vectors。 这个backbone和两个平行的projection head端对端的训练优化通过成对的pairwise contrastive dis/sim loss 在global feature和local feature。
- Dense contrastive learning
我们通过原始的contrastive loss function 展示了dense contrastive learning。 我们定义了keys{t0,t1…}给每一个encoded query r。在此时,我们的query不再代表整个图像(image level),而是encoded a local part of view (pixel level)。特别的,*Sh * Sw的feature map(由 dense project head所产生 sw sh对应feature map的长乘宽),而且我们人为的设置长宽相同(方便计算推理),所有的encoder的负样本T-由不同的patch feature vector pooled,正样本由相同图像(pixel)所提出。损失函数如下

Experimental

















 1795
1795











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









