









node 批量转换文件编码
解决方案
- 使用 npm@jschardet 获取文件编码信息(并非 100%准确)
- 通过 npm@iconv-lite 结合文件二进制流,重新识别文件内容
核心代码如下:
const fs = require('fs')
const path = require('path')
const jschardet = require('jschardet')
const iconv = require('iconv-lite')
function decode(file) {
var buf = fs.readFileSync(file, { encoding: 'binary' })
const result = jschardet.detect(buf)
data = iconv.decode(buf, result.encoding) //使用iconv转成中文格式
return data
}
node 获取文件编码格式
使用 npm@jschardet 这个库,可以获取文件编码信息(当然并非 100%准确)
支持范围在该库描述信息也有说
不过这个库只能识别个大概,并非 100%识别,下面会有一些演示
简单的搭建一个 node 运行环境,读取一下文件信息
$ npm init -y
$ npm i jschardet
- 新建 files/test.txt,并写入一段中文
// index.js
const fs = require('fs')
const path = require('path')
const jschardet = require('jschardet')
// 在同级目录下有个 files 文件夹,里面存放呆会要测试的所有的类型文件
const filesPath = path.resolve(__dirname, './files/')
var txt = fs.readFileSync(path.join(filesPath, 'test.txt'), { encoding: 'binary' })
const result = jschardet.detect(txt)
console.log(result) // 输出: { encoding: 'UTF-8', confidence: 0.99 }
有几个细节:
- readFileSync 用的是 sync 的,所以这个相当于是个同步方法
- readFileSync 的第二个参数中的
encoding,支持传入以哪种方式读取文件信息,这里选中的是binary,默认是nullfs.readFileSync 详细文档 - 在输出部分,encoding 识别为 ‘UTF-8’,其中 confidence 高达 99%
- txt 文件当前是确实是 utf-8 的类型
到这里是不是觉得已经 OK 了?
这时候改一下 files/test.txt ,改成全英文,不要留中文
神奇的一幕:result 输出为:ascii !!
{ "encoding": "ascii", "confidence": 1 }
这时候用电脑自带的记事本重新打开 files/test.txt,另存为 ANSI 格式,然后在用记事本输入中文字符
这时候用 vscode 打开该文件,中文部分已经乱码了:
my name is Jioho
�ҵ�������Jioho
jschardet 识别结果:
{ "encoding": "GB2312", "confidence": 0.99 }
根据编码信息读取文件
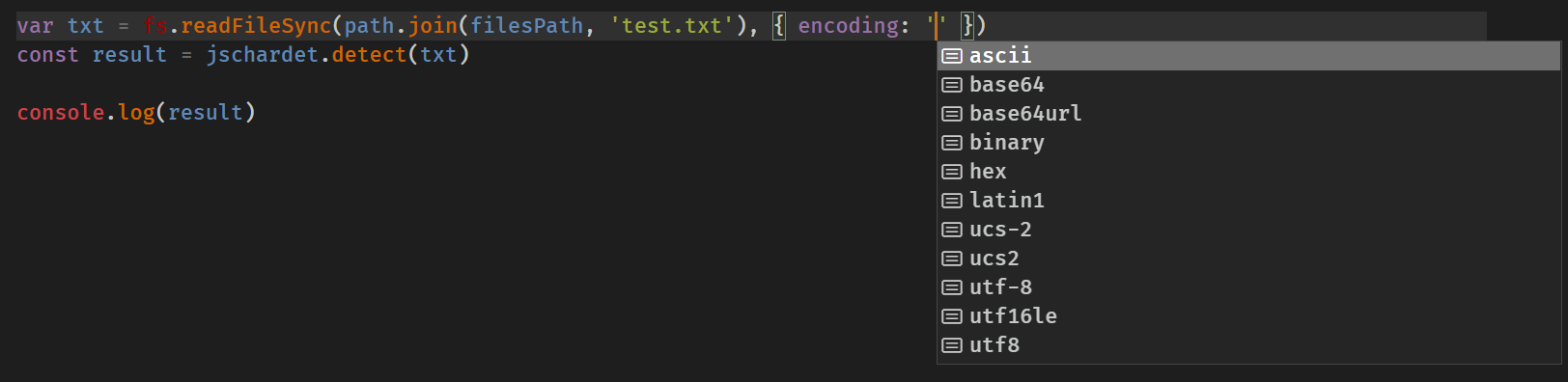
如果还是使用 fs.readFileSync 的话,根据提示能识别的编码如下(非官方文档说明,仅只是编辑器的智能提示~):
接下来要用的一个库是 npm@iconv-lite
改造 index.js 如下
const fs = require('fs')
const path = require('path')
const jschardet = require('jschardet')
const iconv = require('iconv-lite')
const filesPath = path.resolve(__dirname, './files/')
var buf = fs.readFileSync(path.join(filesPath, 'test.txt'), { encoding: 'binary' })
var text = fs.readFileSync(path.join(filesPath, 'test.txt'), { encoding: 'utf-8' })
const result = jschardet.detect(buf)
data = iconv.decode(buf, result.encoding) //使用iconv转成中文格式
console.log('识别的编码:', result.encoding)
console.log('============')
console.log('原文:', text)
console.log('============')
console.log('转义后:', data)
输出结果:
识别的编码: GB2312
============
原文: my name is Jioho
�ҵ�������Jioho
============
转义后: my name is Jioho
我的名字是Jioho
虽然识别出来的编码 GB2312 可是文本还是正确被识别出来了
循环读取
最后扣一下题,把批量处理也实现一下~
其实也就是常见的递归,获取所有文件的方案
function each(filePath: string, fn: eachFn) {
let files = fs.readdirSync(filePath)
files.forEach(item => {
let _fullPath = path.join(filePath, item)
let stat = fs.statSync(_fullPath)
if (stat.isFile() === true) {
fn({ fullPath: _fullPath, current: item }, stat)
}
if (stat.isDirectory() === true) {
each(_fullPath, fn)
}
})
}
// 调用
each('path', function ({ fullPath, current }, stat) {
console.log(fullPath, current)
})














 419
419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









