






目录
开源之夏 2022 项目已发布,申请 Jina AI 项目的同学可以准备起来了~
开源之夏是由「开源软件供应链点亮计划」发起,并长期支持的一项暑期开源活动。旨在鼓励全球在校学生,积极参与开源软件的开发维护,促进优秀开源软件社区的蓬勃发展,培养和发掘更多优秀的开发者。
今年是开源之夏举办的第三届,共计吸引了 124 家社区提报超过 300+ 项目。Jina AI 作为业内领先的神经搜索 (Neural Search) 开源企业,在开源之夏 2022 中共计提报了 3 个项目任务。
同学们现已可以进行任务申请,获得 Jina AI 资深工程师的亲自指导,以及 Jina AI 实习机会。完成项目并贡献给社区后,还将获得开源之夏活动奖金和结项证书。
Jina AI 项目任务详情一览
项目一:近似最近邻搜索算法 HNSW 的改进与优化
涉及技术领域:AI, 近似最近邻, 向量检索
编程语言:C++, Python
项目难度:进阶
联系导师:felix.wang@jina.ai
项目支持报名语言:中文
项目成果仓库:
https://github.com/jina-ai/annlite![]() https://github.com/jina-ai/annlite
https://github.com/jina-ai/annlite
项目描述:
针对海量向量数据的搜索,无论是工业界还是学术界都做了大量的研究。由于精确的向量搜索在海量数据的场景下搜索时间过长,所以目前的常见做法,是在向量上建立近似搜索索引。学术上我们称之为近似最近邻搜索 ANN (Approximate Nearest Neighbor Search) 问题,通常都是通过牺牲搜索精度来换取时间和空间的方式,从大量样本中获取最近邻。
根据 Benchmark 上 ANN 算法的基准测试结果,基于图结构的 HNSW 算法在查询速度和精度上优于其他 ANN 算法。但是 HNSW 算法本身的主要问题就是对内存占用较大,限制了其可以索引的数据大小。
目前我们的开源向量索引产品 AnnLite 核心近似搜索算法是基于 HNSW 来实现,并在此基础上提供了更加丰富的功能(例如支持前置过滤近似查询)。为了使得 AnnLite 能够具备更强的竞争力和实际应用价值,我们希望能够进一步对 HNSW 算法进行改进和优化。
技术要求:
开发者需要对 ANN 算法有较深入的理解,可以熟练使用 C++ 编程语言
产出要求:
* 需要 HNSW 支持向量量化 quantization 技术,减少内存占用的同时能够加快向量距离的计算;
* 对 HNSW 的图索引结构进行改进,在相同数据索引大小的情况下,进一步减少图规模大小;
* 升级前置条件过滤引擎,减少前置过滤耗费的时间;
* 需要能够撰写完整的文档,单元测试和集成测试。
申请地址
项目二:支持基于 Redis 的近似最近邻搜索
涉及技术领域:AI, 数据库,存储,近似最近邻, 向量检索
编程语言:Python
项目难度:进阶
联系导师:bo.wang@jina.ai
项目支持报名语言:中文
项目成果仓库:
https://github.com/jina-ai/docarray![]() https://github.com/jina-ai/docarray
https://github.com/jina-ai/docarray
项目描述:
神经搜索 (Neural Search) 特指使用人工神经网络模型的搜索系统。很多常见的搜索应用,比如以图搜图、听声辨乐,都需要神经搜索。在神经搜索系统中,所有的文件会通过人工神经网络被表示为一个向量并存储在索引中。当用户进行搜索时,用户的查询目标也会被表示为一个向量。通过比较查询向量与索引向量的相似度/距离,我们可以找到最为匹配的文件。
基于神经网络的搜索通常需要在短时间内查询到最相似的文件。这依赖于近似最近邻搜索 (Approximately Nearest Neightbour Search),简称 ANN 搜索。作为一个前沿研究领域,学者们已经提出很多高效的 ANN 算法。Redis 数据库目前已经支持基于图的 ANN 搜索算法:HNSW,该算法能够最大程度的达到检索召回率和检索时间的平衡。
DocArray 作为 Jina AI 神经搜索全家桶的底层模块,能够帮助开发者快速开发搜索系统。在DocArray 中,我们已经支持了多种向量数据库作为存储后台,如 ANNLite, Weaviate, Qdrant 以及 Elasticsearch。
为了帮助 Redis 社区的开发者,我们希望支持 Redis 数据库作为 DocArray 的存储后台,帮助用户高效的进行向量检索。
技术要求:
需要开发者对 DocArray, Redis 以及背后基于 HNSW 的 ANN 搜索算法有一定理解。
产出要求
* 需要在 DocArray 中集成 Redis 作为存储后台;
* 代码有完整的文档及单元测试、集成测试;
* 需要在 DocArray 中产出 Redis ANN 搜索的基准,即:使用基于 Redis 的查询速度/召回率对比我们已经支持的存储后台,结果将发表在我们的比较基准页面。
申请地址:
项目三:基于深度学习的3D物体特征表达与学习
涉及技术领域:AI, 深度学习框架, 表征学习, 3D Mesh 模型
编程语言:Python
项目难度:进阶
联系导师:jem.fu@jina.ai
项目支持报名语言:中文
项目成果仓库:
https://github.com/jina-ai/executor-3d-encoder![]() https://github.com/jina-ai/executor-3d-encoder
https://github.com/jina-ai/executor-3d-encoder
项目描述:
3D 物体的表征形式多种多样,其中一个比较典型的方法是 3D 点云,即某个坐标系下的点的数据集。相比于文本、图像,其包含了物体更加丰富的信息,包括三维坐标 X,Y,Z、颜色、分类值、强度值、时间等等。
3D 物体一个比较典型的应用场景就是元宇宙,其中存在着大量的数字 3D 模型。精确建模与理解这些虚拟物体可以帮助我们更好的实现对 3D 模型进行分类,搜索,以及管理。
目前我们已经对一些 3D 物体模型的预训练模型进行了封装,并且支持对模型的微调 (Finetune),使得用户可以更加便捷地将这些模型应用到实际生产环境中。
为了更好的适应具体使用场景,针对预训练模型的微调通常会使用表征学习。表征学习 (Representation Learning) 是深度学习的一个分支,其广泛应用于工业界,它通过训练深度学习模型优化输入数据的向量表示,以适应相似度计算、检索、推荐等不同应用。
将深度表征学习与 3D 模型数据结合可以将 3D 物体的特征更好的展现出来,以此支持各个领域下对 3D 物体数据的搜索需求。
本项目旨在集成更多针对 3D 物体的神经网络模型,并实现对不同模型的统一管理。
技术要求:
对深度学习/表征学习有基本理解,熟练使用和掌握 Python,熟练使用和掌握PyTorch 等深度学习框架
产出要求:
* 调研并实现目前 SOTA 的 3D 点云编码网络
* 实现 3D 点云数据的预处理,支持对不同模型的快速训练
* 需要能够撰写完整的文档,单元测试和集成测试
申请地址:
报名申请 Jina AI 项目任务
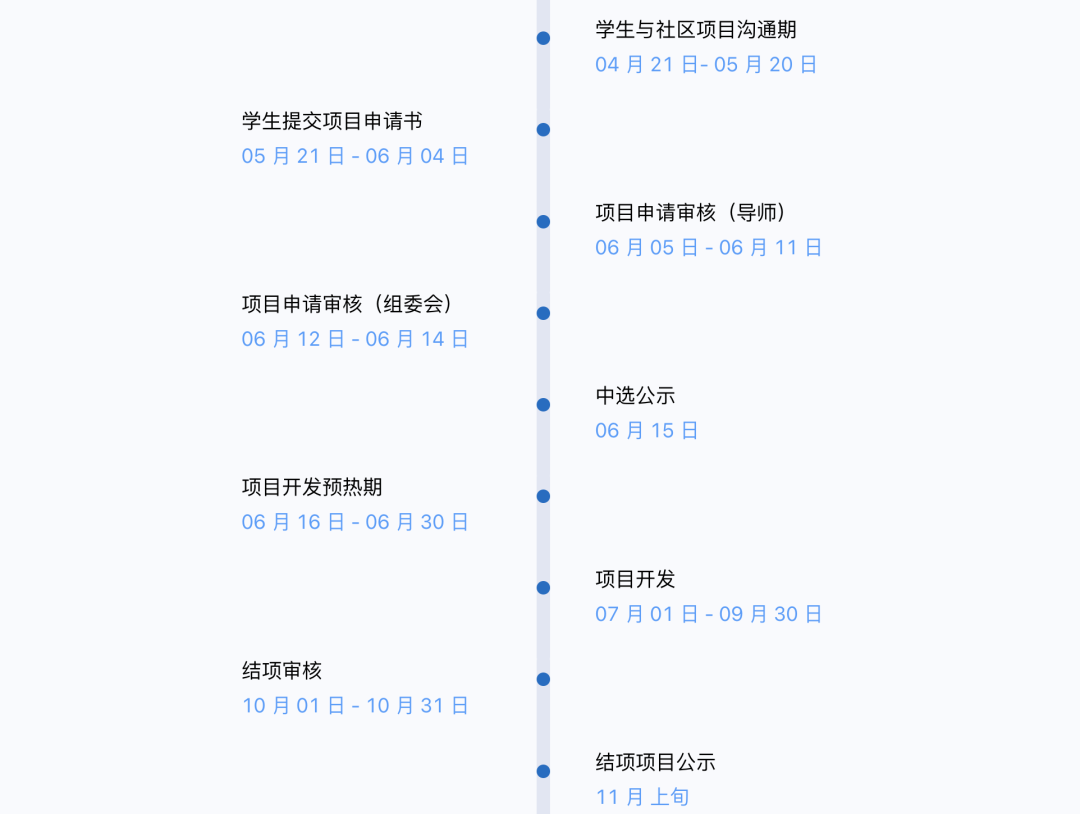
以上就是 Jina AI 在开源之夏 2022 的项目任务及详情,现已开启学生与社区项目沟通通道,其他关键时间节点如下如所示:















 649
649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









