







String的基本特性
- String:字符串,使用一对""引起来表示
String s1 = "Juno99"; //字面量的定义方式
String s2 = new String("Juno99");- String声明为final,是不可被继承的
- String实现了Serializable接口,表示字符串是支持序列化的;实现了Comparable接口,表示String可以比较大小。
- String在jdk8及以前内部定义了final char[] value用于存储字符串数据。jdk9时改为byte[]加上编码标识,节约了一些空间。当然与String相关的一些类,比如AbstractStringBuilder,StringBuilder,StringBuffer也同样做了修改。
- String:代表不可变的字符序列。简称:不可变性。
1、当对字符串重新赋值时,需要重写指定内存区域赋值,不能使用原有的value进行赋值
2、当对现有的字符串进行连接操作时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值
3、当调用String的replace()方法修改指定字符或字符串时,也需要重新指定内存区域赋值,不能使用原有value进行赋值
- 通过字面量的方式(区别于new)给一个字符串赋值,此时的字符串值声明在字符串常量池中。
- 字符串常量池中是不会存储相同内容的字符串的。
- String的String Pool(又称StringTable)是一个固定大小的hashtable,JDK6及以前默认值大小长度是1009,JDK7及之后默认值大小长度是60013。如果放进String Pool的String非常多,就会造成hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是调用String.intern时性能会大幅下降,StringTable的长度越大,运行速度就会越快,因为减少了冲突次数。使用-XX:StringTableSize可设置StringTable的长度。JDK8及之后StringTable最小可设置的长度为1009.
String的内存分配
- 在Java语言中有八种基本数据类型和一种比较特殊的类型String,为了使它们在运行过程中速度更快、更节省内存,都提供了一种常量池的概念。常量池就类似于一个Java系统级别提供的缓存。八种基本数据类型的常量池都是系统协调的,String类型的常量池比较特殊,它的主要使用方法有两种:
1、直接使用双引号声明出来的String对象会直接存储在常量池中。String info = "Juno99";
2、如果不是双引号声明的,可以使用String提供的intern()方法。
- JDK6及以前,字符串常量池存放在永久代,JDK7及之后,字符串常量池调整到Java堆内。所有的字符串都保存在堆内,和其他对象一样,这样就可以在调优时仅调整堆的大小了。
String的基本操作
Java语言规范里要求完全相同的字符串字面量,应该包含同样的Unicode字符序列(包含同一份码点序列的常量),并且必须是指向同一个String类实例。

再看一个官方例子:


字符串拼接操作
- 常量与常量的拼接结果在常量池,原理是编译期优化

- 字符串常量池中不会存在相同内容的常量
- 只要其中有一个是变量,结果就在堆中,相当于在堆空间中new String(),具体内容为拼接后的结果。变量拼接的原理是StringBuilder
- 如果拼接的结果调用intern()方法,则主动将常量池中还没有的字符串对象放入池中,并返回此对象地址,当然,如果本来字符串常量池中就已经存在拼接后的字符串值的话,则直接返回常量池中的对应地址

字符串变量拼接操作的底层原理

字符串拼接操作不都是使用StringBuilder,如果拼接符号其左右两边都是字符串常量,或者常量引用,则仍然使用编译期优化。比如说下面一种情况,当待拼接的字符串变量用final修饰之后就是常量引用了,它服从的是常量的拼接原理,也就是编译期优化。因此,对于一些类、方法、基本数据类型、引用数据类型等,能用final修饰就尽量用上。

拼接操作与append操作的效率对比
下面两个方法分别用+和append进行字符串拼接操作,当highLevel=10000时,测试得知method1用时4014ms,而method2用时7ms,这是因为method1每次拼接的时候都会新建一个StringBuilder和一个String(参考上面的底层原理),而用method2只需要创建一个StringBuilder;另一方面,method1创建了过多的StringBuilder和String对象,内存占用更大,GC也要花费更多的时间。
但method2依然有改进空间,看StringBuilder源码可知,每次创建StringBuilder对象,都会创建一个容量为16的char型数组用于存储数据,如果字符串长度过长,则需要扩容,因此在实际开发中,如果基本确定前前后后要添加的字符串总长度不高于某个限定值highLevel的情况下,建议使构造器,即
StringBuilder s = new StringBuilder(hightLevel); //new char[hightLevel]
intern()的使用
如果不是双引号声明的String对象,可以使用String提供的intern()方法:intern方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中。比如:
String myName = new String("Juno").intern();也就是说,如果在任意字符串上调用String.intern方法,那么其返回结果所指向的那个类实例,必须和直接以常量形式出现的字符串实例完全相同。因此,("a"+"b"+"c").intern() == "abc" 这个表达式的值必定是true。
通俗点讲,Interned String 就是确保字符串在内存中只有一份拷贝,这样可以节约内存空间,加快字符串操作任务的执行速度。注意,这个值会被存放在字符串内部池(String Intern Pool)。
new String("ab")会创建几个对象?看字节码,就知道是两个。
一个对象是:new关键字在堆空间中创建的
另一个对象是:字符串常量池中的对象。字节码指令:ldc

new String("a")+new String("b")会创建几个对象呢?答案是五个,我们依然可以根据字节码来分析
对象1:new StringBuilder()
对象2:new String()
对象3:常量池中的“a” //将对象3的引用地址赋值给对象2
对象4:new String()
对象5:常量池中的“b” //将对象5的引用地址赋值给对象4

深入剖析的话,StringBuilder的toString()方法还创建了一个对象:
对象6:new String("ab"); //但是toString()的调用并没有使字符串常量池中生成“ab”
基于以上理解,看下面一道面试题目的分析
package com.chapter13;
public class StringIntern {
public static void main(String[] args) {
String s = new String("1"); //在堆中新建一个对象,并且StringTable中生成“1”
s.intern(); //StringTable中已存在“1”,不做任何操作
String s2 = "1"; //指向StringTable中“1”的地址
System.out.println(s == s2); //jdk6:false jdk7/8:false
String s3 = new String("1") + new String("1"); //s3变量记录的地址为堆中new String("11")的地址
//执行完上一行代码之后,字符串常量池还不存在11
s3.intern(); //在StringTable中生成“11”,但是,jdk6是在StringTable中创建一个新对象“11”,新对象的地址是不同于s3的
//jdk7及之后并没有创建新对象,而是创建一个指向堆空间中new String("11")的地址
String s4 = "11"; //s4记录的是上一行代码执行时,在StringTable中生成的指向“11”的地址
System.out.println(s3 == s4); //jdk6:flase jdk7/8:true
}
}图解:
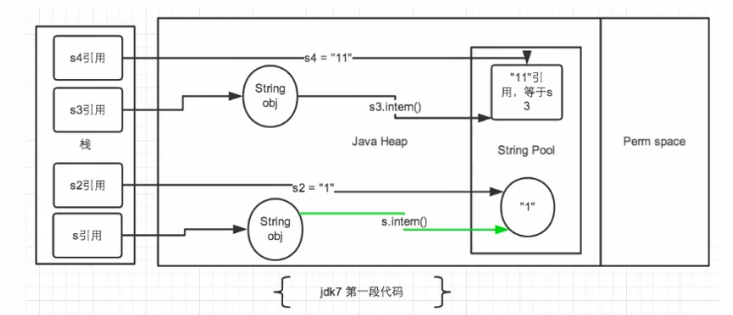
接下来咱们稍作修改,将String s4 = "11"和s3.intern()顺序调换
package com.chapter13;
public class StringIntern1 {
public static void main(String[] args) {
String s3 = new String("1") + new String("1"); //堆中new String("11")
String s4 = "11"; //在字符串常量池中生成对象“11”
String s5 = s3.intern(); //因为字符串常量池中已经存在“11”,所以不做任何操作
System.out.println(s3 == s4); //flase
System.out.println(s5 == s4); //true
}
}总结
- jdk6中,将这个字符串对象尝试放入字符串常量池。如果在字符串常量池已经存在,则不会放入,并返回已有的对象的地址;如果没有,就会把堆中new的对象复制一份,放入字符串常量池,并返回字符串常量池中该对象的地址。
- jdk7中,将这个字符串对象尝试放入字符串常量池。如果在字符串常量池已经存在,则不会放入,并返回已有的对象的地址;如果没有,则会把堆中new的对象的引用地址复制一份,放入字符串常量池,并返回字符串常量池中对应的地址。
练习:


空间效率
对于程序中大量存在的字符串,尤其是存在很多重复的字符串时,使用intern()可以节省内存空间。
大的网站平台,需要内存中存储大量的字符串。比如社交网站,很多人都存储:北京市、海淀区等信息。这时候如果字符串都调用intern()方法,就会明显降低内存的大小。
StringTable的垃圾回收
显示StringTable的空间信息的运行参数:-XX:+PrintStringTableStatics
示例可参考:https://blog.csdn.net/zhuxuemin1991/article/details/103940936
G1中的String去重操作
许多大规模的Java应用的瓶颈在于内存,测试表明,在这些类型的应用里面,Java堆中存活的数据集合差不多25%是String对象。更进一步,这里面差不多一半String对象是重复的,重复的意思是说:string1.equals(string2)= true。堆上存在重复的String对象是一种内存的浪费。这个项目将在G1垃圾收集器中实现自动持续对重复的String对象进行去重,这样能避免浪费内存。
具体实现稍作了解即可

命令行选项
UseStringDeduplication(bool):开启String去重,默认是不开启的,需要手动开启。
PrintStringDeduplicationStatistics(bool):打印详细的去重统计信息
StringDeduplicationAgeThreshold(uintx):达到这个年龄的String对象被认为是去重的候选对象














 6022
6022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









