







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
SQL查询 — 进行集合运算
要点
关系数据库里的表允许存在重复的行,称为多重集合(multiset, bag)
- 结果里不允许出现重复行 —— UNION, INTERSECT
- 结果里留下重复行 —— UNION ALL
集合运算符为了排除掉重复行,默认地会发生排序,而加上可选项ALL之后,就不会再排序。所以性能会有所提升。
*SQL里不支持UNION DISTINCT这样的写法
和(UNION) 差(EXCEPT) 积(CROSS JOIN)
*SQL规定, INTERSECT比UNION和EXCEPT优先级更高
应用样例
1. 比较表和表
比较备份数据(tbl_A)和最新数据(tbl_B),两张表是否是相等的
*方法1: 查询以下语句结果与tbl_A和tbl_B的行数是否一致
S UNION S = S 幂等性 ;UNION ALL不具有幂等性
SELECT COUNT(*)
FROM (SELECT * FROM tbl_A
UNION
SELECT * FROM tbl_B) TMP;
*方法2: 不用检查两张表的行数,直接进行比较
(A UNION B) = (A INTERSECT B)<=> (A = B)
只需判定(A UNION B)EXCEPT (A INTERSECT B)的结果集不是空集
SELECT CASE WHEN COUNT(*) = 0 THEN '相等'
ELSE '不相等' END AS result
FROM ((SELECT * FROM tbl_A
UNION
SELECT * FROM tbl_B)
EXCEPT
(SELECT * FROM tbl_A
INTERSECT
SELECT * FROM tbl_B)) tmp;
以上两Queries都可用于包含NULL的表。
比较表与表的diff
(SELECT * FROM tbl_A
EXCEPT
SELECT * FROM tbl_B)
UNOIN ALL
(SELECT * FROM tbl_B
EXCEPT
SELECT * FROM tbl_A);
2. 用差集实现关系除法运算
代表性的方法有:
- 嵌套使用NOT EXISTS
- 使用HAVING子句转换成一对一关系
- 把除法变成减法
有两张员工技术信息管理表Skills表有列skill,EmpSkills表有列emp,skill,从表EmpSkills中找出精通表Skills中所有技术的员工
表Skills

表EmpSkills
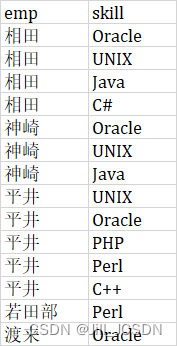
*用求差集的方法进行关系除法的运算(有余数)
SELECT DISTINCT emp
FROM EmpSkills EP1
WHERE NOT EXISTS(SELECT skill FROM Skills
EXCEPT
SELECT skill FROM EmpSkills EP2
WHERE EP1.emp = EP2.emp);
3. 寻找相等的子集
有"供应商-零件"关系表SupParts有列Sup(供应商),part(零件),查询供应完全一样的零件的供应商
表SupParts
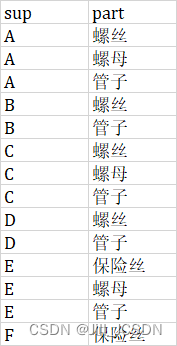
*首先,声称供应商的全部组合;条件1: 两个供应商都经营同种零件;条件2:两个供应商经营的零件种类数相同
SELECT SP1.sup, SP2.sup
FROM SupParts SP1,SupParts SP2
WHERE SP1.sup < SP2.sup --生成全部无重复的供应商组合
AND SP1.part = SP2.part --经营同种类的零件
GROUP BY SP1.sup,SP2.sup
HAVING COUNT(*)=(SELECT COUNT(*) FROM SupParts SP3 --经营零件种类数相等
WHERE SP3.sup = SP1.sup)
AND COUNT(*)=(SELECT COUNT(*) FROM SupParts SP4
WHERE SP4.sup = SP2.sup);
4. 用于删除重复行的高效SQL
有一无主键表Products有列name(产品名称),price(产品单价),从该表中删除重复的行
表Products
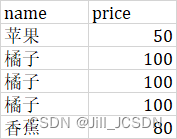
*方法1: 通过EXCEPT求补集
DELETE FROM Products
WHERE row_id IN (SELECT row_id FROM Products
EXCEPT
SELECT MAX(row_id) FROM Products
GROUP BY name,price);
*方法2: 通过NOT IN求补集
DELECT FROM Products
WHERE row_id NOT IN(SELECT MAX(row_id) FROM Products
GROUP BY name,price);
这两种方法的性能优劣主要取决于表的规模,以及删除的行数与留下的行数之间的比率。















 1241
1241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









