







这是一篇今年6月分发表的论文,什么资料都没有的。论文实验结果非常棒,同时想挑战一下自己,多学点东西,开始复现 这篇文章。

这是论文提出的模型的架构。从头开始一点一点学。
经过我的了解,预测的流程如下:
采用VG算法将时间序列转化为图,计算每个VG图中每个点的集体影响力值CI作为点的权重。VG 图简单来说就是两个点能相互看见就连边,反应的是两点之间没有突然的价格变动。CI值是根据每个点的度和以其为圆心某个圆上的点的度计算的。
利用struc2vec算法,进行图嵌入,Struc2vec和其他强调距离等的图嵌入算法不同,强调结构相似性,两个距离很远的点有相似的结构,也可以很相似。简单来说,struc2vec生成一个k层的完全图,每两个点之间都连边,边的权值反映两个点的相似性。层与层之间也相连。然后根据相似度在完全图上从每个点开始随机走,生成一条路径,该条路径上的点作为上下文,根据这个路径,后续采用word2vec中的skipgram,用deepwalk 的方法,将每个点映射成为一个张量。
将X输入一系列DARNNs中的encoder中,再将hidden结果和每个点的CI值输入decoder中,得到最后的decoder的隐藏层状态。
后面的一步处理,经过我和作者确认,将6个输出的隐藏层做和,行成一个张量r^i,进行三次1*1卷积生成query,key,和value,针对每个股票都算出后,经过一次attention机制调整所有股票的value,经过全连接层,得到涨或跌的结果。

VG图计算比较容易理解,公式如下:
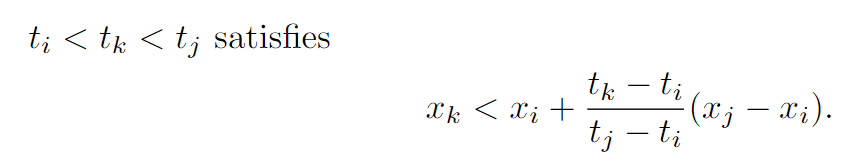
然后是collective influence (CI)的计算,简单来说,一个点CI值取决于这个点的度,以及以这个点为圆心,半径为L的圆上的点的度。公式如下:
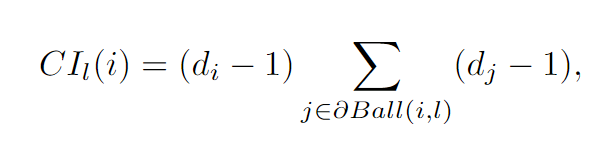
然后是通过struc2vec进行图嵌入,具体过程太过复杂,网络上有很多讲解,不再赘述。
然后是送入DARNNs,DARNN比较熟了,之前也复现过模型。
再然后是CAAN网络,CAAN在论文和论文中给的reference中都没怎么讲解。大致就是根据decoder输出r^i,用1*1的卷积求query^i,key^i,value^i,再求相似性,并进行预测。
详细的讲解在另一篇Attention is All You Need中比较详细。
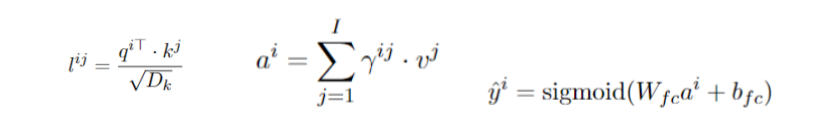
现在就是里面的很多参数的设置不了解(论文中没给,在以后的日子里想办法得到)















 112
112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









