







分享论文:
本文的研究对象是 Decentralized Partially Observable Markov Decision Process (Dec-POMDP) , 首先介绍一下它和传统的MAMDP的区别:
所有实体(entity)的集合记为 E \mathscr{E} E, 这里的实体包括 agent 和一些非 agent 的动态物体, 其中 agent 的集合记为 A \mathscr{A} A. 每个实体的状态记为 s e s^{e} se, e ∈ E e\in \mathscr{E} e∈E, 每个agent动作记为 u a u^{a} ua, a ∈ A a\in \mathscr{A} a∈A, 每个实体有一个特征 c e c^{e} ce(对于agent来说通常是指它的skill-level), e ∈ E e\in \mathscr{E} e∈E, 记联合特征为 c \mathbf{c} c, 是一个环境参量, 一组 c \mathbf{c} c的取值对应一个不同的场景(scenario), 不同的场景出现的概率分布为 ρ ( c ) \rho(\mathbf{c}) ρ(c). “部分观测性”: 每个agent并不能观测到所有实体的状态, 它智能观测到部分实体的状态, 定义 m ( a , e ) m(a,e) m(a,e), a ∈ A , e ∈ E = { 0 , 1 } a\in \mathscr{A}, e\in \mathscr{E}=\{0,1\} a∈A,e∈E={0,1}, 表示agent a a a 能否观测到实体 e e e 的状态(1表示能, 0表示不能). 每个agent的观测为 o a o^{a} oa, a ∈ A a\in \mathscr{A} a∈A. 所有的实体有一个global Q function: Q t o t ( s , u ; c ) Q^{tot}(\mathbf{s}, \mathbf{u};\mathbf{c}) Qtot(s,u;c), 其中 s , u \mathbf{s}, \mathbf{u} s,u 分别为联合状态和联合动作. 在算法中常用的 Q ∗ t o t Q_{*}^{tot} Q∗tot 的approximator为: Q θ t o t ( τ , u ; c ) Q^{tot}_{\theta}(\bm{\tau}, \mathbf{u}; \mathbf{c}) Qθtot(τ,u;c). 其中 τ t = { τ t a } \bm{\tau}_{t}=\{\tau_{t}^{a}\} τt={τta}, τ t a = { o 1 a , a 1 a , . . . , o t a } \tau_{t}^{a}=\{o_{1}^{a}, a_{1}^{a}, ..., o_{t}^{a}\} τta={o1a,a1a,...,ota} 是观测-动作历史(history), 在算法中通常由一个循环神经网络得到: 在每个时刻 t t t, 循环神经网络输入 ( u t − 1 a , o t a ) (u_{t-1}^{a}, o_{t}^{a}) (ut−1a,ota), 以输出作为 τ t a \tau_{t}^{a} τta.
history 的计算
用循环神经网络计算 history
在DQN算法中, 它的损失函数为
L ( θ ) = E ( c , τ t , u t , r t , τ t + 1 ) ∼ D [ ( r t + γ max u ′ Q θ ‾ t o t ( τ t + 1 , u ′ ; c ) − Q θ ‾ t o t ( τ t , u ′ ; c ) ) 2 ] L(\theta) = \mathbb{E}_{(\mathbf{c}, \bm{\tau_{t}}, \bm{u_{t}}, r_{t}, \bm{\tau_{t+1}})\sim \mathcal{D}}[(r_{t}+\gamma \max_{\mathbf{u}'}Q_{\overline{\theta}}^{tot}(\bm{\tau}_{t+1}, \mathbf{u}'; \mathbf{c})-Q_{\overline{\theta}}^{tot}(\bm{\tau}_{t}, \mathbf{u}'; \mathbf{c}))^{2}] L(θ)=E(c,τt,ut,rt,τt+1)∼D[(rt+γu′maxQθtot(τt+1,u′;c)−Qθtot(τt,u′;c))2]
D \mathcal{D} D 是replay buffer, 其中上划线表示target network的参数.
还有一个重要的区别是没有每个agent的reward信息, 环境只会给一个整体评价(team reward)
r
t
r_{t}
rt. 目标函数是discounted cumulative team reward:
G
=
E
τ
[
∑
i
=
1
∞
γ
t
r
t
]
G=\mathbb{E}_{\bm{\tau}}[\sum\limits_{i=1}^{\infty}\gamma^{t}r_{t}]
G=Eτ[i=1∑∞γtrt]
有一个中心控制端(coach agent), 用于生成agent的调度策略, 相当于分配任务, 记为
u
=
{
u
a
}
\mathbf{u}=\{u_{a}\}
u={ua},
a
∈
E
a\in \mathscr{E}
a∈E, 其中
u
a
∈
{
0
,
1
}
u_{a}\in \{0,1\}
ua∈{0,1} 表示agent
a
a
a是否被派去完成这项任务. 每个agent有一个评分(skill-level)
c
a
c^{a}
ca,
a
∈
E
a\in \mathscr{E}
a∈E,
c
=
{
c
a
}
\mathbf{c}=\{c^{a}\}
c={ca}. 如果有多于一个agent去做这项任务, 则整个团队将被惩罚.
定义目标函数:
R
(
u
,
c
)
=
max
a
c
a
u
a
+
1
−
∑
a
u
a
R(\mathbf{u}, \mathbf{c}) = \max_{a} c^{a} u^{a}+1-\sum\limits_{a}u^{a}
R(u,c)=amaxcaua+1−a∑ua
作为agent
a
a
a的目标. 此目标函数第1项表示: 完成这项任务的agent中能力最大的agent的评分, 第2项表示: 1-被派去的agent的数量.
coach agent 能够观测到global state s \mathbf{s} s, 并可以根据global state产生信息发送给agent, 给每个agent发送的信息是定长的, 但是不同agent的不同, 文中称为strategy, 是一个vector, 记作 z a z^{a} za, a ∈ E a\in \mathscr{E} a∈E, 长度为 d z d_{z} dz, z = { z a } \mathbf{z}=\{z^{a}\} z={za}, a ∈ z a a\in z^{a} a∈za, coach产生 z a z^{a} za的策略为 f ( s , c ) f(\mathbf{s}, \mathbf{c}) f(s,c), 在算法中它的approximator记为 f ϕ ( s , c ) f_{\phi}(\mathbf{s}, \mathbf{c}) fϕ(s,c). agent采取策略的时候将会参考coach agent发送的strategy信息. coach agent并不是每个step都给agent发送信息, 而是每 T T T步才收一次global state, 生成信息发送给agent, agent 收到coach发来的信息之后, 在接下来的 T T T 步内根据自己的观测和coach的信息来来产生动作.
Q
t
o
t
(
s
,
u
;
c
)
Q^{tot}(\mathbf{s}, \mathbf{u};\mathbf{c})
Qtot(s,u;c)
L
(
θ
,
ϕ
)
=
E
(
c
,
τ
t
,
u
t
,
r
t
,
τ
t
+
1
)
∼
D
[
(
r
t
+
γ
max
u
′
Q
θ
‾
t
o
t
(
τ
t
+
1
,
u
′
;
∣
z
t
+
1
^
;
c
)
−
Q
θ
‾
t
o
t
(
τ
t
,
u
′
∣
z
t
^
;
c
)
)
2
]
L(\theta, \phi) = \mathbb{E}_{(\mathbf{c}, \bm{\tau_{t}}, \bm{u_{t}}, r_{t}, \bm{\tau_{t+1}})\sim \mathcal{D}}[(r_{t}+\gamma \max_{\mathbf{u}'}Q_{\overline{\theta}}^{tot}(\bm{\tau}_{t+1}, \mathbf{u}'; | \mathbf{z}_{\hat{t+1}}; \mathbf{c})-Q_{\overline{\theta}}^{tot}(\bm{\tau}_{t}, \mathbf{u}'|\mathbf{z}_{\hat{t}} ; \mathbf{c}))^{2}]
L(θ,ϕ)=E(c,τt,ut,rt,τt+1)∼D[(rt+γu′maxQθtot(τt+1,u′;∣zt+1^;c)−Qθtot(τt,u′∣zt^;c))2]
其中
t
^
=
max
{
v
∣
v
≡
0
(
m
o
d
T
)
a
n
d
v
≤
t
}
\hat{t}= \max \{v | v \equiv 0 (\mod \ T ) \mathrm{ and } v\leq t\}
t^=max{v∣v≡0(mod T)andv≤t}, 即距离
t
t
t 时刻最近的coach下发信息时间,
z
t
+
1
^
∼
f
ϕ
(
s
t
^
;
c
)
z_{\hat{t+1}}\sim f_{\phi}(\mathbf{s}_{\hat{t}}; \mathbf{c})
zt+1^∼fϕ(st^;c),
z
t
+
1
^
∼
f
ϕ
‾
(
s
t
+
1
^
;
c
)
z_{\hat{t+1}}\sim f_{\overline{\phi}}(\mathbf{s}_{\hat{t+1}}; \mathbf{c})
zt+1^∼fϕ(st+1^;c).
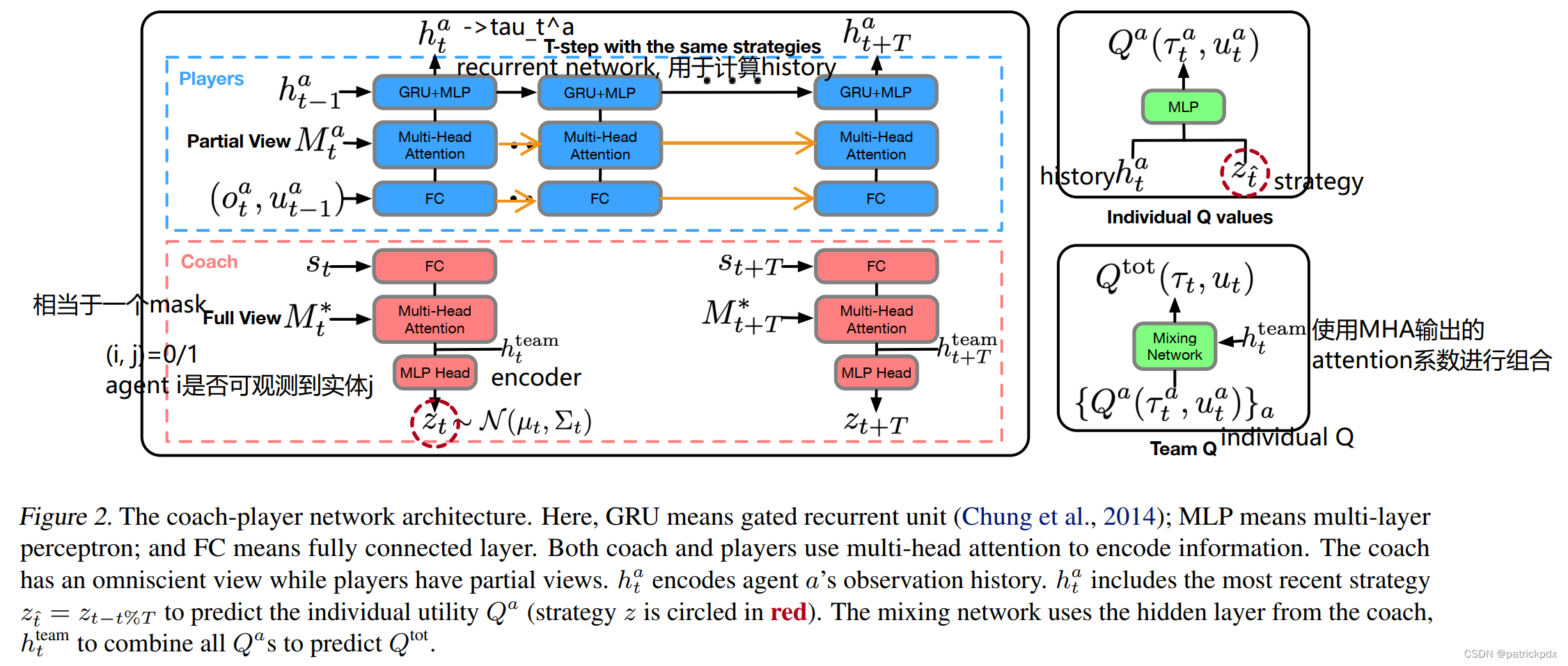
算法示意图:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









