







sklearn,处理机器学习(有监督学习和无监督学习)的包,有六个任务模块和一个数据引入模块
- 有监督学习的分类任务
- 有监督学习的回归任务
- 无监督学习的聚类任务
- 无监督学习的降维任务
- 数据预处理任务
- 模型选择任务
- 数据引入
数据格式:
- Numpy二维数组(ndarray)的稠密数据(dense data)
- SciPy矩阵 (scipy.sparse.matrix)的稀疏数据(sparse data)
上述数据在机器学习中通常用符号X表示,是模型自变量,大小=[样本数,特征数]
有监督学习除了需要特征X还需要标签y,y通常就是Numpy一维数组,无监督学习没有y
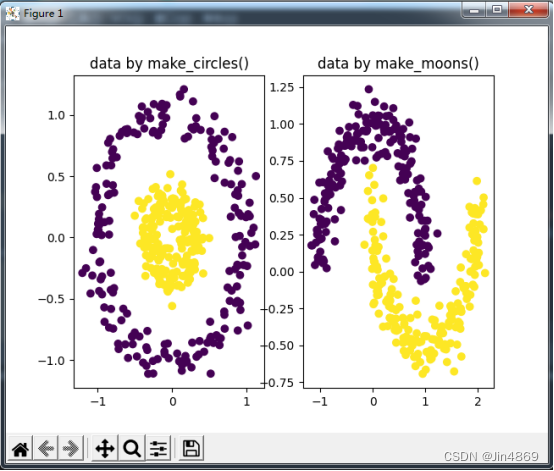
生成数据make_circles和make_moons
make_moons和make_circles是函数用来生成数据集
from sklearn.datasets import make_circles
from sklearn.datasets import make_moons
# 生成数据make_circles和make_moons,并显示X = 400x2 ,Y = {0,1}
# noise设置参数,越小越集中;factor:0<double<1,越小圆环间隔越大
# random_state:生成随机种子,给定一个int型数据,能够保证每次生成数据相同
x_circle, y_circle = make_circles(n_samples=400, shuffle=True, noise=0.1, factor=0.3, random_state=False)
x_moons, y_moons = make_moons(n_samples=400, shuffle=True, noise=0.1, random_state=False)将生成的数据集可视化
import matplotlib.pyplot as plt
plt.figure()
plt.subplot(121)
plt.scatter(x_circle[:, 0], x_circle[:, 1], c=y_circle)
plt.title("data by make_circles()")
plt.subplot(122)
plt.scatter(x_moons[:, 0], x_moons[:, 1], c=y_moons) # scatter生成散点图,c设置散点颜色,用y_moons的值作区分
plt.title("data by make_moons()")
plt.show()生成结果如下
显示一个图像数据集
网址:http://archive.ics.uci.edu/ml/index.php
下载下来的数据是很多图片的压缩包,任务是把图片拼成一张大图
选择:CMU人脸图像数据集
该数据由 640 张黑白人脸图像组成,他们以不同的姿势(直、左、右、上)、表情(中性、快乐、悲伤、愤怒)、眼睛(是否戴太阳镜)和大小拍摄
每个图像都可以通过姿势、表情、眼睛和大小来表征。每个人有 32 张图像捕捉每种特征组合。
图像数据可以在 /faces 中找到。该目录包含 20 个子目录,每个人一个,以 userid 命名。这些目录中的每一个都包含同一个人的几个不同的面部图像。
.pgm
是图片中人物的用户id,这个字段有20个值:an2i, at33, boland, bpm, ch4f, cheyer, choon, danieln, glickman, karyadi, kawamura, kk49, megak, mitchell, night, phoebe, saavik、steffi、sz24 和 tammo。
是人的头部位置,这个字段有4个值:直、左、右、上。
是人的面部表情,这个字段有4个值:中性、快乐、悲伤、愤怒。
是人的眼睛状态,这个字段有2个值:睁眼,太阳镜。
是图像的比例,该字段有 3 个值:1、2 和 4。1 表示全分辨率图像(128 列 x 120 行);2 表示半分辨率图像(64 x 60);4 表示四分之一分辨率的图像(32 x 30)。
如果您仔细查看图像目录,您可能会注意到某些图像具有 .bad 后缀而不是 .pgm 后缀。事实证明,在拍摄的 640 张图像中,有 16 张因相机设置问题而出现故障;这些是.bad 图像。有些人比其他人有更多的毛刺,但每个被“打脸”的人都应该有至少 28 张好的人脸图像(在可能的 32 种变化中,打折规模)。
每个人只从中选择28张照片拼图,一共20个人(同一行)
import numpy as np
from PIL import Image
from os import listdir
ph_path = "D:\\JetBrains\\pythonProject\\machine learning\\faces"
filelist = []
pgm_path = listdir(ph_path)
ROW = 20
COLUMN = 28
WIDTH = 32
HEIGHT = 30
for p in range(len(pgm_path)):
# filelist目录下的文件夹列表
filelist.append(ph_path + str('\\') + str(pgm_path[p]))
print(filelist)
def merge_persons():
# 选择四分之一分辨率图像,观察文件名可知,四分之一分辨率图像文件名endwith(".pgm"),文件名最后一个字符是4
faces = Image.new('RGB', (COLUMN * HEIGHT, ROW * WIDTH)) # 建一个空白图像,然后把图片粘上去
x = 0
for lst in filelist:
num = 0
for pt in listdir(lst):
if pt.endswith('4.pgm') & (pt[-5] == '4'):
# print(pt) 核实下选的图片对不对
# lst + '\\' + pt,图片的地址
faces.paste(Image.open(lst + '\\' + pt), (num * HEIGHT, x * WIDTH))
num += 1
if num > 28:
break
x += 1
faces.save('faces.jpg')
merge_persons()
生成图片:

这里使用了python PIL Image,下面是一些基本用法
# 打开
img = Image.open('1.jpg')
# 灰度
imgGrey = img.convert('L')
# 显示
img.show()
# 保存
img.save('2.jpg')
# 创建指定大小,指定通道类型的空图像
img_white = Image.new('RGB', (width, height), (255,255,255)) # 白色的空图像图像的拼接也可以通过Image和numpy格式相互转换,拼接numpy然后再转成Image形式得到
from PIL import Image
import numpy as np
img = Image.open('01.jpg')
array = np.array(img) # PIL.Image 转 numpy
img1 = Image.fromarray(array) # numpy转 PIL.Image
img1 = Image.fromarray(array.astype('uint8')) # 图像在显示时需要转换为uint8
img1.save('from_array.jpg')

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









