







利用python进行网络图片下载(两种方式)
1:方式一
1:代码
# coding=utf-8
"""
@author: jiajiknag
程序功能: 图片批量下载_方式01
"""
# 导入re模块,直接调用来实现正则匹配
import re
# 导入请求模块
# 具体请参考:https://blog.csdn.net/lincifer/article/details/27374313
import urllib.request
# 定义变量url 获取要下载图片的地址
url = "http://tieba.baidu.com/p/2460150866"
# 使用urlopen()打开,read()读取并设置解码的格式
response = urllib.request.urlopen(url).read().decode('utf-8')
imglist = re.findall('src="(.+?\.jpg)" pic_ext',response)
# 定义变量x并初始化用来计数图片的张数
x = 0
# 遍历
for imgurl in imglist:
# urlretrieve() 方法直接将远程数据下载到本地。
urllib.request.urlretrieve(imgurl, "D:\yanjiusheng\Pycharm\Pycharm workStation\image_download\image\{}.jpg".format(x))
x = x + 1
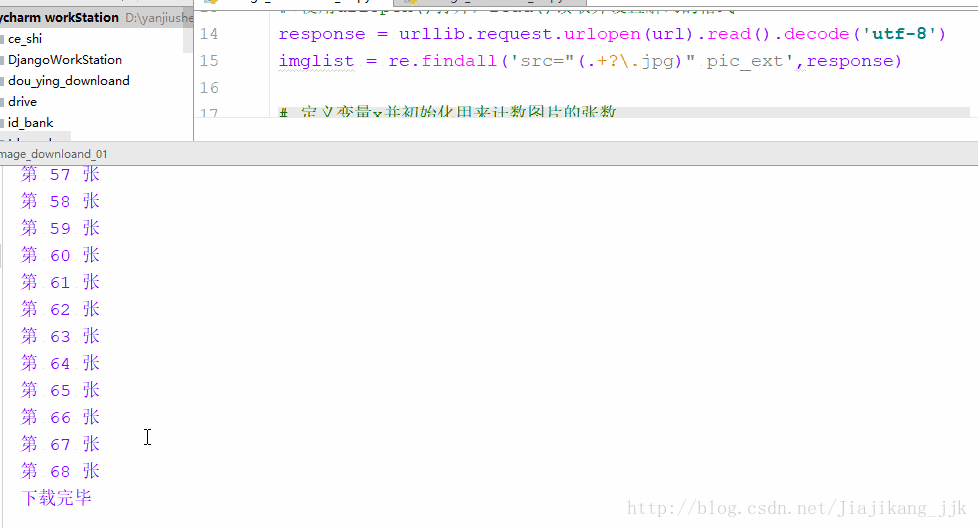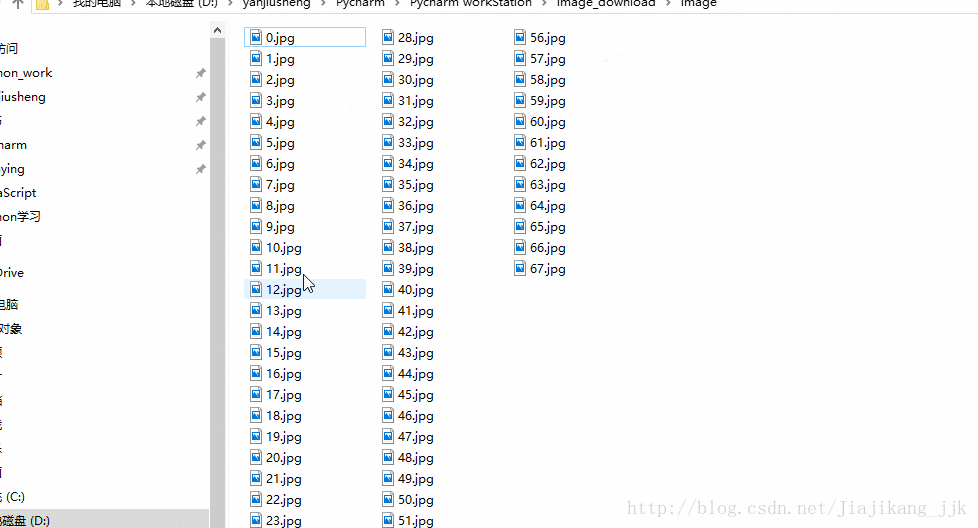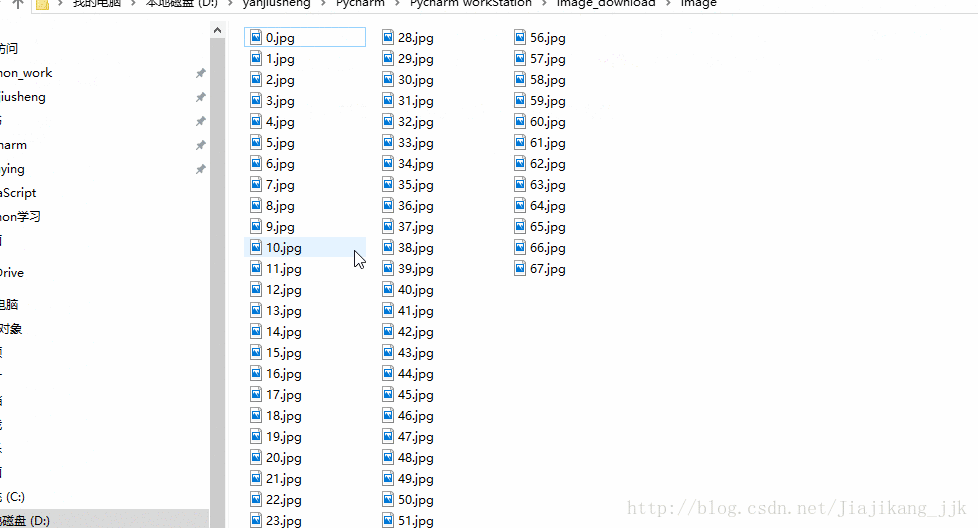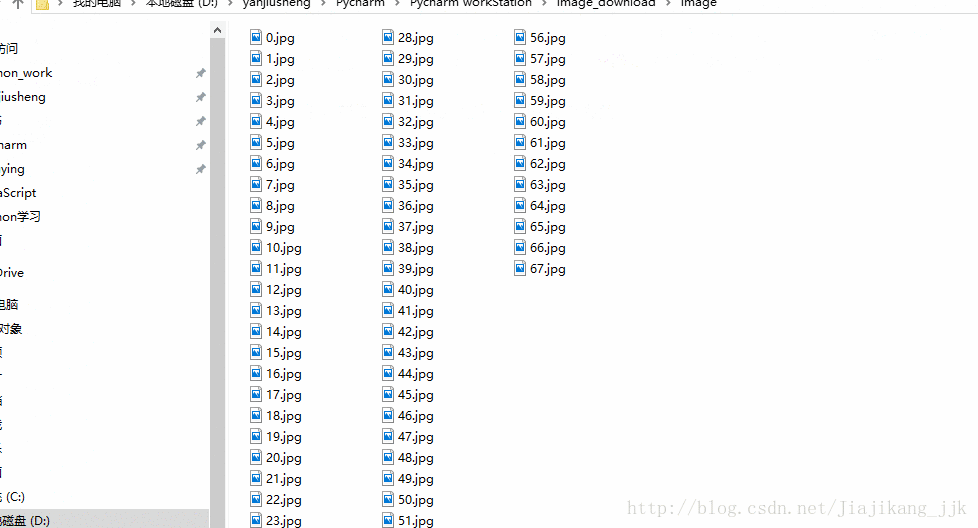
print("第", x ,"张")
print("下载完毕")
2 :结果
2:方式二
1:代码
# coding=utf-8
"""
@author: jiajiknag
程序功能:图片批量下载_方式02
"""
# 导入re模块,直接调用来实现正则匹配
import re
import requests
# 定义变量url 获取要下载图片的地址
url = "http://tieba.baidu.com/p/2460150866"
# 使用get()来获取url
r = requests.get(url)
imglist = re.findall('src="(.+?\.jpg)" pic_ext',r.text)
# 定义变量x并初始化用来计数图片的张数
x = 0
# 遍历
for imgurl in imglist:
# 获取获得的从imglist中遍历得到的imgurl
imgres = requests.get(imgurl)
with open("D:\yanjiusheng\Pycharm\Pycharm workStation\image_download\image_02\{}.jpg".format(x), "wb") as f:
f.write(imgres.content)
x +=1
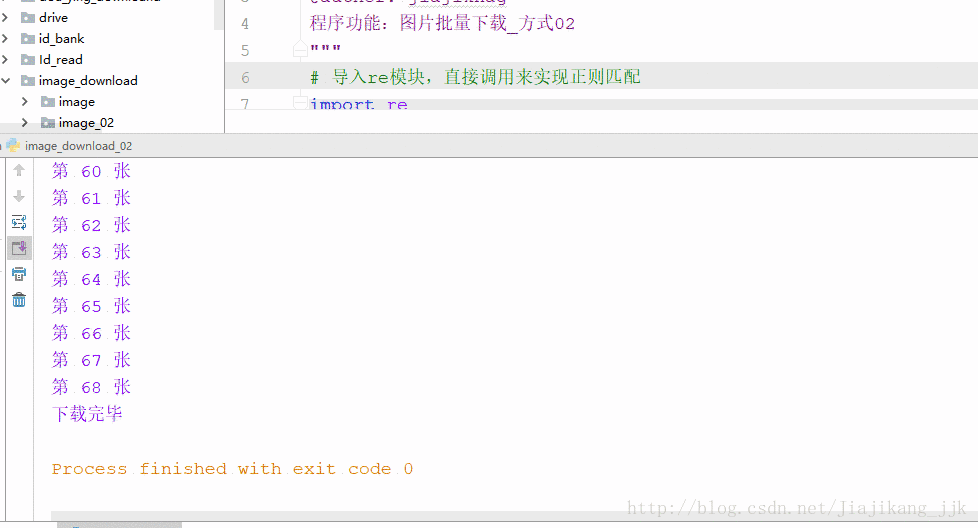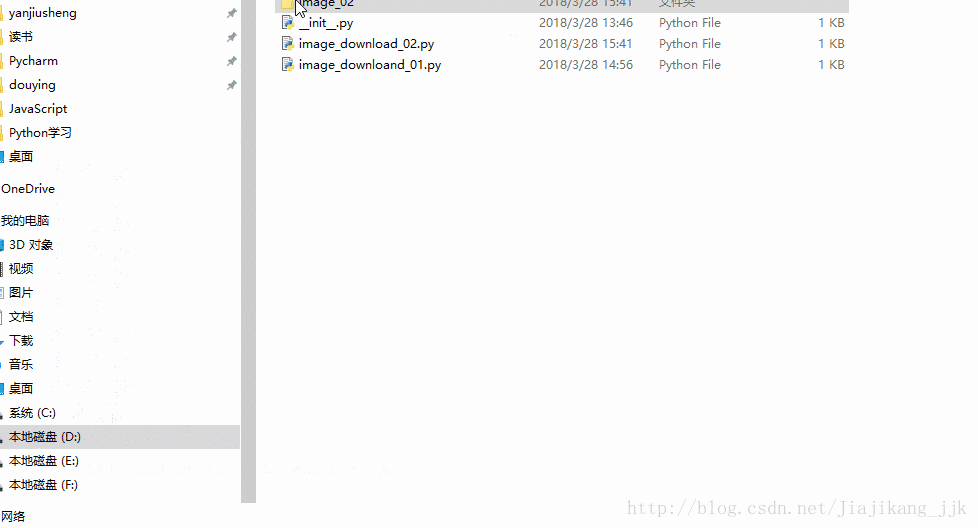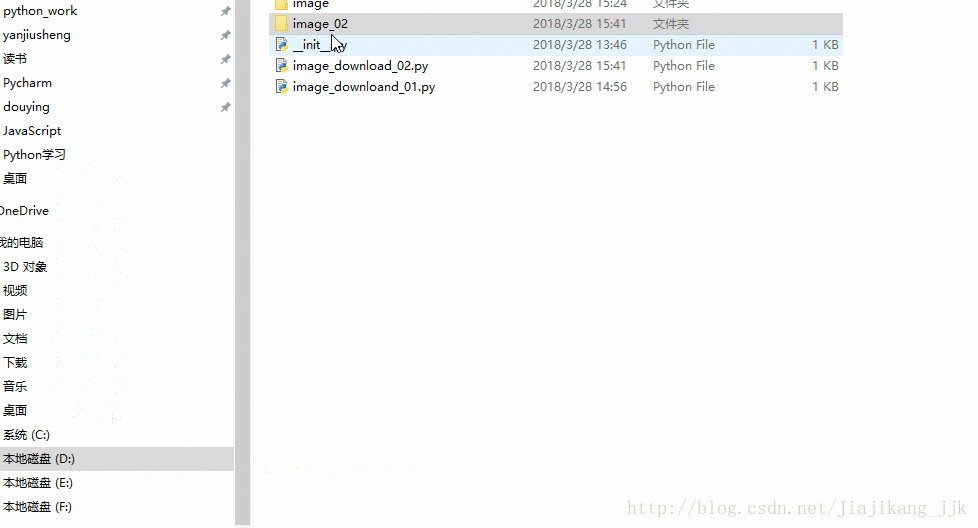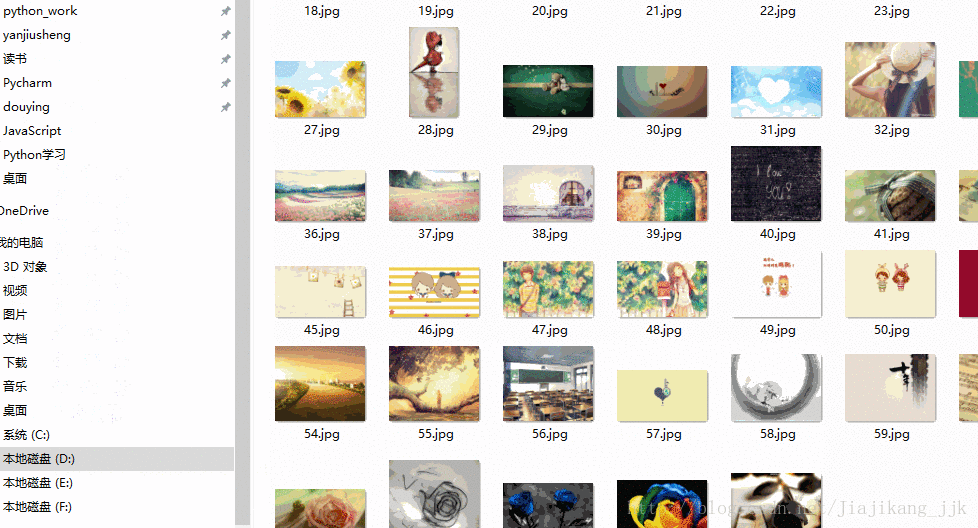
print("第", x ,"张")
print("下载完毕")2:结果















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











