








系列文章目录
目录
前言
在类和对象(中)我们了解了类中的六个默认成员函数,以及用类实现了日期的计算。本章我们再从构造函数出发,介绍static成员、友元函数、友元类、以及再次理解封装,最后通过几个题目来进行实践。
一、初始化列表
1.再谈构造函数
再创建对象时,编译器通过调用构造函数,给每个对象中的成员变量一个合适的初始值。
class Date
{
public:
Date(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
private:
int _year;
int _month;
int _day;
};虽然上述构造函数调用之后,对象中已经有了一个初始值,但是不能将其称为对对象中成员变量的初始化,构造函数体中的语句只能将其称为赋初值,而不能称作初始化。因为初始化只能初始化一次,而构造函数体内可以多次赋值。
2.栈的构造即初始化列表
我们写出栈的默认构造,下面代码正常运行。
#include <iostream>
using namespace std;
typedef int DataType;
class Stack
{
public:
Stack(size_t capacity = 3)//默认构造
{
_array = (DataType*)malloc(sizeof(DataType) * capacity);
if (NULL == _array)
{
perror("malloc申请空间失败!!!");
return;
}
_capacity = capacity;
_size = 0;
}
void Push(DataType data)
{
// CheckCapacity();
_array[_size] = data;
_size++;
}
// 其他方法...
~Stack()
{
if (_array)
{
free(_array);
_array = NULL;
_capacity = 0;
_size = 0;
}
}
private:
DataType* _array;
int _capacity;
int _size;
};
class MyQueue
{
private:
Stack _pushst;
Stack _popst;
int _size;
};
int main()
{
MyQueue q;
return 0;
}初始化成功:
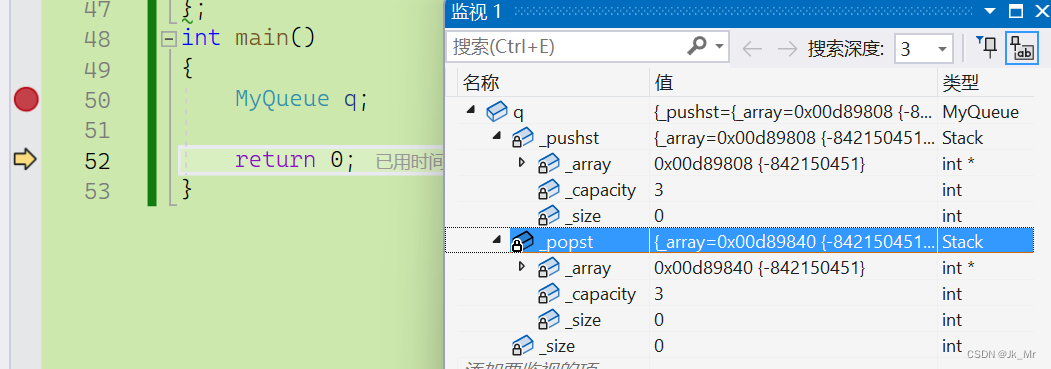
如果我们将构造的缺省值(Stack无默认构造)去掉呢?编译就会失败。MyQueue中的_pushst和_popst不具有默认构造。
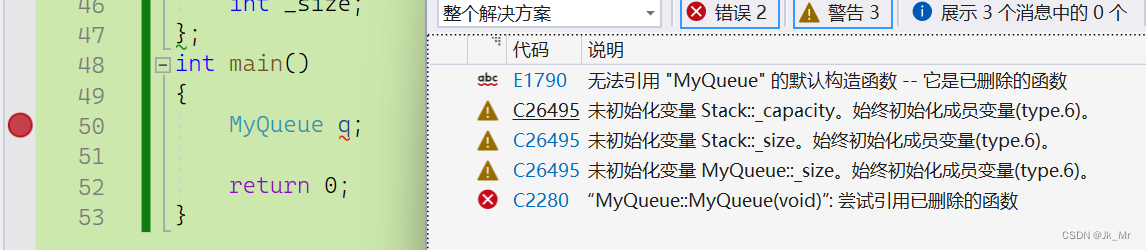

函数体内只能赋值。
所以初始化列表就来了。
初始化列表:
以一个冒号开始,接着是一个以逗号分隔的数据成员列表,每个"成员变量"后面跟一个放在括号中的初始值或表达式。
class MyQueue
{
public:
//Stack无默认构造(带参默认构造),MyQueue也无法生成默认构造。
//不改变Stack情况下,只能显示的写MyQueue的构造,那该怎么传
//初始化列表
MyQueue(int n)
:_pushst(n)
, _popst(n)
, _size(0)
{
}
private:
//声明
Stack _pushst;
Stack _popst;
int _size;
};
int main()
{
MyQueue q(10);
return 0;
}注意:类没有实例化时,类中的成员变量都是声明。
当对象实例化时,即定义时,类中的变量才会定义,那么类中的变量怎么定义,通过哪里定义?
其实初始化列表担当了这个责任.上面的代码实例化q编译器开始定义类中的成员变量,成员函数就找它的定义。
所以可以将初始化列表理解为,成员变量定义的地方。


这里的问题是Stack无默认构造时,怎么使得MyQueue 对象实例化时Stack 的对象实例化。
所以MyQueue中要有默认构造。:_pushst(n) , _popst(n), _size(0)这样也可以的。
内置类型初始化列表可以和函数体内混着用:
MyQueue(int n = 3)
:_pushst(n)
, _popst(n)
{
_size = 0;
}一般情况下不这样写。
【注意】
1. 每个成员变量在初始化列表中只能出现一次(初始化只能初始化一次)
2. 类中包含以下成员,必须放在初始化列表位置进行初始化,不能混着用:
引用成员变量(必须在定义的时候初始化)
const成员变量(必须在定义的时候初始化)
自定义类型成员(且该类没有默认构造函数时)(因为要显示的传参,即定义)
class A
{
public:
A(int a)
:_a(a)
{}
private:
int _a;
};
class B
{
public:
B(int a, int &ref)
:_aobj(a)
,_ref(ref)
,_n(10)
{}
private:
A _aobj; // 没有默认构造函数
int& _ref; // 引用
const int _n; // const
};const 变量只有一次初始化的行为,因为后面不能改变了。自定义类型则要传参。
所以这里验证了初始化列表是成员变量的定义的地方。
初始化列表的作用:
在类和对象(中)上这篇文章中我们提及到了,一个类中有自定义类型的成员变量,在该类实例化时,类中的自定义类型变量会调用它的默认构造函数。
在本章内容了解了初始化列表之后我们知道初始化列表的存在,该自定义类型成员可以不要默认构造。其实如果该自定义类型成员有默认构造,实际上也相当于走了一遍初始化列表,只是编译器自动生成初始化列表,然后自动调用了该自定义类型的默认构造。
编译器干了很多东西,这就是为什么内置类型不做处理,而自定义类型调用它的默认构造的原因。
同样我们知道缺省值是可以直接给在类中的成员变量的。
 实际上该缺省值就是给初始化列表用的。如果同时给缺省值并且初始化列表中也给它初始化,那么初始化列表中的优先。原因就是缺省值是给初始化列表用的,有了初始化列表的就不管缺省值了。
实际上该缺省值就是给初始化列表用的。如果同时给缺省值并且初始化列表中也给它初始化,那么初始化列表中的优先。原因就是缺省值是给初始化列表用的,有了初始化列表的就不管缺省值了。
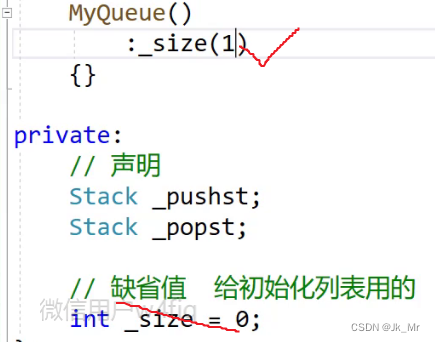 初始化列表优先。
初始化列表优先。 像这样,会走初始化列表,然后进入函数体中赋值。
像这样,会走初始化列表,然后进入函数体中赋值。
下面我们验证一下,给size缺省值是否会进入初始化列表:
Stack类默认构造函数:
Stack(size_t capacity = 3)
{
_array = (DataType*)malloc(sizeof(DataType) * capacity);
if (NULL == _array)
{
perror("malloc申请空间失败!!!");
return;
}
_capacity = capacity;
_size = 0;
}
MyQueue类:
class MyQueue
{
public:
//Stack无默认构造(带参默认构造),MyQueue也无法生成默认构造。
MyQueue()
{}
private:
//声明
Stack _pushst;
Stack _popst;
int _size = 0;
};首先时_pushst和_popst的构造。
第一步:
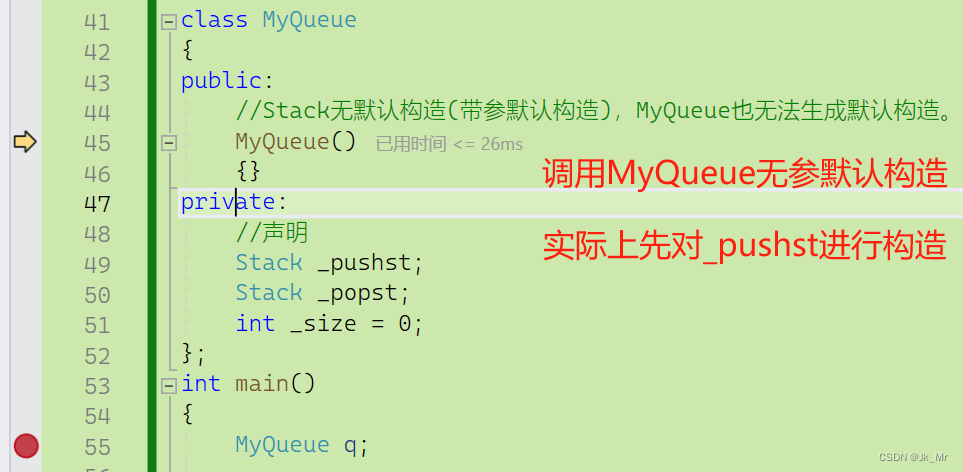
第二步:

第三步:

第四步: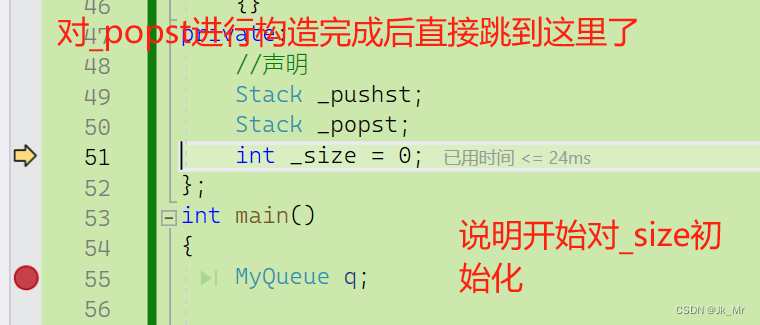
按下F11走到了该位置,说明缺省值给初始化列表了。

我们给出源代码,您可以自己进行验证:注意和显示写出初始化列表的对比。可以先看完下面的初始化顺序在来进行验证。
#include <iostream>
using namespace std;
typedef int DataType;
class Stack
{
public:
Stack(size_t capacity = 3)
{
_array = (DataType*)malloc(sizeof(DataType) * capacity);
if (NULL == _array)
{
perror("malloc申请空间失败!!!");
return;
}
_capacity = capacity;
_size = 0;
}
void Push(DataType data)
{
// CheckCapacity();
_array[_size] = data;
_size++;
}
// 其他方法...
~Stack()
{
if (_array)
{
free(_array);
_array = NULL;
_capacity = 0;
_size = 0;
}
}
private:
DataType* _array;
int _capacity;
int _size;
};
class MyQueue
{
public:
//Stack无默认构造(带参默认构造),MyQueue也无法生成默认构造。
MyQueue()
{}
private:
//声明
Stack _pushst;//使用缺省值走初始化列表
Stack _popst;//使用缺省值走初始化列表
int _size = 0;
};
int main()
{
MyQueue q;
return 0;
}有小伙伴进行疑问了,为什么不显示写初始化列表一定是按照 这样的顺序进行初始化呢?你怎么知道?
这样的顺序进行初始化呢?你怎么知道?
下面我们来进行解释,初始化列表的初始化顺序:
初始化列表的初始化顺序:
成员变量在类中声明次序就是其在初始化列表中的初始化顺序,与其在初始化列表中的先后次序无关。
class A
{
public:
A(int a)
:_a1(a)
,_a2(_a1)
{}
void Print()
{
cout<<_a1<<" "<<_a2<<endl;
}
private:
int _a2;
int _a1;
};
int main()
{
A aa(1);
aa.Print();
}
A.输出1 1
B.程序崩溃
C.编译不通过
D.输出1 随机值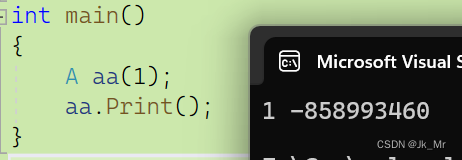 结果可以看出,初始化顺序是成员变量声明的顺序。在之后对象模型我们会介绍原因,会了解对象是如何存储的。
结果可以看出,初始化顺序是成员变量声明的顺序。在之后对象模型我们会介绍原因,会了解对象是如何存储的。
声明的顺序和初始化列表的顺序尽量保持一致。
注意:
初始化列表的括号内是很自由的:
小结一下:
初始化列表,不管你写不写,每个成员变量都会先走一遍。
自定义类型的成员会调用默认构造(没有默认构造就编译报错)。
内置类型有缺省值用缺省值,没有的话,不确定,要看编译器,有的编译器会处理,有的不会处理。
先走初始化列表 + 再走函数体。
实践中:尽可能使用初始化列表初始化,不方便再使用函数体初始化。
在函数体内可以进行其他操作,例如初始化列表对指针开辟了堆空间,然后函数体内可以对堆空间进行初始化,初始化成什么用户决定。
二、隐式类型转换
1.自定义类型的隐式类型转换
观察下面代码:
#include <iostream>
using namespace std;
class A
{
public:
A(int a)
:_a(a)
{}
private:
int _a;
};
int main()
{
A a1(1);//构造
A a2 = a1;//拷贝构造
A a3 = 3;//?这是?
return 0;
}以上代码没有问题,那么a3是怎么构造的?将3拷贝给a3吗?不是的。
这里是隐式类型转换,是内置类型转换成自定义类型。在初识C++(引用部分)提及过内置类型的隐式类型转换。
实际上自定义类型也是可以的。
上面的代码中
结合引用的知识观察下面代码能否通过编译:
#include <iostream> using namespace std; class A { public: A(int a) :_a(a) {} private: int _a; }; int main() { A a1(1); A a2 = a1; //隐式类型转换,内置类型->自定义类型 A a3 = 3; A& ra = 3; return 0; }显然是不行的,临时对象具有常量性质是不可修改的。ra指向临时对象编译不通过
加上const就可以通过:



注意以上的前提是单参数构造函数的前提下,多参数构造下面会介绍。
2.编译器优化
给1中的代码显示写出拷贝构造观察代码输出结果:
#include <iostream>
using namespace std;
class A
{
public:
A(int a)
:_a(a)
{
cout << "A(int a)" << endl;
}
A(const A& a)
{
cout << "A(const A& a)" << endl;
}
private:
int _a;
};
int main()
{
A a1(1);
A a2 = a1;
//隐式类型转换,内置->自定义类型
A a3 = 3;
const A& ra = 3;
return 0;
}
观察代码之后,我们知道:
a1 是构造; a2 是拷贝构造。
为什么a3也是构造呢?再次分析一下:
实际上是编译器搞的鬼,编译器认为,连续的 (构造+拷贝构造) 是多余的, 就会优化为构造。
同理const A& ra = 3;也是由于编译器的优化。

3.隐式类型转换的用处
知道了隐式类型转换,有何用处?我们那栈中的插入,传递自定义类型时举个例子:
#include <iostream>
using namespace std;
class A
{
public:
A(int a)
:_a(a)
{
cout << "A(int a)" << endl;
}
A(const A& a)
{
cout << "A(const A& a)" << endl;
}
private:
int _a;
};
class Stack {
public:
void Push(A x)
{
//.....
}
//....
private:
};
int main()
{
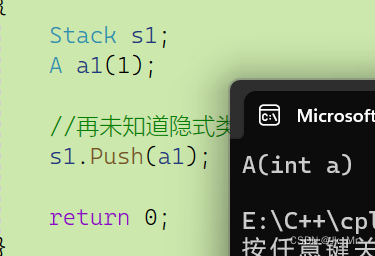
Stack s1;
A a1(1);
//再未知道隐式类型转换之前我们是如下用法
s1.Push(a1);
return 0;
}a1要构造,然后再拷贝给Push的形参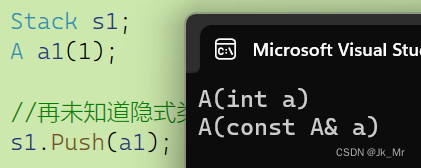 。
。
这样是不是浪费了,所以这样建议加引用。
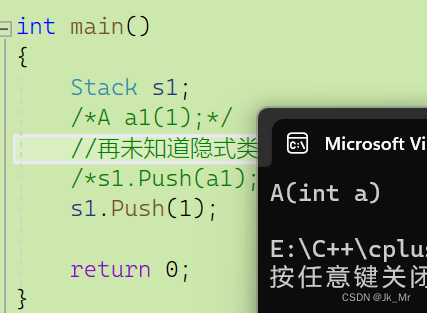
class Stack {
public:
void Push( A& x)
{
//.....
}
//....
private:
}; 这样没有问题。有人会觉得这样写比较繁琐,因为A中是单参数构造,能不能直接传递整形int呢?答案是可以的。
这样没有问题。有人会觉得这样写比较繁琐,因为A中是单参数构造,能不能直接传递整形int呢?答案是可以的。
这时就要用到隐式类型转换的知识:

加上const之后:
class Stack {
public:
void Push(const A& x)
{
//.....
}
//....
private:
}; 使用起来就变得方便了。实际上就是权限平移,只读->只读。后面的阶段会讲到string,它的构造就是如此。
使用起来就变得方便了。实际上就是权限平移,只读->只读。后面的阶段会讲到string,它的构造就是如此。
4.多参数构造隐式类型转换
多参数类型构造时有俩种隐式类型转换:
1第一个参数不缺省,其他参数缺省
:这样就可以传1个参数就好了:
#include <iostream>
using namespace std;
class A
{
public:
A(int a, int b = 2)
:_a(a)
,_b(b)
{
cout << "A(int a)" << endl;
}
A(const A& a)
{
_a = a._a;
_b = a._b;
cout << "A(const A& a)" << endl;
}
private:
int _a;
int _b;
};
class Stack {
public:
void Push(const A& x)
{
//.....
}
//....
private:
};
int main()
{
Stack s1;
A a1 = 1;//1传给a,由于b有缺省,然后1,2构造临时对象拷贝给a1.
s1.Push(1);//传一个就可以了,b默认值是2.
return 0;
}2不进行缺省(多参数)
#include <iostream>
using namespace std;
class A
{
public:
A(int a, int b)
:_a(a)
,_b(b)
{
cout << "A(int a)" << endl;
}
A(const A& a)
{
_a = a._a;
_b = a._b;
cout << "A(const A& a)" << endl;
}
private:
int _a;
int _b;
};
class Stack {
public:
void Push(const A& x)
{
//.....
}
//....
private:
};
int main()
{
Stack s1;
//这也是隐式类型转换
//1,2传给a,b进行构造临时对象,然后拷贝构造给a1
A a1 = {1,2};
//插入就这样的
s1.Push(a1);
s1.Push({ 1,2 });
return 0;
}不太建议大家这样去用。这样不太方便。要时刻注意加{}.这就是多参数的隐式类型转换。
三、explicit关键字
构造函数不仅可以构造与初始化对象,对于接收单个参数的构造函数,还具有类型转换的作用。接收单个参数的构造函数具体表现:
1. 构造函数只有一个参数
2. 构造函数有多个参数,除第一个参数没有默认值外,其余参数都有默认值
3. 全缺省构造函数
class Date
{
public:
// 1. 单参构造函数,没有使用explicit修饰,具有类型转换作用
// explicit修饰构造函数,禁止类型转换---explicit去掉之后,代码可以通过编译
explicit Date(int year)
:_year(year)
{}
/*
// 2. 虽然有多个参数,但是创建对象时后两个参数可以不传递,没有使用explicit修饰,具有类型转
换作用
// explicit修饰构造函数,禁止类型转换
explicit Date(int year, int month = 1, int day = 1)
: _year(year)
, _month(month)
, _day(day)
{}
*/
Date& operator=(const Date& d)
{
if (this != &d)
{
_year = d._year;
_month = d._month;
_day = d._day;
}
return *this;
}
private:
int _year;
int _month;
int _day;
};
void Test()
{
Date d1(2022);
// 用一个整形变量给日期类型对象赋值
// 实际编译器背后会用2023构造一个无名对象,最后用无名对象给d1对象进行赋值
d1 = 2023;
// 将1屏蔽掉,2放开时则编译失败,因为explicit修饰构造函数,禁止了单参构造函数类型转换的作用
} 上述代码可读性不是很好,用explicit修饰构造函数,将会禁止构造函数的隐式转换。
四、隐式类型转换和初始化列表应用
通过上面的知识,我们知道初始化列表的用法和类中的缺省值是给初始化列表用的。并且知道内置类型可以隐式类型转换类型。
那我们在给缺省值和使用初始化列表时会自由。即下面代码:
class A
{
public:
A(int a)
:_a(a)
{
cout << "A(int a)" << endl;
}
A(int a, int b)
:_a(a)
, _b(b)
{
cout << "A(int a, int b)" << endl;
}
A(const A& a)
{
_a = a._a;
_b = a._b;
cout << "A(const A& a)" << endl;
}
private:
//ȱʡֵ
int _a;
int _b;
};
typedef int DataType;
class Stack
{
public:
Stack(size_t capacity = 4)
{
_array = (DataType*)malloc(sizeof(DataType) * capacity);
if (NULL == _array)
{
perror("malloc申请空间失败!!!");
return;
}
_capacity = capacity;
_size = 0;
}
void Push(DataType data)
{
// CheckCapacity();
_array[_size] = data;
_size++;
}
// 其他方法...
~Stack()
{
if (_array)
{
free(_array);
_array = NULL;
_capacity = 0;
_size = 0;
}
}
private:
DataType* _array;
int _capacity;
int _size;
};
class B
{
private:
int _b = 1;
int* _ptr = (int*)malloc(sizeof(int));
Stack _pushst = 10;
A a1 = 1;
A a2 = { 1,2 };
A a3 = a2;
};在以后的程序中,遇到奇怪的代码我们要知道这些知识。
五、static成员
1.概念
声明为static的类成员称为类的静态成员,用static修饰的成员变量,称之为静态成员变量;用static修饰的成员函数,称之为静态成员函数。静态成员变量一定要在类外进行初始化
#include <iostream>
using namespace std;
class A {
public:
A(){++scount;}
A(const A& a) { ++scount; }
~A() { --scount; }
static int GetAount() {return scount; }
private:
int _a;
int _b;
static int scount;
};
int A::scount = 0;
int main()
{
A a1;
cout<<sizeof(a1)<<endl;
return 0;
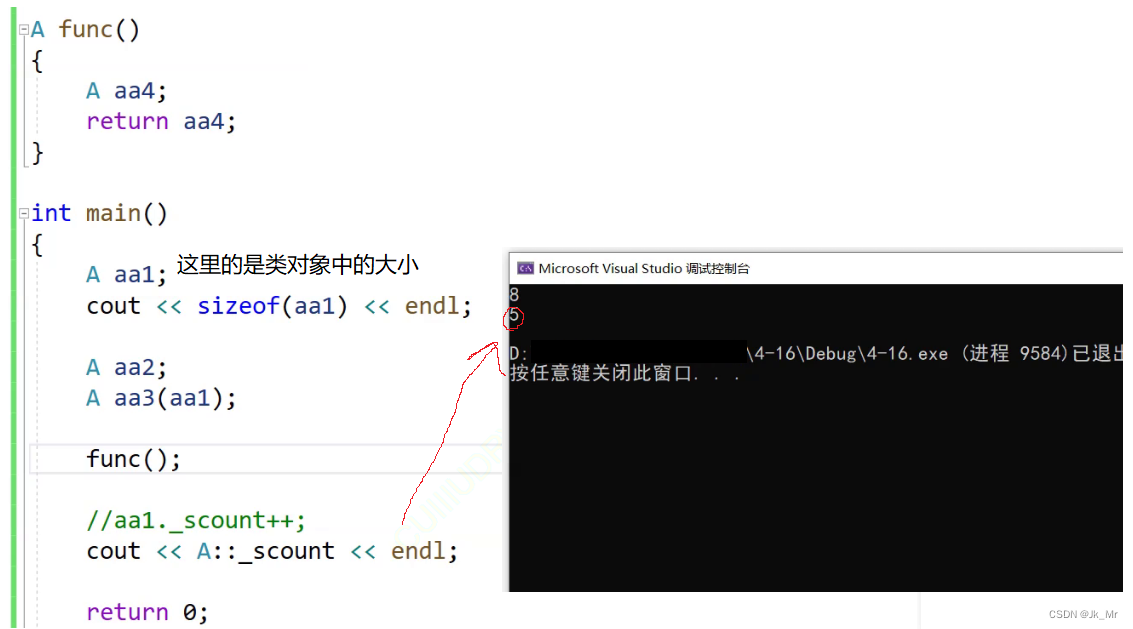
}static成员变量是否在对象中?static成员函数中是否有this指针?
大小:

static函数中使用this:
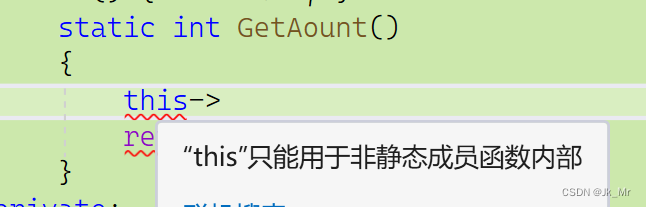
输出结果表明static成员变量不在对象内,不在类中。它存放在静态区。
注意static 成员变量不能给缺省值:
缺省值是给初始化列表的,初始化列表是用来初始化对象成员变量的。
它的初始化只能在类外:
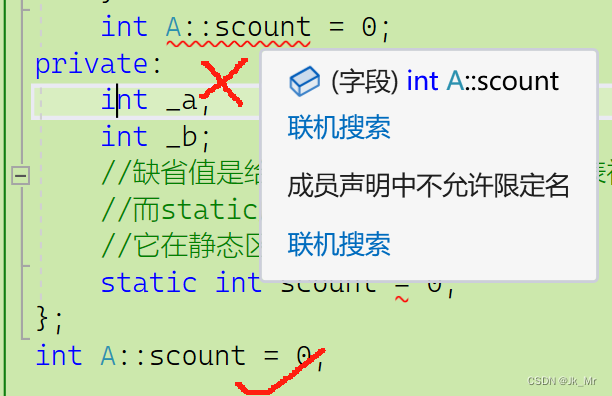
如果static成员受访问限定符的限定。那么当static 成员变量是私有时该怎么访问?
在开始的代码中我们给出了解答,可以通过get来获取相关的值。
static int GetAount() {return scount; }2.特性
1. 静态成员为所有类对象所共享,不属于某个具体的对象,存放在静态区
2. 静态成员变量必须在类外定义,定义时不添加static关键字,类中只是声明
3. 类静态成员即可用 类名::静态成员 或者 对象.静态成员 来访问
4. 静态成员函数没有隐藏的this指针,不能访问任何非静态成员
5. 静态成员也是类的成员,受public、protected、private 访问限定符的限制
static修饰变量,变量存放在静态区。static修饰函数,影响函数的链接属性,不进符号表,限定在了当前文件中。
3.static题目
面试题:实现一个类,计算程序中创建出了多少个类对象。
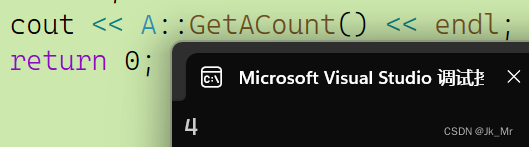
#include <iostream> using namespace std; class A { public: A() { ++_scount; } A(const A& t) { ++_scount; } ~A() { /*--_scount;*/ } static int GetACount() { return _scount; } private: static int _scount; }; int A::_scount = 0; A func() { A a4; return a4; } int main() { A a1; A a2; A a3(a1); func(); cout << A::GetACount() << endl; return 0; }一个对象不是构造出来的就是拷贝构造出来的。
VS2022下的结果:
实际上在过程中func会产生临时对象,构造的对象会多一个:
只不过在2022的编译器下进行了优化 (连续的 (构造+拷贝构造)):

1. 静态成员函数可以调用非静态成员函数吗?
不可以,没有this指针。
2. 非静态成员函数可以调用类的静态成员函数吗?
可以,函数是公用。
1.求1+2+3+...+n,要求不能使用乘除法、for、while、if、else、switch、case等关键字及条件判断语句。
创建对象n次,用一个变量记录,+=赋值给另一个变量。
class Sum{
public:
Sum()
{
_ret += _i;
_i++;
}
public:
static int _i ;
static int _ret;
};
int Sum::_i = 1;//用于从1开始加
int Sum::_ret = 0;//用于赋值+=
class Solution {
public:
int Sum_Solution(int n) {
Sum a[n];//变长数组,构造n次,每次构造_ret+=i;
return Sum::_ret;
}
};六、友元
友元提供了一种突破封装的方式,有时提供了便利。但是友元会增加耦合度,破坏了封装,所以友元不宜多用。
友元分为:友元函数和友元类
1.友元函数
在类和对象(中)下我们提到重载<<和>>可以只能通过重载成全局函数来解决this指针抢占输入输出流的cin和cout的位置,并且提到通过友元函数来解决获取私有成员的办法,这里我们详细讲解。
class Date
{
public:
Date(int year, int month, int day)
: _year(year)
, _month(month)
, _day(day)
{}
// d1 << cout; -> d1.operator<<(&d1, cout); 不符合常规调用
// 因为成员函数第一个参数一定是隐藏的this,所以d1必须放在<<的左侧
ostream& operator<<(ostream& _cout)
{
_cout << _year << "-" << _month << "-" << _day << endl;
return _cout;
}
private:
int _year;
int _month;
int _day;
};友元函数可以直接访问类的私有成员,它是定义在类外部的普通函数,不属于任何类,但需要在类的内部声明,声明时需要加friend关键字。
#include <iostream>
using namespace std;
class Date
{
friend ostream& operator<<(ostream& _cout, const Date& d);
friend istream& operator>>(istream& _cin, Date& d);
public:
Date(int year = 1900, int month = 1, int day = 1)
: _year(year)
, _month(month)
, _day(day)
{}
private:
int _year;
int _month;
int _day;
};
ostream& operator<<(ostream& _cout, const Date& d)
{
_cout << d._year << "-" << d._month << "-" << d._day;
return _cout;
}
istream& operator>>(istream& _cin, Date& d)
{
_cin >> d._year;
_cin >> d._month;
_cin >> d._day;
return _cin;
}
int main()
{
Date d;
cin >> d;
cout << d << endl;
return 0;
}说明:
友元函数可访问类的私有和保护成员,但不是类的成员函数
友元函数不能用const修饰
友元函数可以在类定义的任何地方声明,不受类访问限定符限制
一个函数可以是多个类的友元函数
友元函数的调用与普通函数的调用原理相同
2.友元类
友元类的所有成员函数都可以是另一个类的友元函数,都可以访问另一个类中的非公有成员。
1.友元关系是单向的,不具有交换性。
比如上述Time类和Date类,在Time类中声明Date类为其友元类,那么可以在Date类中直接访问Time类的私有成员变量,但想在Time类中访问Date类中私有的成员变量则不行。
2.友元关系不能传递
如果B是A的友元,C是B的友元,则不能说明C时A的友元。
3.友元关系不能继承,在继承位置再给大家详细介绍。
class Time
{
friend class Date; // 声明日期类为时间类的友元类,则在日期类中就直接访问Time类中的私有成员变量
public:Time(int hour = 0, int minute = 0, int second = 0)
: _hour(hour)
, _minute(minute)
, _second(second)
{}
private:
int _hour;
int _minute;
int _second;
};
class Date
{
public:
Date(int year = 1900, int month = 1, int day = 1)
: _year(year)
, _month(month)
, _day(day)
{}
void SetTimeOfDate(int hour, int minute, int second)
{
// 直接访问时间类私有的成员变量
_t._hour = hour;
_t._minute = minute;
_t._second = second;
}
private:
int _year;
int _month;
int _day;
Time _t;
};A是B的友元类,A就可以访问B的私有成员。在B中声明friend class A。
3. 内部类
概念:如果一个类定义在另一个类的内部,这个内部类就叫做内部类。内部类是一个独立的类,它不属于外部类,更不能通过外部类的对象去访问内部类的成员。外部类对内部类没有任何优越的访问权限。
注意:内部类就是外部类的友元类,参见友元类的定义,内部类可以通过外部类的对象参数来访问外部类中的所有成员。但是外部类不是内部类的友元。
特性:
1. 内部类可以定义在外部类的public、protected、private都是可以的。
(内部类仅仅是受到访问限定符的限制)外部类和内部类是独立的。
2. 注意内部类可以直接访问外部类中的static成员,不需要外部类的对象/类名。
3. sizeof(外部类)=外部类,和内部类没有任何关系。
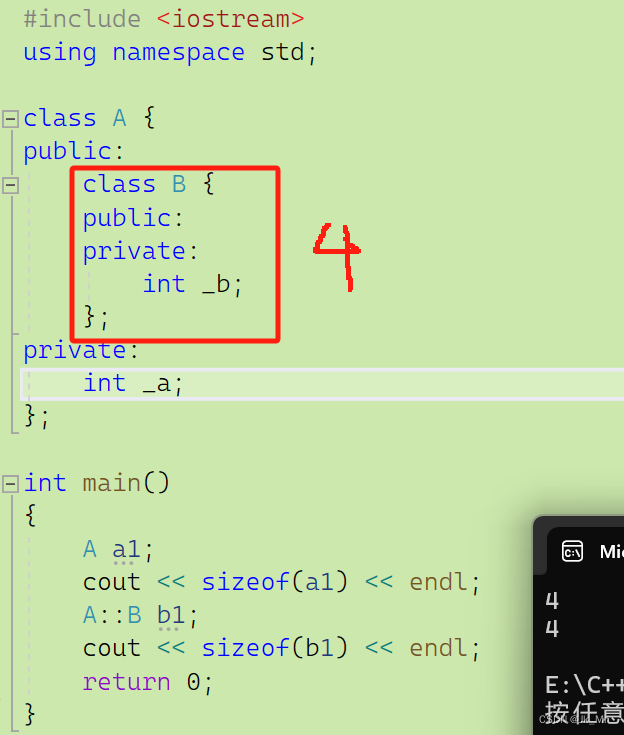
class A
{
private:
static int k;
int h;
public:
class B // B天生就是A的友元
{
public:
void foo(const A& a)
{
cout << k << endl;//OK
cout << a.h << endl;//OK
}
};
};
int A::k = 1;
int main()
{
A::B b;
b.foo(A());
return 0;
}有了内部类的概念,那么求1+2+3+...+n就可以更加简化:
既然Sum是专门用来计算1···n的那么我们可以将它只用于类Solution。
class Solution {
public:
int Sum_Solution(int n) {
Sum a[n];//实例化n次内部类,调用n次构造函数。
return _ret;
}
private:
//内部类,可以直接访问外部类的成员
class Sum
{
public:
Sum()
{
_ret += _i;
_i++;
}
};
static int _i;
static int _ret;
};
int Solution::_i = 1;
int Solution::_ret = 0;七、匿名对象
匿名对象是实例化时没有名字的对象:
#include <iostream>
using namespace std;
class A{
public:
A()
{
cout << "A()" << endl;
}
A(int a)
{
cout << "A(int a)" << endl;
}
~A()
{
cout << "~A()" << endl;
}
private:
int _a;
};
int main()
{
A();
A(1);
return 0;
}匿名对象的生命周期只在当前这一行:
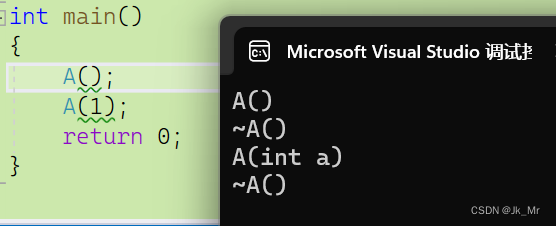
可以观察到,构造之后就析构了。
那么匿名对象有什么用吗?在调用函数时,可以不用创建对象。
#include <iostream>
using namespace std;
class Solution {
public:
int Sum_Solution(int n) {
//....
return n;
}
};
int main()
{
//有名对象调用
Solution s1;
s1.Sum_Solution(10);
//匿名对象调用
Solution().Sum_Solution(10);
return 0;
}后面会详细介绍。
八、编译器对拷贝构造的优化
下面的结果都是在vs2019下演示的,不同的编译器可能优化不同,并且不同版本的编译器优化程度也不同。
1.连续的构造+拷贝构造
在讲解隐式类型转换时,我们提到过,传值传参时,过程是产生临时对象,然后将临时对象拷贝给形参。临时对象具有常量性质。
#include <iostream>
using namespace std;
class A
{
public:
A(int a = 0)
:_a(a)
{
cout << "A(int a = 0)" << endl;
}
A(const A& aa)
:_a(aa._a)
{
cout << "A(const A& aa)" << endl;
}
A& operator=(const A& aa)
{
cout << "A& operator=(const A& aa)" << endl;
if (&aa != this)
{
_a = aa._a;
}
return *this;
}
~A()
{
cout << "~A()" << endl;
}
private:
int _a;
};
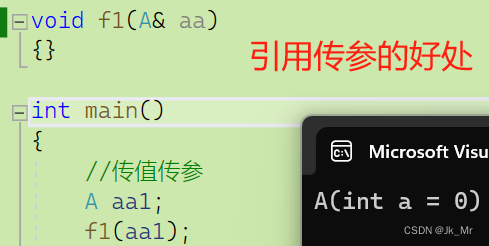
void f1(A aa)//临时对象具有常性
{}
int main()
{
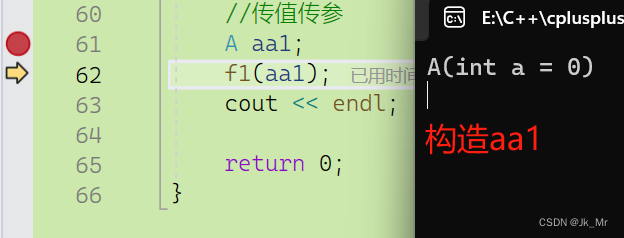
//传值传参
A aa1;
f1(aa1);
cout << endl;
return 0;
}vs2019下结果:
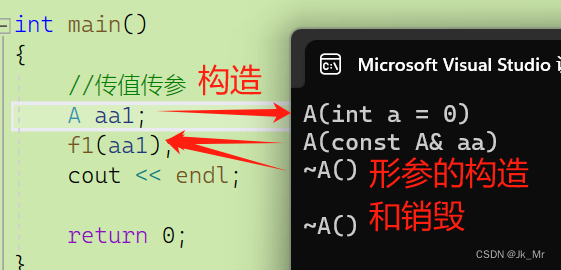
通过调试可以更加详细:


使用引用传参的好处:
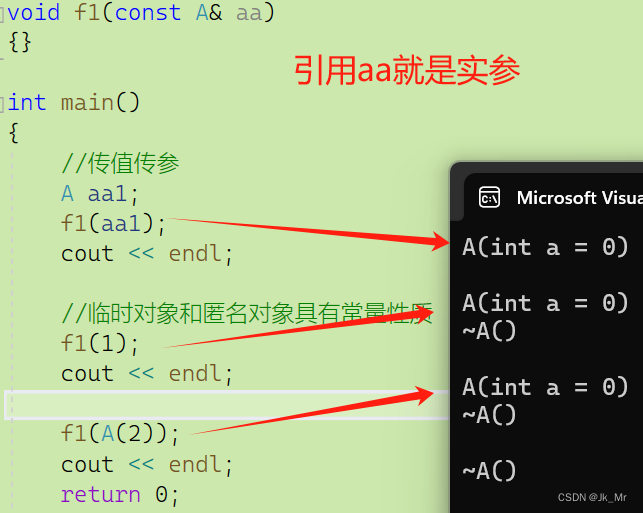
并且最好用const修饰:
void f1(const A& aa)
{}
int main()
{
//传值传参
A aa1;
f1(aa1);
cout << endl;
//临时对象和匿名对象具有常量性质
f1(1);
cout << endl;
f1(A(2));
cout << endl;
return 0;
} 
不用引用:
void f1(A aa)
{}
int main()
{
//传值传参
A aa1;
f1(aa1);
cout << endl;
//临时对象和匿名对象具有常量性质
//连续的构造+拷贝构造优化为构造(不是所有的编译器会做)
f1(1);
cout << endl;
f1(A(2));
cout << endl;
return 0;
}编译器会进行优化,将连续的构造+拷贝构造优化为构造:
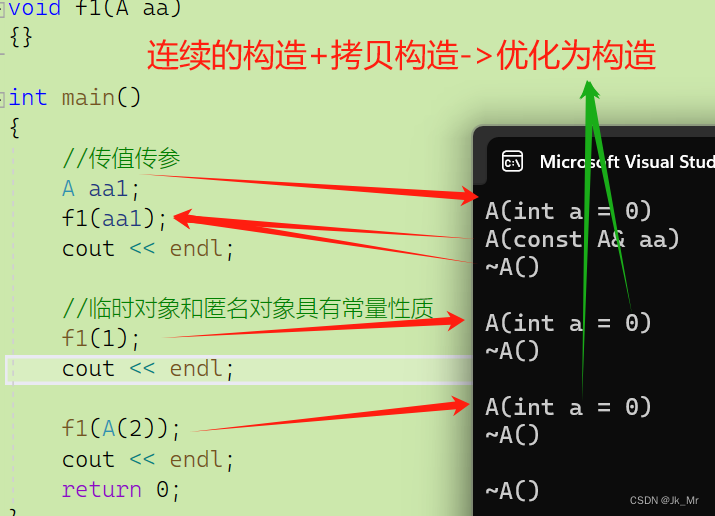
2.连续的俩个拷贝构造
A f2()
{
A aa;
return aa;
}
int main()
{
//连续的一个表达式中,拷贝构造+拷贝构造->优化为一个拷贝构造
A ret = f2();
return 0;
} vs2019下结果:
vs2022下结果:release下也是如此:
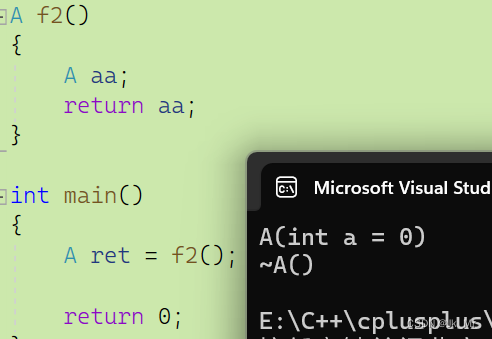 直接优化成一步。
直接优化成一步。
中间产生临时变量直接省略了。
注意不能下面这样写:
A& f2()
{
A aa;
return aa;
}
int main()
{
const A& ret = f2();
return 0;
}引用的是局部对象aa,它是不能确定的。返回临时变量的地址。
如果函数f2返回值是A则可以,那么ret指向的是返回时的临时对象,但是必须有const,临时对象有常量性质。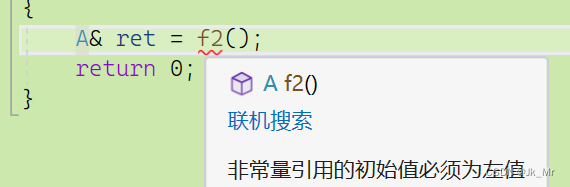
不同版本的编译器优化是不同的。
3.赋值优化不了
A f2()
{
A aa;
return aa;
}
int main()
{
A ret2;
ret2 = f2();
cout << endl;
return 0;
} 这里验证了返回时回有临时变量产生: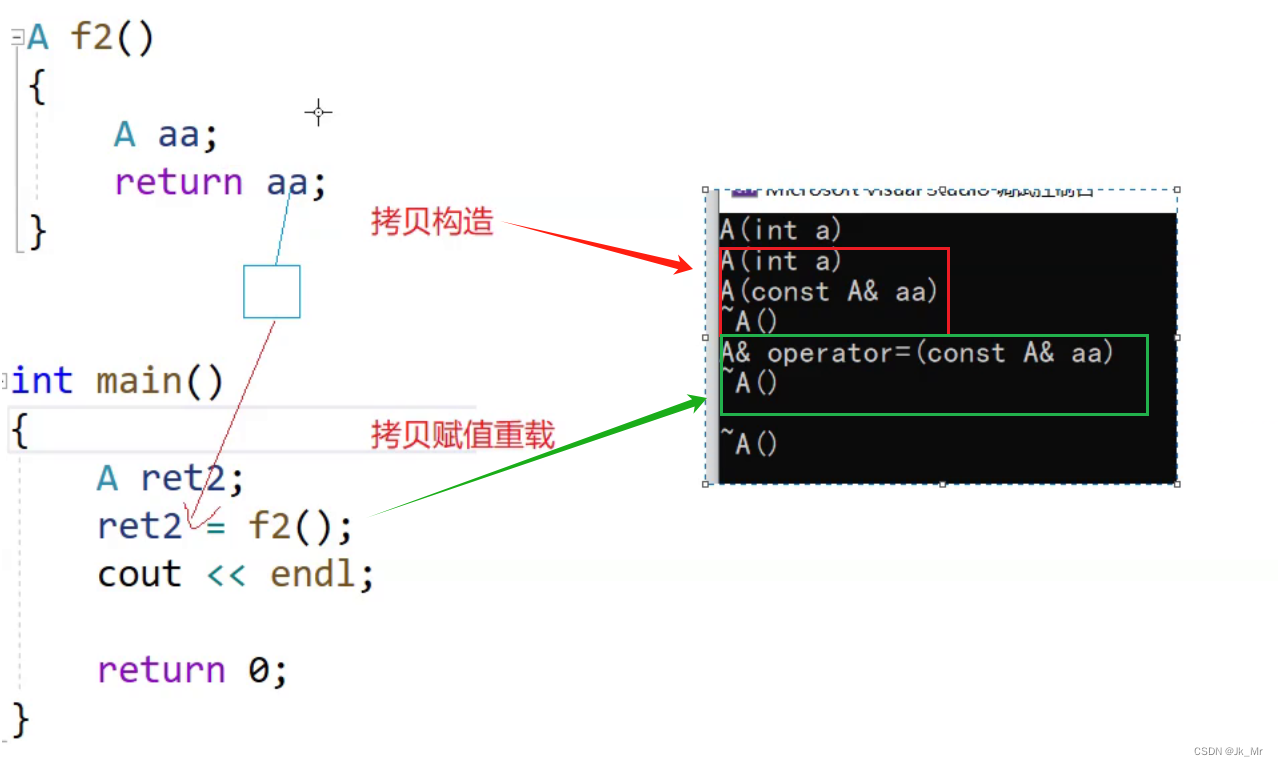
所以尽量不要上面的写法,编译器优化不了。release版本下可以跨行优化: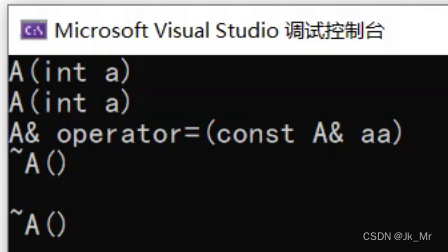 vs2022Debug下也是。
vs2022Debug下也是。
通过加一行代码观察release下的优化:
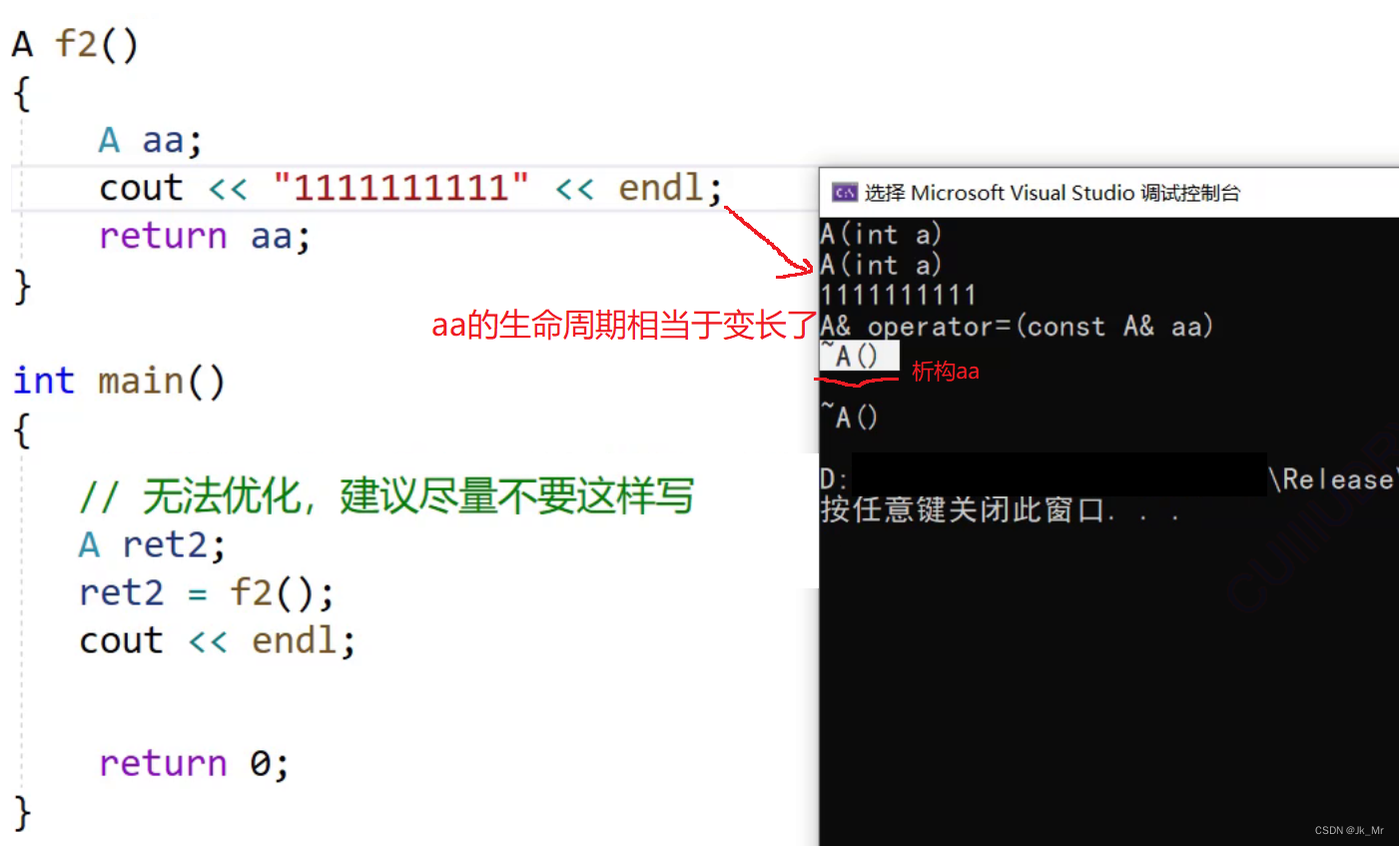
编译器是经过了严格的语义分析进行优化的。
九、再次理解类和对象
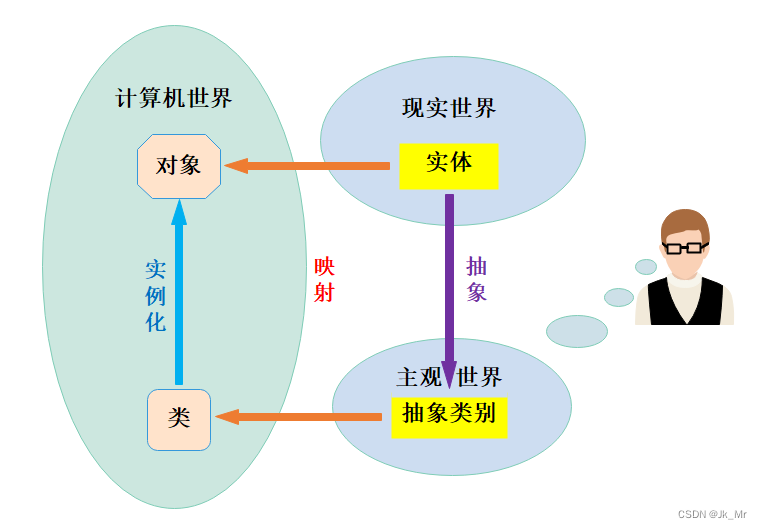
现实生活中的实体计算机并不认识,计算机只认识二进制格式的数据。如果想要让计算机认识现实生活中的实体,用户必须通过某种面向对象的语言,对实体进行描述,然后通过编写程序,创建对象后计算机才可以认识。比如想要让计算机认识洗衣机,就需要:
1. 用户先要对现实中洗衣机实体进行抽象---即在人为思想层面对洗衣机进行认识,洗衣机有什么属性,有那些功能,即对洗衣机进行抽象认知的一个过程
2. 经过1之后,在人的头脑中已经对洗衣机有了一个清醒的认识,只不过此时计算机还不清楚,想要让计算机识别人想象中的洗衣机,就需要人通过某种面相对象的语言(比如:C++、Java、Python等)将洗衣机用类来进行描述,并输入到计算机中
3. 经过2之后,在计算机中就有了一个洗衣机类,但是洗衣机类只是站在计算机的角度对洗衣机对象进行描述的,通过洗衣机类,可以实例化出一个个具体的洗衣机对象,此时计算机才能洗衣机是什么东西。
4. 用户就可以借助计算机中洗衣机对象,来模拟现实中的洗衣机实体了。
在类和对象阶段,大家一定要体会到,类是对某一类实体(对象)来进行描述的,描述该对象具有那些属性,那些方法,描述完成后就形成了一种新的自定义类型,才用该自定义类型就可以实例化具体的对象。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









