




我们知道,对于scrapy框架来说,不仅可以单机构建复杂的爬虫项目,还可以通过简单的修改,将单机版爬虫改为分布式的,大大提高爬取效率。下面我就以一个简单的爬虫案例,介绍一下如何构建一个单机版的爬虫,并做简单修改,使其实现分布式功能。
需求分析
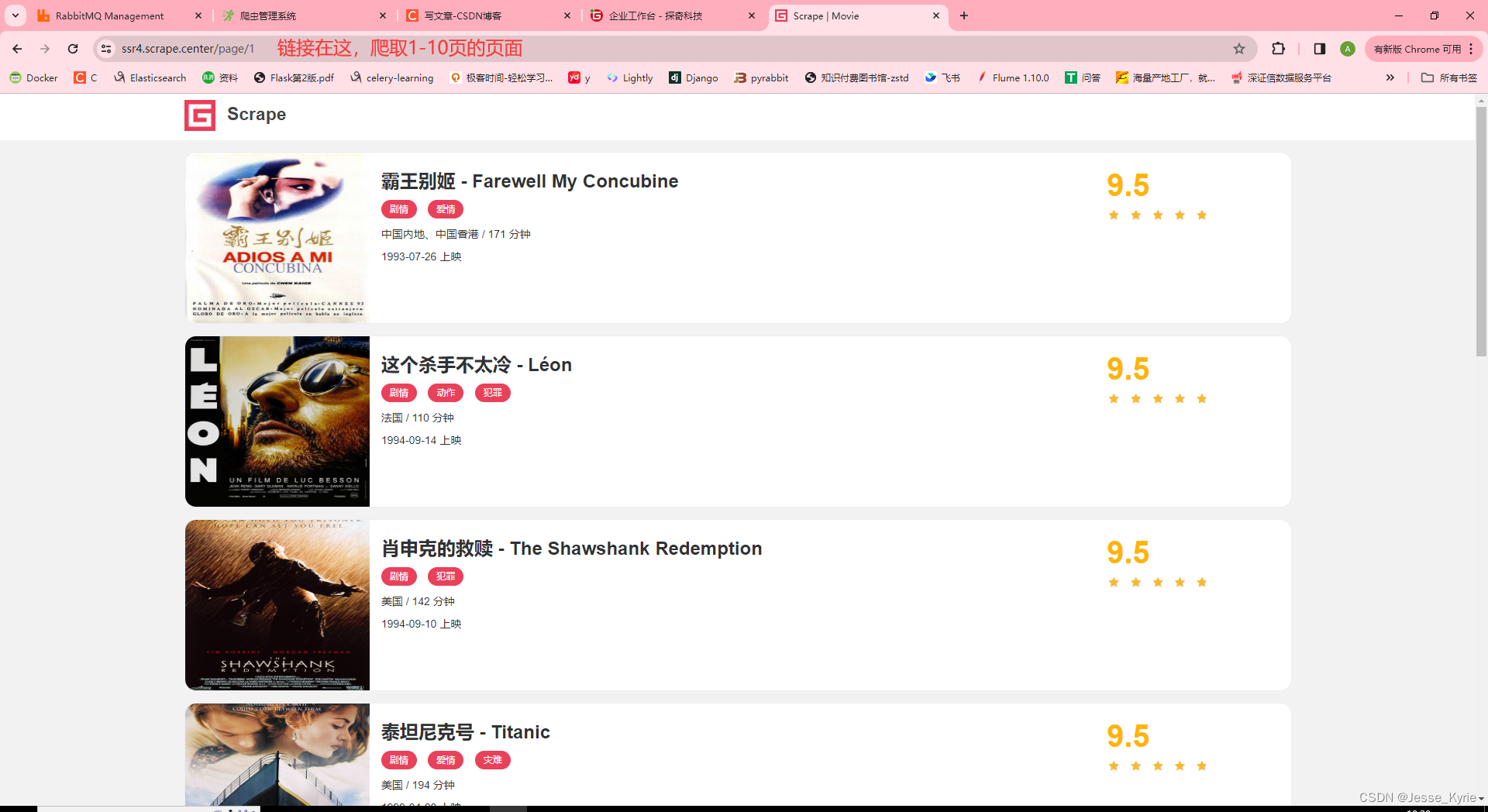
爬取的链接为点我
- 访问页面,并实现1-10页的页面爬取,并保存源码到htmls目录下
- 解析页面,并获取到图片链接,并下载图片,保存到images目录下
单机版爬虫
准备爬虫项目
使用命令构建爬虫项目
在自己的放置爬虫的目录,或新目录内运行命令scrapy startproject scrapyMovieDemo 创建一个scrapy工程
效果如下:

使用命令构建爬虫
使用cd scrapyMovieDemo命令进入已经创建的爬虫项目目录
运行scrapy genspider mv_spider_single ssr4.scrape.center命令创建基础爬虫
效果如下:

项目目录结构介绍
下面我们来看一下创建爬虫工程与创建爬虫过程中,我们的工程与项目文件结构
如下:
最外层是一个名为scrapyMovieDemo的目录
里面是一个与爬虫工程同名的目录,还有一个scrapy.cfg文件
如下:
同名目录下有一个spiders目录,里面包含所有爬虫文件【刚刚创建的mv_spider_single就在spiders目录里面】
同名目录下有items.py,middlerwares.py,pipelines.py,settings.py文件(这里只对整个爬虫开发过程中用到的文件代码进行解释)。【这些文件的介绍,请看这里简单介绍】
创建数据保存目录
在scrapy.cfg文件的同级目录创建htmls和images两个文件
创建后的结果如下:
单机爬虫代码实现
下面我通过修改mv_spider_single.py文件,实现单机爬虫!
基础代码讲解
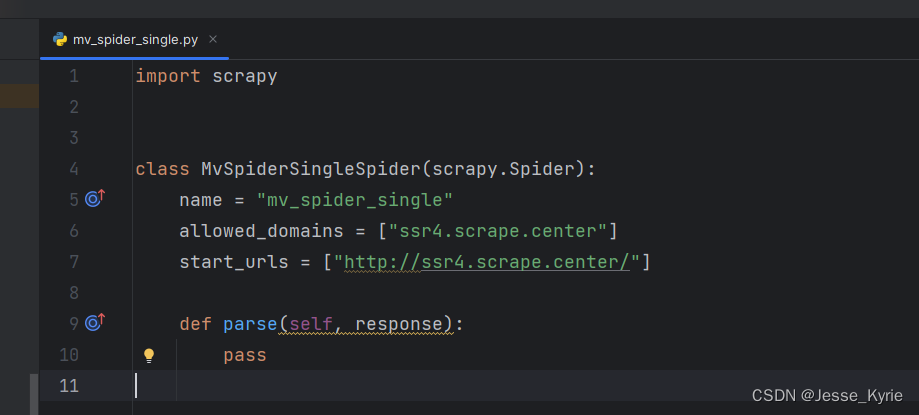
开发前,我们打开mv_spider_single.py文件,里面已经含有了一些基本的代码【如上图】。
以下是代码的逐行解释:
class MvSpiderSingleSpider(scrapy.Spider)定义了一个名为 MvSpiderSingleSpider 的 Spider 类,继承自 Scrapy 的 Spider 类。
name = "mv_spider_single"设置了爬虫的名称为 “mv_spider_single”,用于在 Scrapy 中标识该爬虫。
allowed_domains = ["ssr4.scrape.center"] 指定了允许爬取的域名,即 “ssr4.scrape.center”。
start_urls = ["http://ssr4.scrape.center/"] 设置了起始URL,即爬虫启动时首先请求的URL,这里是 “http://ssr4.scrape.center/”。
def parse(self, response)定义了 parse 方法,用于处理响应。在这个示例中,该方法为空,没有具体的爬取逻辑。
这个爬虫的功能是访问 “http://ssr4.scrape.center/” 网站,但由于 parse 方法为空,没有实际的数据爬取操作。
运行基础代码
这个scrapy自动生成的代码是可以运行的,下面我们来运行一下,看看输出什么东西。
我们在scrapy.cfg的同级目录下,运行命令scrapy crawl mv_spider_single即可运行爬虫代码。代码运行结果如下【这个结果大致浏览一下就可以,这里只是用于演示使用命令运行代码】:
(310) PS C:\Users\epro\Desktop\code\scrapy_demo\scrapyMovieDemo> scrapy crawl mv_spider_single
2024-02-20 09:13:31 [scrapy.utils.log] INFO: Scrapy 2.8.0 started (bot: scrapyMovieDemo)
2024-02-20 09:13:31 [scrapy.utils.log] INFO: Versions: lxml 4.9.1.0, libxml2 2.9.12, cssselect 1.2.0, parsel 1.7.0, w3lib 2.1.1, Twisted 22.10.0, Python 3.10.9 | pac
kaged by Anaconda, Inc. | (main, Mar 1 2023, 18:18:15) [MSC v.1916 64 bit (AMD64)], pyOpenSSL 23.0.0 (OpenSSL 3.0.8 7 Feb 2023), cryptography 39.0.2, Platform Windo
ws-10-10.0.19045-SP0
2024-02-20 09:13:31 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'scrapyMovieDemo',
'FEED_EXPORT_ENCODING': 'utf-8',
'NEWSPIDER_MODULE': 'scrapyMovieDemo.spiders',
'REQUEST_FINGERPRINTER_IMPLEMENTATION': '2.7',
'ROBOTSTXT_OBEY': True,
'SPIDER_MODULES': ['scrapyMovieDemo.spiders'],
'TWISTED_REACTOR': 'twisted.internet.asyncioreactor.AsyncioSelectorReactor'}
2024-02-20 09:13:31 [asyncio] DEBUG: Using selector: SelectSelector
2024-02-20 09:13:31 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.asyncioreactor.AsyncioSelectorReactor
2024-02-20 09:13:31 [scrapy.utils.log] DEBUG: Using asyncio event loop: asyncio.windows_events._WindowsSelectorEventLoop
2024-02-20 09:13:31 [scrapy.extensions.telnet] INFO: Telnet Password: 35be36c817707dbd
2024-02-20 09:13:31 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2024-02-20 09:13:31 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2024-02-20 09:13:31 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2024-02-20 09:13:31 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2024-02-20 09:13:31 [scrapy.core.engine] INFO: Spider opened
2024-02-20 09:13:32 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2024-02-20 09:13:32 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2024-02-20 09:13:33 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (308) to <GET https://ssr4.scrape.center/robots.txt> from <GET http://ssr4.scrape.cent
er/robots.txt>
2024-02-20 09:13:34 [scrapy.core.engine] DEBUG: Crawled (404) <GET https://ssr4.scrape.center/robots.txt> (referer: None)
2024-02-20 09:13:34 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (308) to <GET https://ssr4.scrape.center/> from <GET http://ssr4.scrape.center/>
2024-02-20 09:13:40 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://ssr4.scrape.center/> (referer: None)
2024-02-20 09:13:40 [scrapy.core.engine] INFO: Closing spider (finished)
2024-02-20 09:13:40 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 932,
'downloader/request_count': 4,
'downloader/request_method_count/GET': 4,
'downloader/response_bytes': 43026,
'downloader/response_count': 4,
'downloader/response_status_count/200': 1,
'downloader/response_status_count/308': 2,
'downloader/response_status_count/404': 1,
'elapsed_time_seconds': 8.425927,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2024, 2, 20, 1, 13, 40, 478802),
'log_count/DEBUG': 7,
'log_count/INFO': 10,
'response_received_count': 2,
'robotstxt/request_count': 1,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/404': 1,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2024, 2, 20, 1, 13, 32, 52875)}
2024-02-20 09:13:40 [scrapy.core.engine] INFO: Spider closed (finished)
修改代码实现页面爬取
下面我通过修改mv_spider_single.py文件,实现单机爬虫。
import scrapy
class MvSpiderSingleSpider(scrapy.Spider):
name = "mv_spider_single"
allowed_domains = ["ssr4.scrape.center"]
# 定义类变量start_url,用于后续请求url的构造
start_url = 'https://ssr4.scrape.center/page/{}'
def start_requests(self):
# 定义开始爬取的请求,该方法会在爬虫启动时被调用
print("start_requests")
for page in range(1, 2):
# 拼接成可用的url,实现不同页面的链接构造
url = self.start_url.format(page)
# 构造请求并指定回调函数为 parse,该函数将在响应返回时被调用
yield scrapy.Request(url=url, method='GET', callback=self.parse)
print("send page requests", url)
def parse(self, response):
file_name = 'htmls/demo.html'
with open(file_name, 'wb') as f:
f.write(response.body)
print("页面保存完毕,请查看...")
以上的代码,构造了链接为https://ssr4.scrape.center/page/1的一个请求,并提交发送。
请求响应后,调用parse函数,将响应体保存为demo.html文件。
命令启动爬虫示例
我们在scrapy.cfg的同级目录下,运行命令scrapy crawl mv_spider_single运行爬虫代码。
代码运行成功后,我们发现htmls目录下多了一个demo.html文件,里面包含刚刚请求的响应网页源码。
下面我们查看一下刚刚运行的日志:
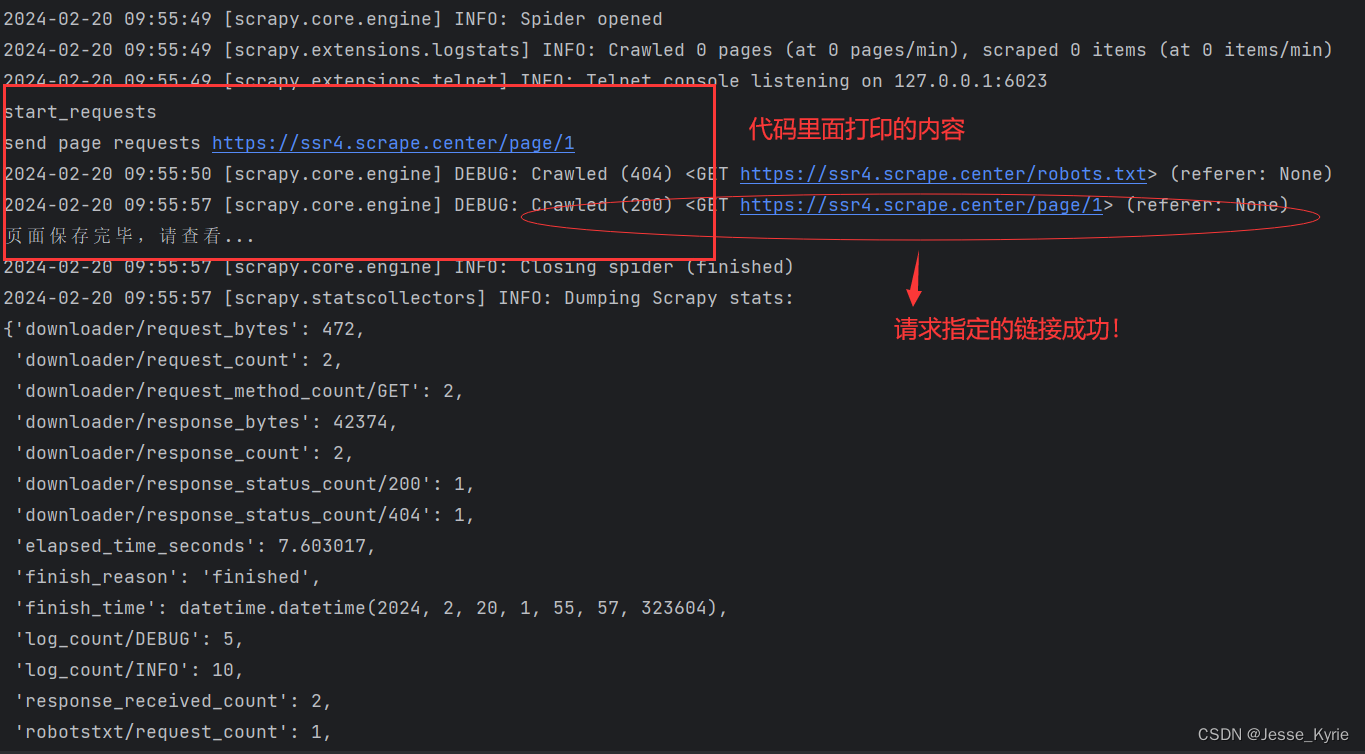
到这里,我们一个简单的单页面scrapy单机版爬虫就实现啦!!!😃
修改代码实现多页爬取
这里我们只需要在构造url时指定多个页面参数,发送多个链接,即可实现多页爬取。
查看以下代码:
class MvSpiderSingleSpider(scrapy.Spider):
name = "mv_spider_single"
allowed_domains = ["ssr4.scrape.center"]
# 定义类变量start_url,用于后续请求url的构造
start_url = 'https://ssr4.scrape.center/page/{}'
# 定义起始页与结束页
start_page = 1
end_page = 10
def start_requests(self):
# 定义开始爬取的请求,该方法会在爬虫启动时被调用
print("start_requests")
for page in range(self.start_page, self.end_page+1):
# 拼接成可用的url,实现不同页面的链接构造
url = self.start_url.format(page)
# 构造请求并指定回调函数为 parse,该函数将在响应返回时被调用
yield scrapy.Request(url=url, method='GET', callback=self.parse,meta={"page":page})
print("send page requests", url)
def parse(self, response):
# file_name = 'htmls/demo.html'
# with open(file_name, 'wb') as f:
# f.write(response.body)
# print("页面保存完毕,请查看...")
page = response.meta.get('page')
print("page", page)
# 保存响应页面源码
file_name = 'htmls/mv_spider_{}.html'.format(page)
with open(file_name, 'wb') as f:
f.write(response.body)
这里我在类变量内定义了开始页码与结束页码,同时通过for循环构造多个url,并发送请求,并在发送请求时指定了meta参数,将页码传递到response内,用于后续爬虫处理。
在parse函数内,我取出meta内的page参数,同时将响应结果的源码保存到htmls内。
再次运行爬虫脚本,获取到的日志如下:
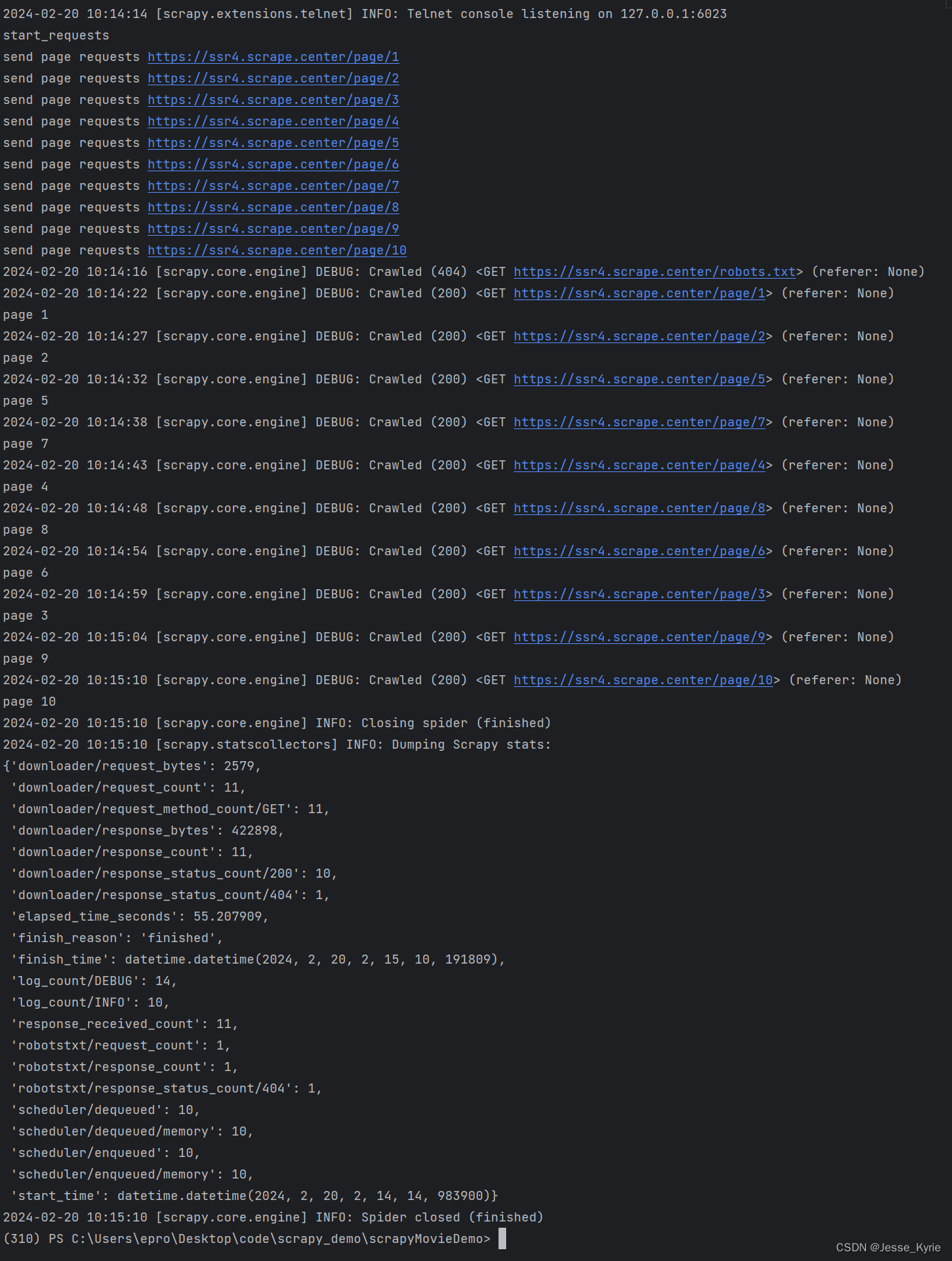
查看htmls文件夹内有10个刚刚请求的结果源码。
到这里,我们就实现了翻页请求的构造与代码运行测试。😋😋😋
解析页面深层爬取
说到解析页面,我们就要从html的结构开始说起
这是官方的解释:
HTML 结构是通过元素之间的嵌套关系来定义的。标签的嵌套和属性的使用共同构建了页面的结构和外观。开发者可以使用这些元素来创建丰富和交互性的网页。 HTML 提供了一种标准化的方式,使浏览器能够正确解释和呈现网页内容。
网页与html解析,可以看我这篇文章点我
这里我将使用xpath定位并解析数据。
xpath解析数据
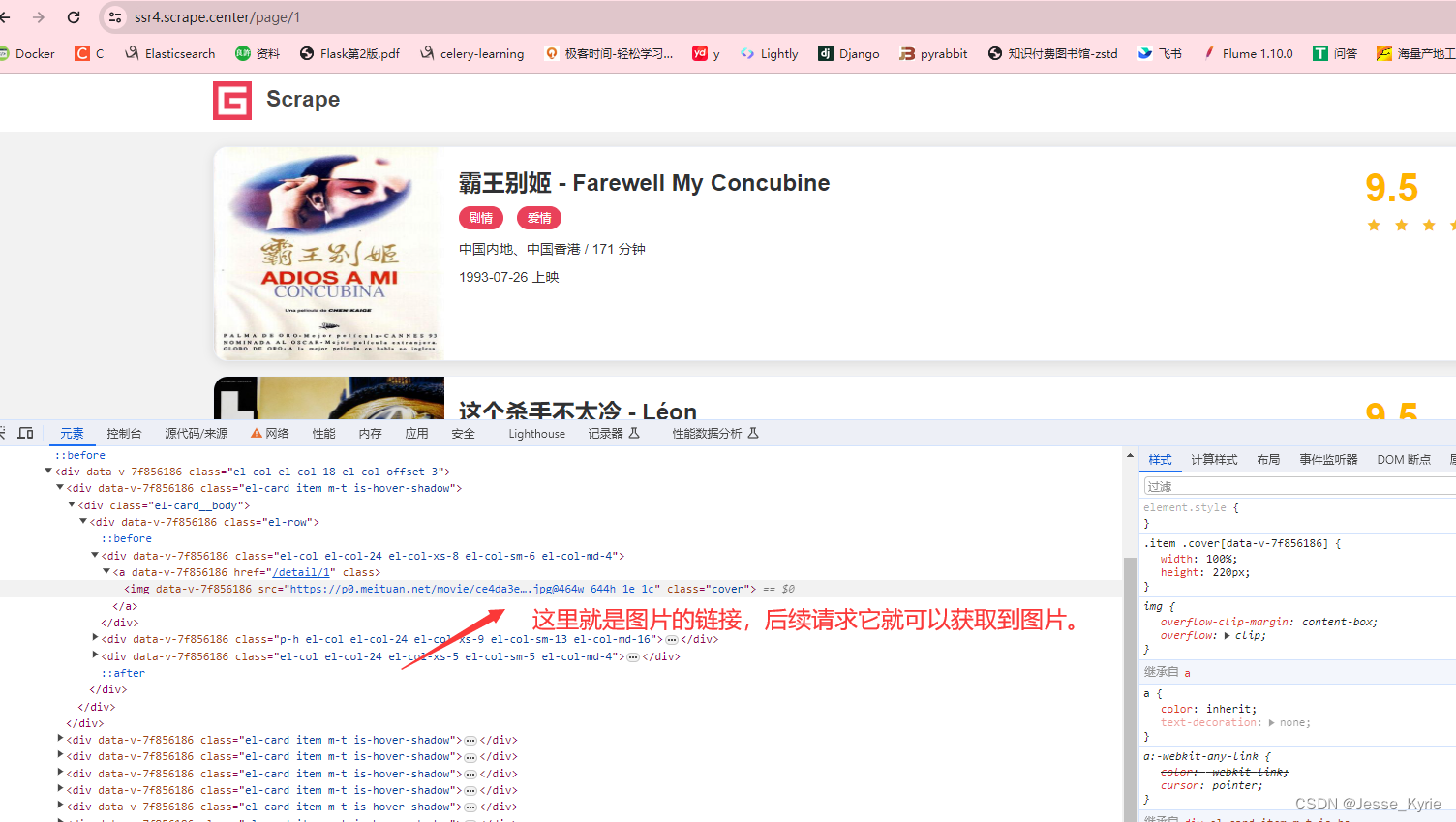
- 打开链接点这里,打开f12,选择图片,右击检查
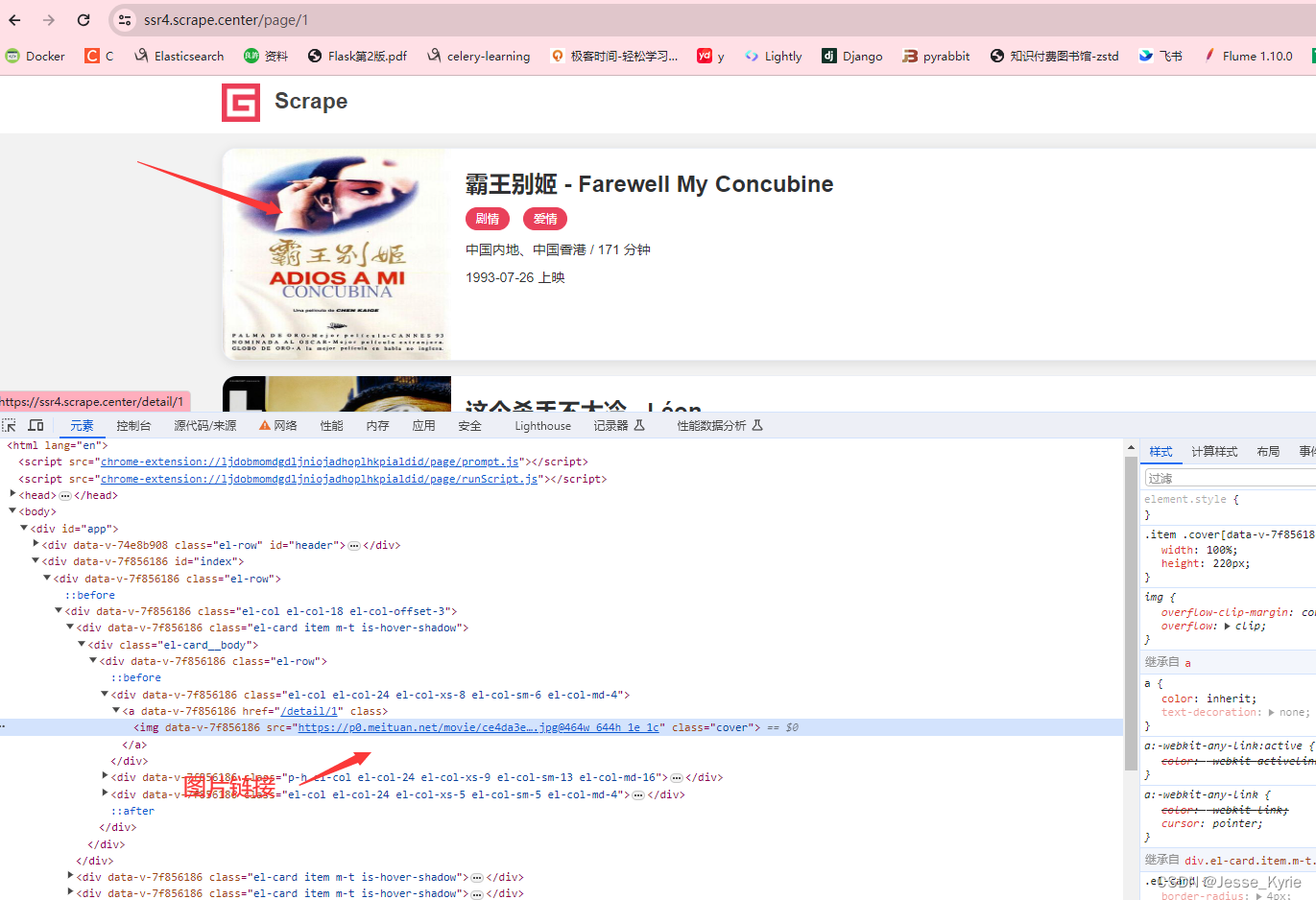
<img data-v-7f856186="" src="https://p0.meituan.net/movie/ce4da3e03e655b5b88ed31b5cd7896cf62472.jpg@464w_644h_1e_1c" class="cover">
这里我们看到了图片链接为img标签的src属性
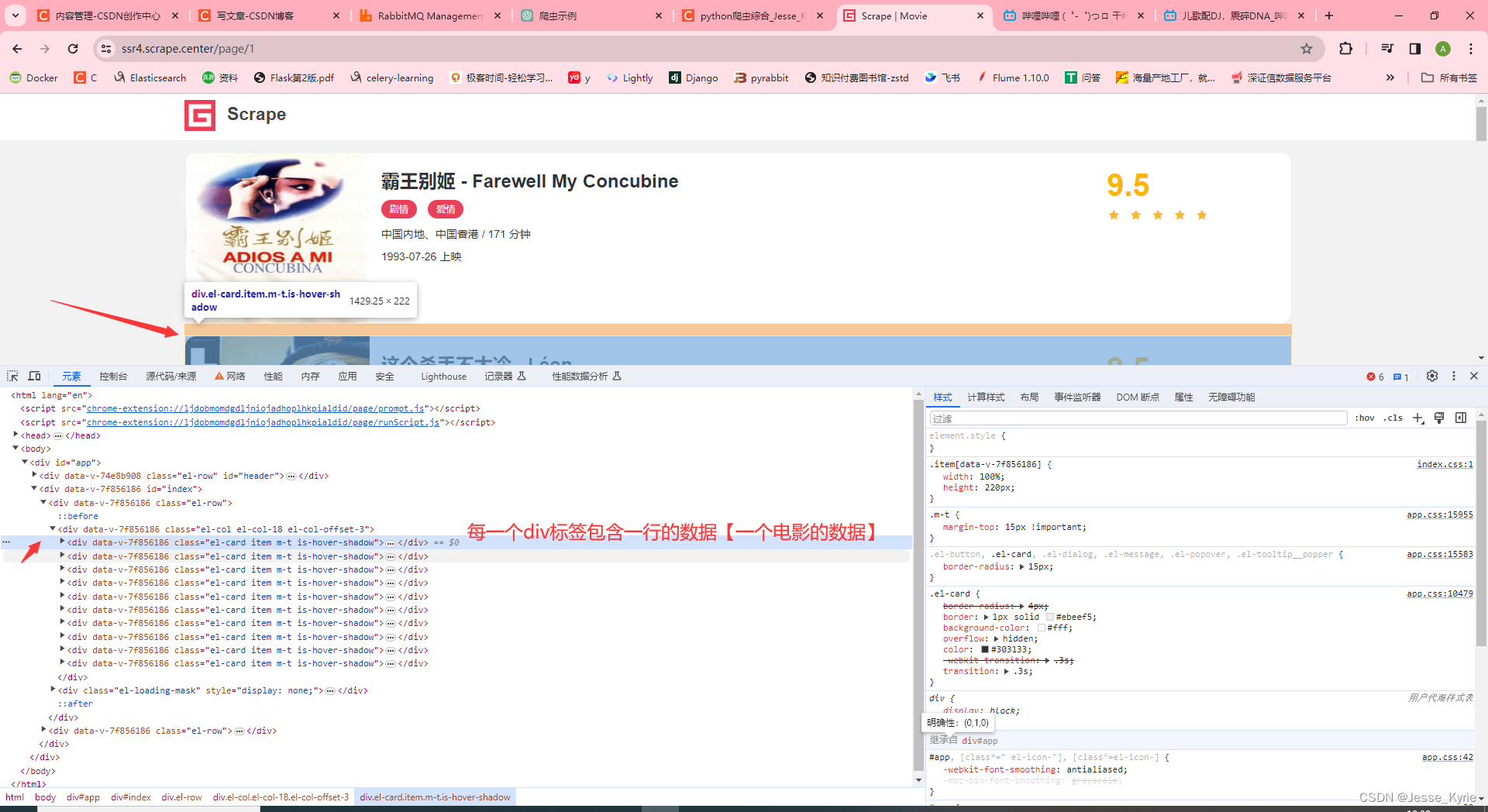
这里我们看到每个div标签包含了页面内的一行数据,可以想到我们只要使用xpath先定位到所有包含img标签的父级div标签,再遍历每个标签元素,提取img标签内的src属性即可。
构造深层爬虫
先在parse函数内添加页面解析代码,获取到图片链接
# 提取图片地址,并发送到队列用于爬虫
img_elements = response.xpath('//div[@class="el-card__body"]//img')
for img in img_elements:
src = img.xpath('@src').get()
img_name = src.split('/')[-1].split('@')[0]
# 发送图片请求
yield scrapy.Request(url=src, method='GET', callback=self.parse_img, meta={'img_name': img_name
})
print("解析完毕 发送图片请求")
再次构造解析函数,用于保存图片请求的响应【保存图片】
def parse_img(self, response):
img_name = response.meta['img_name']
file_name = 'imgs/{}'.format(img_name)
print("下载图片")
with open(file_name, 'wb') as f:
f.write(response.body)
完整的mv_spider_single.py文件里源码如下:
import scrapy
class MvSpiderSingleSpider(scrapy.Spider):
name = "mv_spider_single"
allowed_domains = ["ssr4.scrape.center"]
# 定义类变量start_url,用于后续请求url的构造
start_url = 'https://ssr4.scrape.center/page/{}'
# 定义起始页与结束页
start_page = 1
end_page = 10
def start_requests(self):
# 定义开始爬取的请求,该方法会在爬虫启动时被调用
print("start_requests")
for page in range(self.start_page, self.end_page+1):
# 拼接成可用的url,实现不同页面的链接构造
url = self.start_url.format(page)
# 构造请求并指定回调函数为 parse,该函数将在响应返回时被调用
yield scrapy.Request(url=url, method='GET', callback=self.parse,meta={"page":page})
print("send page requests", url)
def parse(self, response):
# file_name = 'htmls/demo.html'
# with open(file_name, 'wb') as f:
# f.write(response.body)
# print("页面保存完毕,请查看...")
page = response.meta.get('page')
print("page", page)
# 保存响应页面源码
file_name = 'htmls/mv_spider_{}.html'.format(page)
with open(file_name, 'wb') as f:
f.write(response.body)
# 提取图片地址,并发送到队列用于爬虫
img_elements = response.xpath('//div[@class="el-card__body"]//img')
for img in img_elements:
src = img.xpath('@src').get()
# 图片的文件名用链接里面的id来表示,如:ce4da3e03e655b5b88ed31b5cd7896cf62472.jpg
img_name = src.split('/')[-1].split('@')[0]
# 发送图片请求
yield scrapy.Request(url=src, method='GET', callback=self.parse_img, meta={'img_name': img_name
})
print("解析完毕 发送图片请求")
def parse_img(self, response):
img_name = response.meta['img_name']
file_name = 'images/{}'.format(img_name)
print("下载图片")
with open(file_name, 'wb') as f:
f.write(response.body)
运行深层爬虫代码,处理问题
运行上面的爬虫代码,查看日志
2024-02-21 07:52:15 [scrapy.core.engine] DEBUG: Crawled (404) <GET https://ssr4.scrape.center/robots.txt> (referer: None)
2024-02-21 07:52:21 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://ssr4.scrape.center/page/1> (referer: None)
page 1
2024-02-21 07:52:21 [scrapy.spidermiddlewares.offsite] DEBUG: Filtered offsite request to 'p0.meituan.net': <GET https://p0.meituan.net/movie/ce4da3e03e655b5b88ed31b
5cd7896cf62472.jpg@464w_644h_1e_1c>
解析完毕 发送图片请求
2024-02-21 07:52:21 [scrapy.spidermiddlewares.offsite] DEBUG: Filtered offsite request to 'p1.meituan.net': <GET https://p1.meituan.net/movie/6bea9af4524dfbd0b668eaa
7e187c3df767253.jpg@464w_644h_1e_1c>
解析完毕 发送图片请求
发现images文件内并没有获取到图片,日志内有如上情况。
这其实是scrapy自带的过滤器将链接为非allowed_domains下的域名下的请求过滤了,没有将其发送。要解决这个问题也很简单,只要在allowed_domains下添加图片的域名即可
添加后的结果为
allowed_domains = ['ssr4.scrape.center','p0.meituan.net']
这样再次运行爬虫,查看日志
2024-02-21 08:00:48 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://p0.meituan.net/robots.txt> (referer: None)
2024-02-21 08:00:48 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET https://p0.meituan.net/movie/27b76fe6cf3903f3d74963f70786001e143840
6.jpg@464w_644h_1e_1c>
2024-02-21 08:00:48 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET https://p0.meituan.net/movie/8959888ee0c399b0fe53a714bc8a5a17460048
.jpg@464w_644h_1e_1c>
2024-02-21 08:00:48 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET https://p0.meituan.net/movie/1f0d671f6a37f9d7b015e4682b8b113e174332
.jpg@464w_644h_1e_1c>
发现依然没有下载到图片,这里Forbidden by robots.txt 原因是没有爬虫配置内遵守了robot协议。只要我们配置不遵守robot协议即可。
这里我们需要打开spiders目录的同级文件settings.py,对里面的ROBOTSTXT_OBEY参数设置为False
settings.py内默认是True
再次运行爬虫。。
就可以获取到图片了。😆😆😆
images目录内容如下:
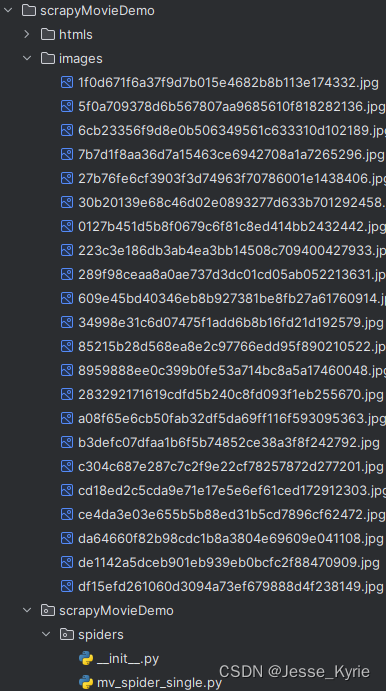
到这里我们的单机版爬虫就开发完成了,成功了一次!!😆😆😆😆😆
分布式爬虫代码实现
如何将一个单机版的爬虫改写为分布式爬虫?这个问题其实很简单,我们可以使用很多种方法改写,这里我介绍一下现在最常用的方案----基于scrapy_redis,使用redis作为爬虫的任务队列,这样多个爬虫都可以共享一个队列,实现了分布式。
修改单机爬虫为分布式的,我们需要分别修改settings.py,spiders内的爬虫文件,同时配置爬虫监听的redis队列即可。
spider修改为分布式
这里我们在定义爬虫的时候,需要继承RedisSpider类,并设置类变量名redis_key为我们监听的redis队列名【我们将请求的一些信息,放入此redis队列】。
同时我们需要定义make_request_from_data函数,这个函数是负责构造请求的,函数的参数data,就是从redis队列内弹出的一个数据,这个数据是字节码需要编码后使用。在函数内,我们将data参数使用utf8编码为字符串,然后构造了请求,并指定了解析函数。
在parse函数内,我们简单得将响应的网页源码保存为html文件。
以下为这个简单分布式爬虫的代码:
import scrapy
from scrapy_redis.spiders import RedisSpider
import json
class DistributemoviespiderSpider(RedisSpider):
name = 'mv_spider_redis'
redis_key = 'movie_queue'
# 获取redis队列数据,构造请求
def make_request_from_data(self, data):
# redis内存放的为url字节串
url = data.decode('utf8') # 解析字节串为字符串url
print("url ====>",url)
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# 保存html到data目录下
page_num = response.url.split('page/')[-1]
file_name = 'htmls/mv_spider_{}.html'.format(page_num)
with open(file_name, 'wb') as f:
f.write(response.body)
print("保存第{}页面源码到htmls目录下 ====>".format(page_num),file_name)
settings.py配置分布式方案
要想上面的爬虫代码跑起来,我们使用单机版的settings.py的配置是不行的,需要做一些修改,主要需要配置的就是调度器,redis链接,去重
在settings.py内,我们需要将SCHEDULER设置为scrapy_redis.scheduler.Scheduler,【即使用scrapy_redis包内的调度器】;我们还需要设置去重,将DUPEFILTER_CLASS设置为scrapy_redis.dupefilter.RFPDupeFilter,【即使用scrapy_redis内的去重器进行分布式去重】;最后
设置redis链接,将REDIS_URL设置为你的redis地址。
这里是我的settings.py文件,注意,每人的redis链接地址不一定相同,需要修改。
# Enables scheduling storing requests queue in redis.
BOT_NAME = "scrapyMovieDemo"
SPIDER_MODULES = ["scrapyMovieDemo.spiders"]
NEWSPIDER_MODULE = "scrapyMovieDemo.spiders"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 过滤重复request方式,避免重复爬取
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 不会清空request队列,阻塞等待downloader获取request爬取
SCHEDULER_PERSIST = True
# Schedule requests 默认使用PriorityQueue (优先队列)
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
# 设置后优先选择url的方式连接
REDIS_URL = 'redis://192.168.10.230:6379/15'
# 下载延迟
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'
}
测试分布式爬虫示例
我这里采用一台机器,开两个终端,一个终端表示一台爬虫节点。
使用scrapy crawl mv_spider_redis命令启动两个爬虫
作为演示,我在队列内塞入批量的链接,如下图:

节点1运行情况:
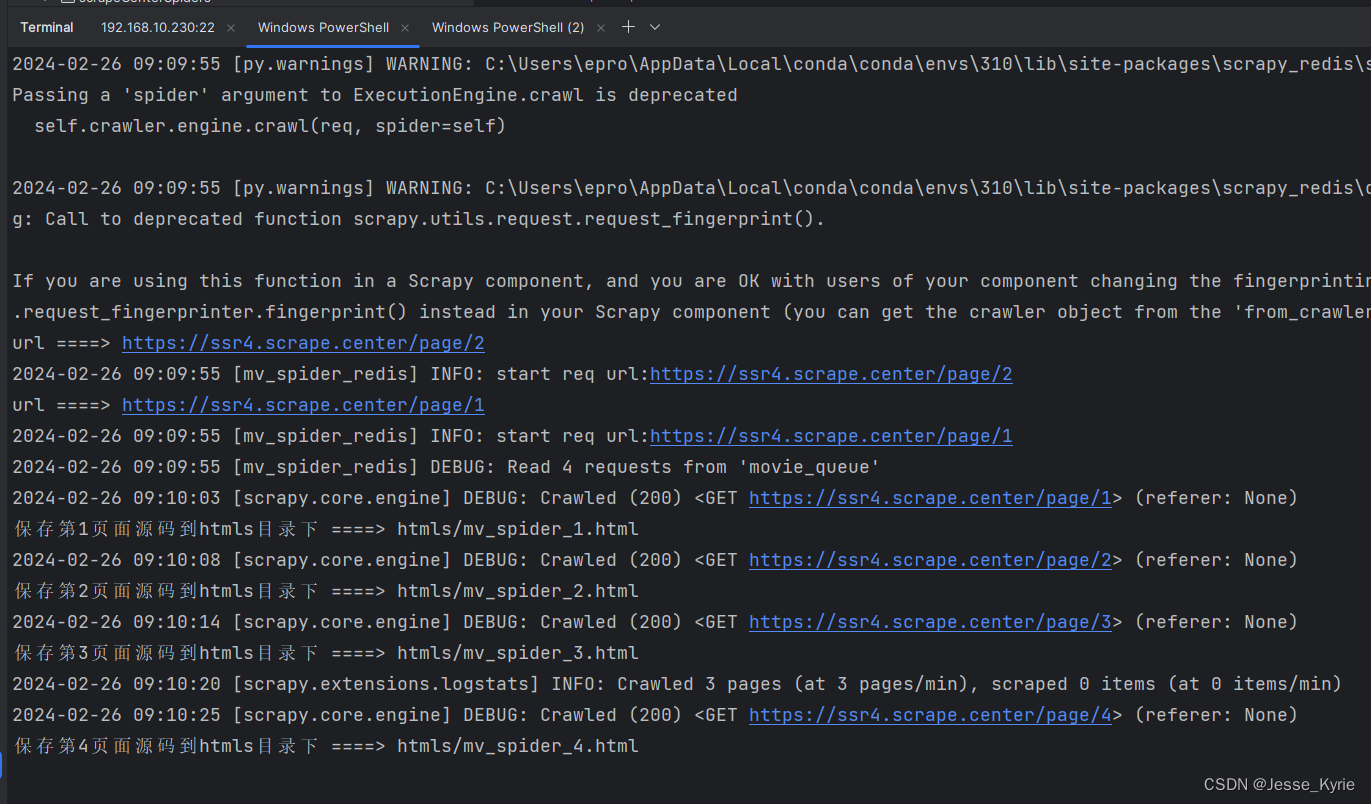
节点2运行情况:
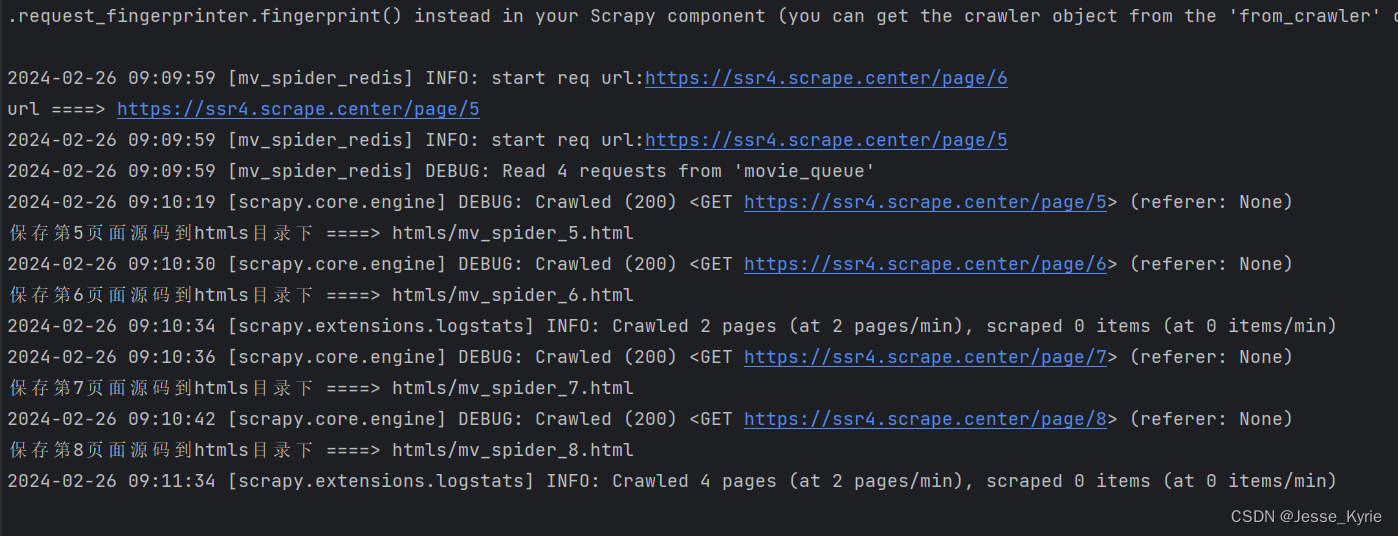
两个节点都从redis内获取到了同一个队列的不同数据,实现了分布式。我们可以通过添加更多的节点,多节点分布式爬虫,大大提高爬虫效率。
结束
这里我们回顾一下如何将单机版爬虫改为分布式爬虫?
- 需要确保我们有scrapy_redis包,如果没有需要pip安装
- 修改spiders内的爬虫文件,让其监听redis队列,并实现请求构造逻辑与解析逻辑
- 修改settings.py文件,配置redis链接,去重。


















 2146
2146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











