







P170
5.1
列举关联规则在不同领域中应用的实例。
答:在医学领域:发现某些症状与某种疾病之间的关联,为医生进行疾病诊断和治疗提供线索;在商业领域:发现商品间的联系,为商场进行商品促销及摆放货架提供辅助决策信息;在地球科学领域:揭示海洋、陆地和大气过程之间的关系。
5.2
给出如下几种类型的关联规则的例子,并说明它们是否是有价值的。
(1) 高支持度和高置信度的规则。
(2) 高支持度和低置信度的规则。
(3) 低支持度和低置信度的规则。
(4) 低支持度和高置信度的规则。
答: (1) 如牛奶>面包,由于这个规则很明显,所以不具有价值。 (2)
如牛奶->大米,由于牛奶、大米销售量都比较高,所以有高支持度。但是很多事务不同时包括牛奶和大米,所以置信度很低,不具有价值。 (3)
如可乐-洗衣粉,由于置信度低,所以不具有价值。 (4) 如尿布>啤酒,虽然支持度低,不过置信度高,具有价值。支持度(support):{X, Y}同时出现的概率
(支持度没有先后顺序之分)
置信度(confidence):购买X的人,同时购买Y的概率

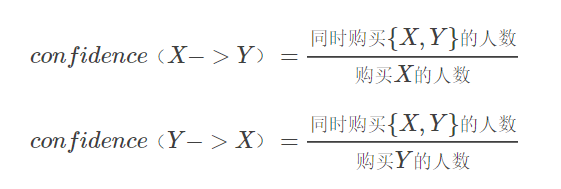
5.3
数据集如表5-14所示:
(1) 把每一个事务作为一个购物篮,计算项集 {e},{b, d} 和 {b, d, e} 的支持度。
(2) 利用 (1) 中结果,计算关联规则 {b, d} → {e} 和 {e} → {b, d} 的置信度。置信度是一个对称的度量吗?
(3) 把每一个用户购买的所有商品作为一个购物篮,计算项集 {e},{b, d} 和 {b, d, e} 的支持度。
(4) 利用 (3) 中结果计算关联规则 {b, d} → {e} 和 {e} → {b, d} 的置信度。置信度是一个对称的度量吗?

答:
(1) s({e})=8/10=0.8;
s({b,d})=2/10=0.2;
s({b,d,e})=2/10=0.2.
(2) c({b,d}->{e})=s({b,d,e}/s({b,d))= 0.2/0.2=1;
c({e}->{b,d})=s({b,d,e})/s({e})= 0.2/0.8=0.25.
由于c({b,d}->{e})≠c({e}->{b,d}),所以置信度不是一个对称的度量。
(3) 如果把每一个用户购买所有的所有商品作为一个购物篮,则
s({e})=4/5=0.8;
s({b,d}) =5/5=1;
s({b,d,e})=4/5=0.8
(4) 利用(3)中结果计算关联规则 {b, d}->{e} 和 {e)->{b,d} 的置信度,则
c({b,d}->{e})=0.8/1 = 0.8
c({e}->{b,d})=0.8/0.8=1
置信度不是一个对称的度量
5.6
考虑如下的频繁3-项集:{1,2,3},{1,2,4},{1,2,5},{1,3,4},{1,3,5},{2,3,4},{2,3,5},{3,4,5}。
(1) 根据Apriori算法的候选项集生成方法,写出利用频繁3-项集生成的所有候选4-项集。
(2) 写出经过剪枝后的所有候选4-项集。
答:
(1) 利用频繁3-项集生成的所有候选4-项集:
{1,2,3,4},{1,2,3,5},{1,2,4,5},{1,3,4,5},{2,3,4,5}
(2) 经过剪枝后的所有候选4-项集:
{1,2,3,4},{1,2,3,5}
过程如下:
因为有性质为:任何非频繁的K-1项集都不可能是频繁项集K项集的子集;
-{1,2,3,4}分裂后:{1,2,4}{2,3,4}{1,3,4}{1,2,3}均满足频繁三项集里的子集,故可作为 4-项集;
-{1,2,3,5}分裂后:{1,2,3}{1,2,5}{2,3,5}{1,3,5}均满足频繁三项集里的子集,故可作为 4-项集;
-{1,2,4,5}分裂后为{1,2,4}{2,4,5}{1,2,5}{1,4,5}其中,{1,4,5}不属于频繁3项集,所以{1,2,4,5}不能作为 4-项集;
-{1,3,4,5}分裂后为{1,3,4}{3,4,5}{1,3,5}{1,4,5}其中,{1,4,5}不属于频繁3项集,所以{1,3,4,5}不能作为 4-项集;
-{2,3,4,5}分裂后为{2,3,4}{3,4,5}{2,3,5}{2,4,5}其中,{2,4,5}不属于频繁3项集,所以{2,3,4,5}不能作为 4-项集;
Apriori算法思想
举个栗子:
我们的数据集D有4条记录,分别是134,235,1235和25。现在我们用Apriori算法来寻找频繁k项集,最小支持度设置为50%。首先我们生成候选频繁1项集,包括我们所有的5个数据并计算5个数据的支持度,计算完毕后我们进行剪枝,数据4由于支持度只有25%被剪掉。我们最终的频繁1项集为1235,现在我们链接生成候选频繁2项集,包括12,13,15,23,25,35共6组。此时我们的第一轮迭代结束。
进入第二轮迭代,我们扫描数据集计算候选频繁2项集的支持度,接着进行剪枝,由于12和15的支持度只有25%而被筛除,得到真正的频繁2项集,包括13,23,25,35。现在我们链接生成候选频繁3项集,123, 135和235共3组,这部分图中没有画出。通过计算候选频繁3项集的支持度,我们发现123和135的支持度均为25%,因此接着被剪枝,最终得到的真正频繁3项集为235一组。由于此时我们无法再进行数据连接,进而得到候选频繁4项集,最终的结果即为频繁3三项集235。
















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









