







【C语言】中文文本文件之词频统计
一、前言
以下代码都是针对于小文本文件,不适用于大文本文件
二、 代码实现一
2.1 源码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct Word //声明一个结构体,分别存储单词和对应单词的个数
{
size_t time;
char word[230000];
};
void Copy(struct Word *array, FILE *read, const int length);
void Count_for_word(struct Word *array, const int length);
// 函数一
void Copy(struct Word *array, FILE *read, const int length) //该函数的作用是把文本中的单词复制到数组中
{
char ch, word[230000];
int i = 0, j;
while (fscanf(read, "%s", &word) != EOF)
{
strcpy(array[i].word, word); // 将word复制到arra[i]中
++i; //移动数组的下标
}
fclose(read); // 关闭文件指针
Count_for_word(array, length); // 调用自定义函数
}
// 函数二
void Count_for_word(struct Word *array, const int length) //统计单词的个数
{
int i, j;
for (i = 0; i < length; i++)
{
array[i].time = 1;
for (j = i + 1; j < length; j++)
{
if (strcmp(array[i].word, array[j].word) == 0)
{
++array[i].time; //如果遇到相同的单词,就把相应的结构体部分增加 1
strcpy(array[j].word, " "); //并把该单词置为空,因为已经读取到数组中了,所以这里改变的是数组的数据,不影响文本数据
}
}
}
printf("the file have %d word\n\n", length);
for (int index = 0; index < length; index++) // 冒泡排序
{
for (int temp = 0; temp < length - index-1; temp++)
{
// 例如:length = 5
if (array[temp].time < array[temp + 1].time)
{
struct Word word = array[temp];
array[temp] = array[temp + 1];
array[temp + 1] = word;
}
}
}
for (i = 0; i < length; i++)
if (strcmp(array[i].word, " ") != 0)
{ // 当不相等时候
//printf("%-5s occurrs %-3d %s\n", array[i].word, array[i].time, ((array[i].time > 1) ? "times" : "time"));
printf("%-5s:%-3d\n", array[i].word, array[i].time);
}
}
int main(int argc, char *argv[])
{
char word[230000];
int length = 0, ch;
FILE *read;
struct Word *array;
if (argc < 2 || argc > 2)
{
printf("usage: %s filename\n", argv[0]);
exit(EXIT_FAILURE);
}
// 打开文本
if ((read = fopen(argv[1], "r")) == NULL)
{
printf("open file failure\n");
exit(EXIT_FAILURE);
}
//
while (fscanf(read, "%s", &word) != EOF) //测试是否读到文件末尾
{
++length; //统计文本中单词的个数
}
rewind(read); //把文件指针置为文本开始的位置,并清除错位信息
array = malloc(sizeof(struct Word) * length); // 单词的长度动态分配内存
Copy(array, read, length); // 调用自定义函数
return 0;
}
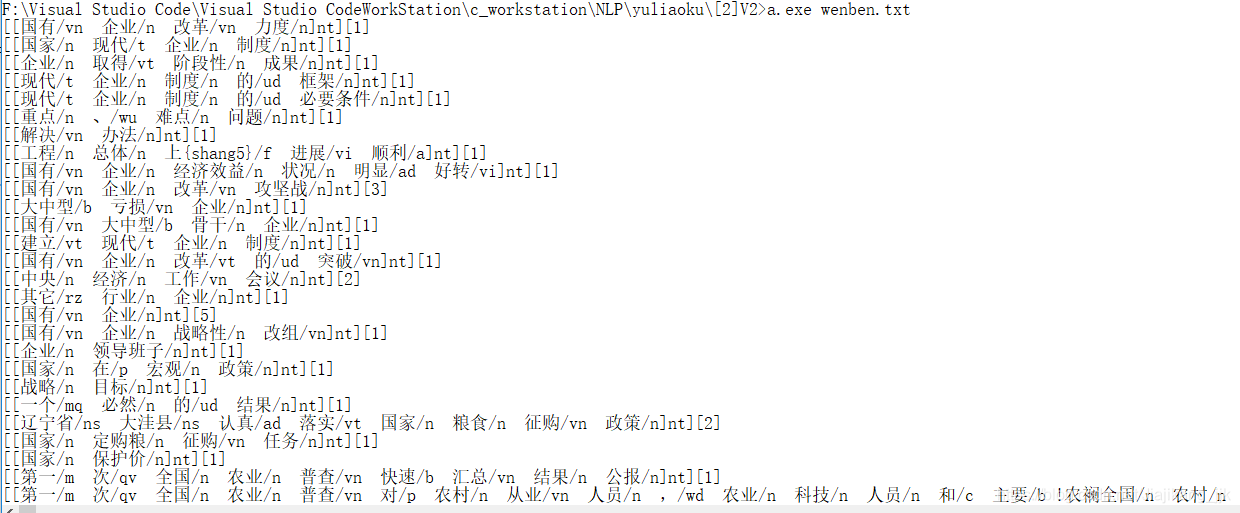
2.2 执行结果

三、代码实现二
3.1 源码
#include <stdio.h>
#include <string.h>
struct words //单词结构体
{
char word[115];
int count;
};
void quick_sort(char s[], int l, int r)
{
if (l < r)
{
int i = l, j = r, x = s[l];
while (i < j)
{
while (i < j && s[j] >= x) //从右到左找到第一个小于x的数
j--;
if (i < j)
s[i++] = s[j];
while (i < j && s[i] <= x) //从左往右找到第一个大于x的数
i++;
if (i < j)
s[j--] = s[i];
}
s[i] = x; //i = j的时候,将x填入中间位置
quick_sort(s, l, i - 1); //递归调用
quick_sort(s, i + 1, r);
}
}
int main(int argc, char *argv[])
{
struct words word[12000] = {0}, stmp = {0};
int i = 0, j = 0, k = 0, flag = 0;
int wors = 0;
char c;
char tmp[100] = {0}; // 存储每个词语,最多存储50个字
FILE *fp = NULL;
fp = fopen(argv[1], "r");
if (fp == NULL)
{
printf("文本打开错误");
return -1;
}
//读文件解析词语
while ((c = fgetc(fp)) != EOF) // 按字符读取
{
//以换行符作为单词标识符。
if (c != '\n')
{
tmp[j++] = c; // 在未遇到词语标识符之前将
//printf("%s\n",tmp);
}
else
{
tmp[j] = '\0'; // 清零操作
j = 0; // 重置
flag = 0;
//判断单词是否已经记录 如果已有则使用率加1
for (k = 0; k < i; k++)
{
if (strcmp(tmp, word[k].word) == 0) // 判断相等函数
{
word[k].count++; // 统计相同的词语的个数
flag = 1; // 设置标识符为1
break;
}
}
//没有则存入单词结构体数组保存
if (!flag)
{
strcpy(word[i].word, tmp);
word[i].count++;
i++;
}
memset(tmp, 0, sizeof(tmp));
memset(tmp, '\0', sizeof(tmp));
}
}
fclose(fp);
int length = sizeof(tmp) / sizeof(char); //求数组的长度
quick_sort(tmp, 0, length);
for (int kk = 0; kk < length; kk++)
{
printf("[%s][%d]\n", word[kk].word, word[kk].count);
}
// 输出排序后的所有已记录单词
/* for (k = 0; k < i; k++)
{
// printf("[%s][%d]\n", word[k].word, word[k].count);
printf("[%s]\n", word[k].word);
} */
return 0;
}
3.2 执行结果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











