






食用方法
环境安装
使用编辑器:vscode最新版
其他使用软件mysql8.0
环境jdk8、python3.11.0(已在requirement.txt指出)
vscode所下载插件如图
数据库创建
为了保证系统数据的可靠性,需要使用mysql存储2412个城市最近24小时的天气数据,每个城市每天约24条记录。以下是数据库表的设计,可使用项目中的init_db.sql脚本直接生成,使用这个方法需要先配置config.py中的数据库信息
mysql -u 用户名 -p < init_db.sql或者在数据库直接使用sql语句进行创建,以下是详细步骤
首先、需要创建一个数据库名为weather_db
creat database weather_db1. 城市信息表 (cities)
CREATE TABLE cities (
city_id INT PRIMARY KEY AUTO_INCREMENT,
city_name VARCHAR(50) NOT NULL,
province VARCHAR(50) NOT NULL,
latitude DECIMAL(10,6),
longitude DECIMAL(10,6),
elevation DECIMAL(10,2),
UNIQUE KEY (city_name, province)
);2. 天气数据表 (weather_data)
CREATE TABLE weather_data (
data_id BIGINT PRIMARY KEY AUTO_INCREMENT,
city_id INT NOT NULL,
observation_time DATETIME NOT NULL, -- 观测时间(整点)
temperature DECIMAL(5,2), -- 整点气温(℃)
precipitation DECIMAL(5,2), -- 整点降水量(mm)
wind_speed DECIMAL(5,2), -- 风速(m/s)
wind_direction VARCHAR(20), -- 风向
pressure DECIMAL(7,2), -- 整点气压(hPa)
humidity INT, -- 相对湿度(%)
weather_condition VARCHAR(50), -- 天气状况(晴/雨等)
data_status TINYINT DEFAULT 1, -- 数据状态(1正常,0异常,2缺失)
crawl_time DATETIME NOT NULL, -- 数据爬取时间
FOREIGN KEY (city_id) REFERENCES cities(city_id),
INDEX (city_id, observation_time),
INDEX (observation_time)
);3. 数据质量表 (data_quality)
CREATE TABLE data_quality (
quality_id INT PRIMARY KEY AUTO_INCREMENT,
city_id INT,
check_date DATE NOT NULL,
total_records INT NOT NULL,
missing_records INT DEFAULT 0,
abnormal_records INT DEFAULT 0,
completeness_rate DECIMAL(5,2),
FOREIGN KEY (city_id) REFERENCES cities(city_id),
INDEX (city_id, check_date)
);获取项目文件后
下载所需依赖
pip install -r requirements.txt打开config.py进行配置
设置自己的数据库配置
# 数据库配置
DB_CONFIG = {
'host': 'localhost',
'user': 'root',
'password': '123456',
'database': 'weather_db',
'port': 3306
}
# 爬虫配置
SPIDER_CONFIG = {
'base_url': 'http://www.nmc.cn',
'request_interval': 1, # 请求间隔时间(秒)
'max_retries': 3, # 最大重试次数
'timeout': 10 # 请求超时时间(秒)
}
# 数据质量配置
QUALITY_CONFIG = {
'min_temperature': -50, # 最低合理温度
'max_temperature': 50, # 最高合理温度
'min_humidity': 0, # 最低合理湿度
'max_humidity': 100 # 最高合理湿度
}
# 日志配置
LOG_CONFIG = {
'level': 'DEBUG', # 日志级别
'format': '%(asctime)s - %(levelname)s - %(message)s',
'filename': 'weather_spider.log', # 日志文件名
'filemode': 'w' # 每次覆盖写入
}
爬取中央气象台近24小时气象数据
python main.py collect --full也可使用
python main.py collect --北京获取指定城市数据
数据库数据可视化测试
python visualization.py --city 南昌执行命令后可在目录中找到两张可视化图
type visualization.log可以看到可视化执行日志
补充数据库
由于爬取的网页中不带有城市的坐标信息,因此使用脚本对坐标信息进行更新:
python update_city_coordinates.py下载spark工具,推荐使用以下指令下载,jdk1.8,下载在以下目录,或者在api.py中更改spark、需要修改jdk的指定位置
cd D:\Spark && curl -L -o spark-3.5.0-bin-hadoop3.tgz https://archive.apache.org/dist/spark/spark-3.5.0/spark-3.5.0-bin-hadoop3.tgz && tar -xzf spark-3.5.0-bin-hadoop3.tgz
spark关键算法
Spark数据分析方法总结:
- 分析方法:
- 使用PySpark进行24小时天气数据实时分析
- 按小时分组计算各气象指标平均值/总和
- 使用Spark SQL进行数据聚合和转换
- 主要处理步骤:
- 初始化SparkSession并配置环境
- 从MySQL数据库获取原始数据
- 创建Spark DataFrame并指定schema
- 使用hour函数提取时间的小时部分
- 按小时分组聚合计算:
- 温度、湿度、气压:计算平均值(avg)
- 降水量:计算总和(sum)
- 风速:计算平均值(avg)
- 技术特点:
- 使用Spark 3.5.0分布式计算框架
- 利用DataFrame API进行结构化数据处理
- 支持多指标并行计算
- 自动处理数据分区和并行执行
- 可视化数据准备:
- 生成时间范围序列
- 计算各指标统计值
- 返回格式化数据供前端ECharts使用
- 分析指标:
- 温度变化趋势
- 累计降水量
- 平均风速变化
- 湿度和气压变化
运行项目
1.在项目根目录中的终端运行
python api.py2.新建一个新终端
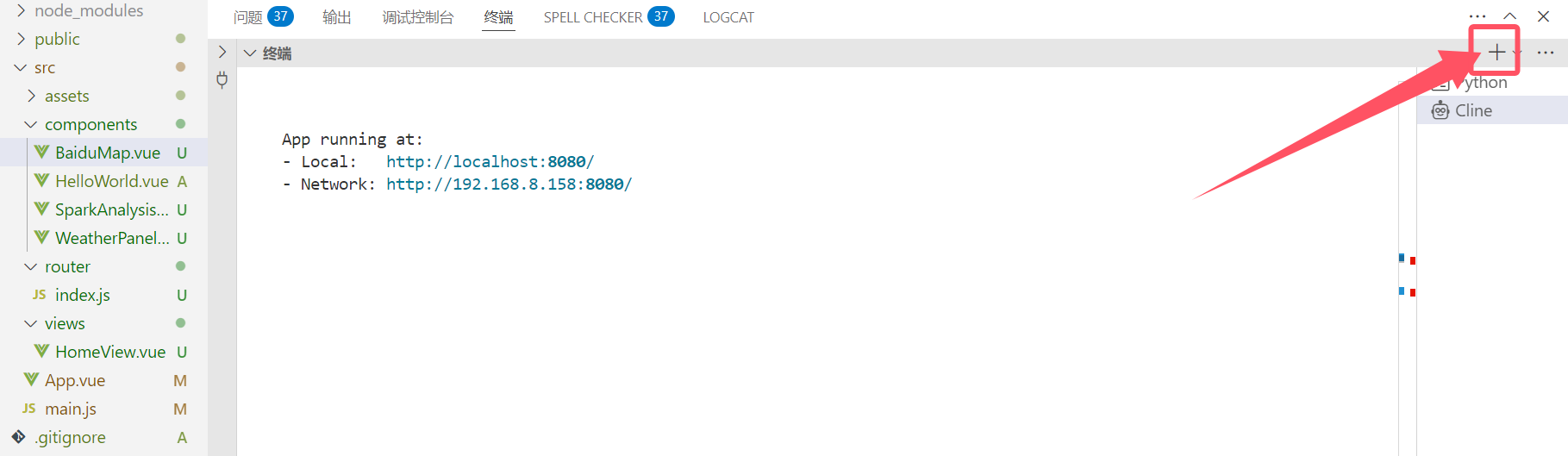
在新的终端输入以下代码
cd weather-visualization && npm run serve如果终端显示有未安装的包,请手动安装,命令 pip install 包名
再重新运行项目
项目特点
-
项目包含前后端多个组件
- 前端使用Vue3 + ECharts + 百度地图
- 后端使用Python Flask + MySQL
- 包含数据爬取、存储、分析和可视化全流程
- 需要分析各模块技术栈和功能
项目技术栈和功能分析:
一、前端技术栈(weather-visualization目录)
- Vue3框架 + Vue CLI构建
- 百度地图API(vue3-baidu-map-gl)
- ECharts数据可视化
- Vue Router前端路由
- 主要功能:
- 城市地图展示与交互
- 气象数据可视化图表
- 实时数据展示面板
- 响应式布局适配不同设备
二、后端技术栈
- Python Flask框架(api.py)
- MySQL数据库(init_db.sql)
- 主要功能:
- RESTful API接口
- 城市数据管理
- 气象数据存储与查询
- 数据质量监控
三、数据处理模块
-
爬虫模块(spider.py)
- 气象数据采集
- 数据清洗与格式化
-
数据分析模块(visualization.py)
- Spark数据分析
- 数据可视化预处理
四、数据库设计
- 城市表(cities)
- 气象数据表(weather_data)
- 数据质量表(data_quality)
- 支持复杂查询和统计分析
五、系统特色
- 前后端分离架构
- 数据采集到可视化完整流程
- 响应式交互设计
- 多维度数据展示
六、项目改进点
1.未爬取到风速与降水量的数据
2.百度地图api不能实现放大地图功能
3.地图标记点因为不能放大的功能而密集,不能确定指定城市的数据


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









